Ce tutoriel vous guide à travers :
- Créer une VM Cloud TPU pour déployer le Llama 2 des grands modèles de langage (LLM), Disponible en différentes tailles (7B, 13B ou 70B)
- Préparer des points de contrôle pour les modèles et les déployer sur SAX
- Interagir avec le modèle via un point de terminaison HTTP
La diffusion pour les tests AGI (SAX) est un système expérimental Paxml, JAX et les modèles PyTorch pour l'inférence. Code et documentation pour SAX se trouvent dans le dépôt Git Saxml. La version stable actuelle compatible avec TPU v5e est la v1.1.0.
À propos des cellules SAX
Une cellule (ou cluster) SAX est l'unité principale pour la diffusion de vos modèles. Il se compose des éléments suivants : deux parties principales:
- Serveur d'administration: ce serveur assure le suivi de vos serveurs de modèles, attribue vers ces serveurs de modèles et aide les clients à trouver le bon avec lesquelles interagir.
- Serveurs de modèles: ces serveurs exécutent votre modèle. Il est responsable de le traitement des requêtes entrantes et la génération de réponses.
Le schéma suivant montre le diagramme d'une cellule SAX:
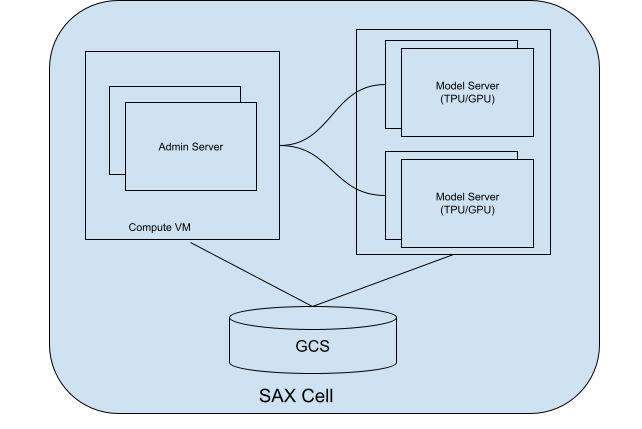
Figure 1 : Cellule SAX avec serveur d'administration et serveur de modèles.
Vous pouvez interagir avec une cellule SAX à l'aide de clients écrits en Python, C++ ou Go, ou directement via un serveur HTTP. Le schéma suivant montre comment peut interagir avec une cellule SAX:

Figure 2. Architecture d'exécution d'un client externe interagissant avec une SAX cellule.
Objectifs
- Configurer des ressources TPU pour la diffusion
- Créer un cluster SAX
- Publier le modèle Llama 2
- Interagir avec le modèle
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
- Cloud TPU
- Compute Engine
- Cloud Storage
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
Configurez votre projet Google Cloud, activez l'API Cloud TPU et créez un compte de service en suivant les instructions de la section Configurer le Cloud TPU environnement.
Créer un TPU
Les étapes suivantes expliquent comment créer une VM TPU qui diffusera votre modèle.
Créez des variables d'environnement :
export PROJECT_ID=PROJECT_ID export ACCELERATOR_TYPE=ACCELERATOR_TYPE export ZONE=ZONE export RUNTIME_VERSION=v2-alpha-tpuv5-lite export SERVICE_ACCOUNT=SERVICE_ACCOUNT export TPU_NAME=TPU_NAME export QUEUED_RESOURCE_ID=QUEUED_RESOURCE_ID
Description des variables d'environnement
PROJECT_ID- L'ID de votre projet Google Cloud.
ACCELERATOR_TYPE- Le type d'accélérateur spécifie la version et la taille
Cloud TPU que vous souhaitez créer. Différentes tailles de modèles Llama 2 ont
différentes exigences de taille de TPU:
<ph type="x-smartling-placeholder">
- </ph>
- 7B:
v5litepod-4ou supérieur - 13B:
v5litepod-8ou supérieur - 70B:
v5litepod-16ou plus
- 7B:
ZONE- Zone dans laquelle vous souhaitez créer votre Cloud TPU.
SERVICE_ACCOUNT- Compte de service que vous souhaitez associer à votre Cloud TPU.
TPU_NAME- Nom de votre Cloud TPU.
QUEUED_RESOURCE_ID- Identifiant de votre requête de ressource en file d'attente.
Définissez l'ID et la zone du projet dans votre configuration active de la Google Cloud CLI:
gcloud config set project $PROJECT_ID && gcloud config set compute/zone $ZONECréez la VM TPU:
gcloud compute tpus queued-resources create ${QUEUED_RESOURCE_ID} \ --node-id ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --accelerator-type ${ACCELERATOR_TYPE} \ --runtime-version ${RUNTIME_VERSION} \ --service-account ${SERVICE_ACCOUNT}Vérifiez que le TPU est actif:
gcloud compute tpus queued-resources list --project $PROJECT_ID --zone $ZONE
Configurer le nœud de conversion de point de contrôle
Pour exécuter les modèles LLama sur un cluster SAX, vous devez convertir le modèle Llama d'origine des points de contrôle dans un format compatible SAX.
La conversion nécessite d'importantes ressources de mémoire, selon le modèle taille:
| Modèle | Type de machine |
|---|---|
| 7 Mrds | 50-60 Go de mémoire |
| 13 Mrds | 120 Go de mémoire |
| 70 Mrds | 500 à 600 Go de mémoire (type de machine N2 ou M1) |
Pour les modèles 7B et 13B, vous pouvez exécuter la conversion sur la VM TPU. Pour le de 70 milliards, vous devez créer une instance Compute Engine environ 1 To d'espace disque:
gcloud compute instances create INSTANCE_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=n2-highmem-128 \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=bk-workday-dlvm,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
Que vous utilisiez une instance TPU ou Compute Engine comme serveur de conversion, configurez votre serveur pour convertir les points de contrôle Llama 2:
Pour les modèles 7B et 13B, définissez la variable d'environnement du nom du serveur sur le nom du TPU:
export CONV_SERVER_NAME=$TPU_NAMEPour le modèle 70B, définissez la variable d'environnement de nom de serveur sur le nom votre instance Compute Engine:
export CONV_SERVER_NAME=INSTANCE_NAME
Connectez-vous au nœud de conversion à l'aide de SSH.
Si votre nœud de conversion est un TPU, connectez-vous au TPU:
gcloud compute tpus tpu-vm ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONESi votre nœud de conversion est une instance Compute Engine, connectez-vous à VM Compute Engine:
gcloud compute ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEInstallez les packages requis sur le nœud de conversion:
sudo apt update sudo apt-get install python3-pip sudo apt-get install git-all pip3 install paxml==1.1.0 pip3 install torch pip3 install jaxlib==0.4.14Téléchargez le script de conversion du point de contrôle Llama:
gcloud storage cp gs://cloud-tpu-inference-public/sax-tokenizers/llama/convert_llama_ckpt.py .
Télécharger les poids Llama 2
Avant de convertir le modèle, vous devez télécharger les pondérations Llama 2. Pour cette vous devez utiliser les pondérations Llama 2 d'origine (par exemple, meta-llama/Llama-2-7b), et non les pondérations qui ont été converties pour le format Hugging Face Transformers ; (par exemple, meta-llama/Llama-2-7b-hf).
Si vous disposez déjà des pondérations Llama 2, passez directement à la section Convertir les pondérations.
Pour télécharger les poids depuis le hub Hugging Face, vous devez définir un jeton d'accès utilisateur, pour demander l'accès aux modèles Llama 2. Pour demander l'accès, suivez les instructions sur la page Hugging Face du modèle que vous souhaitez utiliser, par exemple meta-llama/Llama-2-7b.
Créez un répertoire pour les pondérations:
sudo mkdir WEIGHTS_DIRECTORY
Obtenez les poids Llama2 depuis le hub Hugging Face:
Installez la CLI du hub Hugging Face:
pip install -U "huggingface_hub[cli]"Accédez au répertoire des pondérations:
cd WEIGHTS_DIRECTORY
Téléchargez les fichiers Llama 2:
python3 from huggingface_hub import login login() from huggingface_hub import hf_hub_download, snapshot_download import os PATH=os.getcwd() snapshot_download(repo_id="meta-llama/LLAMA2_REPO", local_dir_use_symlinks=False, local_dir=PATH)
Remplacez LLAMA2_REPO par le nom du dépôt Hugging Face. depuis lequel vous souhaitez télécharger le fichier:
Llama-2-7b,Llama-2-13bouLlama-2-70b.
Convertir les pondérations
Modifier le script de conversion, puis exécuter ce script pour convertir le modèle les pondérations.
Créez un répertoire pour stocker les pondérations converties:
sudo mkdir CONVERTED_WEIGHTS
Clonez le dépôt GitHub Saxml dans un répertoire où vous avez accès en lecture, en écriture et d'exécution:
git clone https://github.com/google/saxml.git -b r1.1.0Accédez au répertoire
saxml:cd saxmlOuvrez le fichier
saxml/tools/convert_llama_ckpt.py.Dans le fichier
saxml/tools/convert_llama_ckpt.py, remplacez la ligne 169:'scale': pytorch_vars[0]['layers.%d.attention_norm.weight' % (layer_idx)].type(torch.float16).numpy()À :
'scale': pytorch_vars[0]['norm.weight'].type(torch.float16).numpy()Exécutez le script
saxml/tools/init_cloud_vm.sh:saxml/tools/init_cloud_vm.shPour 70B uniquement: pour désactiver le mode de test, procédez comme suit:
- Ouvrez le
saxml/server/pax/lm/params/lm_cloud.py. Dans
saxml/server/pax/lm/params/lm_cloud.py, remplacez la ligne 344 par:return TrueÀ :
return False
- Ouvrez le
Convertissez les pondérations:
python3 saxml/tools/convert_llama_ckpt.py --base-model-path WEIGHTS_DIRECTORY \ --pax-model-path CONVERTED_WEIGHTS \ --model-size MODEL_SIZE
Remplacez les éléments suivants :
- WEIGHTS_DIRECTORY: répertoire des pondérations d'origine.
- CONVERTED_WEIGHTS: chemin cible pour les pondérations converties.
- MODEL_SIZE :
7b,13bou70b.
Préparer le répertoire du point de contrôle
Une fois les points de contrôle convertis, leur répertoire doit comporter la structure suivante:
checkpoint_00000000
metadata/
metadata
state/
mdl_vars.params.lm*/
...
...
step/
Créez un fichier vide nommé commit_success.txt et placez-en une copie dans le
checkpoint_00000000, metadata et state. Cela permet à SAX de savoir
que ce point de contrôle est entièrement converti et prêt à être chargé:
Accédez au répertoire du point de contrôle:
cd CONVERTED_WEIGHTS/checkpoint_00000000
Créez un fichier vide nommé
commit_success.txt:touch commit_success.txtAccédez au répertoire des métadonnées et créez un fichier vide nommé
commit_success.txt:cd metadata && touch commit_success.txtAccédez au répertoire d'état et créez un fichier vide nommé
commit_success.txt:cd .. && cd state && touch commit_success.txt
Le répertoire du point de contrôle doit maintenant présenter la structure suivante:
checkpoint_00000000
commit_success.txt
metadata/
commit_success.txt
metadata
state/
commit_success.txt
mdl_vars.params.lm*/
...
...
step/
Créer un bucket Cloud Storage
Vous devez stocker le fichier des points de contrôle dans un bucket Cloud Storage disponibles lors de la publication du modèle.
Définissez une variable d'environnement pour le nom de votre bucket Cloud Storage:
export GSBUCKET=BUCKET_NAME
Créez un bucket:
gcloud storage buckets create gs://${GSBUCKET}Copiez vos fichiers de point de contrôle convertis dans votre bucket:
gcloud storage cp -r CONVERTED_WEIGHTS/checkpoint_00000000 gs://$GSBUCKET/sax_models/llama2/SAX_LLAMA2_DIR/
Remplacez SAX_LLAMA2_DIR par la valeur appropriée:
- 7B:
saxml_llama27b - 13B:
saxml_llama213b - 70B:
saxml_llama270b
- 7B:
Créer un cluster SAX
Pour créer un cluster SAX, vous devez:
- Créer un serveur d'administration
- Créer un serveur de modèles
- Déployer le modèle sur le serveur de modèles
Dans un déploiement type, vous exécutez le serveur d'administration sur une Compute Engine et le serveur de modèles sur un TPU ou un GPU. Dans le cadre de ce vous allez déployer le serveur d'administration et le serveur de modèles sur le même TPU Compute Engine v5e.
Créer un serveur d'administration
Créez le conteneur Docker du serveur d'administration:
Sur le serveur de conversion, installez Docker:
sudo apt-get update sudo apt-get install docker.ioLancez le conteneur Docker du serveur d'administration:
sudo docker run --name sax-admin-server \ -it \ -d \ --rm \ --network host \ --env GSBUCKET=${GSBUCKET} us-docker.pkg.dev/cloud-tpu-images/inference/sax-admin-server:v1.1.0
Vous pouvez exécuter la commande docker run sans l'option -d pour afficher les journaux et
pour s'assurer que le serveur d'administration démarre correctement.
Créer un serveur de modèles
Les sections suivantes expliquent comment créer un serveur de modèles.
Modèle 7b
Lancez le conteneur Docker du serveur de modèles:
sudo docker run --privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='4'
Modèle 13b
Il manque la configuration de LLaMA13BFP16TPUv5e dans lm_cloud.py. La
Les étapes suivantes montrent comment mettre à jour lm_cloud.py et valider une nouvelle image Docker.
Démarrez le serveur de modèles:
sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'Connectez-vous au conteneur Docker à l'aide de SSH:
sudo docker exec -it sax-model-server bashInstallez Vim dans l'image Docker:
$ apt update $ apt install vimOuvrez le fichier
saxml/server/pax/lm/params/lm_cloud.py. RechercherLLaMA13BLe code suivant doit s'afficher:@servable_model_registry.register @quantization.for_transformer(quantize_on_the_fly=False) class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return TrueAjoutez un commentaire ou supprimez la ligne commençant par
@quantization. Après cela la modification, le fichier doit se présenter comme suit:@servable_model_registry.register class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return TrueAjoutez le code suivant pour prendre en charge la configuration du TPU.
@servable_model_registry.register class LLaMA13BFP16TPUv5e(LLaMA13B): """13B model on TPU v5e-8. """ BATCH_SIZE = [1] BUCKET_KEYS = [128] MAX_DECODE_STEPS = [32] ENABLE_GENERATE_STREAM = False ICI_MESH_SHAPE = [1, 1, 8] @property def test_mode(self) -> bool: return FalseQuittez la session SSH du conteneur Docker:
exitValidez les modifications dans une nouvelle image Docker:
sudo docker commit sax-model-server sax-model-server:v1.1.0-modVérifiez que l'image Docker a bien été créée:
sudo docker imagesVous pouvez publier l'image Docker dans Artifact Registry de votre projet, mais le tutoriel continue avec l'image locale.
Arrêtez le serveur de modèles. Le reste du tutoriel utilisera le modèle mis à jour Google Cloud.
sudo docker stop sax-model-serverDémarrez le serveur de modèles à l'aide de l'image Docker mise à jour. Veillez à préciser le nouveau nom de l'image,
sax-model-server:v1.1.0-mod:sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ sax-model-server:v1.1.0-mod \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'
Modèle 70B
Connectez-vous à votre TPU via SSH et démarrez le serveur de modèles:
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE} \
--worker=all \
--command="
gcloud auth configure-docker \
us-docker.pkg.dev
# Pull SAX model server image
sudo docker pull us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0
# Run model server
sudo docker run \
--privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root \
us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='16'
"
Vérifier les journaux
Vérifiez les journaux du serveur de modèles pour vous assurer que celui-ci a démarré correctement:
docker logs -f sax-model-server
Si le serveur de modèles n'a pas démarré, reportez-vous à la section Dépannage. pour en savoir plus.
Pour le modèle 70B, répétez ces étapes pour chaque VM TPU:
Connectez-vous au TPU à l'aide de SSH:
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --worker=WORKER_NUMBERWORKER_NUMBER est un index basé sur 0 qui indique la VM TPU que vous souhaitez auquel vous souhaitez vous connecter.
Vérifiez les journaux :
sudo docker logs -f sax-model-serverTrois VM TPU doivent indiquer qu'elles se sont connectées aux autres instances:
I1117 00:16:07.196594 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.3:10001 I1117 00:16:07.197484 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.87:10001 I1117 00:16:07.199437 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.13:10001L'une des VM TPU doit comporter des journaux indiquant le démarrage du serveur de modèle:
I1115 04:01:29.479170 139974275995200 model_service_base.py:867] Started joining SAX cell /sax/test ERROR: logging before flag.Parse: I1115 04:01:31.479794 1 location.go:141] Calling Join due to address update ERROR: logging before flag.Parse: I1115 04:01:31.814721 1 location.go:155] Joined 10.182.0.44:10000
Publier le modèle
SAX est fourni avec un outil de ligne de commande appelé saxutil, qui simplifie
interagissant avec les serveurs
de modèles SAX. Dans ce tutoriel, vous allez utiliser
saxutil pour publier le modèle. Pour obtenir la liste complète des commandes saxutil, consultez
Le fichier README Saxml
fichier.
Accédez au répertoire dans lequel vous avez cloné le dépôt GitHub Saxml:
cd saxmlPour le modèle 70 milliards, connectez-vous à votre serveur de conversion:
gcloud compute ssh ${CONV_SERVER_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE}Installez Bazel:
sudo apt-get install bazelDéfinissez un alias pour exécuter
saxutilavec votre bucket Cloud Storage:alias saxutil='bazel run saxml/bin:saxutil -- --sax_root=gs://${GSBUCKET}/sax-root'Publiez le modèle à l'aide de
saxutil. Cela prend environ 10 minutes sur un TPU v5litepod-8.saxutil --sax_root=gs://${GSBUCKET}/sax-root publish '/sax/test/MODEL' \ saxml.server.pax.lm.params.lm_cloud.PARAMETERS \ gs://${GSBUCKET}/sax_models/llama2/SAX_LLAMA2_DIR/checkpoint_00000000/ \ 1Remplacez les variables suivantes :
Taille du modèle Valeurs 7 Mrds MODEL: lama27b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama27b
13 Mrds MODEL: llama213b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA13BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama213b
70 Mrds MODEL: llama270b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA70BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama270b
Tester le déploiement
Pour vérifier si le déploiement a réussi, exécutez la commande saxutil ls:
saxutil ls /sax/test/MODEL
Pour réussir votre déploiement, vous devez avoir un nombre d'instances répliquées supérieur à zéro se présente comme suit:
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| MODEL | MODEL PATH | CHECKPOINT PATH | # OF REPLICAS | (SELECTED) REPLICAADDRESS |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| llama27b | saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e | gs://${MODEL_BUCKET}/sax_models/llama2/7b/pax_7B/checkpoint_00000000/ | 1 | 10.182.0.28:10001 |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
Les journaux Docker pour le serveur de modèles se présentent comme suit:
I1114 17:31:03.586631 140003787142720 model_service_base.py:532] Successfully loaded model for key: /sax/test/llama27b
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
Résoudre les problèmes
Si le déploiement échoue, consultez les journaux du serveur de modèles:
sudo docker logs -f sax-model-server
Pour un déploiement réussi, vous devez obtenir le résultat suivant:
Successfully loaded model for key: /sax/test/llama27b
Si les journaux n'indiquent pas que le modèle a été déployé, vérifiez le modèle configuration et le chemin d'accès au point de contrôle du modèle.
Générer des réponses
Vous pouvez utiliser l'outil saxutil pour générer des réponses aux requêtes.
Générer des réponses à une question:
saxutil lm.generate -extra="temperature:0.2" /sax/test/MODEL "Q: Who is Harry Potter's mother? A:"
La sortie devrait ressembler à ce qui suit :
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root' lm.generate /sax/test/llama27b 'Q: Who is Harry Potter's mother? A: `
+-------------------------------+------------+
| GENERATE | SCORE |
+-------------------------------+------------+
| 1. Harry Potter's mother is | -20.214787 |
| Lily Evans. 2. Harry Potter's | |
| mother is Petunia Evans | |
| (Dursley). | |
+-------------------------------+------------+
Interagir avec le modèle depuis un client
Le référentiel SAX comprend des clients que vous pouvez utiliser pour interagir avec une cellule SAX. Les clients sont disponibles en C++, Python et Go. L'exemple suivant montre comment créer un client Python.
Créez le client Python:
bazel build saxml/client/python:sax.cc --compile_one_dependencyAjoutez le client à
PYTHONPATH. Cet exemple suppose que vous avezsaxmlsous votre répertoire d'accueil:export PYTHONPATH=${PYTHONPATH}:$HOME/saxml/bazel-bin/saxml/client/python/Interagissez avec SAX à partir du shell Python:
$ python3 Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import sax >>>
Interagir avec le modèle depuis un point de terminaison HTTP
Pour interagir avec le modèle à partir d'un point de terminaison HTTP, créez un client HTTP:
Créer une VM Compute Engine :
export PROJECT_ID=PROJECT_ID export ZONE=ZONE export HTTP_SERVER_NAME=HTTP_SERVER_NAME export SERVICE_ACCOUNT=SERVICE_ACCOUNT export MACHINE_TYPE=e2-standard-8 gcloud compute instances create $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=$MACHINE_TYPE \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=$HTTP_SERVER_NAME,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
Connectez-vous en SSH à la VM Compute Engine:
gcloud compute ssh $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEClonez le dépôt GitHub AI on GKE:
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.gitAccédez au répertoire du serveur HTTP:
cd ai-on-gke/tools/saxml-on-gke/httpserverCréez le fichier Docker:
docker build -f Dockerfile -t sax-http .Exécutez le serveur HTTP:
docker run -e SAX_ROOT=gs://${GSBUCKET}/sax-root -p 8888:8888 -it sax-http
Testez votre point de terminaison depuis votre ordinateur local ou un autre serveur ayant accès au port 8888 à l'aide des commandes suivantes:
Exportez les variables d'environnement correspondant à l'adresse IP et au port de votre serveur:
export LB_IP=HTTP_SERVER_EXTERNAL_IP export PORT=8888
Définissez la charge utile JSON contenant le modèle et la requête:
json_payload=$(cat << EOF { "model": "/sax/test/MODEL", "query": "Example query" } EOF )Envoyez la requête :
curl --request POST --header "Content-type: application/json" -s $LB_IP:$PORT/generate --data "$json_payload"
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Une fois ce tutoriel terminé, procédez comme suit pour nettoyer votre ressources.
Supprimez votre Cloud TPU.
$ gcloud compute tpus tpu-vm delete $TPU_NAME --zone $ZONESupprimez votre instance Compute Engine, le cas échéant.
gcloud compute instances delete INSTANCE_NAME
Supprimez votre bucket Cloud Storage et son contenu.
gcloud storage rm --recursive gs://BUCKET_NAME
Étape suivante
- Tous les tutoriels TPU
- Modèles de référence compatibles
- Inférence avec v5e
- Convertir un modèle pour l'inférence à l'aide de v5e