Cloud TPU の概要
Tensor Processing Unit(TPU)は、Google 独自に開発された特定用途向け集積回路(ASIC)であり、機械学習ワークロードの高速化に使用されます。TPU ハードウェアの詳細については、システム アーキテクチャをご覧ください。 Cloud TPU は、TPU を Google Cloud でスケーラブルなコンピューティング リソースとして利用できるようにするウェブサービスです。
TPU は、機械学習アルゴリズムでよく見られる大規模な行列演算を実行するために設計されたハードウェアを使用して、モデルを効率的にトレーニングします。TPU にはオンチップの高帯域幅メモリ(HBM)が搭載されており、大きいモデルやバッチサイズを使用できます。TPU は Pod と呼ばれるグループに接続でき、コードをほとんど変更することなくワークロードをスケールアップできます。
仕組み
TPU の仕組みを理解するには、ML モデルのトレーニングにおける計算上の課題に、他のアクセラレータがどのように対処しているかを理解することが役立ちます。
CPU の仕組み
CPU は、フォンノイマン アーキテクチャに基づく汎用プロセッサです。つまり、CPU は以下に示すようにソフトウェアとメモリと連動して機能します。
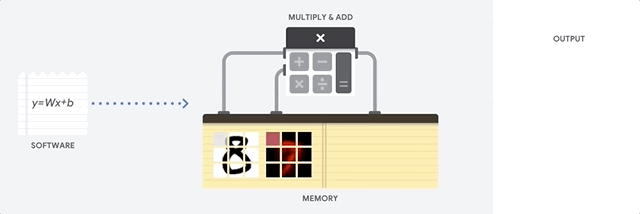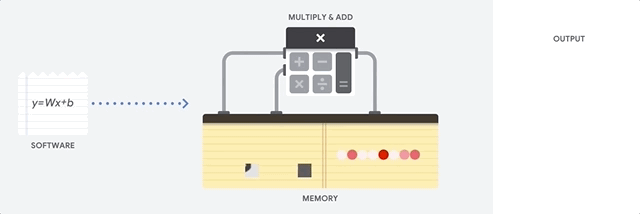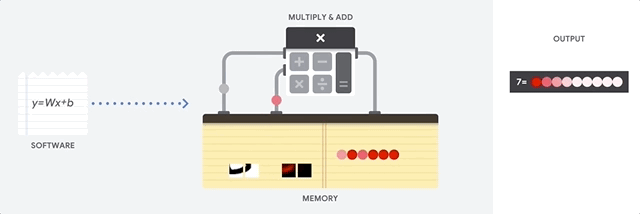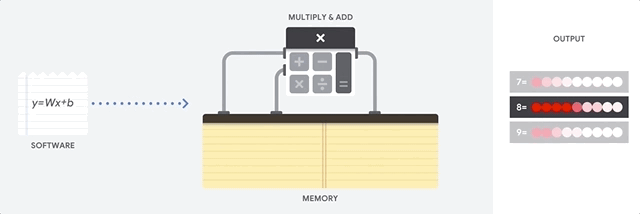
CPU の最大のメリットは、その柔軟性です。さまざまな種類のアプリケーションに対して、任意の種類のソフトウェアを CPU に読み込むことができます。たとえば、PC での文書処理、ロケット エンジンの制御、銀行取引、さらにはニューラル ネットワークを使用した画像分類にも CPU を使用できます。
CPU はメモリから値を読み込み、計算を行い、すべての計算結果をメモリに保存します。メモリアクセスは、計算速度に比べて遅く、CPU の総スループットを制限することがあります。これはフォンノイマン ボトルネックとも呼ばれます。
GPU の仕組み
スループットを向上させるため、GPU には単一のプロセッサ内に数千の算術論理演算ユニット(ALU)が含まれています。最新の GPU には、通常 2,500~5,000 個の ALU が含まれています。大量のプロセッサが存在するということは、数千の乗算と加算を同時に実行できるということになります。

ニューラル ネットワークでの行列演算のように大量の並列処理を行うアプリケーションでは、この GPU アーキテクチャが効果を発揮します。実際、ディープ ラーニングの一般的なトレーニング ワークロードでは、GPU によって CPU とは桁違いのスループットを達成できます。
しかし、GPU が汎用プロセッサであることに変わりはなく、数多くのアプリケーションやソフトウェアをサポートしなければなりません。したがって、GPU にも CPU と同じ問題があります。何千もの ALU で行われるすべての計算で、GPU はレジスタや共有メモリにアクセスして、オペランドを読み取り、計算の中間結果保存しなければなりません。
TPU の仕組み
Cloud TPU は、Google がニューラル ネットワークのワークロードに特化して設計した行列プロセッサです。TPU は文書処理、ロケット エンジンの制御、銀行取引といった操作に対応できませんが、ニューラル ネットワークで使用される大規模な行列演算は極めて高速に処理できます。
TPU の主なタスクは、乗算演算と累積演算の組み合わせである行列処理です。TPU には数千の乗算アキュムレータが含まれています。これらは、直接接続して大規模な物理マトリックスを形成しています。この構造は、シストリック アレイ アーキテクチャと呼ばれています。Cloud TPU v3 では、単一プロセッサ上に 128 x 128 ALU のシストリック アレイが 2 つあります。
TPU ホストは、インフィード キューにデータをストリーミングします。TPU は、インフィード キューからデータを読み込んで HBM メモリに保存します。計算が完了すると、TPU は結果をアウトフィード キューに読み込みます。TPU ホストは次に、アウトフィード キューから結果を読み取り、ホストのメモリに保存します。
行列演算を実行するために、TPU は HBM メモリからパラメータを Matrix Multiplication Unit(MXU)に読み込みます。

続いて、TPU は HBM メモリからデータを読み込みます。乗算が行われるたびに、その結果が次の乗算アキュムレータに渡されます。データとパラメータの乗算結果をすべて合計したものが出力となります。 行列乗算処理中にメモリアクセスは必要ありません。
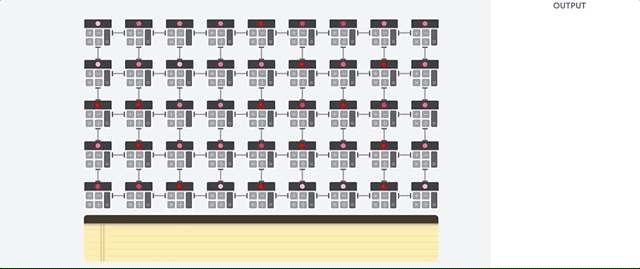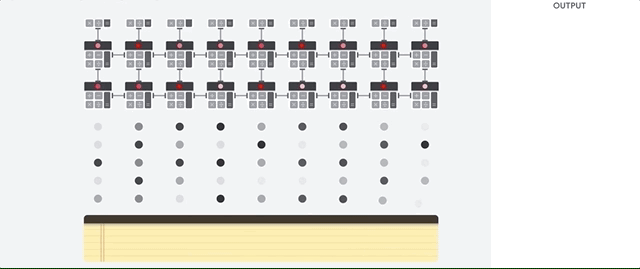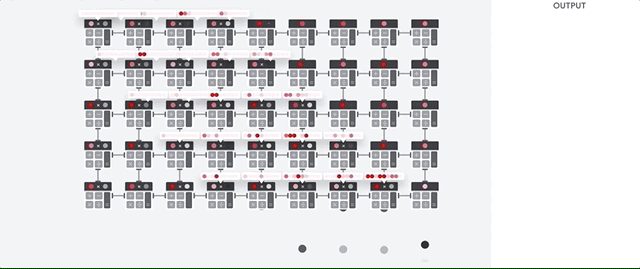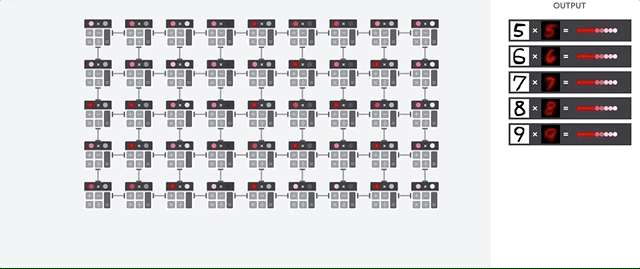
その結果、TPU はニューラル ネットワークにおいて、高い演算スループットを達成できます。
XLA コンパイラ
TPU で実行されるコードは、アクセラレータ線形代数(XLA)コンパイラでコンパイルする必要があります。XLA は、ML フレームワーク アプリケーションによって出力されたグラフを受け取り、グラフの線形代数、損失、勾配のコンポーネントを TPU マシンコードにコンパイルするジャストインタイム コンパイラです。プログラムの残りの部分は TPU ホストマシンで実行されます。XLA コンパイラは、TPU ホストマシンで実行される TPU VM イメージの一部です。
TPU の用途
Cloud TPU は特定のワークロード用に最適化されています。状況によっては、Compute Engine インスタンスで GPU または CPU を使用して機械学習ワークロードを実行する場合があります。一般に、次のガイドラインに基づいてワークロードに最適なハードウェアを決定できます。
CPU
- 最大限の柔軟性を必要とする迅速なプロトタイピング
- トレーニングに時間がかからない単純なモデル
- 実際のバッチサイズが小さい小規模なモデル
- C++ で記述されたカスタム TensorFlow 演算が多く含まれるモデル
- ホストシステムの使用可能な I/O またはネットワーク帯域幅によって制限が課せられるモデル
GPU
- CPU 上で少なくとも部分的に実行しなければならない多数のカスタムの TensorFlow / PyTorch / JAX 演算を使用するモデル
- Cloud TPU で利用できない TensorFlow 演算を使用するモデル(利用可能な TensorFlow 演算のリストをご覧ください)
- 実際のバッチサイズが大きい中~大規模なモデル
TPU
- 行列計算が多くを占めるモデル
- メインのトレーニング ループ内にカスタムの TensorFlow / PyTorch / JAX 演算がないモデル
- トレーニングに数週間または数か月かかるモデル
- 実際のバッチサイズが大きい大規模なモデル
Cloud TPU は、以下のワークロードには適していません。
- 頻繁な分岐を必要とするか、要素ごとの代数演算を多く含む線形代数プログラム
- メモリにあまりアクセスしないワークロード
- 高精度の演算を必要とするワークロード
- メインのトレーニング ループにカスタム演算が含まれるニューラル ネットワーク ワークロード
モデル開発のベスト プラクティス
計算の多くを非行列演算(加算、再形成、連結など)が占めるプログラムは、MXU 使用率が高くならない可能性があります。次に、Cloud TPU に適したモデルを選択して作成する際に役立つガイドラインを示します。
レイアウト
XLA コンパイラでは、マトリックス ユニット(MXU)で効率的に計算を実行するために、行列乗算をより小さなブロックにタイリングするなどのコード変換が行われます。MXU ハードウェアの構造、128x128 のシストリック アレイ、8 の倍数の次元を基本とする TPU のメモリ サブシステムの設計が、タイリングの効率化のために XLA コンパイラによって使用されます。その結果、特定のレイアウトはタイリングに役立ちますが、他のレイアウトではタイリングの前に再形成が必要になります。再形成オペレーションは、多くの場合、Cloud TPU でメモリバウンドです。
図形
XLA コンパイラによって、最初のバッチに合わせて ML グラフがコンパイルされます。後続のバッチに異なる形状がある場合、モデルは機能しません。(形状が変化するたびにグラフを再コンパイルするのでは遅すぎます)。したがって、動的形状を持つテンソルがあるモデルは、TPU にはあまり適していません。
パディング
高パフォーマンスの Cloud TPU プログラムは、密な計算を 128x128 のチャンクにタイリングできるプログラムです。MXU 全体が行列計算で占有されない場合、コンパイラによってテンソルはゼロでパディングされます。パディングには次の 2 つの欠点があります。
- ゼロでパディングされたテンソルでは、TPU コアの利用が不十分になります。
- パディングによって、テンソルに必要なオンチップ メモリ ストレージ量が増加し、極端な場合にはメモリ不足エラーにつながる可能性があります。
パディングは必要に応じて XLA コンパイラによって自動的に行われますが、op_profile ツールを使用して、行われるパディングの量を決定できます。TPU に適したテンソル次元を選択することで、パディングを回避できます。
ディメンション
適切なテンソル次元を選択すると、TPU ハードウェア、特に MXU から最大のパフォーマンスを引き出すために役立ちます。XLA コンパイラは、バッチサイズまたは特徴ディメンションのいずれかを使用して MXU を最大限に利用しようとします。したがって、これらのいずれかは 128 の倍数である必要があります。そうでない場合、コンパイラによっていずれかが 128 までパディングされます。理想的には、バッチサイズとフィーチャ次元は 8 の倍数である必要があり、これによりメモリ サブシステムから高パフォーマンスを引き出すことができます。
VPC Service Controls の統合
Cloud TPU の VPC Service Controls を使用して、Cloud TPU リソースのセキュリティ境界を定義し、その境界をまたがるデータの移動を制御できます。VPC Service Controls の詳細については、VPC Service Controls の概要をご覧ください。 VPC Service Controls とともに Cloud TPU を使用する際の制限事項については、サポートされているプロダクトと制限事項をご覧ください。
Edge TPU
クラウドでトレーニングされた機械学習モデルは、「エッジ」(モノのインターネット(IoT)のエッジで動作するデバイス)で推論を実行する必要があります。こうしたデバイスには、リアルタイムのデータを収集し、インテリジェントな意思決定を行った後で、アクションしたり、他のデバイスやクラウドに情報を伝えるセンサーや他のスマート デバイスがあります。
このようなデバイスは限られた電力(電池を含む)で動作する必要があるため、Google は Edge TPU コプロセッサを低電力デバイス上で ML 推論を高速化するように設計しました。個々の Edge TPU は 1 秒間に 4 兆回のオペレーション(4 TOPS)を実行できますが、2 ワットの電力しか消費しません。言い換えると、1 ワットあたり 2 TOPS です。たとえば、Edge TPU では電力消費を抑えつつ、MobileNet V2 などの最先端のモバイル ビジョンモデルを約 400 フレーム / 秒で実行できます。
この低消費電力 ML アクセラレータは、Cloud TPU と Cloud IoT を強化し、エンドツーエンド(クラウドツーエッジ、ハードウェア + ソフトウェア)のインフラストラクチャを提供します。これにより、AI ベースのソリューションの提供が簡単になります。
Edge TPU は、シングルボード コンピュータ、システム オンモジュール、PCIe/M.2 カード、サーフェス マウント モジュールなど、さまざまなフォーム ファクタのプロトタイピング デバイスと製品版デバイスで利用可能です。Edge TPU とすべての利用可能な製品の詳細については、coral.ai をご覧ください。
Cloud TPU のスタートガイド
- Google Cloud アカウントの設定
- Cloud TPU API を有効にする
- Cloud Storage TPU に Cloud Storage バケットへのアクセスを許可する
- TPU で基本的な計算を実行する
- TPU でリファレンス モデルをトレーニングする
- モデルを分析する
サポートの依頼
Cloud TPU サポートにお問い合わせください。アクティブな Google Cloud プロジェクトがある場合は、次の情報を提供できるようにしてください。
- Google Cloud プロジェクト ID
- TPU 名(存在する場合)
- ご提供いただく必要があるその他の情報
次のステップ
Cloud TPU の詳細を調べるには、次のリソースも役立ちます。