TPU v4
本文档介绍了 Cloud TPU v4 的架构和支持的配置。
系统架构
每个 TPU v4 芯片包含两个 TensorCore。每个 TensorCore 都有四个矩阵乘法单元 (MXU)、一个向量单元和一个标量单元。下表展示了 v4 TPU Pod 的主要规范。
| 主要规范 | v4 Pod 值 |
|---|---|
| 每个芯片峰值计算能力 | 275 teraflop(bf16 或 int8) |
| HBM2 容量和带宽 | 32 GiB、1200 GBps |
| 测得的最小/平均/最大功率 | 90/170/192 W |
| TPU Pod 大小 | 4096 个芯片 |
| 互连拓扑 | 3D 网格 |
| 每个 Pod 的峰值计算能力 | 1.1 exaflop(bf16 或 int8) |
| 每个 Pod 的 All-reduce 带宽 | 1.1 PB/s |
| 每个 Pod 的对分带宽 | 24 TB/s |
下图展示了 TPU v4 芯片。
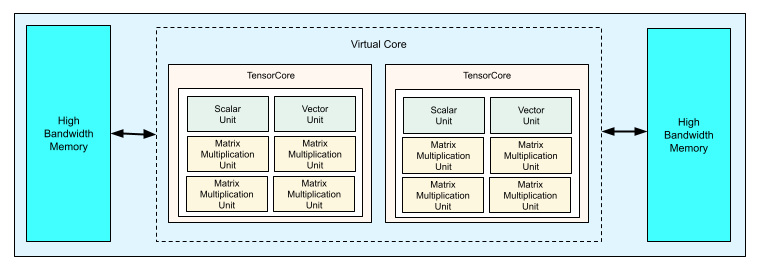
如需详细了解 TPU v4 的架构详情和性能特征,请参阅 TPU v4:适用于机器学习且可为嵌入提供硬件支持的光学可重配置超级计算机。
3D 网格和 3D 环面
v4 TPU 可在 3 个维度上与最近的相邻芯片直接连接,从而形成 3D 网格网络连接。连接可以在切片上配置为 3D 环面,其中拓扑 AxBxC 为 2A=B=C 或 2A=2B=C,其中每个维度都是 4 的倍数。例如,4x4x8、4x8x8 或 12x12x24。一般而言,3D 环面配置的性能将优于 3D 网格配置。如需了解详情,请参阅扭曲的环面拓扑。
TPU v4 相对于 v3 的性能优势
本部分介绍了在 TPU v4 上运行示例训练脚本的一种内存高效方式,以及 TPU v4 与 TPU v3 相比的性能提升。
内存系统
非统一内存访问 (NUMA) 是一种适用于具有多个 CPU 的机器的计算机内存架构。每个 CPU 都可以直接访问高速内存块。CPU 及其内存称为 NUMA 节点。NUMA 节点彼此相连,彼此直接相邻。一个 NUMA 节点的 CPU 可以访问另一个 NUMA 节点中的内存,但这种访问速度比访问 NUMA 节点中的内存慢。
在多 CPU 机器上运行的软件可以将 CPU 所需的数据放置在其 NUMA 节点中,从而提高内存吞吐量。如需详细了解 NUMA,请参阅维基百科上的非统一内存访问。
您可以将训练脚本绑定到 NUMA 节点 0,从而利用 NUMA 位置优势。
如需启用 NUMA 节点绑定,请执行以下操作:
安装 numactl 命令行工具。numactl 可让您使用特定的 NUMA 调度或内存布置政策运行进程。
$ sudo apt-get update $ sudo apt-get install numactl
将脚本代码绑定到 NUMA 节点 0。将 your-training-script 替换为训练脚本的路径。
$ numactl --cpunodebind=0 python3 your-training-script
在以下情况下,请启用 NUMA 节点绑定:
- 您的工作负载极其依赖于 CPU 工作负载(例如,图片分类、推荐工作负载),无论框架如何。
- 您使用的是没有 -pod 后缀的 TPU 运行时版本(例如
tpu-vm-tf-2.10.0-v4)。
其他内存系统差异:
- v4 TPU 芯片在整个芯片中具有统一的 32-GiB HBM 内存空间,可在两个芯片上 TensorCore 之间实现更好的协调。
- 使用最新的内存标准和速度提高了 HBM 性能。
- 改进了 DMA 性能分析,内置支持 512B 粒度的高性能步进。
TensorCore
- MXU 数量翻倍,时钟速率更高,可提供 275 TFLOPS 的最大性能。
- 移位和排列的带宽是原来的 2 倍。
- 适用于通用内存 (Cmem) 的加载存储区内存访问模型。
- 更快的 MXU 权重加载带宽和 8 位模式支持,可减少批次大小并缩短推理延迟时间。
芯片间互连
每个芯片有六个互连链路,可实现网络直径较小的网络拓扑。
其他
- x16 PCIE gen3 接口到主机(直接连接)。
- 改进了安全模型。
- 提高了能源效率。
配置
TPU v4 Pod 由 4096 个芯片组成,这些芯片通过可重配置的高速链路相互连接。借助 TPU v4 的灵活网络,您可以通过多种方式连接相同大小切片中的芯片。创建 TPU 切片时,您可以指定所需的 TPU 版本和 TPU 资源的数量。创建 TPU v4 切片时,您可以通过以下两种方式之一指定其类型和大小:AcceleratorType 和 AccleratorConfig。
使用 AcceleratorType
如果您未指定拓扑,请使用 AcceleratorType。如需使用 AcceleratorType 配置 v4 TPU,请在创建 TPU 切片时使用 --accelerator-type 标志。将 --accelerator-type 设置为包含 TPU 版本和您要使用的 TensorCore 数量的字符串。例如,如需创建具有 32 个 TensorCore 的 v4 切片,您需要使用 --accelerator-type=v4-32。
使用 gcloud compute tpus tpu-vm create 命令,通过 --accelerator-type 标志创建具有 512 个 TensorCore 的 v4 TPU 切片:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --accelerator-type=v4-512 \ --version=tpu-ubuntu2204-base
TPU 版本 (v4) 后面的数字指定了 TensorCore 的数量。v4 TPU 中有两个 TensorCore,因此 TPU 芯片的数量为 512/2 = 256。
如需详细了解如何管理 TPU,请参阅管理 TPU。如需详细了解 Cloud TPU 的系统架构,请参阅系统架构。
使用 AcceleratorConfig
如果您想自定义 TPU 切片的物理拓扑,请使用 AcceleratorConfig。通常,如果切片数超过 256 个,就需要进行性能调优。
如需使用 AcceleratorConfig 配置 v4 TPU,请使用 --type 和 --topology 标志。将 --type 设置为您要使用的 TPU 版本,并将 --topology 设置为切片中 TPU 芯片的物理排列方式。
您可以使用 3 元组 AxBxC 指定 TPU 拓扑,其中 A<=B<=C,并且 A、B、C 均 <= 4 4 或均为 4 的整数倍。值 A、B 和 C 是三个维度中其中一个的芯片数。例如,如需创建具有 16 个芯片的 v4 切片,您需要设置 --type=v4 和 --topology=2x2x4。
使用 gcloud compute tpus tpu-vm create 命令创建 128 个 TPU 芯片排列在 4x4x8 数组中的 v4 TPU 切片:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --type=v4 \ --topology=4x4x8 \ --version=tpu-ubuntu2204-base
在 2A=B=C 或 2A=2B=C 的拓扑中,拓扑变体也针对全对全通信进行了优化,例如 4×4×8、8×8×16 和 12×12×24。这些拓扑称为“扭曲的环面”拓扑。
以下插图展示了一些常见的 TPU v4 拓扑。
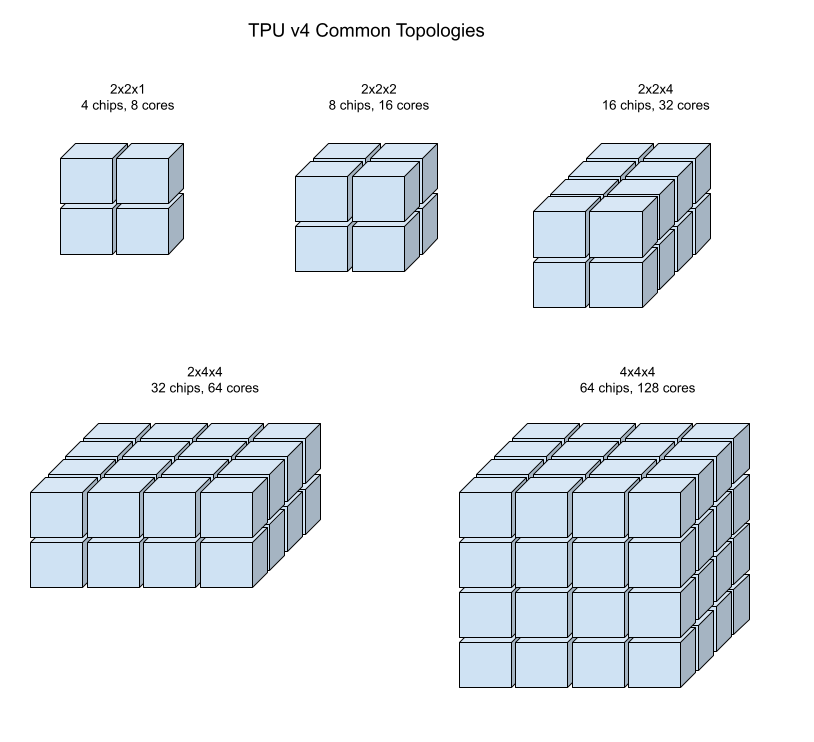
较大的切片可以由一个或多个 4x4x4“立方体”的芯片构建而成。
如需详细了解如何管理 TPU,请参阅管理 TPU。如需详细了解 Cloud TPU 的系统架构,请参阅系统架构。
扭曲的环面拓扑
某些 v4 3D 环面切片形状可以选择使用扭曲的环面拓扑。例如,两个 v4 立方体可以排列为 4x4x8 切片或 4x4x8_twisted。扭曲拓扑可提供明显较高的对分带宽。例如,具有 4x4x8_twisted 拓扑的切片在对分带宽方面比非扭曲的 4x4x8 切片理论上提高了 70%。对分带宽提高对于使用全局通信模式的工作负载非常有用。扭曲拓扑可以提高大多数模型的性能,而大型 TPU 嵌入工作负载受益最大。
对于仅使用数据并行策略的工作负载,扭曲拓扑的性能可能会略好一些。对于 LLM,使用扭曲拓扑的性能可能会因并行类型(DP、MP 等)而异。最佳实践是,在有和没有扭曲拓扑的情况下训练 LLM,以确定哪种情况可为模型提供最佳性能。在对 FSDP MaxText 模型进行的一些实验中,使用扭曲拓扑实现了 1-2 MFU 的改进。
扭曲拓扑的主要优势在于,它可以将非对称环面拓扑(例如 4×4×8)转换为密切相关的对称拓扑。对称拓扑具有许多优势:
- 改进了负载均衡
- 更高的对分带宽
- 数据包路由更短
这些优势最终会转化为许多全局通信模式的性能提升。
TPU 软件支持在切片上使用扭曲的环面,其中每个维度的大小等于最小维度的大小或为其两倍。例如 4x4x8、4×8×8 或 12x12x24。
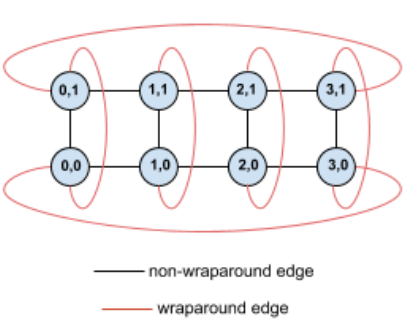
例如,请考虑以下 4×2 环面拓扑,其中 TPU 在切片中使用 (X,Y) 坐标标记:
为了清晰起见,此拓扑图中的边缘显示为无向边缘。实际上,每个边缘都是 TPU 之间的双向连接。我们将网格一侧与另一侧之间的边缘称为环绕边缘,如图所示。
通过扭曲此拓扑,我们最终得到完全对称的 4×2 扭曲环面拓扑:
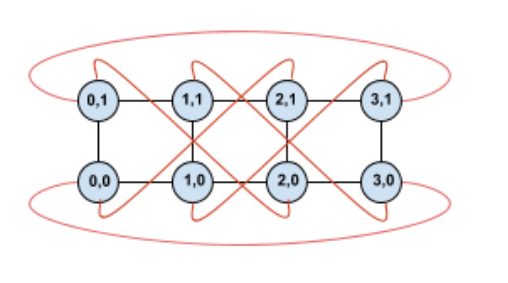
此图与上图之间的唯一变化在于 Y 环绕边缘。它们已被转移以连接到具有坐标 X+2 mod 4 的 TPU,而不是连接到具有相同 X 坐标的另一个 TPU。
同样的概念也适用于不同维度大小和不同维度数量。生成的网络是对称的,只要每个维度等于最小维度的大小或为其两倍。
如需详细了解如何在创建 Cloud TPU 时指定扭曲环面配置,请参阅使用 AcceleratorConfig。
下表展示了支持的扭曲拓扑,以及相对于非扭曲拓扑,使用这些拓扑时对分区带宽的理论增幅。
| 扭曲拓扑 | 与非扭曲环面相比对分带宽理论增加 |
|---|---|
| 4×4×8_twisted | ~70% |
| 8x8x16_twisted | |
| 12×12×24_twisted | |
| 4×8×8_twisted | ~40% |
| 8×16×16_twisted |
TPU v4 拓扑变体
一些包含相同数量的芯片的拓扑可以采用不同的方式进行排列。例如,可以使用以下拓扑来配置具有 512 个芯片(1024 个 TensorCore)的 TPU 切片:4x4x32、4x8x16 或 8x8x8。具有 2048 个芯片(4096 个 TensorCore)的 TPU 切片提供了更多拓扑选项:4x4x128、4x8x64、4x16x32 和 8x16x16。
与给定芯片数量关联的默认拓扑是与立方体最相似的拓扑。这种形状可能是数据并行机器学习训练的最佳选择。对于具有多种并行性的工作负载(例如,模型和数据并行性,或模拟的空间分区),其他拓扑可能非常有用。如果拓扑与所使用的并行性相匹配,这些工作负载的性能最佳。例如,在 X 维度上布置 4 路模型并行性,在 Y 和 Z 维度上布置 256 路数据并行性,则匹配 4x16x16 拓扑。
具有多个并行性维度的模型在将并行性维度映射到 TPU 拓扑维度时性能最佳。这些模型通常是数据和模型并行大语言模型 (LLM)。例如,对于拓扑为 8x16x16 的 TPU v4 切片,TPU 拓扑维度为 8、16 和 16。使用 8 路或 16 路模型并行性(映射到其中一个物理 TPU 拓扑维度)的性能更高。4 路模型并行性在这种拓扑中不太理想,因为它与任何 TPU 拓扑维度都不一致,但在相同数量的芯片上使用 4x16x32 拓扑时,它会达到最佳效果。
TPU v4 配置包含两组配置,一组是拓扑小于 64 个芯片(小型拓扑),另一组是拓扑大于 64 个芯片(大型拓扑)。
小型 v4 拓扑
Cloud TPU 支持以下小于 64 个芯片的 TPU v4 切片,即 4x4x4 立方体。您可以使用基于 TensorCore 的名称(例如 v4-32)或拓扑(例如 2x2x4)创建这些小型 v4 拓扑:
| 名称(基于 TensorCore 数量) | 芯片数量 | 拓扑 |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
大型 v4 拓扑
TPU v4 切片以 64 个芯片为增量提供,形状在三个维度上都是 4 的倍数。维度必须按升序排列。下表中展示了一些示例。其中一些“自定义”拓扑只能使用 --type 和 --topology 标志创建,因为有多种方式可以排列芯片。
| 名称(基于 TensorCore 数量) | 芯片数量 | 拓扑 |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
自定义拓扑:必须使用 --type 和 --topology 标志 |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
自定义拓扑:必须使用 --type 和 --topology 标志 |
1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |