Présentation du convertisseur d'inférence Cloud TPU v5e
Introduction
Le convertisseur d'inférence Cloud TPU prépare et optimise un modèle TensorFlow 2 (TF2) pour l'inférence TPU. Le convertisseur s'exécute dans un shell local ou dans une VM TPU. Le shell de la VM TPU est recommandé, car il est préinstallé avec les outils de ligne de commande nécessaires au convertisseur. Il prend un SavedModel exporté et effectue les étapes suivantes:
- Conversion TPU: ajoute
TPUPartitionedCallet d'autres opérations TPU au modèle pour le rendre utilisable sur le TPU. Par défaut, un modèle exporté pour l'inférence ne comporte pas de telles opérations et ne peut pas être diffusé sur le TPU, même s'il a été entraîné sur le TPU. - Mise en lot: permet d'ajouter des opérations de mise en lot au modèle pour activer la mise en lot dans le graphique afin d'améliorer le débit.
- Conversion BFloat16: convertit le format de données du modèle de
float32enbfloat16pour de meilleures performances de calcul et une utilisation réduite de la mémoire à haut débit (HBM) sur le TPU. - Optimisation de la forme d'E/S: optimise les formes de tenseur pour les données transférées entre le processeur et le TPU afin d'améliorer l'utilisation de la bande passante.
Lorsque vous exportez un modèle, vous créez des alias de fonction pour toutes les fonctions que vous souhaitez exécuter sur le TPU. Ils transmettent ces fonctions au convertisseur, qui les place sur le TPU et les optimise.
Le convertisseur d'inférence Cloud TPU est disponible en tant qu'image Docker pouvant être exécutée dans n'importe quel environnement où Docker est installé.
Temps estimé pour effectuer les étapes ci-dessus: environ 20 à 30 minutes
Prérequis
- Le modèle doit être un modèle TF2 et exporté au format SavedModel.
- Le modèle doit comporter un alias de fonction pour la fonction TPU. Pour savoir comment procéder, consultez l'exemple de code. Les exemples suivants utilisent
tpu_funccomme alias de fonction TPU. - Assurez-vous que le processeur de votre machine est compatible avec les instructions AVX (Advanced Vector Extensions), car la bibliothèque Tensorflow (dépendance du convertisseur d'inférence Cloud TPU) est compilée pour utiliser les instructions AVX.
La plupart des processeurs sont compatibles avec AVX.
- Vous pouvez exécuter
lscpu | grep avxpour vérifier si l'ensemble d'instructions AVX est compatible.
- Vous pouvez exécuter
Avant de commencer
Avant de commencer la configuration, procédez comme suit:
Créer un projet : dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Cloud.
Configurer une VM TPU : créez une VM TPU à l'aide de la console Google Cloud ou de
gcloud, ou utilisez une VM TPU existante pour exécuter l'inférence avec le modèle converti sur la VM TPU.- Assurez-vous que l'image de la VM TPU est basée sur TensorFlow. Par exemple,
--version=tpu-vm-tf-2.11.0. - Le modèle converti sera chargé et diffusé sur cette VM TPU.
- Assurez-vous que l'image de la VM TPU est basée sur TensorFlow. Par exemple,
Assurez-vous de disposer des outils de ligne de commande dont vous avez besoin pour utiliser le convertisseur d'inférence Cloud TPU. Vous pouvez installer Google Cloud SDK et Docker localement ou utiliser une VM TPU sur laquelle ces logiciels sont installés par défaut. Vous utilisez ces outils pour interagir avec l'image du convertisseur.
Connectez-vous à l'instance avec SSH à l'aide de la commande suivante:
gcloud compute tpus tpu-vm ssh ${tpu-name} --zone ${zone} --project ${project-id}
Configuration de l'environnement
Configurez votre environnement à partir du shell de votre VM TPU ou de votre shell local.
Shell de la VM TPU
Dans le shell de votre VM TPU, exécutez les commandes suivantes pour autoriser l'utilisation de Docker en tant que non-root:
sudo usermod -a -G docker ${USER} newgrp docker
Initialisez vos assistants d'identification Docker:
gcloud auth configure-docker \ us-docker.pkg.dev
Interface système locale
Dans votre shell local, configurez l'environnement en procédant comme suit:
Installez le SDK Cloud, qui inclut l'outil de ligne de commande
gcloud.Installez Docker:
Autorisez l'utilisation de Docker en tant qu'utilisateur non racine:
sudo usermod -a -G docker ${USER} newgrp docker
Connectez-vous à votre environnement:
gcloud auth login
Initialisez vos assistants d'identification Docker:
gcloud auth configure-docker \ us-docker.pkg.dev
Extrayez l'image Docker du convertisseur d'inférence:
CONVERTER_IMAGE=us-docker.pkg.dev/cloud-tpu-images/inference/tpu-inference-converter-cli:2.13.0 docker pull ${CONVERTER_IMAGE}
Image du convertisseur
L'image permet d'effectuer des conversions de modèle uniques. Définissez les chemins d'accès au modèle et ajustez les options de conversion en fonction de vos besoins. La section Exemples d'utilisation présente plusieurs cas d'utilisation courants.
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { function_alias: "tpu_func" } batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } '
Inférence avec le modèle converti dans la VM TPU
# Initialize the TPU resolver = tf.distribute.cluster_resolver.TPUClusterResolver("local") tf.config.experimental_connect_to_cluster(resolver) tf.tpu.experimental.initialize_tpu_system(resolver) # Load the model model = tf.saved_model.load(${CONVERTED_MODEL_PATH}) # Find the signature function for serving serving_signature = 'serving_default' # Change the serving signature if needed serving_fn = model.signatures[serving_signature] # Run the inference using requests. results = serving_fn(**inputs) logging.info("Serving results: %s", str(results))
Exemples d'utilisation
Ajouter un alias de fonction pour la fonction TPU
- Recherchez ou créez une fonction dans votre modèle qui encapsule tout ce que vous souhaitez exécuter sur le TPU. Si
@tf.functionn'existe pas, ajoutez-le. - Lorsque vous enregistrez le modèle, fournissez des options d'enregistrement comme ci-dessous pour attribuer un alias
func_on_tpuàmodel.tpu_func. - Vous pouvez transmettre cet alias de fonction au convertisseur.
class ToyModel(tf.keras.Model): @tf.function( input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def tpu_func(self, x): return x * 1.0 model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'func_on_tpu': model.tpu_func, }) tf.saved_model.save(model, model_dir, options=save_options)
Convertir un modèle avec plusieurs fonctions TPU
Vous pouvez placer plusieurs fonctions sur le TPU. Il vous suffit de créer plusieurs alias de fonction et de les transmettre à converter_options_string au convertisseur.
tpu_functions { function_alias: "tpu_func_1" } tpu_functions { function_alias: "tpu_func_2" }
Quantification
La quantification est une technique qui réduit la précision des nombres utilisés pour représenter les paramètres d'un modèle. Cela permet de réduire la taille du modèle et d'accélérer le calcul. Un modèle quantifié offre des gains de débit d'inférence, ainsi qu'une utilisation de la mémoire et une taille de stockage plus faibles, au prix de légères baisses de précision.
La nouvelle fonctionnalité de quantification post-entraînement de TensorFlow qui cible les TPU est développée à partir de la fonctionnalité existante similaire de TensorFlow Lite qui permet de cibler les appareils mobiles et de périphérie. Pour en savoir plus sur la quantification en général, consultez la documentation de TensorFlow Lite.
Concepts de quantification
Cette section définit les concepts spécifiquement liés à la quantification avec le convertisseur d'inférence.
Les concepts liés à d'autres configurations de TPU (par exemple, les tranches, les hôtes, les puces et les TensorCores) sont décrits sur la page Architecture du système TPU.
Quantification post-entraînement (PTQ): la PTQ est une technique qui réduit la taille et la complexité de calcul d'un modèle de réseau de neurones sans affecter significativement sa précision. La PTQ consiste à convertir les poids et les activations à virgule flottante d'un modèle entraîné en entiers à précision inférieure, tels que des entiers de 8 bits ou de 16 bits. Cela peut entraîner une réduction significative de la taille du modèle et de la latence d'inférence, tout en ne subissant qu'une faible perte de justesse.
Calibrage: l'étape de calibrage de la quantification consiste à collecter des statistiques sur la plage de valeurs que prennent les poids et les activations d'un modèle de réseau de neurones. Ces informations permettent de déterminer les paramètres de quantification du modèle, qui sont les valeurs qui seront utilisées pour convertir les pondérations et activations à virgule flottante en entiers.
Ensemble de données représentatif: un ensemble de données représentatif pour la quantification est un petit ensemble de données qui représente les données d'entrée réelles du modèle. Il est utilisé lors de l'étape de calibrage de la quantification pour collecter des statistiques sur la plage de valeurs que les poids et les activations du modèle prendront. L'ensemble de données représentatif doit remplir les propriétés suivantes:
- Il doit représenter correctement les entrées réelles du modèle lors de l'inférence. Cela signifie qu'il doit couvrir la plage de valeurs que le modèle est susceptible de rencontrer dans le monde réel.
- Il doit circuler collectivement dans chaque branche des conditions (telles que
tf.cond), le cas échéant. Cela est important, car le processus de quantification doit pouvoir gérer toutes les entrées possibles du modèle, même si elles ne sont pas explicitement représentées dans l'ensemble de données représentatif. - Il doit être suffisamment important pour collecter suffisamment d'informations statistiques et réduire les erreurs. En règle générale, il est recommandé d'utiliser plus de 200 échantillons représentatifs.
L'ensemble de données représentatif peut être un sous-ensemble de l'ensemble de données d'entraînement ou un ensemble de données distinct conçu spécifiquement pour représenter les entrées réelles du modèle. Le choix de l'ensemble de données à utiliser dépend de l'application spécifique.
Quantification de plage statique (SRQ): la SRQ détermine la plage de valeurs pour les poids et les activations d'un modèle de réseau de neurones une seule fois, lors de l'étape de calibrage. Cela signifie que la même plage de valeurs est utilisée pour toutes les entrées du modèle. Cela peut être moins précis que la quantification de la plage dynamique, en particulier pour les modèles avec une large plage de valeurs d'entrée. Toutefois, la quantification de la plage statique nécessite moins de calcul au moment de l'exécution que la quantification de la plage dynamique.
Quantification de la plage dynamique (DRQ): la DRQ détermine la plage de valeurs pour les poids et les activations d'un modèle de réseau de neurones pour chaque entrée. Cela permet au modèle de s'adapter à la plage de valeurs des données d'entrée, ce qui peut améliorer la précision. Cependant, la quantification de la plage dynamique nécessite plus de calculs au moment de l'exécution que la quantification de la plage statique.
Fonctionnalité Quantification de la plage statique Quantification de la plage dynamique Plage de valeurs Déterminé une fois, lors de la calibration Déterminé pour chaque entrée Précision Peut être moins précis, en particulier pour les modèles avec une large plage de valeurs d'entrée Peut être plus précis, en particulier pour les modèles avec une large plage de valeurs d'entrée Complexité Plus simple Plus complexe Calcul au moment de l'exécution Moins de calculs Plus de calculs Quantification des poids uniquement: la quantification des poids uniquement est un type de quantification qui ne quantize que les poids d'un modèle de réseau de neurones, tout en laissant les activations en virgule flottante. Il peut s'agir d'une bonne option pour les modèles sensibles à la précision, car cela peut aider à préserver la précision du modèle.
Utiliser la quantisation
La quantification peut être appliquée en configurant et en définissant QuantizationOptions sur les options du convertisseur. Voici quelques options notables:
- tags: ensemble de balises identifiant les
MetaGraphDefdans leSavedModelà quantifier. Vous n'avez pas besoin de spécifier si vous n'avez qu'un seulMetaGraphDef. - signature_keys: séquence de clés identifiant
SignatureDefcontenant des entrées et des sorties. Si ce paramètre n'est pas spécifié, ["serving_default"] est utilisé. - quantization_method: méthode de quantification à appliquer. Si aucune valeur n'est spécifiée, la quantification
STATIC_RANGEest appliquée. - op_set: doit être conservé en tant que XLA. Il s'agit actuellement de l'option par défaut. Vous n'avez pas besoin de la spécifier.
- representative_datasets: spécifiez l'ensemble de données utilisé pour calibrer les paramètres de quantification.
Créer l'ensemble de données représentatif
Un ensemble de données représentatif est essentiellement un itérable d'échantillons.
Un échantillon est une carte de: {input_key: input_value}. Exemple :
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
Les ensembles de données représentatifs doivent être enregistrés en tant que fichiers TFRecord à l'aide de la classe TfRecordRepresentativeDatasetSaver actuellement disponible dans le package pip tf-nightly. Exemple :
# Assumed tf-nightly installed.
import tensorflow as tf
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
tf.quantization.experimental.TfRecordRepresentativeDatasetSaver(
path_map={'serving_default': '/tmp/representative_dataset_path'}
).save({'serving_default': representative_dataset})
Examples
L'exemple suivant effectue une quantification du modèle avec la clé de signature serving_default et l'alias de fonction tpu_func:
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' \ tpu_functions { \ function_alias: "tpu_func" \ } \ external_feature_configs { \ quantization_options { \ signature_keys: "serving_default" \ representative_datasets: { \ key: "serving_default" \ value: { \ tfrecord_file_path: "${TF_RECORD_FILE}" \ } \ } \ } \ } '
Ajouter le traitement par lot
Le convertisseur peut être utilisé pour ajouter le traitement par lot à un modèle. Pour obtenir une description des options de traitement par lot pouvant être affinées, consultez la section Définition des options de traitement par lot.
Par défaut, le convertisseur regroupe toutes les fonctions TPU du modèle. Il peut également traiter par lot les signatures et les fonctions fournies par l'utilisateur, ce qui peut améliorer davantage les performances. Toute fonction TPU, fonction fournie par l'utilisateur ou signature groupée doit respecter les exigences strictes de forme de l'opération de traitement par lot.
Le convertisseur peut également mettre à jour les options de traitement par lot existantes. Voici un exemple d'ajout de traitement par lot à un modèle. Pour en savoir plus sur le traitement par lot, consultez la section Présentation détaillée du traitement par lot.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
Désactiver les optimisations bfloat16 et de forme d'E/S
Les optimisations BFloat16 et de forme d'E/S sont activées par défaut. Si elles ne fonctionnent pas correctement avec votre modèle, vous pouvez les désactiver.
# Disable both optimizations disable_default_optimizations: true # Or disable them individually io_shape_optimization: DISABLED bfloat16_optimization: DISABLED
Rapport sur les conversions
Vous pouvez trouver ce rapport sur les conversions dans le journal après avoir exécuté le convertisseur d'inférence. Vous trouverez un exemple ci-dessous.
-------- Conversion Report -------- TPU cost of the model: 96.67% (2034/2104) CPU cost of the model: 3.33% (70/2104) Cost breakdown ================================ % Cost Name -------------------------------- 3.33 70 [CPU cost] 48.34 1017 tpu_func_1 48.34 1017 tpu_func_2 --------------------------------
Ce rapport estime le coût de calcul du modèle de sortie sur le processeur et le TPU, et détaille le coût du TPU pour chaque fonction, qui devrait refléter votre sélection des fonctions TPU dans les options du convertisseur.
Si vous souhaitez mieux utiliser le TPU, vous pouvez tester la structure du modèle et ajuster les options du convertisseur.
Questions fréquentes
Quelle(s) fonction(s) dois-je placer sur le TPU ?
Il est préférable de placer autant que possible votre modèle sur le TPU, car la grande majorité des opérations s'exécutent plus rapidement sur le TPU.
Si votre modèle ne contient aucune opération, chaîne ni tenseur clairsemé incompatible avec le TPU, la meilleure stratégie consiste généralement à placer l'ensemble du modèle sur le TPU. Pour ce faire, recherchez ou créez une fonction qui encapsule l'ensemble du modèle, créez un alias de fonction pour celle-ci, puis transmettez-le au convertisseur.
Si votre modèle contient des parties qui ne peuvent pas fonctionner sur le TPU (par exemple, des opérations, des chaînes ou des tenseurs épars incompatibles avec le TPU), le choix des fonctions TPU dépend de l'emplacement de la partie incompatible.
- S'il se trouve au début ou à la fin du modèle, vous pouvez le refactoriser pour le conserver sur le processeur. Il peut s'agir, par exemple, des étapes de pré- et post-traitement des chaînes. Pour en savoir plus sur le transfert de code vers le processeur, consultez la section "Comment transférer une partie du modèle vers le processeur ?". Il montre une façon typique de refactoriser le modèle.
- S'il se trouve au milieu du modèle, il est préférable de le diviser en trois parties et de placer toutes les opérations incompatibles avec le TPU dans la partie centrale, puis de l'exécuter sur le processeur.
- S'il s'agit d'un tenseur à valeurs dispersées, envisagez d'appeler
tf.sparse.to_densesur le processeur et de transmettre le tenseur dense obtenu à la partie TPU du modèle.
Un autre facteur à prendre en compte est l'utilisation de la mémoire HBM. L'intégration de tableaux peut utiliser beaucoup de HBM. Si elles dépassent la limite matérielle du TPU, elles doivent être placées sur le processeur, ainsi que les opérations de recherche.
Dans la mesure du possible, une seule fonction TPU doit exister sous une seule signature. Si la structure de votre modèle nécessite d'appeler plusieurs fonctions TPU par requête d'inférence entrante, vous devez tenir compte de la latence supplémentaire liée à l'envoi de tenseurs entre le processeur et le TPU.
Un bon moyen d'évaluer la sélection des fonctions TPU consiste à consulter le rapport sur les conversions. Il indique le pourcentage de calcul effectué sur le TPU et le détail du coût de chaque fonction TPU.
Comment déplacer une partie du modèle vers le processeur ?
Si votre modèle contient des parties qui ne peuvent pas être diffusées sur le TPU, vous devez le refactoriser pour les déplacer vers le processeur. Voici un exemple fictif. Il s'agit d'un modèle de langage avec une étape de prétraitement. Par souci de simplicité, le code des définitions et des fonctions de calque est omis.
class LanguageModel(tf.keras.Model): @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.bert_layer(word_ids)
Ce modèle ne peut pas être diffusé directement sur le TPU pour deux raisons. Tout d'abord, le paramètre est une chaîne. Deuxièmement, la fonction preprocess peut contenir de nombreuses opérations de chaîne. Les deux ne sont pas compatibles avec les TPU.
Pour refactoriser ce modèle, vous pouvez créer une autre fonction appelée tpu_func pour héberger la bert_layer intensive en calcul. Créez ensuite un alias de fonction pour tpu_func et transmettez-le au convertisseur. De cette manière, tout ce qui se trouve dans tpu_func s'exécute sur le TPU, et tout ce qui reste dans model_func s'exécute sur le processeur.
class LanguageModel(tf.keras.Model): @tf.function def tpu_func(self, word_ids): return self.bert_layer(word_ids) @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.tpu_func(word_ids)
Que dois-je faire si le modèle contient des opérations, des chaînes ou des tenseurs à valeurs dispersées incompatibles avec TPU ?
La plupart des opérations TensorFlow standards sont compatibles avec le TPU, mais certaines, y compris les tenseurs et les chaînes sporadiques, ne le sont pas. Le convertisseur ne recherche pas les opérations incompatibles avec TPU. Par conséquent, un modèle contenant de telles opérations peut transmettre la conversion. Toutefois, lorsque vous l'exécutez pour l'inférence, des erreurs comme celles ci-dessous se produisent.
'tf.StringToNumber' op isn't compilable for TPU device.
Si votre modèle comporte des opérations incompatibles avec le TPU, elles doivent être placées en dehors de la fonction TPU. De plus, les chaînes ne sont pas un format de données compatible avec le TPU. Par conséquent, les variables de type chaîne ne doivent pas être placées dans la fonction TPU. Les paramètres et les valeurs renvoyées de la fonction TPU ne doivent pas non plus être de type chaîne. De même, évitez de placer des tenseurs épars dans la fonction TPU, y compris dans ses paramètres et valeurs de retour.
Il n'est généralement pas difficile de refactoriser la partie incompatible du modèle et de la déplacer vers le processeur. Voici un exemple.
Comment prendre en charge les opérations personnalisées dans le modèle ?
Si des opérations personnalisées sont utilisées dans votre modèle, le convertisseur risque de ne pas les reconnaître et de ne pas réussir à convertir le modèle. En effet, la bibliothèque d'opérations de l'opération personnalisée, qui contient la définition complète de l'opération, n'est pas associée au convertisseur.
Comme le code du convertisseur n'est pas encore Open Source, il ne peut pas être compilé avec une opération personnalisée.
Que dois-je faire si j'ai un modèle TensorFlow 1 ?
Le convertisseur n'est pas compatible avec les modèles TensorFlow 1. Les modèles TensorFlow 1 doivent être migrés vers TensorFlow 2.
Dois-je activer le pont MLIR lorsque j'exécute mon modèle ?
La plupart des modèles convertis peuvent être exécutés avec le nouveau pont MLIR TF2XLA ou le pont TF2XLA d'origine.
Comment convertir un modèle déjà exporté sans alias de fonction ?
Si un modèle a été exporté sans alias de fonction, le moyen le plus simple est de l'exporter à nouveau et de créer un alias de fonction.
Si la réexportation n'est pas possible, vous pouvez toujours convertir le modèle en fournissant un concrete_function_name. Toutefois, l'identification de la concrete_function_name appropriée nécessite un peu de travail d'enquête.
Les alias de fonction sont un mappage d'une chaîne définie par l'utilisateur à un nom de fonction concret. Ils permettent de faire référence plus facilement à une fonction spécifique du modèle. Le convertisseur accepte à la fois les alias de fonction et les noms de fonction concrets bruts.
Vous pouvez trouver les noms de fonction concrets en examinant le saved_model.pb.
L'exemple suivant montre comment placer une fonction concrète appelée __inference_serve_24 sur le TPU.
sudo docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { concrete_function_name: "__inference_serve_24" }'
Comment résoudre une erreur de contrainte de constante au moment de la compilation ?
Pour l'entraînement et l'inférence, XLA exige que les entrées de certaines opérations aient une forme connue au moment de la compilation du TPU. Cela signifie que lorsque XLA compile la partie TPU du programme, les entrées de ces opérations doivent avoir une forme connue de manière statique.
Il existe deux façons de résoudre ce problème.
- La meilleure option consiste à mettre à jour les entrées de l'opération pour disposer d'une forme connue de manière statique au moment où XLA compile le programme TPU. Cette compilation a lieu juste avant l'exécution de la partie TPU du modèle. Cela signifie que la forme doit être connue de manière statique au moment où
TpuFunctionest sur le point d'être exécuté. - Vous pouvez également modifier
TpuFunctionpour ne plus inclure l'opération problématique.
Pourquoi une erreur de forme de traitement par lot s'affiche-t-elle ?
Le traitement par lot est soumis à des exigences de forme strictes qui permettent de regrouper les requêtes entrantes selon leur dimension 0 (également appelée dimension de traitement par lot). Ces exigences de forme proviennent de l'opération de traitement par lot TensorFlow et ne peuvent pas être assouplies.
Le non-respect de ces exigences entraînera des erreurs telles que:
- Les tenseurs d'entrée groupés doivent comporter au moins une dimension.
- Les dimensions des entrées doivent correspondre.
- Les tenseurs d'entrée groupés fournis dans une invocation d'opération donnée doivent avoir une taille de dimension 0 égale.
- La dimension 0 du tenseur de sortie groupé ne correspond pas à la somme des tailles de dimension 0 des tenseurs d'entrée.
Pour répondre à ces exigences, envisagez de fournir une fonction ou une signature différente au lot. Vous devrez peut-être également modifier les fonctions existantes pour répondre à ces exigences.
Si une fonction est groupée par lot, assurez-vous que toutes les formes de la signature d'entrée de @tf.function sont None dans la dimension 0. Si une signature est groupée, assurez-vous que toutes ses entrées ont la valeur -1 dans la dimension 0.
Pour une explication complète de la raison pour laquelle ces erreurs se produisent et de la façon de les résoudre, consultez Plongée dans le traitement par lot.
Problèmes connus
La fonction TPU ne peut pas appeler indirectement une autre fonction TPU
Bien que le convertisseur puisse gérer la plupart des scénarios d'appel de fonction au niveau de la limite CPU-TPU, il existe un cas rare où il échoue. Il s'agit d'une fonction TPU qui appelle indirectement une autre fonction TPU.
En effet, le convertisseur modifie l'appelant direct d'une fonction TPU, qui passe de l'appel de la fonction TPU elle-même à l'appel d'un bouchon d'appel TPU. Le bouchon d'appel contient des opérations qui ne peuvent fonctionner que sur le processeur. Lorsqu'une fonction TPU appelle une fonction qui appelle finalement l'appelant direct, ces opérations de processeur peuvent être exécutées sur le TPU, ce qui génère des erreurs de kernel manquantes. Notez que ce cas est différent d'une fonction TPU qui appelle directement une autre fonction TPU. Dans ce cas, le convertisseur ne modifie aucune fonction pour appeler le bouchon d'appel. Il peut donc fonctionner.
Dans le convertisseur, nous avons implémenté la détection de ce scénario. Si l'erreur suivante s'affiche, cela signifie que votre modèle a rencontré ce cas limite:
Unable to place both "__inference_tpu_func_2_46" and "__inference_tpu_func_4_68" on the TPU because "__inference_tpu_func_2_46" indirectly calls "__inference_tpu_func_4_68". This behavior is unsupported because it can cause invalid graphs to be generated.
La solution générale consiste à refactoriser le modèle pour éviter un tel scénario d'appel de fonction. Si vous ne parvenez pas à le faire, contactez l'équipe d'assistance Google pour en savoir plus.
Référence
Options de convertisseur au format Protobuf
message ConverterOptions { // TPU conversion options. repeated TpuFunction tpu_functions = 1; // The state of an optimization. enum State { // When state is set to default, the optimization will perform its // default behavior. For some optimizations this is disabled and for others // it is enabled. To check a specific optimization, read the optimization's // description. DEFAULT = 0; // Enabled. ENABLED = 1; // Disabled. DISABLED = 2; } // Batch options to apply to the TPU Subgraph. // // At the moment, only one batch option is supported. This field will be // expanded to support batching on a per function and/or per signature basis. // // // If not specified, no batching will be done. repeated BatchOptions batch_options = 100; // Global flag to disable all optimizations that are enabled by default. // When enabled, all optimizations that run by default are disabled. If a // default optimization is explicitly enabled, this flag will have no affect // on that optimization. // // This flag defaults to false. bool disable_default_optimizations = 202; // If enabled, apply an optimization that reshapes the tensors going into // and out of the TPU. This reshape operation improves performance by reducing // the transfer time to and from the TPU. // // This optimization is incompatible with input_shape_opt which is disabled. // by default. If input_shape_opt is enabled, this option should be // disabled. // // This optimization defaults to enabled. State io_shape_optimization = 200; // If enabled, apply an optimization that updates float variables and float // ops on the TPU to bfloat16. This optimization improves performance and // throughtput by reducing HBM usage and taking advantage of TPU support for // bfloat16. // // This optimization may cause a loss of accuracy for some models. If an // unacceptable loss of accuracy is detected, disable this optimization. // // This optimization defaults to enabled. State bfloat16_optimization = 201; BFloat16OptimizationOptions bfloat16_optimization_options = 203; // The settings for XLA sharding. If set, XLA sharding is enabled. XlaShardingOptions xla_sharding_options = 204; } message TpuFunction { // The function(s) that should be placed on the TPU. Only provide a given // function once. Duplicates will result in errors. For example, if // you provide a specific function using function_alias don't also provide the // same function via concrete_function_name or jit_compile_functions. oneof name { // The name of the function alias associated with the function that // should be placed on the TPU. Function aliases are created during model // export using the tf.saved_model.SaveOptions. // // This is a recommended way to specify which function should be placed // on the TPU. string function_alias = 1; // The name of the concrete function that should be placed on the TPU. This // is the name of the function as it found in the GraphDef and the // FunctionDefLibrary. // // This is NOT the recommended way to specify which function should be // placed on the TPU because concrete function names change every time a // model is exported. string concrete_function_name = 3; // The name of the signature to be placed on the TPU. The user must make // sure there is no TPU-incompatible op under the entire signature. string signature_name = 5; // When jit_compile_functions is set to True, all jit compiled functions // are placed on the TPU. // // To use this option, decorate the relevant function(s) with // @tf.function(jit_compile=True), before exporting. Then set this flag to // True. The converter will find all functions that were tagged with // jit_compile=True and place them on the TPU. // // When using this option, all other settings for the TpuFunction // will apply to all functions tagged with // jit_compile=True. // // This option will place all jit_compile=True functions on the TPU. // If only some jit_compile=True functions should be placed on the TPU, // use function_alias or concrete_function_name. bool jit_compile_functions = 4; } } message BatchOptions { // Number of scheduling threads for processing batches of work. Determines // the number of batches processed in parallel. This should be roughly in line // with the number of TPU cores available. int32 num_batch_threads = 1; // The maximum allowed batch size. int32 max_batch_size = 2; // Maximum number of microseconds to wait before outputting an incomplete // batch. int32 batch_timeout_micros = 3; // Optional list of allowed batch sizes. If left empty, // does nothing. Otherwise, supplies a list of batch sizes, causing the op // to pad batches up to one of those sizes. The entries must increase // monotonically, and the final entry must equal max_batch_size. repeated int32 allowed_batch_sizes = 4; // Maximum number of batches enqueued for processing before requests are // failed fast. int32 max_enqueued_batches = 5; // If set, disables large batch splitting which is an efficiency improvement // on batching to reduce padding inefficiency. bool disable_large_batch_splitting = 6; // Experimental features of batching. Everything inside is subject to change. message Experimental { // The component to be batched. // 1. Unset if it's for all TPU subgraphs. // 2. Set function_alias or concrete_function_name if it's for a function. // 3. Set signature_name if it's for a signature. oneof batch_component { // The function alias associated with the function. Function alias is // created during model export using the tf.saved_model.SaveOptions, and is // the recommended way to specify functions. string function_alias = 1; // The concreate name of the function. This is the name of the function as // it found in the GraphDef and the FunctionDefLibrary. This is NOT the // recommended way to specify functions, because concrete function names // change every time a model is exported. string concrete_function_name = 2; // The name of the signature. string signature_name = 3; } } Experimental experimental = 7; } message BFloat16OptimizationOptions { // Indicates where the BFloat16 optimization should be applied. enum Scope { // The scope currently defaults to TPU. DEFAULT = 0; // Apply the bfloat16 optimization to TPU computation. TPU = 1; // Apply the bfloat16 optimization to the entire model including CPU // computations. ALL = 2; } // This field indicates where the bfloat16 optimization should be applied. // // The scope defaults to TPU. Scope scope = 1; // If set, the normal safety checks are skipped. For example, if the model // already contains bfloat16 ops, the bfloat16 optimization will error because // pre-existing bfloat16 ops can cause issues with the optimization. By // setting this flag, the bfloat16 optimization will skip the check. // // This is an advanced feature and not recommended for almost all models. // // This flag is off by default. bool skip_safety_checks = 2; // Ops that should not be converted to bfloat16. // Inputs into these ops will be cast to float32, and outputs from these ops // will be cast back to bfloat16. repeated string filterlist = 3; } message XlaShardingOptions { // num_cores_per_replica for TPUReplicateMetadata. // // This is the number of cores you wish to split your model into using XLA // SPMD. int32 num_cores_per_replica = 1; // (optional) device_assignment for TPUReplicateMetadata. // // This is in a flattened [x, y, z, core] format (for // example, core 1 of the chip // located in 2,3,0 will be stored as [2,3,0,1]). // // If this is not specified, then the device assignments will utilize the same // topology as specified in the topology attribute. repeated int32 device_assignment = 2; // A serialized string of tensorflow.tpu.TopologyProto objects, used for // the topology attribute in TPUReplicateMetadata. // // You must specify the mesh_shape and device_coordinates attributes in // the topology object. // // This option is required for num_cores_per_replica > 1 cases due to // ambiguity of num_cores_per_replica, for example, // pf_1x2x1 with megacore and df_1x1 // both have num_cores_per_replica = 2, but topology is (1,2,1,1) for pf and // (1,1,1,2) for df. // - For pf_1x2x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,2,1,1] // device_coordinates=flatten([0,0,0,0], [0,1,0,0]) // - For df_1x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,1,1,2] // device_coordinates=flatten([0,0,0,0], [0,0,0,1]) // - For df_2x2, mesh shape and device_coordinates looks like: // mesh_shape = [2,2,1,2] // device_coordinates=flatten( // [0,0,0,0],[0,0,0,1],[0,1,0,0],[0,1,0,1] // [1,0,0,0],[1,0,0,1],[1,1,0,0],[1,1,0,1]) bytes topology = 3; }
Analyse approfondie du traitement par lot
Le traitement par lots permet d'améliorer le débit et l'utilisation des TPU. Il permet de traiter plusieurs requêtes en même temps. Pendant l'entraînement, le traitement par lot peut être effectué à l'aide de tf.data. Lors de l'inférence, cela se fait généralement en ajoutant une opération dans le graphique qui regroupe les requêtes entrantes. L'opération attend d'avoir suffisamment de requêtes ou qu'un délai d'expiration soit atteint avant de générer un grand lot à partir des requêtes individuelles. Pour en savoir plus sur les différentes options de traitement par lot pouvant être affinées, y compris les tailles de lot et les délais avant expiration, consultez la section Définition des options de traitement par lot.
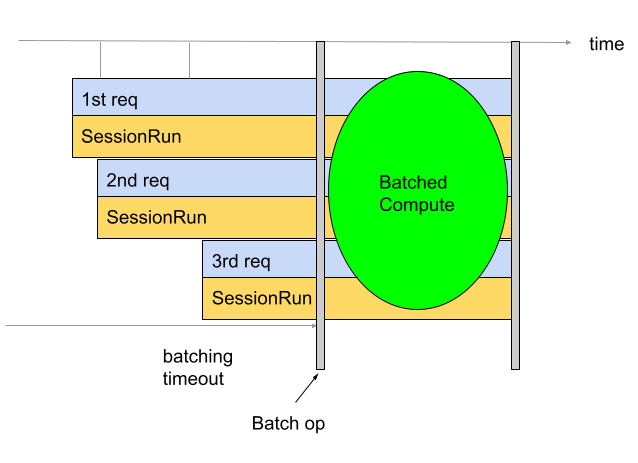
Par défaut, le convertisseur insère l'opération de traitement par lot juste avant le calcul du TPU. Il encapsule les fonctions TPU fournies par l'utilisateur et tout calcul TPU préexistant dans le modèle avec des opérations de traitement par lot. Vous pouvez remplacer ce comportement par défaut en indiquant au convertisseur les fonctions et/ou les signatures à traiter par lot.
L'exemple suivant montre comment ajouter le traitement par lot par défaut.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
Traitement des signatures par lots
Le traitement par lot de signature regroupe l'ensemble du modèle à partir des entrées de la signature et jusqu'aux sorties de la signature. Contrairement au comportement par défaut de traitement par lot du convertisseur, le traitement par lot des signatures regroupe à la fois le calcul TPU et le calcul CPU. Cela permet d'obtenir un gain de performances de 10 à 20 % lors de l'inférence sur certains modèles.
Comme pour tous les traitements par lot, le traitement par lot des signatures est soumis à des exigences strictes concernant la forme.
Pour vous assurer que ces exigences de forme sont respectées, les entrées de signature doivent avoir au moins deux dimensions. La première dimension est la taille de lot et doit être de -1. Par exemple, (-1, 4), (-1) ou (-1,
128, 4, 10) sont toutes des formes d'entrée valides. Si ce n'est pas possible, envisagez d'utiliser le comportement de traitement par lot par défaut ou le traitement par lot de fonctions.
Pour utiliser le traitement par lot de signatures, indiquez le ou les noms de signature en tant que signature_name à l'aide de BatchOptions.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { signature_name: "serving_default" } }
Traitement par lot des fonctions
Le traitement par lot de fonctions permet d'indiquer au convertisseur la ou les fonctions à traiter par lot. Par défaut, le convertisseur traite toutes les fonctions TPU par lot. Le traitement par lot de fonctions remplace ce comportement par défaut.
Le traitement par lot de fonctions peut être utilisé pour effectuer des calculs de CPU par lot. De nombreux modèles enregistrent une amélioration des performances lorsque leur calcul de processeur est groupé. Le meilleur moyen de traiter des calculs de processeur par lot consiste à utiliser le traitement par lot de signature. Toutefois, il est possible que cela ne fonctionne pas pour certains modèles. Dans ce cas, le traitement par lot de fonctions peut être utilisé pour effectuer un traitement par lot d'une partie du calcul du processeur en plus du calcul du TPU. Notez que l'opération de traitement par lot ne peut pas s'exécuter sur le TPU. Par conséquent, toute fonction de traitement par lot fournie doit être appelée sur le processeur.
Le traitement par lot de fonctions peut également être utilisé pour répondre aux exigences strictes de forme imposées par l'opération de traitement par lot. Lorsque la ou les fonctions TPU ne répondent pas aux exigences de forme de l'opération de traitement par lot, le traitement par lot de fonctions peut être utilisé pour indiquer au convertisseur de traiter par lot différentes fonctions.
Pour utiliser cette fonctionnalité, générez un function_alias pour la fonction à traiter par lot. Pour ce faire, recherchez ou créez une fonction dans votre modèle qui encapsule tout ce que vous souhaitez traiter par lot. Assurez-vous que cette fonction respecte les exigences strictes concernant la forme imposées par l'opération de traitement par lot. Ajoutez @tf.function si elle n'en contient pas déjà un.
Il est important de fournir le input_signature au @tf.function. La dimension 0 doit être None, car il s'agit de la dimension de lot. Elle ne peut donc pas avoir une taille fixe. Par exemple, [None, 4], [None] ou [None, 128, 4, 10] sont toutes des formes d'entrée valides. Lorsque vous enregistrez le modèle, fournissez des SaveOptions comme ceux indiqués ci-dessous pour attribuer à model.batch_func un alias "batch_func". Vous pouvez ensuite transmettre cet alias de fonction au convertisseur.
class ToyModel(tf.keras.Model): @tf.function(input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def batch_func(self, x): return x * 1.0 ... model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'batch_func': model.batch_func, }) tf.saved_model.save(model, model_dir, options=save_options)
Transmettez ensuite le ou les function_alias à l'aide de BatchOptions.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { function_alias: "batch_func" } }
Définition des options de traitement par lots
num_batch_threads: (entier) Nombre de threads de planification pour le traitement des lots de travail. Détermine le nombre de lots traités en parallèle. Ce nombre devrait correspondre à peu près au nombre de cœurs de TPU disponibles.max_batch_size: (entier) Taille maximale de lot autorisée. Peut être plus grand queallowed_batch_sizespour utiliser la division de lots de grande taille.batch_timeout_micros: (entier) Nombre maximal de microsecondes à attendre avant d'afficher un lot incomplet.allowed_batch_sizes: (liste d'entiers) Si la liste n'est pas vide, elle ajoute des éléments à la taille la plus proche de la liste. La liste doit être croissante et l'élément final doit être inférieur ou égal àmax_batch_size.max_enqueued_batches: (entier) Nombre maximal de lots mis en file d'attente pour traitement avant que les requêtes ne soient rapidement refusées.
Mettre à jour les options de traitement par lots existantes
Vous pouvez ajouter ou mettre à jour des options de traitement par lot en exécutant l'image Docker en spécifiant batch_options et en définissant disable_default_optimizations sur "true" à l'aide de l'option --converter_options_string. Les options de traitement par lot seront appliquées à chaque fonction TPU ou opération de traitement par lot préexistante.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } disable_default_optimizations=True
Exigences concernant la forme de la fonctionnalité de traitement par lot
Les lots sont créés en concatenant les tenseurs d'entrée pour toutes les requêtes le long de leur dimension de lot (0). Les tenseurs de sortie sont divisés le long de leur dimension 0. Pour effectuer ces opérations, l'opération de traitement par lot présente des exigences de forme strictes pour ses entrées et ses sorties.
Tutoriel
Pour comprendre ces exigences, il est utile de commencer par comprendre comment le traitement par lot est effectué. Dans l'exemple ci-dessous, nous effectuons un traitement par lot d'une opération tf.matmul simple.
def my_func(A, B) return tf.matmul(A, B)
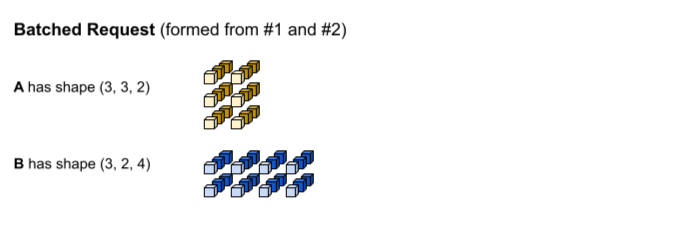
La première requête d'inférence produit les entrées A et B avec les formes (1, 3,
2) et (1, 2, 4), respectivement. La deuxième requête d'inférence produit les entrées A et B avec les formes (2, 3, 2) et (2, 2, 4).

Le délai avant expiration de la mise en lot est atteint. Le modèle accepte une taille de lot de trois, de sorte que les requêtes d'inférence 1 et 2 soient regroupées sans remplissage. Les tenseurs groupés sont formés en concatenant les requêtes 1 et 2 le long de la dimension de lot (0). Étant donné que l'élément A de l'élément 1 a la forme (1, 3, 2) et que l'élément A de l'élément 2 a la forme (2, 3, 2), lorsqu'ils sont concatenatés le long de la dimension de lot (0), la forme obtenue est (3, 3, 2).
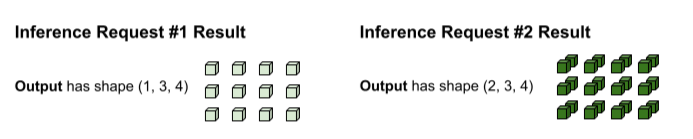
tf.matmul est exécuté et génère une sortie de forme (3, 3,
4).

La sortie de tf.matmul est groupée par lot. Elle doit donc être divisée en requêtes distinctes. L'opération de traitement par lot procède à une division selon la dimension de lot (0) de chaque tenseur de sortie. Il décide de la manière de diviser la dimension 0 en fonction de la forme des entrées d'origine. Étant donné que les formes de la requête 1 ont une dimension 0 de 1, sa sortie a une dimension 0 de 1 pour une forme de (1, 3, 4).
Étant donné que les formes de la requête 2 ont une dimension 0 de 2, sa sortie a une dimension 0 de 2 pour une forme de (2, 3, 4).
Exigences concernant les formes
Pour effectuer la concaténation des entrées et la division des sorties décrites ci-dessus, l'opération de traitement par lot doit respecter les exigences de forme suivantes:
Les entrées de traitement par lot ne peuvent pas être des scalaires. Pour pouvoir effectuer une concaténation le long de la dimension 0, les tenseurs doivent avoir au moins deux dimensions.
Dans la procédure ci-dessus. Ni A ni B ne sont des scalaires.
Si vous ne respectez pas cette exigence, une erreur de type
Batching input tensors must have at least one dimensions'affichera. Pour corriger simplement cette erreur, faites du scalaire un vecteur.Pour différentes requêtes d'inférence (par exemple, différentes invocations d'exécution de session), les tenseurs d'entrée portant le même nom ont la même taille pour chaque dimension, à l'exception de la dimension 0. Cela permet de concatenater proprement les entrées le long de leur dimension 0.
Dans la procédure ci-dessus, la réponse A de la requête 1 a la forme
(1, 3, 2). Cela signifie que toute future requête doit produire une forme avec le motif(X, 3, 2). La demande 2 répond à cette exigence avec(2, 3, 2). De même, la forme de la requête 1 est(1, 2, 4). Par conséquent, toutes les futures requêtes doivent produire une forme avec le motif(X, 2, 4).Si vous ne respectez pas cette exigence, une erreur de type
Dimensions of inputs should matchs'affichera.Pour une requête d'inférence donnée, toutes les entrées doivent avoir la même taille de dimension 0. Si les différentes dimensions 0 des différents tensors d'entrée de l'opération de traitement par lot sont différentes, l'opération de traitement par lot ne sait pas comment diviser les tensors de sortie.
Dans la procédure ci-dessus, la taille de la dimension 0 des tenseurs de la requête 1 est de 1. Cela permet à l'opération de traitement par lot de savoir que sa sortie doit avoir une taille de dimension 0 de 1. De même, les tenseurs de la requête 2 ont une taille de dimension 0 de 2. Par conséquent, leur sortie aura une taille de dimension 0 de 2. Lorsque l'opération de traitement par lot divise la forme finale de
(3, 3, 4), elle produit(1, 3, 4)pour la requête 1 et(2, 3, 4)pour la requête 2.Si vous ne respectez pas cette exigence, des erreurs telles que
Batching input tensors supplied in a given op invocation must have equal 0th-dimension sizes'afficheront.La taille de la dimension 0 de la forme de chaque tenseur de sortie doit être la somme de la taille de la dimension 0 de tous les tenseurs d'entrée (plus tout remplissage introduit par l'opération de mise en lot pour répondre à la
allowed_batch_sizela plus grande suivante). Cela permet à l'opération de mise en lot de diviser les tenseurs de sortie selon leur dimension 0 en fonction de la dimension 0 des tenseurs d'entrée.Dans la procédure ci-dessus, la dimension 0 des tenseurs d'entrée est de 1 pour la requête 1 et de 2 pour la requête 2. Par conséquent, chaque tenseur de sortie doit avoir une dimension 0 de 3, car 1 + 2=3. Le tenseur de sortie
(3, 3, 4)répond à cette exigence. Si 3 n'était pas une taille de lot valide, mais que 4 l'était, l'opération de traitement par lot aurait dû rembourrer la 0e dimension des entrées de 3 à 4. Dans ce cas, chaque tenseur de sortie doit avoir une taille de dimension 0 de 4.Si vous ne respectez pas cette exigence, une erreur de type
Batched output tensor's 0th dimension does not equal the sum of the 0th dimension sizes of the input tensorss'affichera.
Résoudre les erreurs liées aux exigences de forme
Pour répondre à ces exigences, envisagez de fournir une fonction ou une signature différente au lot. Vous devrez peut-être également modifier les fonctions existantes pour répondre à ces exigences.
Si une fonction est traitée par lot, assurez-vous que toutes les formes de la signature d'entrée de @tf.function contiennent None dans la dimension 0 (également appelée dimension de lot). Si une signature est groupée, assurez-vous que toutes ses entrées ont la valeur -1 dans la dimension 0.
L'opération BatchFunction n'accepte pas SparseTensors comme entrée ou sortie.
En interne, chaque tenseur à valeurs dispersées est représenté par trois tenseurs distincts pouvant avoir des tailles de dimension 0 différentes.