Surveiller les VM Cloud TPU
Ce guide explique comment utiliser Google Cloud Monitoring pour surveiller vos VM Cloud TPU. Google Cloud Monitoring collecte automatiquement les métriques et les journaux de votre Cloud TPU et de son hôte Compute Engine. Ces données peuvent être utilisées pour surveiller l'état de votre Cloud TPU et de Compute Engine.
Les métriques vous permettent de suivre une quantité numérique au fil du temps, par exemple l'utilisation du processeur, l'utilisation du réseau ou la durée d'inactivité de TensorCore. Les journaux enregistrent les événements à un moment précis. Les entrées de journal sont écrites par votre propre code, par les services Google Cloud, par les applications tierces et par l'infrastructure Google Cloud. Vous pouvez également générer des métriques à partir des données présentes dans une entrée de journal en créant une métrique basée sur les journaux. Vous pouvez également définir des règles d'alerte en fonction des valeurs de métrique ou des entrées de journal.
Ce guide présente Google Cloud Monitoring et vous explique comment:
- Afficher les métriques Cloud TPU
- Configurer des règles d'alerte pour les métriques Cloud TPU
- Interroger les journaux Cloud TPU
- Créer des métriques basées sur les journaux pour configurer des alertes et visualiser des tableaux de bord
Prérequis
Ce document suppose que vous disposez de connaissances de base sur Google Cloud Monitoring. Vous devez disposer d'une VM Compute Engine et de ressources Cloud TPU pour pouvoir commencer à générer et à utiliser Google Cloud Monitoring. Pour en savoir plus, consultez le guide de démarrage rapide de Cloud TPU.
Métriques
Les métriques Google Cloud sont générées automatiquement par les VM Compute Engine et l'environnement d'exécution Cloud TPU. Les métriques suivantes sont générées par les VM Cloud TPU:
memory/usagenetwork/received_bytes_countnetwork/sent_bytes_countcpu/utilizationtpu/tensorcore/idle_durationaccelerator/tensorcore_utilizationaccelerator/memory_bandwidth_utilizationaccelerator/duty_cycleaccelerator/memory_totalaccelerator/memory_used
L'affichage de la valeur d'une métrique dans l'explorateur de métriques peut prendre jusqu'à 180 secondes.
Pour obtenir la liste complète des métriques générées par Cloud TPU, consultez la page Métriques Google Cloud Cloud TPU.
Utilisation de la mémoire
La métrique memory/usage est générée pour la ressource TPU Worker et suit la mémoire utilisée par la VM TPU en octets. Cette métrique est échantillonnée toutes les 60 secondes.
Nombre d'octets reçus sur le réseau
La métrique network/received_bytes_count est générée pour la ressource TPU Worker et suit le nombre cumulé d'octets de données que la VM TPU a reçus sur le réseau à un moment donné.
Nombre d'octets envoyés sur le réseau
La métrique network/sent_bytes_count est générée pour la ressource TPU Worker et suit le nombre cumulé d'octets envoyés par la VM TPU sur le réseau à un moment donné.
Utilisation du processeur
La métrique cpu/utilization est générée pour la ressource TPU Worker et suit l'utilisation actuelle du processeur sur le nœud de calcul TPU, représentée sous forme de pourcentage, échantillonnée une fois par minute. Les valeurs sont généralement comprises entre 0,0 et 100,0, mais peuvent dépasser 100,0.
Durée d'inactivité de TensorCore
La métrique tpu/tensorcore/idle_duration est générée pour la ressource TPU Worker et suit le nombre de secondes pendant lesquelles le TensorCore de chaque puce TPU est inactif. Cette métrique est disponible pour chaque puce de tous les TPU utilisés. Si un TensorCore est utilisé, la valeur de la durée d'inactivité est réinitialisée sur zéro. Lorsque le TensorCore n'est plus utilisé, la valeur de la durée d'inactivité commence à augmenter.
Le graphique suivant montre la métrique tpu/tensorcore/idle_duration pour une VM TPU v2-8 avec un seul nœud de calcul. Chaque nœud de calcul dispose de quatre puces. Dans cet exemple, les quatre chips ont les mêmes valeurs pour tpu/tensorcore/idle_duration. Les graphiques se superposent donc.
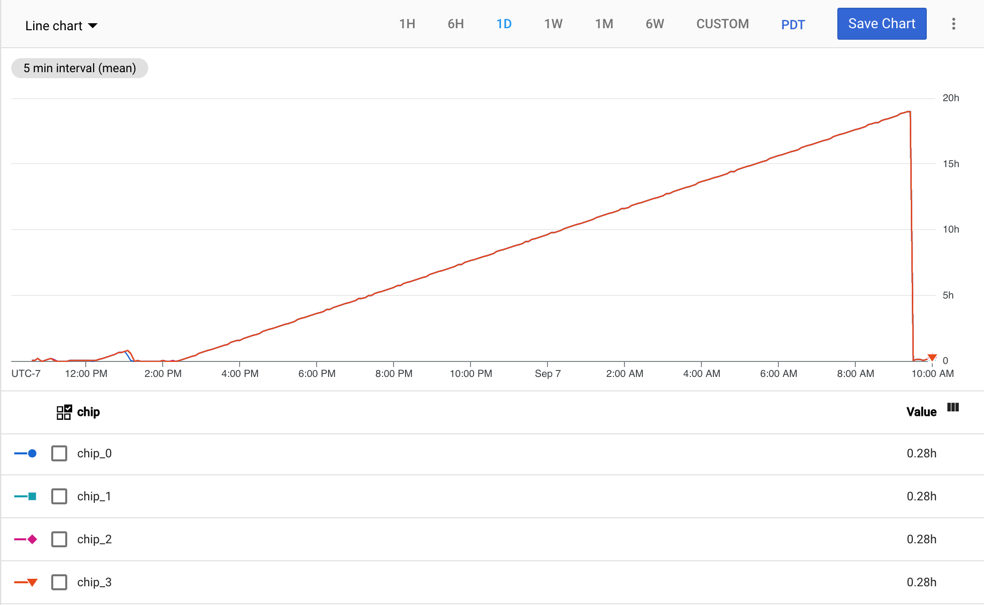
Utilisation de TensorCore
La métrique accelerator/tensorcore_utilization est générée pour la ressource GCE TPU
Worker et suit le pourcentage actuel de TensorCore utilisé. Cette métrique est calculée en divisant le nombre d'opérations TensorCore effectuées sur une période d'échantillonnage par le nombre maximal d'opérations pouvant être effectuées sur la même période d'échantillonnage. Plus la valeur est élevée, plus l'utilisation est optimale. La métrique d'utilisation de TensorCore est compatible avec les générations de TPU v4 et ultérieures.
Utilisation de la bande passante de mémoire
La métrique accelerator/memory_bandwidth_utilization est générée pour la ressource GCE TPU Worker et suit le pourcentage actuel de bande passante mémoire de l'accélérateur utilisée. Cette métrique est calculée en divisant la bande passante mémoire utilisée sur une période d'échantillonnage par la bande passante maximale acceptée sur la même période d'échantillonnage. Plus la valeur est élevée, plus l'utilisation est optimale. La métrique "Utilisation de la bande passante de mémoire" est compatible avec les générations de TPU v4 et ultérieures.
Cycle d'utilisation de l'accélérateur
La métrique accelerator/duty_cycle est générée pour la ressource GCE TPU Worker et suit le pourcentage de temps au cours de la période d'échantillonnage pendant laquelle l'accélérateur TensorCore a été en mode de traitement actif. Les valeurs sont comprises entre 0 et 100. Plus la valeur est élevée, plus l'utilisation de TensorCore est optimale. Cette métrique est indiquée lorsqu'une charge de travail de machine learning s'exécute sur la VM TPU. La métrique du cycle de service de l'accélérateur est compatible avec JAX 0.4.14 et versions ultérieures, PyTorch 2.1 et versions ultérieures, et
TensorFlow 2.14.0 et versions ultérieures.
Mémoire totale de l'accélérateur
La métrique accelerator/memory_total est générée pour la ressource GCE TPU Worker et suit la mémoire totale de l'accélérateur allouée en octets.
Cette métrique est indiquée lorsqu'une charge de travail de machine learning s'exécute sur la VM TPU. La métrique "Mémoire totale de l'accélérateur" est compatible avec JAX 0.4.14 et versions ultérieures, PyTorch 2.1 et versions ultérieures, et
TensorFlow 2.14.0 et versions ultérieures.
Mémoire de l'accélérateur utilisée
La métrique accelerator/memory_used est générée pour la ressource GCE TPU Worker et suit la mémoire d'accélérateur totale utilisée en octets. Cette métrique est indiquée lorsqu'une charge de travail de machine learning s'exécute sur la VM TPU. La métrique "Mémoire de l'accélérateur utilisée" est compatible avec JAX 0.4.14 et versions ultérieures, PyTorch 2.1 et versions ultérieures, et
TensorFlow 2.14.0 et versions ultérieures.
Afficher les métriques
Vous pouvez afficher les métriques à l'aide de l'explorateur de métriques dans la console Google Cloud.
Dans l'explorateur de métriques, cliquez sur Sélectionner une métrique, puis recherchez TPU Worker ou GCE TPU Worker, en fonction de la métrique qui vous intéresse.
Sélectionnez une ressource pour afficher toutes les métriques disponibles pour cette ressource.
Si Active est activé, seules les métriques ayant enregistré des séries temporelles au cours des 25 dernières heures sont listées. Désactivez Active pour afficher toutes les métriques.
Vous pouvez également accéder aux métriques à l'aide d'appels HTTP curl.
Utilisez le bouton Essayez dans la documentation projects.timeSeries.query pour récupérer la valeur d'une métrique au cours de la période spécifiée.
- Saisissez le nom au format suivant:
projects/{project-name}. Ajoutez une requête à la section Request body (Corps de la requête). Voici un exemple de requête permettant de récupérer la métrique de durée d'inactivité pour la zone spécifiée au cours des cinq dernières minutes.
fetch tpu_worker | filter zone = 'us-central2-b' | metric tpu.googleapis.com/tpu/tensorcore/idle_duration | within 5mCliquez sur Execute (Exécuter) pour effectuer l'appel et afficher les résultats du message POST HTTP.
Pour en savoir plus sur la personnalisation de cette requête, consultez la documentation de référence sur le langage de requête de surveillance.
Créer des alertes
Vous pouvez créer des règles d'alerte qui indiquent à Cloud Monitoring d'envoyer une alerte lorsqu'une condition est remplie.
Les étapes de cette section présentent un exemple d'ajout d'une règle d'alerte pour la métrique TensorCore Idle Duration. Chaque fois que cette métrique dépasse 24 heures, Cloud Monitoring envoie un e-mail à l'adresse e-mail enregistrée.
- Accédez à la console Monitoring.
- Dans le volet de navigation, cliquez sur Alertes.
- Cliquez sur Modifier les canaux de notification.
- Sous Adresse e-mail, cliquez sur Ajouter. Saisissez une adresse e-mail et un nom à afficher, puis cliquez sur Enregistrer.
- Sur la page Alertes, cliquez sur Créer une règle.
- Cliquez sur Sélectionner une métrique, puis sélectionnez Durée d'inactivité du Tensor Core, puis cliquez sur Appliquer.
- Cliquez sur Suivant, puis sur Seuil.
- Pour Déclencheur d'alerte, sélectionnez À chaque infraction de série temporelle.
- Pour Position du seuil, sélectionnez Au-dessus du seuil.
- Dans le champ Valeur du seuil, saisissez
86400000. - Cliquez sur Suivant.
- Sous Canaux de notification, sélectionnez votre canal de notification par e-mail, puis cliquez sur OK.
- Saisissez un nom pour la règle d'alerte.
- Cliquez sur Suivant, puis sur Créer une règle.
Lorsque la durée d'inactivité du TensorCore dépasse 24 heures, un e-mail est envoyé à l'adresse e-mail que vous avez spécifiée.
Journalisation
Les entrées de journal sont écrites par les services Google Cloud, les services tiers, les frameworks ML ou votre code. Vous pouvez afficher les journaux à l'aide de l'explorateur de journaux ou de l'API Logs. Pour en savoir plus sur la journalisation Google Cloud, consultez Google Cloud Logging.
Les journaux des nœuds de calcul TPU contiennent des informations sur un nœud de calcul Cloud TPU spécifique dans une zone spécifique, par exemple la quantité de mémoire disponible sur le nœud de calcul Cloud TPU (system_available_memory_GiB).
Les journaux des ressources auditées contiennent des informations sur le moment où une API Cloud TPU spécifique a été appelée et sur l'auteur de l'appel. Par exemple, vous pouvez trouver des informations sur les appels aux API CreateNode, UpdateNode et DeleteNode.
Les frameworks de ML peuvent générer des journaux dans la sortie standard et l'erreur standard. Ces journaux sont contrôlés par des variables d'environnement et sont lus par votre script d'entraînement.
Votre code peut écrire des journaux dans Google Cloud Logging. Pour en savoir plus, consultez les pages Écrire des journaux standards et Écrire des journaux structurés.
Interroger les journaux Google Cloud
Lorsque vous consultez des journaux dans la console Google Cloud, la page effectue une requête par défaut.
Vous pouvez afficher la requête en sélectionnant le bouton bascule Show query. Vous pouvez modifier la requête par défaut ou en créer une. Pour en savoir plus, consultez la page Créer des requêtes dans l'explorateur de journaux.
Journaux des ressources auditées
Pour afficher les journaux des ressources auditées:
- Accédez à l'explorateur de journaux Google Cloud.
- Cliquez sur le menu déroulant Toutes les ressources.
- Cliquez sur Ressource auditée, puis sur Cloud TPU.
- Choisissez l'API Cloud TPU qui vous intéresse.
- Cliquez sur Appliquer. Les journaux sont affichés dans les résultats de la requête.
Cliquez sur une entrée de journal pour la développer. Chaque entrée de journal comporte plusieurs champs, y compris les suivants:
- logName: nom du journal
- protoPayload -> @type: type du journal
- protoPayload -> resourceName: nom de votre Cloud TPU
- protoPayload -> methodName: nom de la méthode appelée (journaux d'audit uniquement)
- protoPayload -> request -> @type: type de requête
- protoPayload -> request -> node: détails sur le nœud Cloud TPU
- protoPayload -> request -> node_id: nom du TPU
- severity: gravité du journal
Journaux du nœud de calcul TPU
Pour afficher les journaux des nœuds de calcul TPU:
- Accédez à l'explorateur de journaux Google Cloud.
- Cliquez sur le menu déroulant Toutes les ressources.
- Cliquez sur Nœud de calcul TPU.
- Sélectionnez une zone.
- Sélectionnez le Cloud TPU qui vous intéresse.
- Cliquez sur Appliquer. Les journaux sont affichés dans les résultats de la requête.
Cliquez sur une entrée de journal pour la développer. Chaque entrée de journal comporte un champ appelé jsonPayload. Développez jsonPayload pour afficher plusieurs champs, y compris les suivants:
- accelerator_type: type d'accélérateur
- consumer_project: projet dans lequel se trouve le Cloud TPU
- evententry_timestamp: heure à laquelle le journal a été généré
- system_available_memory_GiB: mémoire disponible sur le nœud de travail Cloud TPU (0 à 350 Gio)
Créer des métriques basées sur des journaux
Cette section explique comment créer les métriques basées sur les journaux utilisées pour configurer les tableaux de bord et les alertes de surveillance. Pour en savoir plus sur la création de métriques basées sur les journaux par programmation, consultez la section Créer des métriques basées sur les journaux par programmation à l'aide de l'API REST Cloud Logging.
Dans l'exemple suivant, le sous-champ system_available_memory_GiB illustre comment créer une métrique basée sur les journaux pour surveiller la mémoire disponible des nœuds de travail Cloud TPU.
- Accédez à l'explorateur de journaux Google Cloud.
Dans la zone de requête, saisissez la requête suivante pour extraire toutes les entrées de journal où le sous-champ system_available_memory_GiB est défini pour le nœud de calcul Cloud TPU principal:
resource.type=tpu_worker resource.labels.project_id=your-project resource.labels.zone=your-tpu-zone resource.labels.node_id=your-tpu-name resource.labels.worker_id=0 logName=projects/your-project/logs/tpu.googleapis.com%2Fruntime_monitor jsonPayload.system_available_memory_GiB:*
Cliquez sur Créer une métrique pour afficher l'éditeur de métriques.
Sous Type de métrique, sélectionnez Distribution.
Saisissez un nom, une description facultative et une unité de mesure pour votre métrique. Pour cet exemple, saisissez "matrix_unit_utilization_percent" et "Utilisation des unités matricielles" dans les champs Nom et Description, respectivement. Le filtre est prérempli avec le script que vous avez saisi dans l'explorateur de journaux.
Cliquez sur Créer une métrique.
Cliquez sur Afficher dans l'explorateur de métriques pour afficher votre nouvelle métrique. L'affichage de vos métriques peut prendre quelques minutes.
Créer des métriques basées sur les journaux avec l'API REST Cloud Logging
Vous pouvez également créer des métriques basées sur les journaux via l'API Cloud Logging. Pour en savoir plus, consultez Créer une métrique de distribution.
Créer des tableaux de bord et des alertes à l'aide de métriques basées sur les journaux
Les tableaux de bord sont utiles pour visualiser les métriques (prévoir un délai d'environ deux minutes), et les alertes pour envoyer des notifications en cas d'erreur. Pour en savoir plus, consultez les pages suivantes :
- Tableaux de bord de surveillance et de journalisation
- Gérer les tableaux de bord personnalisés
- Créer des règles d'alerte basées sur des métriques
Créer des tableaux de bord
Pour créer un tableau de bord dans Cloud Monitoring pour la métrique Durée d'inactivité de Tensor Core:
- Accédez à la console Monitoring.
- Dans le volet de navigation, cliquez sur Tableaux de bord.
- Cliquez sur Créer un tableau de bord, puis sur Ajouter un widget.
- Choisissez le type de graphique à ajouter. Pour cet exemple, choisissez Ligne.
- Saisissez un titre pour le widget.
- Cliquez sur le menu déroulant Sélectionner une métrique, puis saisissez "Durée d'inactivité du Tensor Core" dans le champ de filtre.
- Dans la liste des métriques, sélectionnez TPU Worker (Agent TPU) -> Tpu (TPU) -> Tensorcore idle duration (Durée d'inactivité du Tensorcore).
- Pour filtrer le contenu du tableau de bord, cliquez sur le menu déroulant Filtrer.
- Sous Libellés de ressources, sélectionnez project_id.
- Choisissez un comparateur, puis saisissez une valeur dans le champ Valeur.
- Cliquez sur Appliquer.