Introdução ao Cloud TPU
As unidades de processamento de tensor (TPUs) são circuitos integrados de aplicação específica (ASICs, na sigla em inglês) desenvolvidos especialmente pelo Google. Elas são usadas para acelerar as cargas de trabalho de machine learning. Para mais informações sobre o hardware de TPU, consulte Arquitetura do sistema. O Cloud TPU é um serviço da Web que disponibiliza TPUs como recursos de computação escalonáveis no Google Cloud.
As TPUs treinam seus modelos com mais eficiência se usarem hardwares projetados para executar operações de matriz de grande escala, geralmente encontradas em algoritmos de machine learning. As TPUs têm memória de alta largura de banda no chip (HBM), o que permite usar modelos e tamanhos de lote maiores. As TPUs podem ser conectadas em grupos chamados Pods, que escalonar verticalmente as cargas de trabalho com pouca ou nenhuma alteração no código.
Como funciona?
Para entender como as TPUs funcionam, vale a pena entender como outros aceleradores lidam com os desafios computacionais do treinamento de modelos de ML.
Como funciona uma CPU
Uma CPU é um processador de uso geral baseado na arquitetura de von Neumann. Isso significa que uma CPU trabalha com software e memória, assim:
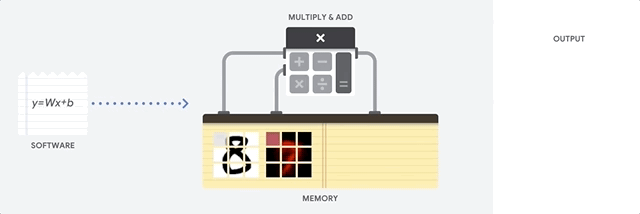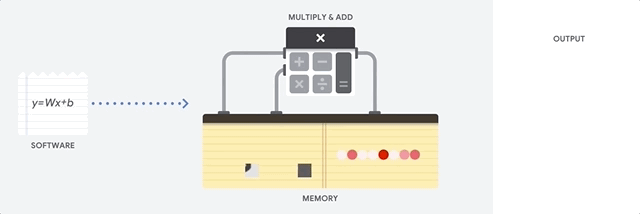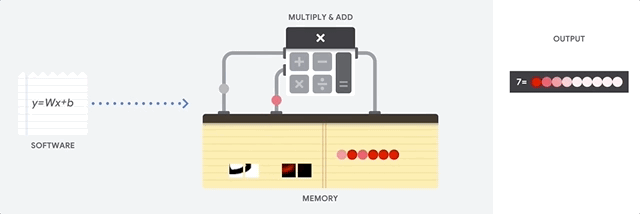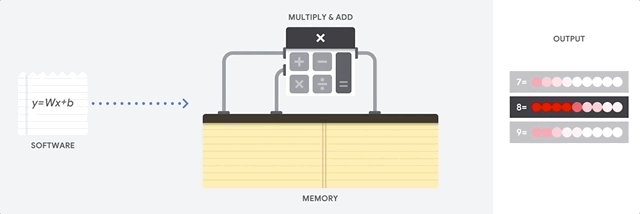
O maior benefício das CPUs é a flexibilidade. É possível carregar qualquer tipo de software em uma CPU para vários tipos diferentes de aplicativos. Por exemplo, é possível usar uma CPU para processar texto em um PC, controlar motores de foguete, executar transações bancárias ou classificar imagens com uma rede neural.
Uma CPU carrega valores da memória, realiza um cálculo com base nos valores e armazena o resultado de cada cálculo na memória. O acesso à memória é lento quando comparado à velocidade do cálculo e pode limitar a capacidade total das CPUs. Isso geralmente é chamado de gargalo de von Neumann.
Como funciona uma GPU
Para aumentar a capacidade de processamento, as GPUs contêm milhares de unidades lógicas aritméticas (ALUs, na sigla em inglês) em um único processador. Uma GPU moderna geralmente contém entre 2.500 e 5.000 ALUs. O grande número de processadores significa que é possível executar milhares de multiplicações e adições simultaneamente.

Essa arquitetura de GPU funciona bem em aplicativos com enorme paralelismo, como a operação de matrizes em uma rede neural. Na verdade, em uma carga de trabalho de treinamento típica para aprendizado profundo, uma GPU fornece uma ordem de grandeza maior do que uma CPU.
No entanto, a GPU ainda é um processador de uso geral que precisa ser compatível com vários aplicativos e softwares diferentes. Portanto, as GPUs têm o mesmo problema que as CPUs. Para cada cálculo nas milhares de ALUs, uma GPU precisa acessar registros ou memória compartilhada para ler e armazenar os resultados de cálculos intermediários.
Como funciona uma TPU
O Google projetou as Cloud TPUs como um processador de matriz especializado em cargas de trabalho de redes neurais. As TPUs não podem executar processadores de texto, controlar mecanismos de foguete ou executar transações bancárias, mas podem processar operações de matriz em massa usadas em redes neurais em velocidades muito rápidas.
A principal tarefa das TPUs é o processamento de matrizes, que é uma combinação de operações de multiplicação e acumulação. As TPUs contêm milhares de acumuladores de multiplicação que estão diretamente conectados entre si para formar uma matriz física grande. Isso é chamado de arquitetura de matriz sistólica. O Cloud TPU v3 contém duas matrizes sistólicas de 128 x 128 ALUs em um único processador.
O host da TPU transmite os dados para uma fila de entrada. A TPU carrega dados da fila de alimentação e os armazena na memória HBM. Quando a computação é concluída, a TPU carrega os resultados na fila de saída. Em seguida, o host da TPU lê os resultados da fila de saída e os armazena na memória do host.
Para executar as operações de matriz, a TPU carrega os parâmetros da memória HBM na unidade de multiplicação de matrizes (MXU).

Em seguida, ela carrega dados da memória HBM. Conforme cada multiplicação é executada, o resultado é transmitido para o próximo acumulador de multiplicação. A saída é a soma de todos os resultados de multiplicação entre os dados e os parâmetros. Não é necessário acessar a memória durante o processo de multiplicação de matrizes.
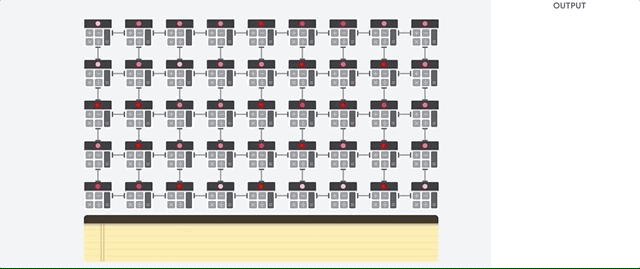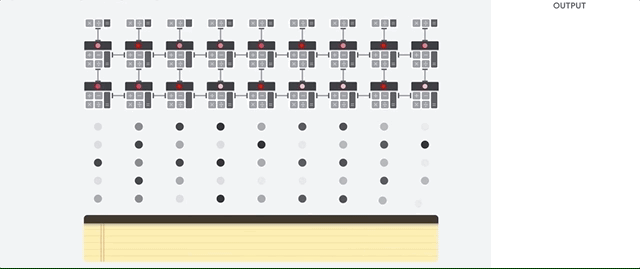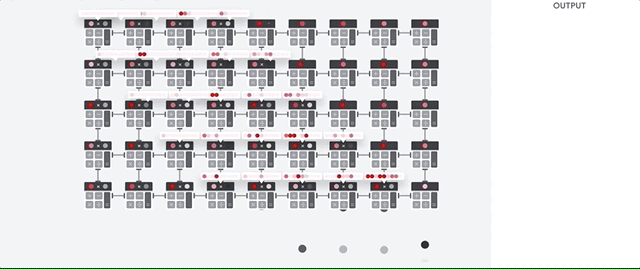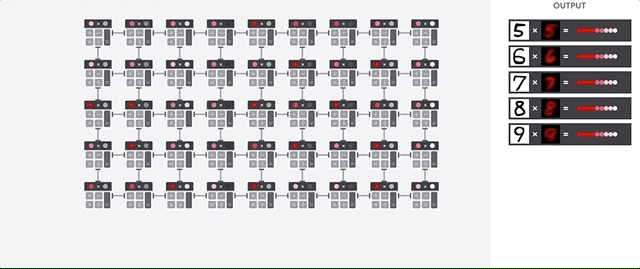
Como resultado, as TPUs podem alcançar uma alta capacidade computacional em cálculos de redes neurais.
Compilador XLA
O código executado em TPUs precisa ser compilado pelo compilador de álgebra linear acelerada (XLA, na sigla em inglês). A XLA é um compilador just-in-time que usa o gráfico emitido por um aplicativo de framework de ML e compila os componentes de álgebra linear, perda e gradiente do gráfico em código de máquina TPU. O restante do programa é executado na máquina host da TPU. O compilador XLA faz parte da imagem da VM da TPU que é executada em uma máquina host da TPU.
Quando usar TPUs
Os Cloud TPUs são otimizados para cargas de trabalho específicas. Em algumas situações, é recomendável usar GPUs ou CPUs em instâncias do Compute Engine para executar cargas de trabalho de aprendizado de máquina. Em geral, é possível decidir qual hardware é melhor para sua carga de trabalho com base nas diretrizes a seguir:
CPUs
- prototipagem rápida que requer flexibilidade máxima
- modelos simples que não levam muito tempo para serem treinados
- modelos pequenos com tamanhos de lotes menores
- Modelos que contêm muitas operações personalizadas do TensorFlow escritas em C++
- modelos limitados por E/S disponíveis ou pela largura de banda de rede do sistema host;
GPUs
- modelos com um número significativo de operações personalizadas do TensorFlow/PyTorch/JAX que precisam ser executadas pelo menos parcialmente nas CPUs.
- Modelos com operações do TensorFlow que não estão disponíveis no Cloud TPU (consulte a lista de operações do TensorFlow disponíveis)
- modelos de médio a grande porte com tamanhos de lote maiores
TPUs
- modelos com preponderância de computações matriciais
- Modelos sem operações personalizadas do TensorFlow/PyTorch/JAX no loop de treinamento principal
- modelos com treinamento de semanas ou meses
- modelos grandes com tamanhos grandes de lote efetivo
- Modelos com embeddings ultragrandes comuns em cargas de trabalho de classificação avançada e recomendação
Os Cloud TPUs não são adequados para as seguintes cargas de trabalho:
- Programas algébricos lineares que requerem ramificação frequente ou contêm muitas operações algébricas de elemento
- Cargas de trabalho que exigem aritmética de alta precisão
- Cargas de trabalho de rede neural com operações personalizadas no loop de treinamento principal
Práticas recomendadas para o desenvolvimento de modelos
Um programa com computação dominada por operações não matriciais, como "add", "reshape" ou "concatenate", provavelmente não atingirá uma alta utilização de MXU. Confira a seguir algumas diretrizes que ajudam a escolher e criar modelos adequados para o Cloud TPU.
Layout
O compilador XLA executa transformações no código, incluindo a divisão do produto de matrizes em blocos menores para executar computações na MXU com mais eficiência. A estrutura do hardware da MXU (um arranjo sistólico de 128x128) e o design do subsistema de memória da TPU (que preferencialmente usa dimensões que são múltiplas de oito) são usados pelo compilador XLA para aumentar a eficiência da divisão em blocos. Por consequência, determinados layouts são mais propícios para a divisão em blocos, enquanto outros requerem a realização de remodelações antes da divisão. As operações de remodelação geralmente são limitadas pela memória no Cloud TPU.
Formas
O compilador XLA compila um gráfico de ML a tempo para o primeiro lote. Se os lotes subsequentes tiverem formas diferentes, o modelo não vai funcionar. Compilar novamente o gráfico sempre que a forma muda é um processo muito lento. Portanto, qualquer modelo que tenha tensores com formas dinâmicas não é adequado para TPUs.
Preenchimento
Programas de alto desempenho do Cloud TPU são aqueles com computação densa que pode ser facilmente dividida em blocos de 128 x 128. Quando uma computação de matriz não ocupa uma MXU inteira, o compilador preenche os tensores com zeros. O preenchimento apresenta duas desvantagens:
- Os tensores preenchidos com zeros utilizam pouco o núcleo da TPU.
- O preenchimento aumenta a quantidade de armazenamento em memória on-chip necessária para um tensor, o que pode resultar em erro de falta de memória em casos extremos.
O preenchimento é realizado automaticamente pelo compilador XLA quando necessário. No entanto, é possível determinar a quantidade de preenchimento por meio da ferramenta op_profile. Para evitar o preenchimento, escolha dimensões de tensor que sejam adequadas para as TPUs.
Dimensões
Escolher as dimensões de tensores adequadas ajuda muito para conseguir o máximo de desempenho do hardware da TPU, especialmente da MXU. O compilador XLA tenta usar o tamanho do lote ou uma dimensão de recurso para maximizar o uso da MXU. Portanto, um desses deve ser um múltiplo de 128. Caso contrário, o compilador preencherá um desses valores até chegar em 128. De preferência, o tamanho do lote e as dimensões da característica devem ser múltiplos de oito, permitindo, assim, conseguir um alto desempenho do subsistema de memória.
Integração do VPC Service Controls
O VPC Service Controls do Cloud TPU permite definir perímetros de segurança em torno dos recursos do Cloud TPU e controlar a movimentação de dados no limite do perímetro. Para saber mais sobre o VPC Service Controls, consulte a visão geral sobre ele. Para saber mais sobre as limitações de uso da Cloud TPU com os VPC Service Controls, consulte os produtos e limitações com suporte.
Edge TPU
Os modelos de machine learning treinados na nuvem precisam executar cada vez mais inferências no nível mais avançado, ou seja, em dispositivos que operam no limite da Internet das coisas (IoT). Esses dispositivos incluem sensores e outros dispositivos inteligentes que reúnem dados em tempo real, tomam decisões inteligentes e, em seguida, realizam ações ou comunicam informações a outros dispositivos ou à nuvem.
Como esses dispositivos precisam funcionar com energia limitada, o Google desenvolveu o coprocessador Edge TPU para acelerar a inferência de ML em dispositivos de baixa potência. Um Edge TPU individual pode executar quatro trilhões de operações por segundo (4 TOPS) usando apenas 2 watts de energia. Em outras palavras, você recebe 2 TOPS por watt. Por exemplo, o Edge TPU pode executar modelos de última geração para dispositivos móveis, como o MobileNet V2, em quase 400 frames por segundo e com eficiência de consumo de energia.
Esse acelerador de ML de baixo consumo aumenta o Cloud TPU e o Cloud IoT para fornecer uma infraestrutura completa (nuvem para hardware, hardware e software) que facilita suas soluções baseadas em IA.
O Edge TPU está disponível para dispositivos de prototipagem e produção em vários formatos, incluindo um computador de placa única, um sistema em módulo, uma placa PCIe/M.2 e um módulo para superfície. Para mais informações sobre o Edge TPU e todos os produtos disponíveis, visite coral.ai.
Primeiros passos com o Cloud TPU
- Configurar uma conta do Google Cloud
- Ativar a API Cloud TPU
- Conceda ao Cloud TPU acesso aos seus buckets do Cloud Storage
- Executar um cálculo básico em uma TPU
- Treinar um modelo de referência em uma TPU
- Analisar seu modelo
Como pedir ajuda
Entre em contato com o suporte do Cloud TPU. Se você tiver um projeto ativo do Google Cloud, esteja preparado para fornecer as seguintes informações:
- ID do seu projeto do Google Cloud
- O nome da TPU, se houver
- Outras informações que você quer fornecer
A seguir
Quer saber mais sobre o Cloud TPU? Os recursos a seguir podem ajudar: