Contenuti di questo tutorial:
- Creazione di una VM Cloud TPU per il deployment di Llama 2 famiglia di modelli linguistici di grandi dimensioni (LLM), Disponibile in diverse dimensioni (7B, 13B o 70B)
- Preparazione dei checkpoint per i modelli ed esecuzione del deployment su SAX
- Interazione con il modello tramite un endpoint HTTP
Serving for AGI Experiments (SAX) è un sistema sperimentale che pubblica modelli Paxml, JAX e PyTorch per l'inferenza. Il codice e la documentazione per SAX si trovano nel repository Git Saxml. L'attuale versione stabile con supporto di TPU v5e è la v1.1.0.
Informazioni sulle celle SAX
Una cella (o un cluster) SAX è l'unità di base per la pubblicazione dei modelli. È costituito da due parti principali:
- Server di amministrazione: questo server tiene traccia dei server dei modelli, assegna i modelli a questi server e aiuta i clienti a trovare il server dei modelli corretto con cui interagire.
- Server dei modelli: questi server eseguono il tuo modello. Sono responsabili l'elaborazione delle richieste in arrivo e la generazione delle risposte.
Il seguente diagramma mostra una cella SAX:
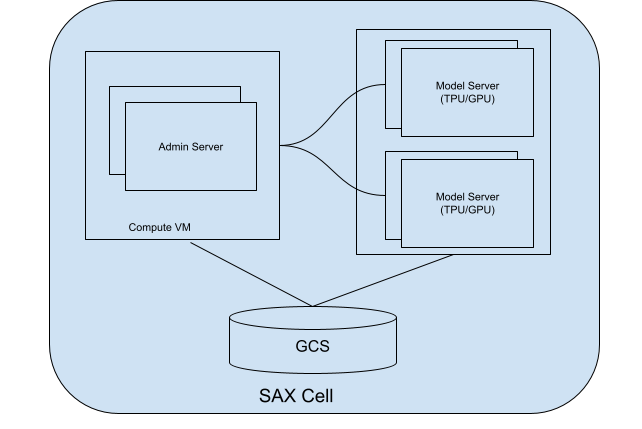
Figura 1. Cella SAX con server di amministrazione e server del modello.
Puoi interagire con una cella SAX utilizzando client scritti in Python, C++ o Go. direttamente tramite un server HTTP. Il seguente diagramma mostra come una rete Il client può interagire con una cella SAX:

Figura 2. Architettura di runtime di un client esterno che interagisce con una cellula SAX.
Obiettivi
- Configura le risorse TPU per la distribuzione
- Crea un cluster SAX
- Pubblica il modello Llama 2
- Interagisci con il modello
Costi
In questo documento utilizzi i seguenti componenti fatturabili di Google Cloud:
- Cloud TPU
- Compute Engine
- Cloud Storage
Per generare una stima dei costi basata sull'utilizzo previsto,
utilizza il Calcolatore prezzi.
Prima di iniziare
Configura il tuo progetto Google Cloud, attiva l'API Cloud TPU e crea un account di servizio seguendo le istruzioni riportate in Configurare l'ambiente Cloud TPU.
Crea una TPU
I passaggi seguenti mostrano come creare una VM TPU che pubblicherà il tuo modello.
Crea le variabili di ambiente:
export PROJECT_ID=PROJECT_ID export ACCELERATOR_TYPE=ACCELERATOR_TYPE export ZONE=ZONE export RUNTIME_VERSION=v2-alpha-tpuv5-lite export SERVICE_ACCOUNT=SERVICE_ACCOUNT export TPU_NAME=TPU_NAME export QUEUED_RESOURCE_ID=QUEUED_RESOURCE_ID
Descrizioni delle variabili di ambiente
PROJECT_ID- L'ID del tuo progetto Google Cloud.
ACCELERATOR_TYPE- Il tipo di acceleratore specifica la versione e le dimensioni della
Cloud TPU che vuoi creare. Le diverse dimensioni del modello Llama 2 hanno
requisiti di dimensione di TPU diversi:
- 7B:
v5litepod-4o più - 13B:
v5litepod-8o versioni successive - 70 miliardi:
v5litepod-16o versioni successive
- 7B:
ZONE- La zona in cui vuoi creare la Cloud TPU.
SERVICE_ACCOUNT- L'account di servizio che vuoi collegare a Cloud TPU.
TPU_NAME- Il nome della tua Cloud TPU.
QUEUED_RESOURCE_ID- Un identificatore per la richiesta di risorsa in coda.
Imposta l'ID progetto e la zona nella configurazione dell'interfaccia a riga di comando Google Cloud attiva:
gcloud config set project $PROJECT_ID && gcloud config set compute/zone $ZONECrea la VM TPU:
gcloud compute tpus queued-resources create ${QUEUED_RESOURCE_ID} \ --node-id ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --accelerator-type ${ACCELERATOR_TYPE} \ --runtime-version ${RUNTIME_VERSION} \ --service-account ${SERVICE_ACCOUNT}Verifica che la TPU sia attiva:
gcloud compute tpus queued-resources list --project $PROJECT_ID --zone $ZONE
Configura il nodo di conversione del checkpoint
Per eseguire i modelli LLama su un cluster SAX, devi convertire il file Llama originale i punti di controllo a un formato compatibile con SAX.
La conversione richiede risorse di memoria significative, a seconda del modello dimensioni:
| Modello | Tipo di macchina |
|---|---|
| 7 MLD | 50-60 GB di memoria |
| 13B | 120 GB di memoria |
| 70 mld | 500-600 GB di memoria (tipo di macchina N2 o M1) |
Per il modello 7B e 13B, puoi eseguire la conversione sulla VM TPU. Per del modello da 70 miliardi, devi creare un'istanza Compute Engine e circa 1 TB di spazio su disco:
gcloud compute instances create INSTANCE_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=n2-highmem-128 \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=bk-workday-dlvm,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
Che tu utilizzi una TPU o un'istanza Compute Engine come server di conversione, Configura il server per convertire i checkpoint Llama 2:
Per il modello 7B e 13B, imposta la variabile di ambiente del nome del server con il nome della tua TPU:
export CONV_SERVER_NAME=$TPU_NAMEPer il modello 70B, imposta la variabile di ambiente del nome del server sul nome la tua istanza Compute Engine:
export CONV_SERVER_NAME=INSTANCE_NAME
Connettiti al nodo di conversione tramite SSH.
Se il tuo nodo di conversione è una TPU, connettiti alla TPU:
gcloud compute tpus tpu-vm ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONESe il nodo di conversione è un'istanza Compute Engine, connettiti alla VM Compute Engine:
gcloud compute ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEInstalla i pacchetti richiesti sul nodo di conversione:
sudo apt update sudo apt-get install python3-pip sudo apt-get install git-all pip3 install paxml==1.1.0 pip3 install torch pip3 install jaxlib==0.4.14Scarica lo script di conversione del checkpoint Lama:
gcloud storage cp gs://cloud-tpu-inference-public/sax-tokenizers/llama/convert_llama_ckpt.py .
Scarica i pesi di Llama 2
Prima di convertire il modello, devi scaricare i pesi Llama 2. Per questo tutorial, devi utilizzare i pesi originali di Llama 2 (ad esempio, meta-llama/Llama-2-7b) e non i pesi che sono stati convertiti per il formato Hugging Face Transformers (ad esempio, meta-llama/Llama-2-7b-hf).
Se disponi già dei pesi Llama 2, passa direttamente al campo Convertire i pesi.
Per scaricare i pesi dall'hub Hugging Face, devi configurare un token di accesso utente e richiedere l'accesso ai modelli Llama 2. Per richiedere l'accesso, segui le istruzioni riportate sulla pagina di Hugging Face del modello che vuoi utilizzare, ad esempio meta-llama/Llama-2-7b.
Crea una directory per i pesi:
sudo mkdir WEIGHTS_DIRECTORY
Ottieni i pesi di Llama2 dall'hub Hugging Face:
Installa l'interfaccia a riga di comando dell'hub Hugging Face:
pip install -U "huggingface_hub[cli]"Passa alla directory dei pesi:
cd WEIGHTS_DIRECTORY
Scarica i file Llama 2:
python3 from huggingface_hub import login login() from huggingface_hub import hf_hub_download, snapshot_download import os PATH=os.getcwd() snapshot_download(repo_id="meta-llama/LLAMA2_REPO", local_dir_use_symlinks=False, local_dir=PATH)
Sostituisci LLAMA2_REPO con il nome del repository Hugging Face da cui vuoi scaricare:
Llama-2-7b,Llama-2-13boLlama-2-70b.
Converti le ponderazioni
Modifica lo script di conversione ed esegui lo script di conversione per convertire il modello i pesi.
Crea una directory per contenere i pesi convertiti:
sudo mkdir CONVERTED_WEIGHTS
Clona il repository GitHub di Saxml in una directory in cui disponi delle autorizzazioni di lettura, scrittura e esecuzione:
git clone https://github.com/google/saxml.git -b r1.1.0Passa alla directory
saxml:cd saxmlApri il file
saxml/tools/convert_llama_ckpt.py.Nel file
saxml/tools/convert_llama_ckpt.py, modifica la riga 169 da:'scale': pytorch_vars[0]['layers.%d.attention_norm.weight' % (layer_idx)].type(torch.float16).numpy()A:
'scale': pytorch_vars[0]['norm.weight'].type(torch.float16).numpy()Esegui lo script
saxml/tools/init_cloud_vm.sh:saxml/tools/init_cloud_vm.shSolo per 70B. Disattiva la modalità di test. Ecco come:
- Apri l'app
saxml/server/pax/lm/params/lm_cloud.py. Nella
saxml/server/pax/lm/params/lm_cloud.pycambia la riga 344 da:return TrueA:
return False
- Apri l'app
Converti le ponderazioni:
python3 saxml/tools/convert_llama_ckpt.py --base-model-path WEIGHTS_DIRECTORY \ --pax-model-path CONVERTED_WEIGHTS \ --model-size MODEL_SIZE
Sostituisci quanto segue:
- WEIGHTS_DIRECTORY: directory per i pesi originali.
- CONVERTED_WEIGHTS: percorso target per i pesi convertiti.
- MODEL_SIZE:
7b,13bo70b.
prepara la directory del checkpoint
Dopo aver convertito i checkpoint, la directory dei checkpoint dovrebbe contenere la seguente struttura:
checkpoint_00000000
metadata/
metadata
state/
mdl_vars.params.lm*/
...
...
step/
Crea un file vuoto denominato commit_success.txt e inserisci una copia nelle directory checkpoint_00000000, metadata e state. In questo modo, SAX viene informato
che questo checkpoint è completamente convertito e pronto per il caricamento:
Passa alla directory del checkpoint:
cd CONVERTED_WEIGHTS/checkpoint_00000000
Crea un file vuoto denominato
commit_success.txt:touch commit_success.txtPassa alla directory dei metadati e crea un file vuoto denominato
commit_success.txt:cd metadata && touch commit_success.txtPassa alla directory dello stato e crea un file vuoto denominato
commit_success.txt:cd .. && cd state && touch commit_success.txt
La directory dei checkpoint ora dovrebbe avere la seguente struttura:
checkpoint_00000000
commit_success.txt
metadata/
commit_success.txt
metadata
state/
commit_success.txt
mdl_vars.params.lm*/
...
...
step/
Crea un bucket Cloud Storage
Devi archiviare il file convertito in un bucket Cloud Storage, in modo che disponibili durante la pubblicazione del modello.
Imposta una variabile di ambiente per il nome del tuo bucket Cloud Storage:
export GSBUCKET=BUCKET_NAME
Crea un bucket:
gcloud storage buckets create gs://${GSBUCKET}Copia i file checkpoint convertiti nel bucket:
gcloud storage cp -r CONVERTED_WEIGHTS/checkpoint_00000000 gs://$GSBUCKET/sax_models/llama2/SAX_LLAMA2_DIR/
Sostituisci SAX_LLAMA2_DIR con il valore appropriato:
- 7B:
saxml_llama27b - 13 MLD:
saxml_llama213b - 70 mld:
saxml_llama270b
- 7B:
Crea un cluster SAX
Per creare un cluster SAX, devi:
- Creare un server di amministrazione
- Crea un server del modello
- Esegui il deployment del modello sul server del modello
In un deployment tipico, esegui il server di amministrazione su un'istanza Compute Engine e il server del modello su una TPU o una GPU. Ai fini di questo eseguirai il deployment del server di amministrazione e del server del modello sulla stessa TPU v5e.
Crea il server di amministrazione
Crea il container Docker del server di amministrazione:
Sul server di conversione, installa Docker:
sudo apt-get update sudo apt-get install docker.ioAvvia il contenitore Docker del server di amministrazione:
sudo docker run --name sax-admin-server \ -it \ -d \ --rm \ --network host \ --env GSBUCKET=${GSBUCKET} us-docker.pkg.dev/cloud-tpu-images/inference/sax-admin-server:v1.1.0
Puoi eseguire il comando docker run senza l'opzione -d per visualizzare i log e assicurarti che il server di amministrazione venga avviato correttamente.
Crea il server del modello
Le sezioni seguenti mostrano come creare un server di modelli.
Modello 7b
Avvia il container Docker del server di modelli:
sudo docker run --privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='4'
Modello 13b
La configurazione per LLaMA13BFP16TPUv5e non è presente in lm_cloud.py. La
i seguenti passaggi mostrano come aggiornare lm_cloud.py ed eseguire il commit di una nuova immagine Docker.
Avvia il server del modello:
sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'Connettiti al contenitore Docker tramite SSH:
sudo docker exec -it sax-model-server bashInstalla Vim nell'immagine Docker:
$ apt update $ apt install vimApri il file
saxml/server/pax/lm/params/lm_cloud.py. CercaLLaMA13B. Dovresti vedere il seguente codice:@servable_model_registry.register @quantization.for_transformer(quantize_on_the_fly=False) class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return TrueCommenta o elimina la riga che inizia con
@quantization. Dopo questa data modifica, il file sarà simile al seguente:@servable_model_registry.register class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return TrueAggiungi il seguente codice per supportare la configurazione TPU.
@servable_model_registry.register class LLaMA13BFP16TPUv5e(LLaMA13B): """13B model on TPU v5e-8. """ BATCH_SIZE = [1] BUCKET_KEYS = [128] MAX_DECODE_STEPS = [32] ENABLE_GENERATE_STREAM = False ICI_MESH_SHAPE = [1, 1, 8] @property def test_mode(self) -> bool: return FalseEsci dalla sessione SSH del container Docker:
exitEsegui il commit delle modifiche in una nuova immagine Docker:
sudo docker commit sax-model-server sax-model-server:v1.1.0-modVerifica che sia stata creata la nuova immagine Docker:
sudo docker imagesPuoi pubblicare l'immagine Docker in Artifact Registry del tuo progetto, ma in questo tutorial procederemo con l'immagine locale.
Arresta il server del modello. Per il resto del tutorial verrà utilizzato il server del modello aggiornato.
sudo docker stop sax-model-serverAvvia il server del modello utilizzando l'immagine Docker aggiornata. Assicurati di specificare il nome dell'immagine aggiornata,
sax-model-server:v1.1.0-mod:sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ sax-model-server:v1.1.0-mod \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'
Modello 70 miliardi
Connettiti alla TPU tramite SSH e avvia il server del modello:
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE} \
--worker=all \
--command="
gcloud auth configure-docker \
us-docker.pkg.dev
# Pull SAX model server image
sudo docker pull us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0
# Run model server
sudo docker run \
--privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root \
us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='16'
"
Controlla i log
Controlla i log del server del modello per assicurarti che il server del modello sia stato avviato correttamente:
docker logs -f sax-model-server
Se il server del modello non si è avviato, consulta la sezione Risoluzione dei problemi per ulteriori informazioni.
Per il modello da 70 miliardi, ripeti questi passaggi per ogni VM TPU:
Connettiti alla TPU tramite SSH:
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --worker=WORKER_NUMBER
WORKER_NUMBER è un indice in base a 0 che indica la VM TPU che vuoi connettersi.
Controlla i log:
sudo docker logs -f sax-model-serverTre VM TPU dovrebbero mostrare che si sono connesse alle altre istanze:
I1117 00:16:07.196594 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.3:10001 I1117 00:16:07.197484 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.87:10001 I1117 00:16:07.199437 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.13:10001Una delle VM TPU deve avere log che mostrano il server del modello che inizia:
I1115 04:01:29.479170 139974275995200 model_service_base.py:867] Started joining SAX cell /sax/test ERROR: logging before flag.Parse: I1115 04:01:31.479794 1 location.go:141] Calling Join due to address update ERROR: logging before flag.Parse: I1115 04:01:31.814721 1 location.go:155] Joined 10.182.0.44:10000
Pubblica il modello
SAX è dotato di uno strumento a riga di comando chiamato saxutil, che semplifica
l'interazione con i server dei modelli SAX. In questo tutorial utilizzi
saxutil per pubblicare il modello. Per l'elenco completo dei comandi saxutil, vedi
il file README di Saxml
un file YAML.
Passa alla directory in cui hai clonato il repository GitHub di Saxml:
cd saxmlPer il modello 70B, connettiti al server di conversione:
gcloud compute ssh ${CONV_SERVER_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE}Installa Bazel:
sudo apt-get install bazelImposta un alias per l'esecuzione di
saxutilcon il tuo bucket Cloud Storage:alias saxutil='bazel run saxml/bin:saxutil -- --sax_root=gs://${GSBUCKET}/sax-root'Pubblica il modello utilizzando
saxutil. L'operazione richiede circa 10 minuti su un TPU v5litepod-8.saxutil --sax_root=gs://${GSBUCKET}/sax-root publish '/sax/test/MODEL' \ saxml.server.pax.lm.params.lm_cloud.PARAMETERS \ gs://${GSBUCKET}/sax_models/llama2/SAX_LLAMA2_DIR/checkpoint_00000000/ \ 1
Sostituisci le seguenti variabili:
Dimensione modello Valori 7 miliardi MODEL: llama27b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama27b
13 MLD MODEL: lama213b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA13BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama213b
70 MLD MODEL: lama270b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA70BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama270b
Test del deployment
Per verificare se il deployment è riuscito, utilizza il comando saxutil ls:
saxutil ls /sax/test/MODEL
Un deployment riuscito deve avere un numero di repliche maggiore di zero e simile al seguente:
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| MODEL | MODEL PATH | CHECKPOINT PATH | # OF REPLICAS | (SELECTED) REPLICAADDRESS |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| llama27b | saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e | gs://${MODEL_BUCKET}/sax_models/llama2/7b/pax_7B/checkpoint_00000000/ | 1 | 10.182.0.28:10001 |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
I log Docker per il server del modello saranno simili al seguente:
I1114 17:31:03.586631 140003787142720 model_service_base.py:532] Successfully loaded model for key: /sax/test/llama27b
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
Risoluzione dei problemi
Se il deployment non riesce, controlla i log del server del modello:
sudo docker logs -f sax-model-server
Per un deployment corretto, dovresti vedere l'output seguente:
Successfully loaded model for key: /sax/test/llama27b
Se i log non indicano che è stato eseguito il deployment del modello, controlla il modello configurazione e il percorso del checkpoint del modello.
Generare risposte
Puoi utilizzare lo strumento saxutil per generare risposte ai prompt.
Generare risposte a una domanda:
saxutil lm.generate -extra="temperature:0.2" /sax/test/MODEL "Q: Who is Harry Potter's mother? A:"
L'output dovrebbe essere simile al seguente:
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root' lm.generate /sax/test/llama27b 'Q: Who is Harry Potter's mother? A: `
+-------------------------------+------------+
| GENERATE | SCORE |
+-------------------------------+------------+
| 1. Harry Potter's mother is | -20.214787 |
| Lily Evans. 2. Harry Potter's | |
| mother is Petunia Evans | |
| (Dursley). | |
+-------------------------------+------------+
Interagire con il modello da un client
Il repository SAX include client che puoi utilizzare per interagire con una cella SAX. I client sono disponibili in C++, Python e Go. L'esempio seguente mostra come creare un client Python.
Crea il client Python:
bazel build saxml/client/python:sax.cc --compile_one_dependencyAggiungi il client a
PYTHONPATH. Questo esempio presuppone che tu abbiasaxmlnella directory home:export PYTHONPATH=${PYTHONPATH}:$HOME/saxml/bazel-bin/saxml/client/python/Interagisci con SAX dalla shell Python:
$ python3 Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import sax >>>
Interagire con il modello da un endpoint HTTP
Per interagire con il modello da un endpoint HTTP, crea un client HTTP:
Crea una VM Compute Engine:
export PROJECT_ID=PROJECT_ID export ZONE=ZONE export HTTP_SERVER_NAME=HTTP_SERVER_NAME export SERVICE_ACCOUNT=SERVICE_ACCOUNT export MACHINE_TYPE=e2-standard-8 gcloud compute instances create $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=$MACHINE_TYPE \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=$HTTP_SERVER_NAME,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
Connettiti alla VM Compute Engine tramite SSH:
gcloud compute ssh $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEClona l'AI nel repository GitHub di GKE:
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.gitPassa alla directory del server HTTP:
cd ai-on-gke/tools/saxml-on-gke/httpserverCrea il file Docker:
docker build -f Dockerfile -t sax-http .Esegui il server HTTP:
docker run -e SAX_ROOT=gs://${GSBUCKET}/sax-root -p 8888:8888 -it sax-http
Testa l'endpoint dalla tua macchina locale o da un altro server con accesso alla porta 8888 utilizzando i seguenti comandi:
Esporta le variabili di ambiente per l'indirizzo IP e la porta del server:
export LB_IP=HTTP_SERVER_EXTERNAL_IP export PORT=8888
Imposta il payload JSON, contenente il modello e la query:
json_payload=$(cat << EOF { "model": "/sax/test/MODEL", "query": "Example query" } EOF )
Invia la richiesta:
curl --request POST --header "Content-type: application/json" -s $LB_IP:$PORT/generate --data "$json_payload"
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Al termine di questo tutorial, segui questi passaggi per ripulire Google Cloud.
Elimina la Cloud TPU.
$ gcloud compute tpus tpu-vm delete $TPU_NAME --zone $ZONE
Elimina l'istanza Compute Engine, se ne hai creata una.
gcloud compute instances delete INSTANCE_NAME
Eliminare il bucket Cloud Storage e i relativi contenuti.
gcloud storage rm --recursive gs://BUCKET_NAME
Passaggi successivi
- Tutti i tutorial sulle TPU
- Modelli di riferimento supportati
- Inferenza mediante v5e
- Convertire un modello per l'inferenza utilizzando v5e