Pengantar Konverter Inferensi Cloud TPU v5e
Pengantar
Cloud TPU Inference Converter menyiapkan dan mengoptimalkan model TensorFlow 2 (TF2) untuk inferensi TPU. Konverter berjalan di shell VM lokal atau TPU. Shell VM TPU direkomendasikan karena sudah diinstal sebelumnya dengan alat command line yang diperlukan untuk pengonversi. Model ini menggunakan SavedModel yang diekspor dan melakukan langkah-langkah berikut:
- Konversi TPU: Menambahkan
TPUPartitionedCalldan operasi TPU lainnya ke model agar dapat ditayangkan di TPU. Secara default, model yang diekspor untuk inferensi tidak memiliki operasi tersebut dan tidak dapat ditayangkan di TPU, meskipun dilatih di TPU. - Pengelompokan: Menambahkan operasi pengelompokan ke model untuk mengaktifkan pengelompokan dalam grafik untuk throughput yang lebih baik.
- Konversi BFloat16: Konversi ini mengonversi format data model dari
float32kebfloat16untuk performa komputasi yang lebih baik dan penggunaan Memori Bandwidth Tinggi (HBM) yang lebih rendah di TPU. - Pengoptimalan Bentuk IO: Fungsi ini mengoptimalkan bentuk tensor untuk data yang ditransfer antara CPU dan TPU guna meningkatkan penggunaan bandwidth.
Saat mengekspor model, pengguna membuat alias fungsi untuk fungsi apa pun yang ingin mereka jalankan di TPU. Fungsi ini diteruskan ke Pengonversi dan Pengonversi menempatkannya di TPU serta mengoptimalkannya.
Cloud TPU Inference Converter tersedia sebagai image Docker yang dapat dijalankan di lingkungan apa pun dengan Docker yang diinstal.
Estimasi waktu untuk menyelesaikan langkah-langkah yang ditampilkan di atas: ~20 menit - 30 menit
Prasyarat
- Model harus berupa model TF2 dan diekspor dalam format SavedModel.
- Model harus memiliki alias fungsi untuk fungsi TPU. Lihat
contoh kode
untuk mengetahui cara melakukannya. Contoh berikut menggunakan
tpu_funcsebagai alias fungsi TPU. - Pastikan CPU komputer Anda mendukung petunjuk Advanced Vector eXtensions (AVX), karena library Tensorflow (dependensi Cloud TPU Inference Converter) dikompilasi untuk menggunakan petunjuk AVX.
Sebagian besar CPU
memiliki dukungan AVX.
- Anda dapat menjalankan
lscpu | grep avxuntuk memeriksa apakah set instruksi AVX didukung.
- Anda dapat menjalankan
Sebelum memulai
Sebelum memulai penyiapan, lakukan hal berikut:
Buat project baru: Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Cloud.
Siapkan VM TPU: Buat VM TPU baru menggunakan Google Cloud Console atau
gcloud, atau gunakan VM TPU yang ada untuk menjalankan inferensi dengan model yang dikonversi di VM TPU.- Pastikan image VM TPU berbasis TensorFlow. Misalnya,
--version=tpu-vm-tf-2.11.0. - Model yang dikonversi akan dimuat dan ditayangkan di VM TPU ini.
- Pastikan image VM TPU berbasis TensorFlow. Misalnya,
Pastikan Anda memiliki alat command line yang diperlukan untuk menggunakan Cloud TPU Inference Converter. Anda dapat menginstal Google Cloud SDK dan Docker secara lokal atau menggunakan VM TPU yang telah menginstal software ini secara default. Anda menggunakan alat ini untuk berinteraksi dengan gambar Converter.
Hubungkan ke instance dengan SSH menggunakan perintah berikut:
gcloud compute tpus tpu-vm ssh ${tpu-name} --zone ${zone} --project ${project-id}
Penyiapan Lingkungan
Siapkan lingkungan Anda dari shell VM TPU atau dari shell lokal.
Shell VM TPU
Di shell VM TPU, jalankan perintah berikut untuk mengizinkan penggunaan docker non-root:
sudo usermod -a -G docker ${USER} newgrp docker
Lakukan inisialisasi helper Kredensial Docker Anda:
gcloud auth configure-docker \ us-docker.pkg.dev
Shell Lokal
Di shell lokal Anda, siapkan lingkungan menggunakan langkah-langkah berikut:
Instal Cloud SDK, yang menyertakan alat command line
gcloud.Instal Docker:
Izinkan penggunaan Docker non-root:
sudo usermod -a -G docker ${USER} newgrp docker
Login ke lingkungan Anda:
gcloud auth login
Lakukan inisialisasi helper Kredensial Docker Anda:
gcloud auth configure-docker \ us-docker.pkg.dev
Ambil image Docker Inference Converter:
CONVERTER_IMAGE=us-docker.pkg.dev/cloud-tpu-images/inference/tpu-inference-converter-cli:2.13.0 docker pull ${CONVERTER_IMAGE}
Gambar Konverter
Gambar digunakan untuk melakukan konversi model satu kali. Tetapkan jalur model dan sesuaikan opsi pengonversi agar sesuai dengan kebutuhan Anda. Bagian Contoh Penggunaan menyediakan beberapa kasus penggunaan umum.
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { function_alias: "tpu_func" } batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } '
Inferensi dengan model yang dikonversi di VM TPU
# Initialize the TPU resolver = tf.distribute.cluster_resolver.TPUClusterResolver("local") tf.config.experimental_connect_to_cluster(resolver) tf.tpu.experimental.initialize_tpu_system(resolver) # Load the model model = tf.saved_model.load(${CONVERTED_MODEL_PATH}) # Find the signature function for serving serving_signature = 'serving_default' # Change the serving signature if needed serving_fn = model.signatures[serving_signature] # Run the inference using requests. results = serving_fn(**inputs) logging.info("Serving results: %s", str(results))
Contoh Penggunaan
Menambahkan alias fungsi untuk fungsi TPU
- Temukan atau buat fungsi dalam model yang menggabungkan semua yang ingin Anda jalankan di TPU. Jika
@tf.functiontidak ada, tambahkan. - Saat menyimpan model, berikan SaveOptions seperti di bawah untuk memberi
model.tpu_funcaliasfunc_on_tpu. - Anda dapat meneruskan alias fungsi ini ke pengonversi.
class ToyModel(tf.keras.Model): @tf.function( input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def tpu_func(self, x): return x * 1.0 model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'func_on_tpu': model.tpu_func, }) tf.saved_model.save(model, model_dir, options=save_options)
Mengonversi model dengan beberapa fungsi TPU
Anda dapat menempatkan beberapa fungsi di TPU. Cukup buat beberapa alias fungsi dan teruskan dalam converter_options_string ke pengonversi.
tpu_functions { function_alias: "tpu_func_1" } tpu_functions { function_alias: "tpu_func_2" }
Kuantisasi
Kuantisasi adalah teknik yang mengurangi presisi angka yang digunakan untuk merepresentasikan parameter model. Hal ini menghasilkan ukuran model yang lebih kecil dan komputasi yang lebih cepat. Model kuantisasi memberikan peningkatan throughput inferensi serta penggunaan memori dan ukuran penyimpanan yang lebih kecil, dengan mengorbankan penurunan akurasi yang kecil.
Fitur Kuantifikasi Pasca-Pelatihan baru di TensorFlow yang menargetkan TPU, dikembangkan dari fitur serupa yang ada di TensorFlow Lite yang digunakan untuk menargetkan perangkat seluler dan edge. Untuk mempelajari lebih lanjut kuantisasi secara umum, Anda dapat melihat dokumen TensorFlow Lite.
Konsep kuantisasi
Bagian ini menentukan konsep yang secara khusus terkait dengan kuantisasi dengan Inference Converter.
Konsep yang terkait dengan konfigurasi TPU lainnya (misalnya, slice, host, chip, dan TensorCore) dijelaskan di halaman Arsitektur Sistem TPU.
Kuantisasi pasca-pelatihan (PTQ): PTQ adalah teknik yang mengurangi ukuran dan kompleksitas komputasi model jaringan saraf tanpa memengaruhi akurasinya secara signifikan. PTQ berfungsi dengan mengonversi bobot floating point dan aktivasi model terlatih menjadi bilangan bulat presisi lebih rendah, seperti bilangan bulat 8-bit atau 16-bit. Hal ini dapat menyebabkan pengurangan ukuran model dan latensi inferensi yang signifikan, dengan hanya mengalami sedikit penurunan akurasi.
Kalibrasi: Langkah kalibrasi untuk kuantisasi adalah proses mengumpulkan statistik tentang rentang nilai yang diambil oleh bobot dan aktivasi model jaringan saraf. Informasi ini digunakan untuk menentukan parameter kuantisasi untuk model, yang merupakan nilai yang akan digunakan untuk mengonversi bobot dan aktivasi floating point menjadi bilangan bulat.
Set Data Representatif: Set data representatif untuk kuantisasi adalah set data kecil yang mewakili data input sebenarnya untuk model. Ini digunakan selama langkah kalibrasi kuantisasi untuk mengumpulkan statistik tentang rentang nilai yang akan diambil oleh bobot dan aktivasi model. Set data representatif harus memenuhi properti berikut:
- Model ini harus merepresentasikan input sebenarnya ke model dengan benar selama inferensi. Artinya, model harus mencakup rentang nilai yang kemungkinan akan dilihat model di dunia nyata.
- Ini harus mengalir secara kolektif melalui setiap cabang kondisional
(seperti
tf.cond), jika ada. Hal ini penting karena proses kuantisasi harus dapat menangani semua kemungkinan input ke model, meskipun tidak direpresentasikan secara eksplisit dalam set data perwakilan. - Ukurannya harus cukup besar untuk mengumpulkan statistik yang cukup dan mengurangi error. Sebagai aturan umum, sebaiknya gunakan lebih dari 200 sampel perwakilan.
Set data perwakilan dapat berupa subkumpulan set data pelatihan, atau dapat berupa set data terpisah yang dirancang secara khusus untuk mewakili input dunia nyata ke model. Pilihan set data yang akan digunakan bergantung pada aplikasi tertentu.
Kuantisasi Rentang Statis (SRQ): SRQ menentukan rentang nilai untuk bobot dan aktivasi model jaringan saraf satu kali, selama langkah kalibrasi. Ini berarti bahwa rentang nilai yang sama digunakan untuk semua input ke model. Hal ini dapat kurang akurat daripada kuantisasi rentang dinamis, terutama untuk model dengan berbagai nilai input. Namun, kuantisasi rentang statis memerlukan lebih sedikit komputasi pada waktu eksekusi daripada kuantisasi rentang dinamis.
Kuantisasi Rentang Dinamis (DRQ): DRQ menentukan rentang nilai untuk bobot dan aktivasi model jaringan saraf untuk setiap input. Hal ini memungkinkan model beradaptasi dengan rentang nilai data input, yang dapat meningkatkan akurasi. Namun, kuantisasi rentang dinamis memerlukan lebih banyak komputasi pada waktu proses daripada kuantisasi rentang statis.
Fitur Kuantisasi rentang statis Kuantisasi rentang dinamis Rentang nilai Ditentukan satu kali, selama kalibrasi Ditentukan untuk setiap input Akurasi Dapat kurang akurat, terutama untuk model dengan berbagai nilai input Dapat lebih akurat, terutama untuk model dengan berbagai nilai input Kompleksitas Lebih sederhana Lebih kompleks Komputasi pada waktu proses Komputasi lebih sedikit Komputasi lainnya Kuantisasi Khusus Bobot: Kuantisasi khusus bobot adalah jenis kuantisasi yang hanya mengkuantisasi bobot model jaringan saraf, sementara membiarkan aktivasi dalam floating point. Hal ini dapat menjadi opsi yang baik untuk model yang sensitif terhadap akurasi, karena dapat membantu mempertahankan akurasi model.
Cara menggunakan kuantisasi
Kuantifikasi dapat diterapkan dengan mengonfigurasi dan menetapkan QuantizationOptions ke opsi pengonversi. Opsi yang penting adalah:
- tags: Kumpulan tag yang mengidentifikasi
MetaGraphDefdalamSavedModeluntuk dikuantisasi. Tidak perlu menentukan jika Anda hanya memiliki satuMetaGraphDef. - signature_keys: Urutan kunci yang mengidentifikasi
SignatureDefyang berisi input dan output. Jika tidak ditentukan, ["serving_default"] akan digunakan. - quantization_method: Metode kuantisasi yang akan diterapkan. Jika tidak ditentukan, kuantisasi
STATIC_RANGEakan diterapkan. - op_set: Harus disimpan sebagai XLA. Saat ini, ini adalah opsi default, tidak perlu ditentukan.
- representative_datasets: Menentukan set data yang digunakan untuk mengkalibrasi parameter kuantisasi.
Membuat set data representatif
Set data representatif pada dasarnya adalah sampel yang dapat di-iterasi.
Dengan sampel adalah peta dari: {input_key: input_value}. Contoh:
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
Set data perwakilan harus disimpan sebagai file TFRecord
menggunakan class TfRecordRepresentativeDatasetSaver
yang saat ini tersedia dalam paket pip tf-nightly. Contoh:
# Assumed tf-nightly installed.
import tensorflow as tf
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
tf.quantization.experimental.TfRecordRepresentativeDatasetSaver(
path_map={'serving_default': '/tmp/representative_dataset_path'}
).save({'serving_default': representative_dataset})
Contoh
Contoh berikut mengkuantisasi model dengan kunci tanda tangan
serving_default dan alias fungsi tpu_func:
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' \ tpu_functions { \ function_alias: "tpu_func" \ } \ external_feature_configs { \ quantization_options { \ signature_keys: "serving_default" \ representative_datasets: { \ key: "serving_default" \ value: { \ tfrecord_file_path: "${TF_RECORD_FILE}" \ } \ } \ } \ } '
Menambahkan pengelompokan
Konverter dapat digunakan untuk menambahkan pengelompokan ke model. Untuk deskripsi opsi pengelompokan yang dapat disesuaikan, lihat Definisi opsi pengelompokan.
Secara default, Konverter akan mengelompokkan fungsi TPU apa pun dalam model. Fungsi ini juga dapat mengelompokkan tanda tangan dan fungsi yang disediakan pengguna, yang dapat lebih meningkatkan performa. Setiap fungsi TPU, fungsi atau tanda tangan yang disediakan pengguna yang dikelompokkan, harus memenuhi persyaratan bentuk yang ketat dari operasi pengelompokan.
Konverter juga dapat memperbarui opsi pengelompokan yang ada. Berikut adalah contoh cara menambahkan pengelompokan ke model. Untuk informasi selengkapnya tentang pengelompokan, lihat Pembahasan mendalam tentang pengelompokan.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
Menonaktifkan pengoptimalan bentuk IO dan bfloat16
BFloat16 dan Pengoptimalan Bentuk IO diaktifkan secara default. Jika tidak berfungsi dengan baik dengan model Anda, fitur tersebut dapat dinonaktifkan.
# Disable both optimizations disable_default_optimizations: true # Or disable them individually io_shape_optimization: DISABLED bfloat16_optimization: DISABLED
Laporan Konversi
Anda dapat menemukan laporan konversi ini dari log setelah menjalankan Konverter Inference. Berikut contohnya.
-------- Conversion Report -------- TPU cost of the model: 96.67% (2034/2104) CPU cost of the model: 3.33% (70/2104) Cost breakdown ================================ % Cost Name -------------------------------- 3.33 70 [CPU cost] 48.34 1017 tpu_func_1 48.34 1017 tpu_func_2 --------------------------------
Laporan ini memperkirakan biaya komputasi model output pada CPU dan TPU, serta merinci lebih lanjut biaya TPU untuk setiap fungsi, yang akan mencerminkan pemilihan fungsi TPU Anda di opsi pengonversi.
Jika ingin memanfaatkan TPU dengan lebih baik, sebaiknya bereksperimen dengan struktur model dan sesuaikan opsi pengonversi.
FAQ
Fungsi mana yang harus saya tempatkan di TPU?
Sebaiknya tempatkan model Anda sebanyak mungkin di TPU, karena sebagian besar operasi dieksekusi lebih cepat di TPU.
Jika model Anda tidak berisi op, string, atau tensor longgar yang tidak kompatibel dengan TPU, menempatkan seluruh model di TPU biasanya merupakan strategi terbaik. Dan Anda dapat melakukannya dengan menemukan atau membuat fungsi yang menggabungkan seluruh model, membuat alias fungsi untuknya, dan meneruskannya ke Converter.
Jika model Anda berisi bagian yang tidak dapat berfungsi di TPU (misalnya, operasi, string, atau tensor jarang yang tidak kompatibel dengan TPU), pilihan fungsi TPU bergantung pada lokasi bagian yang tidak kompatibel.
- Jika berada di awal atau akhir model, Anda dapat memfaktorkan ulang model untuk mempertahankannya di CPU. Contohnya adalah tahap pra- dan pasca-pemrosesan string. Untuk informasi selengkapnya tentang cara memindahkan kode ke CPU, lihat "Bagaimana cara memindahkan bagian model ke CPU?" Contoh ini menunjukkan cara umum untuk memfaktorkan ulang model.
- Jika berada di tengah model, sebaiknya bagi model menjadi tiga bagian dan masukkan semua operasi yang tidak kompatibel dengan TPU di bagian tengah, lalu jalankan di CPU.
- Jika ini adalah tensor jarang, pertimbangkan untuk memanggil
tf.sparse.to_densedi CPU dan meneruskan tensor rapat yang dihasilkan ke bagian TPU model.
Faktor lain yang perlu dipertimbangkan adalah penggunaan HBM. Menyematkan tabel dapat menggunakan banyak HBM. Jika tumbuh melebihi batasan hardware TPU, data tersebut harus ditempatkan di CPU, bersama dengan operasi pencarian.
Jika memungkinkan, hanya boleh ada satu fungsi TPU dalam satu tanda tangan. Jika struktur model Anda memerlukan pemanggilan beberapa fungsi TPU per permintaan inferensi yang masuk, Anda harus mengetahui latensi tambahan pengiriman tensor antara CPU dan TPU.
Cara yang baik untuk mengevaluasi pemilihan fungsi TPU adalah dengan memeriksa Laporan Konversi. Laporan ini menunjukkan persentase komputasi yang ditempatkan di TPU, dan perincian biaya setiap fungsi TPU.
Bagaimana cara memindahkan bagian model ke CPU?
Jika model Anda berisi bagian yang tidak dapat ditayangkan di TPU, Anda perlu memfaktorkan ulang model untuk memindahkannya ke CPU. Berikut adalah contoh mainan. Model ini adalah model bahasa dengan tahap pra-pemrosesan. Kode untuk definisi dan fungsi lapisan dihilangkan agar lebih praktis.
class LanguageModel(tf.keras.Model): @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.bert_layer(word_ids)
Model ini tidak dapat ditayangkan langsung di TPU karena dua alasan. Pertama, parameter adalah string. Kedua, fungsi preprocess dapat berisi banyak operasi
string. Keduanya tidak kompatibel dengan TPU.
Untuk memfaktorkan ulang model ini, Anda dapat membuat fungsi lain yang disebut tpu_func untuk
menghosting bert_layer yang intensif komputasi. Kemudian, buat alias fungsi untuk
tpu_func dan teruskan ke Konverter. Dengan cara ini, semua yang ada di dalam
tpu_func akan berjalan di TPU, dan semua yang tersisa di model_func akan berjalan di
CPU.
class LanguageModel(tf.keras.Model): @tf.function def tpu_func(self, word_ids): return self.bert_layer(word_ids) @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.tpu_func(word_ids)
Apa yang harus saya lakukan jika model memiliki operasi, string, atau tensor jarang yang tidak kompatibel dengan TPU?
Sebagian besar operasi TensorFlow standar didukung di TPU, tetapi beberapa operasi, termasuk string dan tensor jarang, tidak didukung. Konverter tidak memeriksa operasi yang tidak kompatibel dengan TPU. Jadi, model yang berisi operasi tersebut dapat meneruskan konversi. Namun, saat menjalankannya untuk inferensi, error seperti di bawah akan terjadi.
'tf.StringToNumber' op isn't compilable for TPU device.
Jika model Anda memiliki operasi yang tidak kompatibel dengan TPU, operasi tersebut harus ditempatkan di luar fungsi TPU. Selain itu, string adalah format data yang tidak didukung di TPU. Jadi, variabel berjenis string tidak boleh ditempatkan dalam fungsi TPU. Selain itu, parameter dan nilai yang ditampilkan dari fungsi TPU juga tidak boleh berjenis string. Demikian pula, hindari menempatkan tensor jarang dalam fungsi TPU, termasuk dalam parameter dan nilai return-nya.
Biasanya tidak sulit untuk memfaktorkan ulang bagian model yang tidak kompatibel dan memindahkannya ke CPU. Berikut adalah contohnya.
Bagaimana cara mendukung operasi kustom dalam model?
Jika operasi kustom digunakan dalam model Anda, Konverter mungkin tidak mengenalinya dan gagal mengonversi model. Hal ini karena library op dari op kustom, yang berisi definisi lengkap op, tidak ditautkan ke Converter.
Karena saat ini kode pengonversi belum open source, pengonversi tidak dapat di-build dengan op kustom.
Apa yang harus saya lakukan jika memiliki model TensorFlow 1?
Konverter tidak mendukung model TensorFlow 1. Model TensorFlow 1 harus dimigrasikan ke TensorFlow 2.
Apakah saya perlu mengaktifkan jembatan MLIR saat menjalankan model?
Sebagian besar model yang dikonversi dapat dijalankan dengan jembatan MLIR TF2XLA yang lebih baru atau jembatan TF2XLA asli.
Bagaimana cara mengonversi model yang telah diekspor tanpa alias fungsi?
Jika model diekspor tanpa alias fungsi, cara termudah adalah mengekspornya lagi dan membuat alias fungsi.
Jika mengekspor ulang bukan merupakan opsi, Anda masih dapat mengonversi model dengan menyediakan concrete_function_name. Namun, mengidentifikasi concrete_function_name
yang benar memang memerlukan beberapa penyelidikan.
Alias fungsi adalah pemetaan dari string yang ditentukan pengguna ke nama fungsi konkret. Fungsi ini memudahkan Anda merujuk ke fungsi tertentu dalam model. Konverter menerima alias fungsi dan nama fungsi konkret mentah.
Nama fungsi konkret dapat ditemukan dengan memeriksa saved_model.pb.
Contoh berikut menunjukkan cara menempatkan fungsi konkret yang disebut
__inference_serve_24 di TPU.
sudo docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { concrete_function_name: "__inference_serve_24" }'
Bagaimana cara mengatasi error batasan konstanta waktu kompilasi?
Untuk pelatihan dan inferensi, XLA mewajibkan input ke operasi tertentu memiliki bentuk yang diketahui pada waktu kompilasi TPU. Artinya, saat XLA mengompilasi bagian TPU program, input ke operasi ini harus memiliki bentuk yang diketahui secara statis.
Ada dua cara untuk mengatasi masalah ini.
- Opsi terbaiknya adalah memperbarui input op agar memiliki bentuk yang diketahui secara statis
pada saat XLA mengompilasi program TPU. Kompilasi ini terjadi
tepat sebelum bagian TPU model dijalankan. Artinya, bentuk
harus diketahui secara statis pada saat
TpuFunctionakan dijalankan. - Opsi lainnya adalah mengubah
TpuFunctionagar tidak lagi menyertakan op yang bermasalah.
Mengapa saya mendapatkan error bentuk pengelompokan?
Pembuatan batch memiliki persyaratan bentuk yang ketat yang memungkinkan permintaan masuk dikelompokkan berdasarkan dimensi ke-0 (alias dimensi pembuatan batch). Persyaratan bentuk ini berasal dari operasi pengelompokan TensorFlow dan tidak dapat dilonggarkan.
Kegagalan dalam memenuhi persyaratan ini akan menyebabkan error seperti:
- Tensor input pengelompokan harus memiliki minimal satu dimensi.
- Dimensi input harus cocok.
- Tensor input pengelompokan yang disediakan dalam pemanggilan op tertentu harus memiliki ukuran dimensi ke-0 yang sama.
- Dimensi ke-0 tensor output batch tidak sama dengan jumlah ukuran dimensi ke-0 tensor input.
Untuk memenuhi persyaratan ini, pertimbangkan untuk memberikan fungsi atau tanda tangan yang berbeda ke batch. Anda mungkin juga perlu mengubah fungsi yang ada untuk memenuhi persyaratan ini.
Jika fungsi
dikelompokkan, pastikan semua bentuk input_signature @tf.function-nya
memiliki None di dimensi ke-0. Jika tanda tangan
dikelompokkan, pastikan semua inputnya memiliki -1 di dimensi ke-0.
Untuk mengetahui penjelasan lengkap tentang alasan terjadinya error ini dan cara mengatasinya, lihat Penjelasan Mendalam tentang Pengelompokan.
Masalah Umum
Fungsi TPU tidak dapat memanggil fungsi TPU lain secara tidak langsung
Meskipun Konverter dapat menangani sebagian besar skenario pemanggilan fungsi di seluruh batas CPU-TPU, ada satu kasus ekstrem yang jarang terjadi yang akan gagal. Hal ini terjadi saat fungsi TPU secara tidak langsung memanggil fungsi TPU lain.
Hal ini karena Konverter mengubah pemanggil langsung fungsi TPU dari memanggil fungsi TPU itu sendiri menjadi memanggil stub panggilan TPU. Stub panggilan berisi operasi yang hanya dapat berfungsi di CPU. Saat fungsi TPU memanggil fungsi apa pun yang pada akhirnya memanggil pemanggil langsung, operasi CPU tersebut dapat dibawa ke TPU untuk dieksekusi, yang akan menghasilkan error kernel yang tidak ada. Perhatikan bahwa kasus ini berbeda dengan fungsi TPU yang langsung memanggil fungsi TPU lain. Dalam hal ini, Konverter tidak mengubah salah satu fungsi untuk memanggil stub panggilan, sehingga dapat berfungsi.
Di Konverter, kami telah menerapkan deteksi skenario ini. Jika Anda melihat error berikut, artinya model Anda telah mencapai kasus ekstrem ini:
Unable to place both "__inference_tpu_func_2_46" and "__inference_tpu_func_4_68" on the TPU because "__inference_tpu_func_2_46" indirectly calls "__inference_tpu_func_4_68". This behavior is unsupported because it can cause invalid graphs to be generated.
Solusi umumnya adalah memfaktorkan ulang model untuk menghindari skenario pemanggilan fungsi tersebut. Jika Anda merasa sulit melakukannya, hubungi tim dukungan Google untuk membahas lebih lanjut.
Referensi
Opsi Konverter dalam format Protobuf
message ConverterOptions { // TPU conversion options. repeated TpuFunction tpu_functions = 1; // The state of an optimization. enum State { // When state is set to default, the optimization will perform its // default behavior. For some optimizations this is disabled and for others // it is enabled. To check a specific optimization, read the optimization's // description. DEFAULT = 0; // Enabled. ENABLED = 1; // Disabled. DISABLED = 2; } // Batch options to apply to the TPU Subgraph. // // At the moment, only one batch option is supported. This field will be // expanded to support batching on a per function and/or per signature basis. // // // If not specified, no batching will be done. repeated BatchOptions batch_options = 100; // Global flag to disable all optimizations that are enabled by default. // When enabled, all optimizations that run by default are disabled. If a // default optimization is explicitly enabled, this flag will have no affect // on that optimization. // // This flag defaults to false. bool disable_default_optimizations = 202; // If enabled, apply an optimization that reshapes the tensors going into // and out of the TPU. This reshape operation improves performance by reducing // the transfer time to and from the TPU. // // This optimization is incompatible with input_shape_opt which is disabled. // by default. If input_shape_opt is enabled, this option should be // disabled. // // This optimization defaults to enabled. State io_shape_optimization = 200; // If enabled, apply an optimization that updates float variables and float // ops on the TPU to bfloat16. This optimization improves performance and // throughtput by reducing HBM usage and taking advantage of TPU support for // bfloat16. // // This optimization may cause a loss of accuracy for some models. If an // unacceptable loss of accuracy is detected, disable this optimization. // // This optimization defaults to enabled. State bfloat16_optimization = 201; BFloat16OptimizationOptions bfloat16_optimization_options = 203; // The settings for XLA sharding. If set, XLA sharding is enabled. XlaShardingOptions xla_sharding_options = 204; } message TpuFunction { // The function(s) that should be placed on the TPU. Only provide a given // function once. Duplicates will result in errors. For example, if // you provide a specific function using function_alias don't also provide the // same function via concrete_function_name or jit_compile_functions. oneof name { // The name of the function alias associated with the function that // should be placed on the TPU. Function aliases are created during model // export using the tf.saved_model.SaveOptions. // // This is a recommended way to specify which function should be placed // on the TPU. string function_alias = 1; // The name of the concrete function that should be placed on the TPU. This // is the name of the function as it found in the GraphDef and the // FunctionDefLibrary. // // This is NOT the recommended way to specify which function should be // placed on the TPU because concrete function names change every time a // model is exported. string concrete_function_name = 3; // The name of the signature to be placed on the TPU. The user must make // sure there is no TPU-incompatible op under the entire signature. string signature_name = 5; // When jit_compile_functions is set to True, all jit compiled functions // are placed on the TPU. // // To use this option, decorate the relevant function(s) with // @tf.function(jit_compile=True), before exporting. Then set this flag to // True. The converter will find all functions that were tagged with // jit_compile=True and place them on the TPU. // // When using this option, all other settings for the TpuFunction // will apply to all functions tagged with // jit_compile=True. // // This option will place all jit_compile=True functions on the TPU. // If only some jit_compile=True functions should be placed on the TPU, // use function_alias or concrete_function_name. bool jit_compile_functions = 4; } } message BatchOptions { // Number of scheduling threads for processing batches of work. Determines // the number of batches processed in parallel. This should be roughly in line // with the number of TPU cores available. int32 num_batch_threads = 1; // The maximum allowed batch size. int32 max_batch_size = 2; // Maximum number of microseconds to wait before outputting an incomplete // batch. int32 batch_timeout_micros = 3; // Optional list of allowed batch sizes. If left empty, // does nothing. Otherwise, supplies a list of batch sizes, causing the op // to pad batches up to one of those sizes. The entries must increase // monotonically, and the final entry must equal max_batch_size. repeated int32 allowed_batch_sizes = 4; // Maximum number of batches enqueued for processing before requests are // failed fast. int32 max_enqueued_batches = 5; // If set, disables large batch splitting which is an efficiency improvement // on batching to reduce padding inefficiency. bool disable_large_batch_splitting = 6; // Experimental features of batching. Everything inside is subject to change. message Experimental { // The component to be batched. // 1. Unset if it's for all TPU subgraphs. // 2. Set function_alias or concrete_function_name if it's for a function. // 3. Set signature_name if it's for a signature. oneof batch_component { // The function alias associated with the function. Function alias is // created during model export using the tf.saved_model.SaveOptions, and is // the recommended way to specify functions. string function_alias = 1; // The concreate name of the function. This is the name of the function as // it found in the GraphDef and the FunctionDefLibrary. This is NOT the // recommended way to specify functions, because concrete function names // change every time a model is exported. string concrete_function_name = 2; // The name of the signature. string signature_name = 3; } } Experimental experimental = 7; } message BFloat16OptimizationOptions { // Indicates where the BFloat16 optimization should be applied. enum Scope { // The scope currently defaults to TPU. DEFAULT = 0; // Apply the bfloat16 optimization to TPU computation. TPU = 1; // Apply the bfloat16 optimization to the entire model including CPU // computations. ALL = 2; } // This field indicates where the bfloat16 optimization should be applied. // // The scope defaults to TPU. Scope scope = 1; // If set, the normal safety checks are skipped. For example, if the model // already contains bfloat16 ops, the bfloat16 optimization will error because // pre-existing bfloat16 ops can cause issues with the optimization. By // setting this flag, the bfloat16 optimization will skip the check. // // This is an advanced feature and not recommended for almost all models. // // This flag is off by default. bool skip_safety_checks = 2; // Ops that should not be converted to bfloat16. // Inputs into these ops will be cast to float32, and outputs from these ops // will be cast back to bfloat16. repeated string filterlist = 3; } message XlaShardingOptions { // num_cores_per_replica for TPUReplicateMetadata. // // This is the number of cores you wish to split your model into using XLA // SPMD. int32 num_cores_per_replica = 1; // (optional) device_assignment for TPUReplicateMetadata. // // This is in a flattened [x, y, z, core] format (for // example, core 1 of the chip // located in 2,3,0 will be stored as [2,3,0,1]). // // If this is not specified, then the device assignments will utilize the same // topology as specified in the topology attribute. repeated int32 device_assignment = 2; // A serialized string of tensorflow.tpu.TopologyProto objects, used for // the topology attribute in TPUReplicateMetadata. // // You must specify the mesh_shape and device_coordinates attributes in // the topology object. // // This option is required for num_cores_per_replica > 1 cases due to // ambiguity of num_cores_per_replica, for example, // pf_1x2x1 with megacore and df_1x1 // both have num_cores_per_replica = 2, but topology is (1,2,1,1) for pf and // (1,1,1,2) for df. // - For pf_1x2x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,2,1,1] // device_coordinates=flatten([0,0,0,0], [0,1,0,0]) // - For df_1x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,1,1,2] // device_coordinates=flatten([0,0,0,0], [0,0,0,1]) // - For df_2x2, mesh shape and device_coordinates looks like: // mesh_shape = [2,2,1,2] // device_coordinates=flatten( // [0,0,0,0],[0,0,0,1],[0,1,0,0],[0,1,0,1] // [1,0,0,0],[1,0,0,1],[1,1,0,0],[1,1,0,1]) bytes topology = 3; }
Pembahasan Mendalam tentang Pengelompokan
Pengelompokan digunakan untuk meningkatkan throughput dan penggunaan TPU. Hal ini memungkinkan beberapa permintaan diproses secara bersamaan. Selama pelatihan, pengelompokan
dapat dilakukan menggunakan tf.data. Selama inferensi, hal ini biasanya dilakukan dengan menambahkan
operasi dalam grafik yang mengelompokkan permintaan masuk. Operasi menunggu hingga memiliki cukup
permintaan atau waktu tunggu tercapai sebelum menghasilkan batch besar dari
setiap permintaan. Lihat
Definisi opsi pengelompokan
untuk mengetahui informasi selengkapnya tentang berbagai opsi pengelompokan yang dapat disesuaikan,
termasuk ukuran batch dan waktu tunggu.
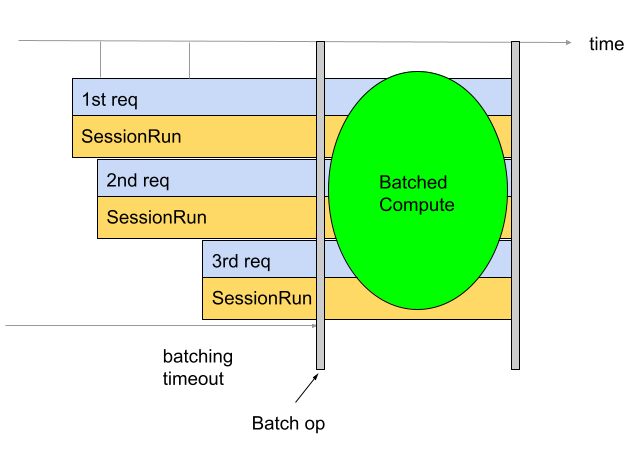
Secara default, Konverter menyisipkan operasi pengelompokan langsung sebelum komputasi TPU. Fungsi ini menggabungkan fungsi TPU yang disediakan pengguna dan komputasi TPU yang sudah ada dalam model dengan operasi pengelompokan. Anda dapat mengganti perilaku default ini dengan memberi tahu Converter fungsi dan/atau tanda tangan yang harus dikelompokkan.
Contoh berikut menunjukkan cara menambahkan pengelompokan default.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
Pengelompokan tanda tangan
Pengelompokan tanda tangan mengelompokkan seluruh model mulai dari input tanda tangan dan menuju output tanda tangan. Tidak seperti perilaku pengelompokan default Konverter, pengelompokan tanda tangan mengelompokkan komputasi TPU dan komputasi CPU. Hal ini memberikan peningkatan performa 10% hingga 20% selama inferensi pada beberapa model.
Seperti semua pengelompokan, pengelompokan Signature memiliki
persyaratan bentuk yang ketat.
Untuk membantu memastikan persyaratan bentuk ini terpenuhi, input tanda tangan harus memiliki
bentuk yang memiliki minimal dua dimensi. Dimensi pertama adalah ukuran batch
dan harus memiliki ukuran -1. Misalnya, (-1, 4), (-1), atau (-1,
128, 4, 10) semuanya adalah bentuk input yang valid. Jika tidak memungkinkan, pertimbangkan untuk menggunakan
perilaku pengelompokan default atau
pengelompokan fungsi.
Untuk menggunakan pengelompokan tanda tangan, berikan nama tanda tangan sebagai signature_name
menggunakan BatchOptions.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { signature_name: "serving_default" } }
Pengelompokan fungsi
Pengelompokan fungsi dapat digunakan untuk memberi tahu Pengonversi fungsi mana yang harus dikelompokkan. Secara default, Konverter akan mengelompokkan semua fungsi TPU. Pengelompokan fungsi akan menggantikan perilaku default ini.
Pengelompokan fungsi dapat digunakan untuk mengelompokkan komputasi CPU. Banyak model mengalami peningkatan performa saat komputasi CPU-nya dikelompokkan. Cara terbaik untuk melakukan komputasi CPU secara massal adalah menggunakan pengelompokan tanda tangan, tetapi mungkin tidak berfungsi untuk beberapa model. Dalam kasus tersebut, pengelompokan fungsi dapat digunakan untuk mengelompokkan bagian dari komputasi CPU selain komputasi TPU. Perhatikan bahwa operasi pengelompokan tidak dapat berjalan di TPU sehingga setiap fungsi pengelompokan yang disediakan harus dipanggil di CPU.
Pengelompokan fungsi juga dapat digunakan untuk memenuhi persyaratan bentuk yang ketat yang diberlakukan oleh operasi pengelompokan. Jika fungsi TPU tidak memenuhi persyaratan bentuk operasi pengelompokan, pengelompokan fungsi dapat digunakan untuk memberi tahu Konverter untuk mengelompokkan fungsi yang berbeda.
Untuk menggunakannya, buat function_alias untuk fungsi yang harus dikelompokkan. Anda dapat melakukannya dengan menemukan atau membuat fungsi dalam model
yang menggabungkan semua yang ingin Anda masukkan ke dalam batch. Pastikan fungsi ini memenuhi
persyaratan bentuk yang ketat
yang diberlakukan oleh operasi pengelompokan. Tambahkan @tf.function jika belum ada.
Penting untuk memberikan input_signature ke @tf.function. Dimensi
ke-0 harus None karena merupakan dimensi batch sehingga tidak boleh berupa
ukuran tetap. Misalnya, [None, 4], [None], atau [None, 128, 4, 10] semuanya
adalah bentuk input yang valid. Saat menyimpan model, berikan SaveOptions seperti yang ditunjukkan
di bawah untuk memberi model.batch_func alias "batch_func". Kemudian, Anda dapat meneruskan
alias fungsi ini ke pengonversi.
class ToyModel(tf.keras.Model): @tf.function(input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def batch_func(self, x): return x * 1.0 ... model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'batch_func': model.batch_func, }) tf.saved_model.save(model, model_dir, options=save_options)
Selanjutnya, teruskan function_alias menggunakan BatchOptions.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { function_alias: "batch_func" } }
Definisi opsi pengelompokan
num_batch_threads: (bilangan bulat) Jumlah thread penjadwalan untuk memproses batch pekerjaan. Menentukan jumlah batch yang diproses secara paralel. Jumlah ini harus kira-kira sesuai dengan jumlah core TPU yang tersedia.max_batch_size: (bilangan bulat) Ukuran batch maksimum yang diizinkan. Dapat lebih besar dariallowed_batch_sizesuntuk memanfaatkan pemisahan batch besar.batch_timeout_micros: (bilangan bulat) Jumlah maksimum mikrodetik yang akan ditunggu sebelum menghasilkan batch yang tidak lengkap.allowed_batch_sizes: (daftar bilangan bulat) Jika tidak kosong, daftar tersebut akan menambahkan batch hingga ukuran terdekat dalam daftar. Daftar harus bertambah secara monoton dan elemen terakhir harus lebih rendah dari atau sama denganmax_batch_size.max_enqueued_batches: (bilangan bulat) Jumlah maksimum batch yang dimasukkan ke antrean untuk diproses sebelum permintaan gagal dengan cepat.
Memperbarui opsi pengelompokan yang ada
Anda dapat menambahkan atau memperbarui opsi pengelompokan dengan menjalankan image Docker yang menentukan
batch_options dan menetapkan disable_default_optimizations ke true menggunakan
flag --converter_options_string. Opsi batch akan diterapkan ke setiap
fungsi TPU atau operasi pengelompokan yang sudah ada.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } disable_default_optimizations=True
Persyaratan bentuk pengelompokan
Batch dibuat dengan menggabungkan tensor input di seluruh permintaan di sepanjang dimensi batch (ke-0). Tensor output dibagi menurut dimensi ke-0. Untuk melakukan operasi ini, operasi pengelompokan memiliki persyaratan bentuk yang ketat untuk input dan output-nya.
Panduan
Untuk memahami persyaratan ini, sebaiknya pahami terlebih dahulu cara
pemrosesan batch dilakukan. Pada contoh di bawah, kita mengelompokkan op
tf.matmul sederhana.
def my_func(A, B) return tf.matmul(A, B)
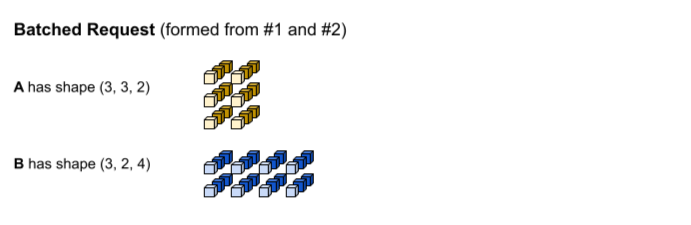
Permintaan inferensi pertama menghasilkan input A dan B dengan bentuk (1, 3,
2) dan (1, 2, 4). Permintaan inferensi kedua menghasilkan
input A dan B dengan bentuk (2, 3, 2) dan (2, 2, 4).

Waktu tunggu pengelompokan tercapai. Model ini mendukung ukuran batch 3 sehingga
permintaan inferensi #1 dan #2 dikelompokkan bersama tanpa padding. Tensor
yang dikelompokkan dibuat dengan menggabungkan permintaan #1 dan #2 di sepanjang dimensi
batch (ke-0). Karena A #1 memiliki bentuk (1, 3, 2) dan A #2 memiliki bentuk
(2, 3, 2), saat digabungkan di sepanjang dimensi batch (ke-0),
bentuk yang dihasilkan adalah (3, 3, 2).
tf.matmul dieksekusi dan menghasilkan output dengan bentuk (3, 3,
4).

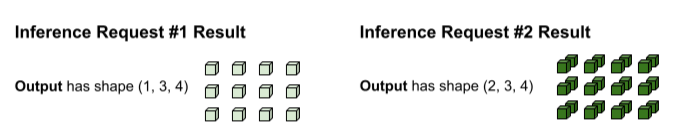
Output tf.matmul dikelompokkan sehingga perlu dibagi kembali menjadi
permintaan terpisah. Operasi pengelompokan melakukan hal ini dengan membagi dimensi batch (ke-0)
dari setiap tensor output. Fungsi ini menentukan cara memisahkan dimensi ke-0 berdasarkan
bentuk input asli. Karena bentuk permintaan #1 memiliki dimensi
ke-0 sebesar 1, output-nya memiliki dimensi ke-0 sebesar 1 untuk bentuk (1, 3, 4).
Karena bentuk permintaan #2 memiliki dimensi ke-0 sebesar 2, outputnya memiliki dimensi ke-0 sebesar 2 untuk bentuk (2, 3, 4).
Persyaratan Bentuk
Untuk melakukan penggabungan input dan pemisahan output yang dijelaskan di atas, operasi pengelompokan memiliki persyaratan bentuk berikut:
Input untuk pengelompokan tidak boleh berupa skalar. Untuk menyambungkan sepanjang dimensi ke-0, tensor harus memiliki minimal dua dimensi.
Dalam panduan di atas. A maupun B bukan skalar.
Kegagalan dalam memenuhi persyaratan ini akan menyebabkan error seperti:
Batching input tensors must have at least one dimension. Perbaikan sederhana untuk error ini adalah membuat skalar menjadi vektor.Di berbagai permintaan inferensi (misalnya, pemanggilan sesi yang berbeda), tensor input dengan nama yang sama memiliki ukuran yang sama untuk setiap dimensi kecuali dimensi ke-0. Hal ini memungkinkan input digabungkan dengan rapi di sepanjang dimensi ke-0.
Dalam panduan di atas, A permintaan #1 memiliki bentuk
(1, 3, 2). Artinya, setiap permintaan mendatang harus menghasilkan bentuk dengan pola(X, 3, 2). Permintaan #2 memenuhi persyaratan ini dengan(2, 3, 2). Demikian pula, B permintaan #1 memiliki bentuk(1, 2, 4)sehingga semua permintaan mendatang harus menghasilkan bentuk dengan pola(X, 2, 4).Kegagalan dalam memenuhi persyaratan ini akan menyebabkan error seperti:
Dimensions of inputs should match.Untuk permintaan inferensi tertentu, semua input harus memiliki ukuran dimensi ke-0 yang sama. Jika tensor input yang berbeda ke operasi pengelompokan memiliki dimensi ke-0 yang berbeda, operasi pengelompokan tidak tahu cara memisahkan tensor output.
Dalam panduan di atas, semua tensor permintaan #1 memiliki ukuran dimensi ke-0 sebesar 1. Hal ini memungkinkan operasi pengelompokan mengetahui bahwa outputnya harus memiliki ukuran dimensi ke-0 sebesar 1. Demikian pula, tensor permintaan #2 memiliki ukuran dimensi ke-0 sebesar 2, sehingga outputnya akan memiliki ukuran dimensi ke-0 sebesar 2. Saat operasi pengelompokan memisahkan bentuk akhir
(3, 3, 4), operasi tersebut akan menghasilkan(1, 3, 4)untuk permintaan #1 dan(2, 3, 4)untuk permintaan #2.Kegagalan dalam memenuhi persyaratan ini akan mengakibatkan error seperti:
Batching input tensors supplied in a given op invocation must have equal 0th-dimension size.Ukuran dimensi ke-0 dari setiap bentuk tensor output harus berupa jumlah semua ukuran dimensi ke-0 tensor input (ditambah padding yang diperkenalkan oleh operasi pengelompokan untuk memenuhi
allowed_batch_sizeterbesar berikutnya). Hal ini memungkinkan operasi pengelompokan untuk membagi tensor output di sepanjang dimensi ke-0 berdasarkan dimensi ke-0 tensor input.Dalam panduan di atas, tensor input memiliki dimensi ke-0 sebesar 1 dari permintaan #1 dan 2 dari permintaan #2. Oleh karena itu, setiap tensor output harus memiliki dimensi ke-0 sebesar 3 karena 1+2=3. Tensor output
(3, 3, 4)memenuhi persyaratan ini. Jika 3 bukan ukuran batch yang valid, tetapi 4 valid, operasi pengelompokan harus menambahkan dimensi ke-0 input dari 3 menjadi 4. Dalam hal ini, setiap tensor output harus memiliki ukuran dimensi ke-0 sebesar 4.Kegagalan dalam memenuhi persyaratan ini akan menyebabkan error seperti:
Batched output tensor's 0th dimension does not equal the sum of the 0th dimension sizes of the input tensors.
Mengatasi Error Persyaratan Bentuk
Untuk memenuhi persyaratan ini, pertimbangkan untuk memberikan fungsi atau tanda tangan yang berbeda ke batch. Anda mungkin juga perlu mengubah fungsi yang ada untuk memenuhi persyaratan ini.
Jika
fungsi
dikelompokkan, pastikan semua bentuk input_signature @tf.function-nya
memiliki None di dimensi ke-0 (alias dimensi batch). Jika
tanda tangan
dikelompokkan, pastikan semua inputnya memiliki -1 di dimensi ke-0.
Operasi BatchFunction tidak mendukung SparseTensors sebagai input atau output.
Secara internal, setiap tensor jarang direpresentasikan sebagai tiga tensor terpisah yang dapat
memiliki ukuran dimensi ke-0 yang berbeda.