TPU v3
Questo documento descrive l'architettura e le configurazioni supportate di Cloud TPU v3.
Architettura di sistema
Ogni chip TPU v3 contiene due TensorCore. Ogni Tensor Core ha due unità di moltiplicazione a matrice (MXU), un'unità vettoriale e un'unità scalare. La tabella seguente mostra le specifiche principali e i relativi valori per un pod TPU v3.
| Specifiche principali | Valori del pod v3 |
|---|---|
| Potenza di calcolo di picco per chip | 123 teraflops (bf16) |
| Capacità e larghezza di banda HBM2 | 32 GiB, 900 GBps |
| Potenza minima/media/massima misurata | 123/220/262 W |
| Dimensioni del pod TPU | 1024 chip |
| Topologia di interconnessione | Toro 2D |
| Potenza di picco per pod | 126 petaflops (bf16) |
| Larghezza di banda all-reduce per pod | 340 TB/s |
| Larghezza di banda bisezionale per pod | 6,4 TB/s |
Il seguente diagramma mostra un chip TPU v3.
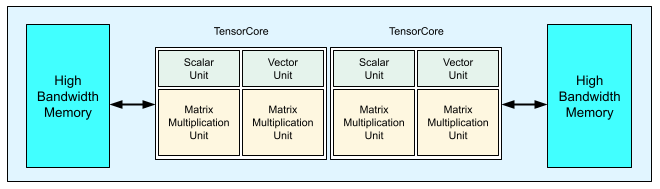
I dettagli dell'architettura e le caratteristiche di prestazioni di TPU v3 sono disponibili in A Domain Specific Supercomputer for Training Deep Neural Networks.
Vantaggi in termini di prestazioni della TPU v3 rispetto alla v2
L'aumento di FLOPS per TensorCore e della capacità di memoria nelle configurazioni TPU v3 puoi migliorare le prestazioni dei tuoi modelli nei seguenti modi:
Le configurazioni TPU v3 offrono vantaggi significativi in termini di prestazioni per ogni TensorCore per i modelli con vincoli di calcolo. I modelli con vincoli di memoria nelle configurazioni TPU v2 potrebbero non ottenere lo stesso miglioramento delle prestazioni se sono vincolati anche dalla memoria nelle configurazioni TPU v3.
Nei casi in cui i dati non rientrano nella memoria delle configurazioni TPU v2, TPU v3 può offrire prestazioni migliorate e ridurre il ricomputo dei valori intermedi (rematerializzazione).
Le configurazioni TPU v3 possono eseguire nuovi modelli con dimensioni dei batch che non erano supportate dalle configurazioni TPU v2. Ad esempio, TPU v3 potrebbe consentire modelli ResNet più profondi e immagini più grandi con RetinaNet.
I modelli quasi vincolati dall'input ("infeed") su TPU v2 perché i passaggi di addestramento sono in attesa di input potrebbero essere vincolati dall'input anche con Cloud TPU v3. La guida sul rendimento della pipeline può aiutarti a risolvere i problemi infeed.
Configurazioni
Un pod TPU v3 è composto da 1024 chip interconnessi con link ad alta velocità. Per
creare un dispositivo o una sezione TPU v3, utilizza il flag --accelerator-type
nel comando di creazione della TPU (gcloud compute tpus tpu-vm). Specifica il tipo di acceleratore specificando la
versione TPU e il numero di core TPU. Ad esempio, per una singola TPU v3, utilizza
--accelerator-type=v3-8. Per una sezione v3 con 128 TensorCore, utilizza
--accelerator-type=v3-128.
La tabella seguente elenca i tipi di TPU v3 supportati:
| Versione TPU | Fine del supporto |
|---|---|
| v3-8 | (Data di fine non ancora impostata) |
| v3-32 | (Data di fine non ancora impostata) |
| v3-128 | (Data di fine non ancora impostata) |
| v3-256 | (Data di fine non ancora impostata) |
| v3-512 | (Data di fine non ancora impostata) |
| v3-1024 | (Data di fine non ancora impostata) |
| v3-2048 | (Data di fine non ancora impostata) |
Il seguente comando mostra come creare una sezione TPU v3 con 128 TensorCore:
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=europe-west4-a \ --accelerator-type=v3-128 \ --version=tpu-ubuntu2204-base
Per saperne di più sulla gestione delle TPU, consulta Gestire le TPU. Per ulteriori informazioni sull'architettura di sistema di Cloud TPU, consulta Architettura di sistema.