Einführung in den Cloud TPU v5e-Inferenzkonverter
Einführung
Der Cloud TPU-Inferenzkonverter bereitet ein TensorFlow 2-Modell (TF2) für die TPU-Inferenz vor und optimiert es. Der Konverter wird in einer lokalen oder TPU-VM-Shell ausgeführt. Die TPU VM-Shell wird empfohlen, da sie die für den Konverter erforderlichen Befehlszeilentools bereits vorinstalliert hat. Es nimmt ein exportiertes SavedModel und führt die folgenden Schritte aus:
- TPU-Konvertierung: Dem Modell werden
TPUPartitionedCallund andere TPU-Vorgänge hinzugefügt, damit es auf der TPU ausgeführt werden kann. Standardmäßig enthält ein Modell, das für die Inferenz exportiert wurde, keine solchen Vorgänge und kann nicht auf der TPU bereitgestellt werden, auch wenn es auf der TPU trainiert wurde. - Batchverarbeitung: Dem Modell werden Batch-Vorgänge hinzugefügt, um die In-Graph-Batchverarbeitung zu ermöglichen und so den Durchsatz zu verbessern.
- BFloat16-Konvertierung: Das Datenformat des Modells wird von
float32inbfloat16konvertiert, um die Rechenleistung zu verbessern und die HBM-Nutzung (High Bandwidth Memory) auf der TPU zu senken. - IO-Shape-Optimierung: Hiermit werden die Tensorformen für Daten optimiert, die zwischen der CPU und der TPU übertragen werden, um die Bandbreitennutzung zu verbessern.
Beim Exportieren eines Modells erstellen Nutzer Funktionsaliasse für alle Funktionen, die auf der TPU ausgeführt werden sollen. Diese Funktionen werden an den Converter übergeben, der sie auf der TPU platziert und optimiert.
Der Cloud TPU-Inferenzkonverter ist als Docker-Image verfügbar, das in jeder Umgebung ausgeführt werden kann, in der Docker installiert ist.
Geschätzte Dauer für die oben genannten Schritte: 20–30 Minuten
Vorbereitung
- Das Modell muss ein TF2-Modell sein und im SavedModel-Format exportiert werden.
- Das Modell muss einen Funktionsalias für die TPU-Funktion haben. Eine Anleitung dazu finden Sie im Codebeispiel. In den folgenden Beispielen wird
tpu_funcals Alias der TPU-Funktion verwendet. - Die CPU Ihres Computers muss AVX-Anweisungen (Advanced Vector Extensions) unterstützen, da die TensorFlow-Bibliothek (die Abhängigkeit des Cloud TPU-Inferenzkonverters) für die Verwendung von AVX-Anweisungen kompiliert wird.
AVX wird von den meisten CPUs unterstützt.
- Mit
lscpu | grep avxkönnen Sie prüfen, ob der AVX-Instruction-Set unterstützt wird.
- Mit
Hinweis
Führen Sie vor der Einrichtung die folgenden Schritte aus:
Neues Projekt erstellen: Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Cloud-Projekt aus oder erstellen Sie eines.
TPU-VM einrichten: Sie können eine neue TPU-VM über die Google Cloud Console oder
gclouderstellen oder eine vorhandene TPU-VM verwenden, um die Inferenz mit dem umgewandelten Modell auf der TPU-VM auszuführen.- Das TPU-VM-Image muss auf TensorFlow basieren. Beispiel:
--version=tpu-vm-tf-2.11.0. - Das konvertierte Modell wird auf dieser TPU-VM geladen und bereitgestellt.
- Das TPU-VM-Image muss auf TensorFlow basieren. Beispiel:
Sie benötigen die Befehlszeilentools, die Sie für die Verwendung des Cloud TPU-Inferenzkonverters benötigen. Sie können das Google Cloud SDK und Docker lokal installieren oder eine TPU-VM verwenden, auf der diese Software standardmäßig installiert ist. Mit diesen Tools können Sie mit dem Converter-Bild interagieren.
Stellen Sie mit dem folgenden Befehl eine SSH-Verbindung zur Instanz her:
gcloud compute tpus tpu-vm ssh ${tpu-name} --zone ${zone} --project ${project-id}
Umgebung einrichten
Richten Sie die Umgebung über die Shell Ihrer TPU-VM oder über die lokale Shell ein.
TPU VM-Shell
Führen Sie in der TPU-VM-Shell die folgenden Befehle aus, um die Docker-Nutzung für nicht-root-Nutzer zuzulassen:
sudo usermod -a -G docker ${USER} newgrp docker
Initialisieren Sie Ihre Docker Credential Helper:
gcloud auth configure-docker \ us-docker.pkg.dev
Lokale Shell
Richten Sie die Umgebung in Ihrer lokalen Shell mit den folgenden Schritten ein:
Installieren Sie das Cloud SDK. Das
gcloud-Befehlszeilentool ist dort enthalten.Installieren Sie Docker:
Docker-Nutzung für Nutzer ohne Root-Berechtigung zulassen:
sudo usermod -a -G docker ${USER} newgrp docker
Melden Sie sich in Ihrer Umgebung an:
gcloud auth login
Initialisieren Sie Ihre Docker Credential Helper:
gcloud auth configure-docker \ us-docker.pkg.dev
Rufen Sie das Docker-Image des Inference Converters ab:
CONVERTER_IMAGE=us-docker.pkg.dev/cloud-tpu-images/inference/tpu-inference-converter-cli:2.13.0 docker pull ${CONVERTER_IMAGE}
Bild des Konverters
Das Bild dient einmaligen Modellkonvertierungen. Legen Sie die Modellpfade fest und passen Sie die Konvertierungsoptionen an Ihre Anforderungen an. Im Abschnitt Beispiele für die Verwendung finden Sie einige gängige Anwendungsfälle.
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { function_alias: "tpu_func" } batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } '
Inferenzen mit dem konvertierten Modell in der TPU-VM
# Initialize the TPU resolver = tf.distribute.cluster_resolver.TPUClusterResolver("local") tf.config.experimental_connect_to_cluster(resolver) tf.tpu.experimental.initialize_tpu_system(resolver) # Load the model model = tf.saved_model.load(${CONVERTED_MODEL_PATH}) # Find the signature function for serving serving_signature = 'serving_default' # Change the serving signature if needed serving_fn = model.signatures[serving_signature] # Run the inference using requests. results = serving_fn(**inputs) logging.info("Serving results: %s", str(results))
Anwendungsbeispiele
Alias für die TPU-Funktion hinzufügen
- Suchen Sie in Ihrem Modell nach einer Funktion oder erstellen Sie eine, die alles umschließt, was auf der TPU ausgeführt werden soll. Wenn
@tf.functionnicht vorhanden ist, fügen Sie sie hinzu. - Geben Sie beim Speichern des Modells SaveOptions wie unten an, um
model.tpu_funcden Aliasfunc_on_tpuzu geben. - Sie können diesen Funktionsalias an den Konverter übergeben.
class ToyModel(tf.keras.Model): @tf.function( input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def tpu_func(self, x): return x * 1.0 model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'func_on_tpu': model.tpu_func, }) tf.saved_model.save(model, model_dir, options=save_options)
Modell mit mehreren TPU-Funktionen konvertieren
Sie können mehrere Funktionen auf die TPU legen. Erstellen Sie einfach mehrere Funktionsaliasse und übergeben Sie sie in converter_options_string an den Konverter.
tpu_functions { function_alias: "tpu_func_1" } tpu_functions { function_alias: "tpu_func_2" }
Quantisierung
Bei der Quantisierung wird die Genauigkeit der Zahlen reduziert, die zur Darstellung der Parameter eines Modells verwendet werden. Das führt zu einer kleineren Modellgröße und einer schnelleren Berechnung. Ein quantisiertes Modell bietet einen höheren Inferenzdurchsatz sowie eine geringere Speichernutzung und Speichergröße, allerdings zu Lasten einer geringfügigen Genauigkeitsminderung.
Die neue Quantisierungsfunktion nach dem Training in TensorFlow, die auf TPU ausgerichtet ist, wurde aus der ähnlichen Funktion in TensorFlow Lite entwickelt, die für die Ausrichtung auf Mobil- und Edge-Geräte verwendet wird. Weitere Informationen zur Quantisierung im Allgemeinen finden Sie im Dokument zu TensorFlow Lite.
Quantisierungskonzepte
In diesem Abschnitt werden Konzepte speziell im Zusammenhang mit der Quantisierung mit dem Inference Converter definiert.
Konzepte im Zusammenhang mit anderen TPU-Konfigurationen (z. B. Slices, Hosts, Chips und TensorCores) werden auf der Seite TPU-Systemarchitektur beschrieben.
Quantisierung nach dem Training (PTQ): Mit dieser Methode wird die Größe und die Rechenkomplexität eines neuronalen Netzwerkmodells reduziert, ohne dass sich dies wesentlich auf die Genauigkeit auswirkt. Bei der PTQ werden die Gleitkommagewichte und -Aktivierungen eines trainierten Modells in Ganzzahlen mit niedrigerer Genauigkeit umgewandelt, z. B. 8‑Bit- oder 16‑Bit-Ganzzahlen. Dies kann zu einer deutlichen Verringerung der Modellgröße und der Inferenzlatenz führen, während die Genauigkeit nur geringfügig beeinträchtigt wird.
Kalibrierung: Bei der Kalibrierung für die Quantisierung werden Statistiken zum Wertebereich erfasst, den die Gewichte und Aktivierungen eines neuronalen Netzwerkmodells annehmen. Anhand dieser Informationen werden die Quantisierungsparameter für das Modell bestimmt. Das sind die Werte, mit denen die Gleitkommagewichte und -Aktivierungen in Ganzzahlen umgewandelt werden.
Repräsentatives Dataset: Ein repräsentatives Dataset für die Quantisierung ist ein kleines Dataset, das die tatsächlichen Eingabedaten für das Modell darstellt. Sie wird während des Kalibrierungsschritts der Quantisierung verwendet, um Statistiken zum Wertebereich zu erfassen, den die Gewichte und Aktivierungen des Modells annehmen werden. Das repräsentative Dataset sollte die folgenden Eigenschaften erfüllen:
- Sie sollte die tatsächlichen Eingaben in das Modell während der Inferenz korrekt darstellen. Das bedeutet, dass der Wertebereich den Bereich abdecken sollte, den das Modell in der Praxis wahrscheinlich sehen wird.
- Sie sollte alle Verzweigungen von Bedingungen durchlaufen (z. B.
tf.cond), falls vorhanden. Das ist wichtig, weil der Quantisierungsprozess alle möglichen Eingaben in das Modell verarbeiten muss, auch wenn sie nicht explizit im repräsentativen Datensatz enthalten sind. - Sie sollte groß genug sein, um genügend Statistiken zu erfassen und Fehler zu reduzieren. Als Faustregel wird empfohlen, mehr als 200 repräsentative Stichproben zu verwenden.
Das repräsentative Dataset kann ein Teil des Trainings-Datasets sein oder ein separates Dataset, das speziell für die repräsentative Darstellung der realen Eingaben in das Modell entwickelt wurde. Welcher Datensatz verwendet wird, hängt von der jeweiligen Anwendung ab.
Statische Bereichsquantisierung (SRQ): Bei der SRQ wird der Wertebereich für die Gewichte und Aktivierungen eines neuronalen Netzwerkmodells einmal während des Kalibrierungsschritts festgelegt. Das bedeutet, dass für alle Eingaben in das Modell derselbe Wertebereich verwendet wird. Dies kann weniger genau sein als die Quantisierung mit dynamischem Bereich, insbesondere bei Modellen mit einem großen Bereich von Eingabewerten. Die Quantisierung mit statischem Bereich erfordert jedoch weniger Berechnungen bei der Laufzeit als die Quantisierung mit dynamischem Bereich.
Quantisierung mit dynamischem Bereich (Dynamic Range Quantization, DRQ): Mit DRQ wird der Wertebereich für die Gewichte und Aktivierungen eines neuronalen Netzwerkmodells für jede Eingabe bestimmt. So kann sich das Modell an den Wertebereich der Eingabedaten anpassen, was die Genauigkeit verbessern kann. Die Quantisierung mit dynamischem Bereich erfordert jedoch mehr Berechnungen bei der Laufzeit als die Quantisierung mit statischem Bereich.
Feature Quantisierung mit statischem Bereich Quantisierung des dynamischen Bereichs Wertebereich Wird einmal während der Kalibrierung ermittelt Für jede Eingabe bestimmt Genauigkeit Kann weniger genau sein, insbesondere bei Modellen mit einem großen Bereich von Eingabewerten Kann genauer sein, insbesondere bei Modellen mit einem großen Bereich von Eingabewerten Komplexität Einfacher Komplexer Berechnung während der Laufzeit Weniger Rechenleistung Mehr Rechenleistung Quantisierung nur der Gewichte: Bei dieser Quantisierungsart werden nur die Gewichte eines neuronalen Netzwerkmodells quantisiert, während die Aktivierungswerte im Gleitkommaformat bleiben. Dies kann eine gute Option für Modelle sein, die empfindlich auf Genauigkeit reagieren, da es dazu beitragen kann, die Genauigkeit des Modells beizubehalten.
Quantisierung
Die Quantisierung kann angewendet werden, indem die Option QuantizationOptions konfiguriert und den Konvertierungsoptionen zugewiesen wird. Zu den wichtigsten Optionen gehören:
- tags: Sammlung von Tags, die die
MetaGraphDefinnerhalb derSavedModelidentifizieren, die quantisiert werden soll. Wenn Sie nur eineMetaGraphDefhaben, müssen Sie diese Angabe nicht machen. - signature_keys: Sequenz von Schlüsseln, die
SignatureDefmit Eingaben und Ausgaben identifizieren. Wenn keine Angabe erfolgt, wird [„serving_default“] verwendet. - quantization_method: Zu anzuwendende Quantisierungsmethode. Wenn nichts angegeben wird, wird die Quantisierung
STATIC_RANGEangewendet. - op_set: Sollte als XLA beibehalten werden. Diese Option ist derzeit die Standardoption und muss nicht angegeben werden.
- representative_datasets: Geben Sie das Dataset an, das für die Kalibrierung der Quantisierungsparameter verwendet wird.
Repräsentativen Datensatz erstellen
Ein repräsentativer Datensatz ist im Grunde eine Iterable von Stichproben.
Ein Beispiel ist eine Karte von {input_key: input_value}. Beispiel:
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
Die repräsentativen Datasets sollten als TFRecord-Dateien mit der Klasse TfRecordRepresentativeDatasetSaver gespeichert werden, die derzeit im Pip-Paket „tf-nightly“ verfügbar ist. Beispiel:
# Assumed tf-nightly installed.
import tensorflow as tf
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
tf.quantization.experimental.TfRecordRepresentativeDatasetSaver(
path_map={'serving_default': '/tmp/representative_dataset_path'}
).save({'serving_default': representative_dataset})
Beispiele
Im folgenden Beispiel wird das Modell mit dem Signaturschlüssel serving_default und dem Funktionsalias tpu_func quantisiert:
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' \ tpu_functions { \ function_alias: "tpu_func" \ } \ external_feature_configs { \ quantization_options { \ signature_keys: "serving_default" \ representative_datasets: { \ key: "serving_default" \ value: { \ tfrecord_file_path: "${TF_RECORD_FILE}" \ } \ } \ } \ } '
Batch-Verarbeitung hinzufügen
Mit dem Konverter können Sie einem Modell Batch-Verarbeitung hinzufügen. Eine Beschreibung der Optionen für die Batchverarbeitung, die angepasst werden können, finden Sie unter Definition der Optionen für die Batchverarbeitung.
Standardmäßig führt der Konverter alle TPU-Funktionen im Modell im Batch aus. Außerdem können von Nutzern bereitgestellte Signaturen und Funktionen im Batch verarbeitet werden, um die Leistung weiter zu verbessern. Alle TPU-Funktionen, vom Nutzer bereitgestellten Funktionen oder Signaturen, die in Batches verarbeitet werden, müssen die strengen Anforderungen an die Form der Batch-Vorgänge erfüllen.
Mit dem Converter können Sie auch vorhandene Batch-Optionen aktualisieren. Im folgenden Beispiel wird gezeigt, wie Sie einem Modell Batching hinzufügen. Weitere Informationen zum Batching finden Sie unter Batching im Detail.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
bfloat16- und IO-Form-Optimierungen deaktivieren
BFloat16- und IO-Shape-Optimierungen sind standardmäßig aktiviert. Wenn sie mit Ihrem Modell nicht gut funktionieren, können sie deaktiviert werden.
# Disable both optimizations disable_default_optimizations: true # Or disable them individually io_shape_optimization: DISABLED bfloat16_optimization: DISABLED
Conversion-Bericht
Sie finden diesen Conversion-Bericht im Protokoll, nachdem Sie den Inferenzkonverter ausgeführt haben. Ein Beispiel dafür sehen Sie unten.
-------- Conversion Report -------- TPU cost of the model: 96.67% (2034/2104) CPU cost of the model: 3.33% (70/2104) Cost breakdown ================================ % Cost Name -------------------------------- 3.33 70 [CPU cost] 48.34 1017 tpu_func_1 48.34 1017 tpu_func_2 --------------------------------
In diesem Bericht werden die Rechenkosten des Ausgabemodells auf CPU und TPU geschätzt. Außerdem werden die TPU-Kosten nach Funktion aufgeschlüsselt. Diese sollten Ihrer Auswahl der TPU-Funktionen in den Konvertierungsoptionen entsprechen.
Wenn Sie die TPU besser nutzen möchten, sollten Sie mit der Modellstruktur experimentieren und die Konvertierungsoptionen anpassen.
Häufig gestellte Fragen
Welche Funktion(en) sollte ich auf die TPU legen?
Es ist am besten, so viel wie möglich von Ihrem Modell auf der TPU auszuführen, da die meisten Vorgänge auf der TPU schneller ausgeführt werden.
Wenn Ihr Modell keine TPU-inkompatiblen Operationen, Strings oder spärlichen Tensoren enthält, ist es in der Regel am besten, das gesamte Modell auf der TPU auszuführen. Dazu können Sie eine Funktion finden oder erstellen, die das gesamte Modell umschließt, einen Funktionsalias dafür erstellen und diesen an den Konverter übergeben.
Wenn Ihr Modell Teile enthält, die nicht auf der TPU ausgeführt werden können (z.B. TPU-inkompatible Vorgänge, Strings oder spärliche Tensoren), hängt die Auswahl der TPU-Funktionen davon ab, wo sich der inkompatible Teil befindet.
- Wenn es sich am Anfang oder Ende des Modells befindet, können Sie das Modell umstrukturieren, damit es auf der CPU ausgeführt wird. Beispiele sind Vor- und Nachbearbeitungsphasen für Strings. Weitere Informationen zum Verschieben von Code auf die CPU finden Sie unter Wie verschiebe ich einen Teil des Modells auf die CPU? Es zeigt eine typische Methode zum Refaktorisieren des Modells.
- Wenn sich die TPU-kompatiblen Vorgänge in der Mitte des Modells befinden, ist es besser, das Modell in drei Teile zu teilen und alle TPU-kompatiblen Vorgänge im mittleren Teil zu platzieren und auf der CPU auszuführen.
- Wenn es sich um einen spärlichen Tensor handelt, können Sie
tf.sparse.to_denseauf der CPU aufrufen und den resultierenden dichten Tensor an den TPU-Teil des Modells übergeben.
Ein weiterer Faktor ist die HBM-Nutzung. Das Einbetten von Tabellen kann viel HBM verbrauchen. Wenn sie die Hardwarebeschränkung der TPU überschreiten, müssen sie zusammen mit den Suchvorgängen auf der CPU ausgeführt werden.
Unter einer Signatur sollte nach Möglichkeit nur eine TPU-Funktion vorhanden sein. Wenn die Struktur Ihres Modells den Aufruf mehrerer TPU-Funktionen pro eingehender Inferenzanfrage erfordert, sollten Sie die zusätzliche Latenz beim Senden von Tensoren zwischen CPU und TPU berücksichtigen.
Eine gute Möglichkeit, die Auswahl der TPU-Funktionen zu bewerten, ist der Conversion-Bericht. Sie enthält den Prozentsatz der Berechnungen, die auf der TPU ausgeführt wurden, und eine Aufschlüsselung der Kosten für jede TPU-Funktion.
Wie verschiebe ich einen Teil des Modells auf die CPU?
Wenn Ihr Modell Teile enthält, die nicht auf der TPU gesendet werden können, müssen Sie das Modell umstrukturieren, um sie auf die CPU zu verschieben. Hier ein Beispiel: Das Modell ist ein Sprachmodell mit einer Vorverarbeitungsphase. Der Code für Ebenendefinitionen und ‑funktionen wurde aus Gründen der Übersichtlichkeit weggelassen.
class LanguageModel(tf.keras.Model): @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.bert_layer(word_ids)
Dieses Modell kann aus zwei Gründen nicht direkt auf der TPU bereitgestellt werden. Erstens ist der Parameter ein String. Zweitens kann die preprocess-Funktion viele String-Vorgänge enthalten. Beide sind nicht mit TPUs kompatibel.
Um dieses Modell zu überarbeiten, können Sie eine weitere Funktion namens tpu_func erstellen, um die rechenintensive bert_layer zu hosten. Erstellen Sie dann einen Funktionsalias für tpu_func und übergeben Sie ihn an den Konverter. So wird alles innerhalb von tpu_func auf der TPU ausgeführt und alles, was in model_func übrig bleibt, auf der CPU.
class LanguageModel(tf.keras.Model): @tf.function def tpu_func(self, word_ids): return self.bert_layer(word_ids) @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.tpu_func(word_ids)
Was kann ich tun, wenn das Modell TPU-inkompatible Vorgänge, Strings oder spärliche Tensoren enthält?
Die meisten Standard-TensorFlow-Vorgänge werden auf der TPU unterstützt, einige jedoch nicht, z. B. Sparse-Tensors und Strings. Der Konverter prüft nicht auf TPU-inkompatible Vorgänge. Ein Modell mit solchen Vorgängen kann also die Umwandlung bestehen. Wenn Sie es jedoch für die Inferenz ausführen, treten Fehler wie unten aufgeführt auf.
'tf.StringToNumber' op isn't compilable for TPU device.
Wenn Ihr Modell TPU-inkompatible Vorgänge enthält, sollten diese außerhalb der TPU-Funktion platziert werden. Außerdem ist „String“ ein nicht unterstütztes Datenformat auf der TPU. Daher sollten Variablen vom Typ „String“ nicht in die TPU-Funktion eingefügt werden. Außerdem sollten die Parameter und Rückgabewerte der TPU-Funktion nicht vom Typ „String“ sein. Vermeiden Sie außerdem, Sparse-Tensoren in die TPU-Funktion einzugeben, einschließlich ihrer Parameter und Rückgabewerte.
Es ist in der Regel nicht schwierig, den inkompatiblen Teil des Modells zu refaktorisieren und auf die CPU zu verschieben. Hier ist ein Beispiel.
Wie kann ich benutzerdefinierte Vorgänge im Modell unterstützen?
Wenn in Ihrem Modell benutzerdefinierte Vorgänge verwendet werden, werden sie vom Converter möglicherweise nicht erkannt und das Modell kann nicht konvertiert werden. Das liegt daran, dass die Operatorbibliothek des benutzerdefinierten Operators, die die vollständige Definition des Operators enthält, nicht mit dem Konverter verknüpft ist.
Da der Code des Converters derzeit noch nicht als Open Source verfügbar ist, kann er nicht mit benutzerdefinierten Befehlen erstellt werden.
Was muss ich tun, wenn ich ein TensorFlow 1-Modell habe?
Der Konverter unterstützt keine TensorFlow 1-Modelle. TensorFlow 1-Modelle sollten zu TensorFlow 2 migriert werden.
Muss ich die MLIR-Bridge aktivieren, wenn ich mein Modell ausführe?
Die meisten konvertierten Modelle können entweder mit der neueren TF2XLA-MLIR-Bridge oder der ursprünglichen TF2XLA-Bridge ausgeführt werden.
Wie konvertiere ich ein Modell, das bereits ohne Funktionsalias exportiert wurde?
Wenn ein Modell ohne Funktionsalias exportiert wurde, ist es am einfachsten, es noch einmal zu exportieren und einen Funktionsalias zu erstellen.
Wenn ein erneuter Export nicht möglich ist, können Sie das Modell trotzdem konvertieren, indem Sie eine concrete_function_name angeben. Die richtige concrete_function_name zu ermitteln, erfordert jedoch etwas Detektivarbeit.
Funktionsaliasse sind eine Zuordnung von einem benutzerdefinierten String zu einem bestimmten Funktionsnamen. Sie erleichtern den Verweis auf eine bestimmte Funktion im Modell. Der Konverter akzeptiert sowohl Funktionsaliasse als auch rohe konkrete Funktionsnamen.
Konkrete Funktionsnamen finden Sie in der saved_model.pb.
Im folgenden Beispiel wird gezeigt, wie eine bestimmte Funktion namens __inference_serve_24 auf der TPU bereitgestellt wird.
sudo docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { concrete_function_name: "__inference_serve_24" }'
Wie behebe ich einen Fehler bei der Kompilierzeitkonstanten?
Sowohl für das Training als auch für die Inferenz erfordert XLA, dass die Eingaben für bestimmte Vorgänge zur TPU-Kompilierungszeit ein bekanntes Shape haben. Das bedeutet, dass die Eingaben dieser Vorgänge eine statisch bekannte Form haben müssen, wenn XLA den TPU-Teil des Programms kompiliert.
Es gibt zwei Möglichkeiten, dieses Problem zu beheben.
- Am besten aktualisieren Sie die Eingaben des Vorgangs, damit sie zu dem Zeitpunkt, zu dem XLA das TPU-Programm kompiliert, eine statisch bekannte Form haben. Diese Kompilierung erfolgt kurz vor dem Ausführen des TPU-Teils des Modells. Das bedeutet, dass die Form zum Zeitpunkt der Ausführung von
TpuFunctionstatisch bekannt sein sollte. - Eine weitere Möglichkeit besteht darin, die
TpuFunctionso zu ändern, dass sie die fehlerhafte Operation nicht mehr enthält.
Warum erhalte ich einen Fehler bei der Batch-Bildverarbeitung?
Für das Batching gelten strenge Formatanforderungen, die es ermöglichen, eingehende Anfragen entlang ihrer Nulldimension (auch Batching-Dimension genannt) zu bündeln. Diese Formanforderungen stammen aus der TensorFlow-Batch-Operation und können nicht gelockert werden.
Wenn Sie diese Anforderungen nicht erfüllen, kann es zu Fehlern wie den folgenden kommen:
- Batch-Eingabetensoren müssen mindestens eine Dimension haben.
- Die Dimensionen der Eingaben müssen übereinstimmen.
- Batch-Eingabetensoren, die in einer bestimmten Funktionsaufruf bereitgestellt werden, müssen dieselbe Größe in der Nulldimension haben.
- Die Nullte Dimension des Batch-Ausgabetensors entspricht nicht der Summe der Größen der Nullten Dimension der Eingabetensoren.
Um diese Anforderungen zu erfüllen, können Sie dem Batch eine andere Funktion oder Signatur zuweisen. Möglicherweise müssen Sie auch vorhandene Funktionen ändern, um diese Anforderungen zu erfüllen.
Wenn eine Funktion in Batches verarbeitet wird, muss die Eingabesignatur der @tf.function in der 0. Dimension den Wert „None“ haben. Wenn eine Signatur in einem Batch verarbeitet wird, muss für alle Eingaben in der 0. Dimension „-1“ angegeben sein.
Eine vollständige Erklärung dazu, warum diese Fehler auftreten und wie sie behoben werden können, finden Sie im Artikel Batching – ein genauer Blick.
Bekannte Probleme
TPU-Funktion kann keine andere TPU-Funktion indirekt aufrufen
Der Konverter kann zwar die meisten Funktionsaufrufsszenarien über die CPU-TPU-Grenze hinweg verarbeiten, es gibt jedoch einen seltenen Grenzfall, in dem er fehlschlägt. Eine TPU-Funktion ruft indirekt eine andere TPU-Funktion auf.
Das liegt daran, dass der Converter den direkten Aufrufer einer TPU-Funktion so ändert, dass nicht mehr die TPU-Funktion selbst, sondern ein TPU-Aufruf-Stub aufgerufen wird. Der Aufruf-Stub enthält Vorgänge, die nur auf der CPU ausgeführt werden können. Wenn eine TPU-Funktion eine Funktion aufruft, die schließlich den direkten Aufrufer aufruft, können diese CPU-Vorgänge zur Ausführung auf die TPU verschoben werden, was zu fehlenden Kernelfehlern führt. Hinweis: Dieser Fall unterscheidet sich von einer TPU-Funktion, die direkt eine andere TPU-Funktion aufruft. In diesem Fall ändert der Konverter keine der Funktionen, um den Call-Stub aufzurufen, sodass er funktionieren kann.
Im Converter haben wir die Erkennung dieses Szenarios implementiert. Wenn der folgende Fehler angezeigt wird, ist Ihr Modell auf diesen Grenzfall gestoßen:
Unable to place both "__inference_tpu_func_2_46" and "__inference_tpu_func_4_68" on the TPU because "__inference_tpu_func_2_46" indirectly calls "__inference_tpu_func_4_68". This behavior is unsupported because it can cause invalid graphs to be generated.
Die allgemeine Lösung besteht darin, das Modell zu überarbeiten, um ein solches Szenario zu vermeiden. Falls das schwierig ist, wenden Sie sich an das Google-Supportteam.
Referenz
Konvertierungsoptionen im Protobuf-Format
message ConverterOptions { // TPU conversion options. repeated TpuFunction tpu_functions = 1; // The state of an optimization. enum State { // When state is set to default, the optimization will perform its // default behavior. For some optimizations this is disabled and for others // it is enabled. To check a specific optimization, read the optimization's // description. DEFAULT = 0; // Enabled. ENABLED = 1; // Disabled. DISABLED = 2; } // Batch options to apply to the TPU Subgraph. // // At the moment, only one batch option is supported. This field will be // expanded to support batching on a per function and/or per signature basis. // // // If not specified, no batching will be done. repeated BatchOptions batch_options = 100; // Global flag to disable all optimizations that are enabled by default. // When enabled, all optimizations that run by default are disabled. If a // default optimization is explicitly enabled, this flag will have no affect // on that optimization. // // This flag defaults to false. bool disable_default_optimizations = 202; // If enabled, apply an optimization that reshapes the tensors going into // and out of the TPU. This reshape operation improves performance by reducing // the transfer time to and from the TPU. // // This optimization is incompatible with input_shape_opt which is disabled. // by default. If input_shape_opt is enabled, this option should be // disabled. // // This optimization defaults to enabled. State io_shape_optimization = 200; // If enabled, apply an optimization that updates float variables and float // ops on the TPU to bfloat16. This optimization improves performance and // throughtput by reducing HBM usage and taking advantage of TPU support for // bfloat16. // // This optimization may cause a loss of accuracy for some models. If an // unacceptable loss of accuracy is detected, disable this optimization. // // This optimization defaults to enabled. State bfloat16_optimization = 201; BFloat16OptimizationOptions bfloat16_optimization_options = 203; // The settings for XLA sharding. If set, XLA sharding is enabled. XlaShardingOptions xla_sharding_options = 204; } message TpuFunction { // The function(s) that should be placed on the TPU. Only provide a given // function once. Duplicates will result in errors. For example, if // you provide a specific function using function_alias don't also provide the // same function via concrete_function_name or jit_compile_functions. oneof name { // The name of the function alias associated with the function that // should be placed on the TPU. Function aliases are created during model // export using the tf.saved_model.SaveOptions. // // This is a recommended way to specify which function should be placed // on the TPU. string function_alias = 1; // The name of the concrete function that should be placed on the TPU. This // is the name of the function as it found in the GraphDef and the // FunctionDefLibrary. // // This is NOT the recommended way to specify which function should be // placed on the TPU because concrete function names change every time a // model is exported. string concrete_function_name = 3; // The name of the signature to be placed on the TPU. The user must make // sure there is no TPU-incompatible op under the entire signature. string signature_name = 5; // When jit_compile_functions is set to True, all jit compiled functions // are placed on the TPU. // // To use this option, decorate the relevant function(s) with // @tf.function(jit_compile=True), before exporting. Then set this flag to // True. The converter will find all functions that were tagged with // jit_compile=True and place them on the TPU. // // When using this option, all other settings for the TpuFunction // will apply to all functions tagged with // jit_compile=True. // // This option will place all jit_compile=True functions on the TPU. // If only some jit_compile=True functions should be placed on the TPU, // use function_alias or concrete_function_name. bool jit_compile_functions = 4; } } message BatchOptions { // Number of scheduling threads for processing batches of work. Determines // the number of batches processed in parallel. This should be roughly in line // with the number of TPU cores available. int32 num_batch_threads = 1; // The maximum allowed batch size. int32 max_batch_size = 2; // Maximum number of microseconds to wait before outputting an incomplete // batch. int32 batch_timeout_micros = 3; // Optional list of allowed batch sizes. If left empty, // does nothing. Otherwise, supplies a list of batch sizes, causing the op // to pad batches up to one of those sizes. The entries must increase // monotonically, and the final entry must equal max_batch_size. repeated int32 allowed_batch_sizes = 4; // Maximum number of batches enqueued for processing before requests are // failed fast. int32 max_enqueued_batches = 5; // If set, disables large batch splitting which is an efficiency improvement // on batching to reduce padding inefficiency. bool disable_large_batch_splitting = 6; // Experimental features of batching. Everything inside is subject to change. message Experimental { // The component to be batched. // 1. Unset if it's for all TPU subgraphs. // 2. Set function_alias or concrete_function_name if it's for a function. // 3. Set signature_name if it's for a signature. oneof batch_component { // The function alias associated with the function. Function alias is // created during model export using the tf.saved_model.SaveOptions, and is // the recommended way to specify functions. string function_alias = 1; // The concreate name of the function. This is the name of the function as // it found in the GraphDef and the FunctionDefLibrary. This is NOT the // recommended way to specify functions, because concrete function names // change every time a model is exported. string concrete_function_name = 2; // The name of the signature. string signature_name = 3; } } Experimental experimental = 7; } message BFloat16OptimizationOptions { // Indicates where the BFloat16 optimization should be applied. enum Scope { // The scope currently defaults to TPU. DEFAULT = 0; // Apply the bfloat16 optimization to TPU computation. TPU = 1; // Apply the bfloat16 optimization to the entire model including CPU // computations. ALL = 2; } // This field indicates where the bfloat16 optimization should be applied. // // The scope defaults to TPU. Scope scope = 1; // If set, the normal safety checks are skipped. For example, if the model // already contains bfloat16 ops, the bfloat16 optimization will error because // pre-existing bfloat16 ops can cause issues with the optimization. By // setting this flag, the bfloat16 optimization will skip the check. // // This is an advanced feature and not recommended for almost all models. // // This flag is off by default. bool skip_safety_checks = 2; // Ops that should not be converted to bfloat16. // Inputs into these ops will be cast to float32, and outputs from these ops // will be cast back to bfloat16. repeated string filterlist = 3; } message XlaShardingOptions { // num_cores_per_replica for TPUReplicateMetadata. // // This is the number of cores you wish to split your model into using XLA // SPMD. int32 num_cores_per_replica = 1; // (optional) device_assignment for TPUReplicateMetadata. // // This is in a flattened [x, y, z, core] format (for // example, core 1 of the chip // located in 2,3,0 will be stored as [2,3,0,1]). // // If this is not specified, then the device assignments will utilize the same // topology as specified in the topology attribute. repeated int32 device_assignment = 2; // A serialized string of tensorflow.tpu.TopologyProto objects, used for // the topology attribute in TPUReplicateMetadata. // // You must specify the mesh_shape and device_coordinates attributes in // the topology object. // // This option is required for num_cores_per_replica > 1 cases due to // ambiguity of num_cores_per_replica, for example, // pf_1x2x1 with megacore and df_1x1 // both have num_cores_per_replica = 2, but topology is (1,2,1,1) for pf and // (1,1,1,2) for df. // - For pf_1x2x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,2,1,1] // device_coordinates=flatten([0,0,0,0], [0,1,0,0]) // - For df_1x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,1,1,2] // device_coordinates=flatten([0,0,0,0], [0,0,0,1]) // - For df_2x2, mesh shape and device_coordinates looks like: // mesh_shape = [2,2,1,2] // device_coordinates=flatten( // [0,0,0,0],[0,0,0,1],[0,1,0,0],[0,1,0,1] // [1,0,0,0],[1,0,0,1],[1,1,0,0],[1,1,0,1]) bytes topology = 3; }
Batching im Detail
Mit der Batchverarbeitung lassen sich Durchsatz und TPU-Auslastung verbessern. So können mehrere Anfragen gleichzeitig verarbeitet werden. Während des Trainings kann die Batchverarbeitung mit tf.data erfolgen. Während der Inferenz wird in der Regel eine Operation in den Graphen eingefügt, die eingehende Anfragen bündelt. Der Vorgang wartet, bis genügend Anfragen vorhanden sind oder ein Zeitlimit erreicht wird, bevor er einen großen Batch aus den einzelnen Anfragen generiert. Weitere Informationen zu den verschiedenen Optionen für die Batchverarbeitung, die angepasst werden können, einschließlich Batchgrößen und Zeitüberschreitungen, finden Sie unter Definition von Batchverarbeitungsoptionen.
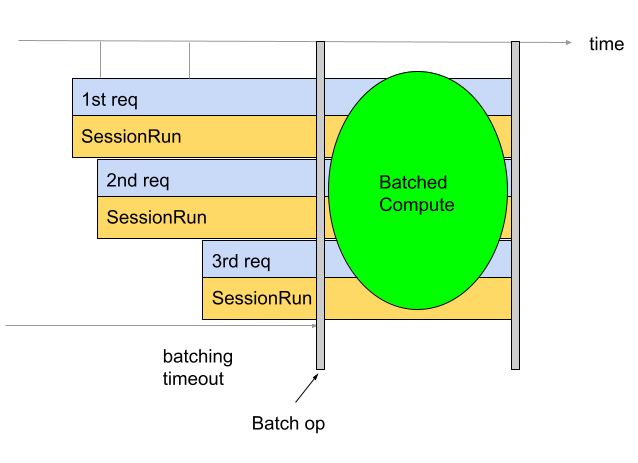
Standardmäßig fügt der Converter die Batch-Operation direkt vor der TPU-Berechnung ein. Sie umhüllt die vom Nutzer bereitgestellten TPU-Funktionen und alle vorhandenen TPU-Berechnungen im Modell mit Batch-Vorgängen. Dieses Standardverhalten kann überschrieben werden, indem Sie dem Konverter mitteilen, welche Funktionen und/oder Signaturen in Batches verarbeitet werden sollen.
Im folgenden Beispiel wird gezeigt, wie Sie die Standard-Batchverarbeitung hinzufügen.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
Batchverarbeitung von Signaturen
Beim Batching von Signaturen wird das gesamte Modell in Batches verarbeitet, beginnend bei den Eingaben der Signatur und endend bei den Ausgaben der Signatur. Im Gegensatz zum standardmäßigen Batch-Verhalten des Converters werden beim Batching von Signaturen sowohl die TPU- als auch die CPU-Berechnung in Batches ausgeführt. Dies führt bei einigen Modellen zu einer Leistungssteigerung von 10 bis 20 % bei der Inferenz.
Wie bei allen Batch-Vorgängen gelten für das Batching von Signaturen strenge Formvorgaben.
Damit diese Anforderungen an die Form erfüllt werden, sollten Signatureingaben Formen mit mindestens zwei Dimensionen haben. Die erste Dimension ist die Batchgröße und sollte -1 sein. Zum Beispiel sind (-1, 4), (-1) oder (-1,
128, 4, 10) alle gültige Eingabeformen. Wenn das nicht möglich ist, können Sie das standardmäßige Batch-Verhalten oder das Batch-Verhalten für Funktionen verwenden.
Wenn Sie die Batch-Signatur verwenden möchten, geben Sie den Namen der Signatur(en) als signature_name(s) mit dem BatchOptions an.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { signature_name: "serving_default" } }
Batchverarbeitung von Funktionen
Mit dem Batch-Verfahren für Funktionen können Sie dem Converter mitteilen, welche Funktionen in einem Batch verarbeitet werden sollen. Standardmäßig führt der Converter alle TPU-Funktionen im Batch aus. Beim Batch-Ausführen von Funktionen wird dieses Standardverhalten überschrieben.
Mit dem Funktions-Batching können CPU-Berechnungen in Batches ausgeführt werden. Bei vielen Modellen lässt sich die Leistung verbessern, wenn die CPU-Berechnungen in Batches ausgeführt werden. Die beste Methode für die Batch-CPU-Berechnung ist die Signatur-Batchverarbeitung. Bei einigen Modellen funktioniert sie jedoch möglicherweise nicht. In diesen Fällen kann die Funktion „Batching“ verwendet werden, um einen Teil der CPU-Berechnung zusätzlich zur TPU-Berechnung zu batchen. Die Batch-Operation kann nicht auf der TPU ausgeführt werden. Daher muss jede bereitgestellte Batch-Funktion auf der CPU aufgerufen werden.
Mit dem Batching von Funktionen können auch die strengen Formanforderungen der Batch-Operation erfüllt werden. Wenn die TPU-Funktionen nicht den Formvorschriften der Batch-Operation entsprechen, kann der Converter mithilfe des Funktions-Batching aufgefordert werden, verschiedene Funktionen zu batchen.
Erstellen Sie dazu eine function_alias für die Funktion, die in Batches ausgeführt werden soll. Dazu können Sie in Ihrem Modell eine Funktion suchen oder erstellen, die alles umschließt, was Sie in einem Batch verarbeiten möchten. Achten Sie darauf, dass diese Funktion die strengen Anforderungen an die Form erfüllt, die durch die Batch-Operation auferlegt werden. Fügen Sie @tf.function hinzu, falls noch keine vorhanden ist.
Es ist wichtig, dass Sie die input_signature an die @tf.function senden. Die Nullte Dimension sollte None sein, da es sich um die Batchdimension handelt und sie daher keine feste Größe haben kann. Beispiele für gültige Eingabeformen sind [None, 4], [None] oder [None, 128, 4, 10]. Geben Sie beim Speichern des Modells SaveOptions wie unten gezeigt an, um model.batch_func den Alias „batch_func“ zuzuweisen. Diesen Funktionsalias können Sie dann an den Konverter übergeben.
class ToyModel(tf.keras.Model): @tf.function(input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def batch_func(self, x): return x * 1.0 ... model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'batch_func': model.batch_func, }) tf.saved_model.save(model, model_dir, options=save_options)
Übergeben Sie als Nächstes die function_alias mithilfe der BatchOptions.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { function_alias: "batch_func" } }
Definition von Stapelverarbeitungsoptionen
num_batch_threads: (Ganzzahl) Anzahl der Planungsthreads für die Verarbeitung von Arbeitspaketen. Bestimmt die Anzahl der parallel verarbeiteten Batches. Diese sollte ungefähr der Anzahl der verfügbaren TPU-Kerne entsprechen.max_batch_size: (ganzzahl) Maximale zulässige Batchgröße. Kann größer alsallowed_batch_sizessein, um die Aufteilung großer Batches zu nutzen.batch_timeout_micros: (ganzzahl) Maximale Anzahl von Mikrosekunden, die gewartet werden soll, bevor ein unvollständiger Batch ausgegeben wird.allowed_batch_sizes: (Liste von Ganzzahlen) Wenn die Liste nicht leer ist, werden die Batches auf die nächstliegende Größe in der Liste aufgestockt. Die Liste muss monoton steigend sein und das letzte Element darf nicht größer alsmax_batch_sizesein.max_enqueued_batches: (Ganzzahl) Maximale Anzahl von Batches, die zur Verarbeitung in die Warteschlange gestellt werden, bevor Anfragen schnell fehlschlagen.
Vorhandene Stapelverarbeitungsoptionen aktualisieren
Sie können Batch-Optionen hinzufügen oder aktualisieren, indem Sie das Docker-Image mit der Angabe von „batch_options“ ausführen und disable_default_optimizations mit dem Flag --converter_options_string auf „true“ setzen. Die Batch-Optionen werden auf jede TPU-Funktion oder vorhandene Batch-Operation angewendet.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } disable_default_optimizations=True
Anforderungen an die Form von Batches
Batches werden erstellt, indem Eingabetensoren über Anfragen hinweg entlang ihrer Batchdimension (0. Dimension) zusammengefügt werden. Die Ausgabetensoren werden entlang ihrer Nulldimension aufgeteilt. Für die Ausführung dieser Vorgänge gelten strenge Formatanforderungen für die Eingaben und Ausgaben des Batch-Vorgangs.
Schritt-für-Schritt-Anleitung
Um diese Anforderungen zu verstehen, ist es hilfreich, zuerst zu verstehen, wie das Batching durchgeführt wird. Im folgenden Beispiel wird eine einfache tf.matmul-Operation in Batches ausgeführt.
def my_func(A, B) return tf.matmul(A, B)
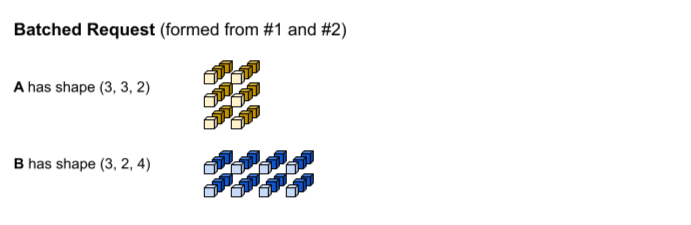
Die erste Inferenzanfrage erzeugt die Eingaben A und B mit den Formen (1, 3,
2) und (1, 2, 4). Die zweite Inferenzanfrage erzeugt die Eingaben A und B mit den Formen (2, 3, 2) und (2, 2, 4).

Das Zeitlimit für die Batchverarbeitung wurde erreicht. Das Modell unterstützt eine Batchgröße von 3, sodass die Inferenzanfragen 1 und 2 ohne Auffüllung zusammengefasst werden. Die Batch-Tensoren werden gebildet, indem die Anfragen 1 und 2 entlang der Batch-Dimension (0) zusammengefügt werden. Da A in Beispiel 1 die Form (1, 3, 2) und A in Beispiel 2 die Form (2, 3, 2) hat, ergibt sich beim Zusammenführen entlang der Batch-Dimension (0. Dimension) die Form (3, 3, 2).
Der tf.matmul wird ausgeführt und es wird eine Ausgabe mit der Form (3, 3,
4) erzeugt.

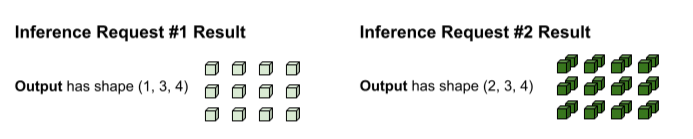
Die Ausgabe der tf.matmul erfolgt in Batches und muss daher in separate Anfragen aufgeteilt werden. Dazu wird der Batching-Operator entlang der Batch-Dimension (0. Dimension) jedes Ausgabetensors aufgeteilt. Sie entscheidet, wie die Nullte Dimension basierend auf der Form der ursprünglichen Eingaben aufgeteilt wird. Da die Formen in Anfrage 1 die Nullte Dimension 1 haben, hat die Ausgabe die Nullte Dimension 1 für eine Form von (1, 3, 4).
Da die Formen in Anfrage 2 die Nullte Dimension 2 haben, hat die Ausgabe die Nullte Dimension 2 für eine Form von (2, 3, 4).
Anforderungen an die Form
Damit die oben beschriebene Zusammenführung der Eingaben und Aufteilung der Ausgabe durchgeführt werden kann, gelten für die Batch-Operation die folgenden Anforderungen an die Form:
Eingaben für Batch-Vorgänge dürfen keine Skalare sein. Damit eine Konkatenierung entlang der 0. Dimension möglich ist, müssen die Tensoren mindestens zwei Dimensionen haben.
In der Anleitung oben. Weder A noch B sind Skalare.
Andernfalls wird ein Fehler wie
Batching input tensors must have at least one dimensionausgegeben. Eine einfache Lösung für diesen Fehler besteht darin, den Skalar in einen Vektor umzuwandeln.Bei verschiedenen Inferenzanfragen (z. B. verschiedenen Aufrufen der Sitzungsausführung) haben Eingabetensoren mit demselben Namen für jede Dimension dieselbe Größe, mit Ausnahme der Nulldimension. So können Eingaben entlang ihrer Nulldimension sauber zusammengefügt werden.
In der obigen Schritt-für-Schritt-Anleitung hat A in Anfrage 1 die Form
(1, 3, 2). Das bedeutet, dass jede zukünftige Anfrage eine Form mit dem Muster(X, 3, 2)erzeugen muss. Anfrage 2 erfüllt diese Anforderung mit(2, 3, 2). Ebenso hat B in Anfrage 1 die Form(1, 2, 4). Alle zukünftigen Anfragen müssen daher eine Form mit dem Muster(X, 2, 4)erzeugen.Andernfalls wird ein Fehler wie
Dimensions of inputs should matchausgegeben.Für eine bestimmte Inferenzanfrage müssen alle Eingaben dieselbe Größe für die Nullte Dimension haben. Wenn verschiedene Eingabetensoren für die Batch-Operation unterschiedliche Nulldimensionale Dimensionen haben, weiß die Batch-Operation nicht, wie die Ausgabetensoren aufgeteilt werden sollen.
In der obigen Schritt-für-Schritt-Anleitung haben die Tensoren von Anfrage 1 alle eine Größe von 1 in der Nulldimension. So wird der Batch-Vorgang darüber informiert, dass die Ausgabe eine Größe von 1 für die Nullte Dimension haben soll. Die Tensoren von Anfrage 2 haben ebenfalls eine Größe von 2 in der Nulldimension, sodass die Ausgabe eine Größe von 2 in der Nulldimension hat. Wenn die Batch-Operation die endgültige Form von
(3, 3, 4)aufteilt, wird(1, 3, 4)für Anfrage 1 und(2, 3, 4)für Anfrage 2 generiert.Andernfalls werden Fehler wie
Batching input tensors supplied in a given op invocation must have equal 0th-dimension sizeausgegeben.Die Größe der 0. Dimension der Form jedes Ausgabetensors muss der Summe der Größe der 0. Dimension aller Eingabetensoren entsprechen (zuzüglich aller Paddings, die durch die Batch-Operation hinzugefügt wurden, um die nächstgrößere
allowed_batch_sizezu erreichen). So kann die Batch-Operation die Ausgabetensoren basierend auf der 0. Dimension der Eingabetensoren entlang ihrer 0. Dimension aufteilen.In der obigen Schritt-für-Schritt-Anleitung haben die Eingabetensoren die Nullte Dimension 1 von Anfrage 1 und 2 von Anfrage 2. Daher muss jeder Ausgabetensor eine Nullte Dimension von 3 haben, da 1 + 2=3. Der Ausgabetensor
(3, 3, 4)erfüllt diese Anforderung. Wenn 3 keine gültige Batchgröße, aber 4 eine gültige Batchgröße wäre, müsste die Batch-Operation die 0. Dimension der Eingaben von 3 auf 4 auffüllen. In diesem Fall müsste jeder Ausgabetensor eine Größe von 4 für die Nullte Dimension haben.Andernfalls wird ein Fehler wie
Batched output tensor's 0th dimension does not equal the sum of the 0th dimension sizes of the input tensorsausgegeben.
Fehler bei Formvoraussetzungen beheben
Um diese Anforderungen zu erfüllen, können Sie dem Batch eine andere Funktion oder Signatur zuweisen. Möglicherweise müssen Sie auch vorhandene Funktionen ändern, um diese Anforderungen zu erfüllen.
Wenn eine Funktion in einem Batch ausgeführt wird, muss die Eingabesignatur der @tf.function in der 0. Dimension (d. h. der Batch-Dimension) None enthalten. Wenn eine Signatur in einem Batch verarbeitet wird, muss für alle Eingaben in der 0. Dimension „-1“ angegeben werden.
Der BatchFunction-Operator unterstützt SparseTensors nicht als Eingaben oder Ausgaben.
Intern wird jeder spärliche Tensor als drei separate Tensoren dargestellt, die unterschiedliche Größen der Nulldimension haben können.