TPU v3
이 문서에서는 Cloud TPU v3의 아키텍처와 지원되는 구성을 설명합니다.
시스템 아키텍처
각 v3 TPU 칩에는 2개의 TensorCore가 포함됩니다. 각 TensorCore에는 2개의 행렬 곱셈 단위(MXU), 벡터 단위, 스칼라 단위가 있습니다. 다음 표는 v3 TPU Pod의 키 사양과 값을 보여줍니다.
| 주요 사양 | v3 포드 값 |
|---|---|
| 칩당 최고 컴퓨팅 | 123테라플롭(bf16) |
| HBM2 용량 및 대역폭 | 32GiB, 900GBps |
| 측정된 최소/평균/최대 전력 | 123/220/262W |
| TPU Pod 크기 | 칩 1,024개 |
| 상호 연결 토폴로지 | 2D 토러스 |
| 포드당 최고 컴퓨팅 | 126페타플롭(bf16) |
| 포드당 올리듀스 대역폭 | 340TB/초 |
| 포드당 바이섹션 대역폭 | 6.4TB/초 |
다음 다이어그램은 TPU v3 칩을 보여줍니다.
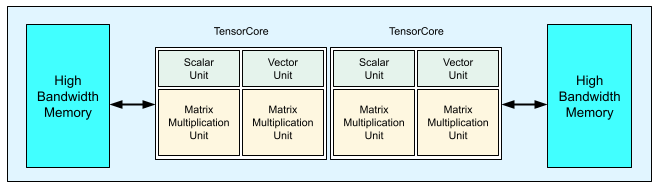
TPU v3의 아키텍처 세부정보 및 성능 특성은 심층신경망 학습용 도메인별 슈퍼 컴퓨터에서 확인할 수 있습니다.
TPU v3와 v2의 성능 이점 비교
TPU v3 구성의 늘어난 TensorCore당 FLOPS와 메모리 용량은 다음과 같은 방식으로 모델의 성능을 개선할 수 있습니다.
TPU v3 구성은 연산 제약 모델의 TensorCore당 성능 측면에서 상당한 이점을 제공합니다. TPU v2 구성의 메모리 제약 모델이 TPU v3 구성에서도 메모리의 제약을 받는 경우 이와 같은 수준의 성능 개선을 달성하지 못할 수 있습니다.
TPU v2 구성에서 데이터가 메모리에 들어가지 않는 경우 TPU v3으로 성능을 높이고 중간 값 재계산(재구체화)을 줄일 수 있습니다.
TPU v3 구성에서는 TPU v2 구성에서 맞지 않았던 배치 크기로 새 모델을 실행할 수 있습니다. 예를 들어 TPU v3은 더 깊은 ResNet 모델 및 RetinaNet에서 더 큰 이미지를 허용할 수 있습니다.
학습 단계에서 입력을 기다리는 이유로 TPU v2에서 거의 입력에 제약을 받은('인피드') 모델은 Cloud TPU v3에서도 입력에 제약을 받을 수 있습니다. 파이프라인 성능 가이드가 인피드 문제를 해결하는 데 도움이 될 수 있습니다.
구성
TPU v3 Pod는 고속 링크로 상호 연결된 1,024개의 칩으로 구성되어 있습니다. TPU v3 기기 또는 슬라이스를 만들려면 TPU 만들기 명령어(gcloud compute tpus tpu-vm)에 --accelerator-type 플래그를 사용합니다. TPU 버전과 TPU 코어 수를 지정하여 가속기 유형을 지정합니다. 예를 들어 단일 v3 TPU의 경우 --accelerator-type=v3-8을 사용합니다. TensorCore 128개가 포함된 v3 슬라이스의 경우 --accelerator-type=v3-128을 사용합니다.
다음 표에는 지원되는 v3 TPU 유형이 나열되어 있습니다.
| TPU 버전 | 지원 종료 |
|---|---|
| v3-8 | (종료일 미정) |
| v3-32 | (종료일 미정) |
| v3-128 | (종료일 미정) |
| v3-256 | (종료일 미정) |
| v3-512 | (종료일 미정) |
| v3-1024 | (종료일 미정) |
| v3-2048 | (종료일 미정) |
다음 명령어는 TensorCore 128개가 포함된 v3 TPU 슬라이스를 만드는 방법을 보여줍니다.
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=europe-west4-a \ --accelerator-type=v3-128 \ --version=tpu-ubuntu2204-base
TPU 관리에 대한 자세한 내용은 TPU 관리를 참조하세요. Cloud TPU의 시스템 아키텍처에 대한 자세한 내용은 시스템 아키텍처를 참조하세요.