Memantau VM Cloud TPU
Panduan ini menjelaskan cara menggunakan Google Cloud Monitoring untuk memantau VM Cloud TPU Anda. Google Cloud Monitoring secara otomatis mengumpulkan metrik dan log dari Cloud TPU dan Compute Engine host-nya. Data ini dapat digunakan untuk memantau kondisi Cloud TPU dan Compute Engine Anda.
Metrik memungkinkan Anda melacak kuantitas numerik dari waktu ke waktu, misalnya, pemakaian CPU, penggunaan jaringan, atau durasi tidak ada aktivitas TensorCore. Log mencatat peristiwa pada titik waktu tertentu. Entri log ditulis oleh kode Anda sendiri, Google Cloud layanan, aplikasi pihak ketiga, dan infrastruktur Google Cloud . Anda juga dapat membuat metrik dari data yang ada dalam entri log dengan membuat metrik berbasis log. Anda juga dapat menetapkan kebijakan pemberitahuan berdasarkan nilai metrik atau entri log.
Panduan ini membahas Pemantauan Google Cloud dan menunjukkan cara:
- Melihat metrik Cloud TPU
- Menyiapkan kebijakan pemberitahuan metrik Cloud TPU
- Kueri log Cloud TPU
- Buat metrik berbasis log untuk menyiapkan pemberitahuan dan memvisualisasikan dasbor
Dokumen ini mengasumsikan beberapa pengetahuan dasar tentang Google Cloud Monitoring. Anda harus memiliki resource VM Compute Engine dan Cloud TPU yang dibuat sebelum dapat mulai membuat dan menggunakan Google Cloud Monitoring. Lihat Panduan Memulai Cloud TPU untuk mengetahui detail selengkapnya.
Metrik
MetrikGoogle Cloud dibuat secara otomatis oleh VM Compute Engine dan runtime Cloud TPU. Metrik berikut dihasilkan oleh VM Cloud TPU:
memory/usagenetwork/received_bytes_countnetwork/sent_bytes_countcpu/utilizationtpu/tensorcore/idle_durationaccelerator/tensorcore_utilizationaccelerator/memory_bandwidth_utilizationaccelerator/duty_cycleaccelerator/memory_totalaccelerator/memory_used
Mungkin perlu waktu hingga 180 detik antara saat nilai metrik dibuat dan saat ditampilkan di Penjelajah metrik.
Untuk mengetahui daftar lengkap metrik yang dihasilkan oleh Cloud TPU, lihat Google Cloud Metrik Cloud TPU.
Penggunaan memori
Metrik memory/usage dihasilkan untuk resource TPU Worker dan melacak
memori yang digunakan oleh VM TPU dalam byte. Metrik ini diambil sampelnya setiap 60 detik.
Jumlah byte jaringan yang diterima
Metrik network/received_bytes_count dihasilkan untuk resource TPU Worker dan melacak jumlah byte data kumulatif yang diterima VM TPU melalui jaringan pada suatu titik waktu.
Jumlah byte yang dikirim jaringan
Metrik network/sent_bytes_count dibuat untuk resource TPU Worker
dan melacak jumlah byte kumulatif yang dikirim VM TPU melalui jaringan pada
titik waktu tertentu.
Pemakaian CPU
Metrik cpu/utilization dihasilkan untuk resource TPU Worker dan melacak pemakaian CPU saat ini pada TPU worker, yang dinyatakan sebagai persentase, yang diambil sampelnya sekali per menit. Nilai biasanya antara 0,0 dan 100,0, tetapi mungkin melebihi 100,0.
Durasi tidak ada aktivitas TensorCore
Metrik tpu/tensorcore/idle_duration dibuat untuk resource TPU Worker
dan melacak jumlah detik TensorCore setiap chip TPU telah
menganggur. Metrik ini tersedia untuk setiap chip di semua TPU yang digunakan. Jika TensorCore
sedang digunakan, nilai durasi tidak ada aktivitas akan direset ke nol. Saat TensorCore tidak lagi digunakan, nilai durasi tidak ada aktivitas akan mulai meningkat.
Grafik berikut menunjukkan metrik tpu/tensorcore/idle_duration untuk VM TPU v2-8
yang memiliki satu pekerja. Setiap pekerja memiliki empat chip. Dalam contoh ini, keempat chip memiliki nilai yang sama untuk tpu/tensorcore/idle_duration, sehingga grafik saling tumpang-tindih.
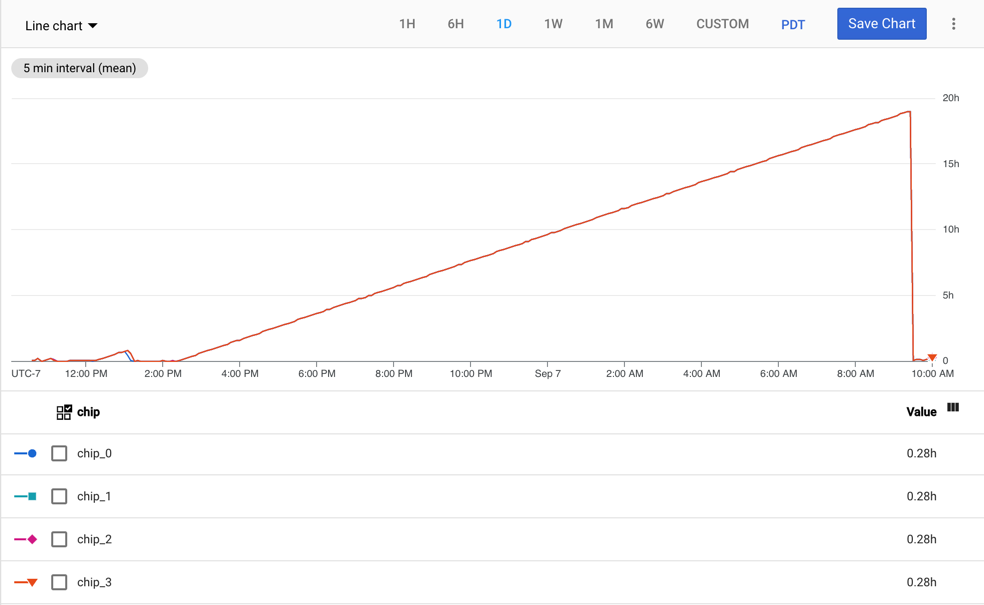
Penggunaan TensorCore
Metrik accelerator/tensorcore_utilization dibuat untuk resource GCE TPU
Worker dan melacak persentase TensorCore saat ini yang digunakan. Metrik ini dihitung dengan membagi jumlah operasi TensorCore yang dilakukan selama periode sampel dengan jumlah maksimum operasi yang dapat dilakukan selama periode sampel yang sama. Nilai yang lebih besar berarti pemakaian yang lebih baik. Metrik pemakaian TensorCore didukung oleh generasi TPU v4 dan yang lebih baru.
Penggunaan Bandwidth Memori
Metrik accelerator/memory_bandwidth_utilization dibuat untuk resource
GCE TPU Worker dan melacak persentase bandwidth memori akselerator saat ini yang sedang digunakan. Metrik ini dihitung dengan membagi bandwidth memori yang digunakan selama periode sampel dengan bandwidth maksimum yang didukung selama periode sampel yang sama. Nilai yang lebih besar berarti pemakaian yang lebih baik. Metrik Penggunaan Bandwidth Memori didukung oleh TPU generasi v4 dan yang lebih baru.
Siklus Tugas Akselerator
Metrik accelerator/duty_cycle dihasilkan untuk resource GCE TPU Worker dan melacak persentase waktu selama periode sampel saat TensorCore akselerator diproses secara aktif. Nilai berada dalam rentang 0
hingga 100. Nilai yang lebih besar berarti pemakaian TensorCore yang lebih baik. Metrik ini dilaporkan saat workload machine learning berjalan di VM TPU. Metrik Siklus Tugas Akselerator didukung untuk JAX
0.4.14 dan yang lebih baru,
PyTorch
2.1 dan yang lebih baru, serta
TensorFlow
2.14.0 dan yang lebih baru.
Total Memori Akselerator
Metrik accelerator/memory_total dibuat untuk resource GCE TPU Worker
dan melacak total memori akselerator yang dialokasikan dalam byte.
Metrik ini dilaporkan saat workload machine learning berjalan di TPU VM. Metrik Total Memori Akselerator didukung untuk JAX
0.4.14 dan yang lebih baru,
PyTorch
2.1 dan yang lebih baru, serta
TensorFlow
2.14.0 dan yang lebih baru.
Penggunaan Memori Akselerator
Metrik accelerator/memory_used dibuat untuk resource GCE TPU Worker
dan melacak total memori akselerator yang digunakan dalam byte. Metrik ini dilaporkan saat workload machine learning berjalan di VM TPU. Metrik Penggunaan Memori Akselerator didukung untuk JAX
0.4.14 dan yang lebih baru,
PyTorch
2.1 dan yang lebih baru, serta
TensorFlow
2.14.0 dan yang lebih baru.
Melihat metrik
Anda dapat melihat metrik menggunakan Metrics explorer di konsol Google Cloud .
Di Metrics explorer, klik Pilih metrik, lalu telusuri TPU Worker
atau GCE TPU Worker, bergantung pada metrik yang Anda minati.
Pilih resource untuk menampilkan semua metrik yang tersedia untuk resource tersebut.
Jika Aktif diaktifkan, hanya metrik dengan data deret waktu dalam 25 jam terakhir yang akan dicantumkan. Nonaktifkan Aktif untuk mencantumkan semua metrik.
Anda juga dapat mengakses metrik menggunakan panggilan HTTP curl.
Gunakan tombol Coba di dokumentasi projects.timeSeries.query untuk mengambil nilai metrik dalam jangka waktu yang ditentukan.
- Isi nama dalam format berikut:
projects/{project-name}. Tambahkan kueri ke bagian Isi permintaan. Berikut adalah contoh kueri untuk mengambil metrik durasi tidak ada aktivitas untuk zona yang ditentukan selama lima menit terakhir.
fetch tpu_worker | filter zone = 'us-central2-b' | metric tpu.googleapis.com/tpu/tensorcore/idle_duration | within 5mKlik Execute untuk melakukan panggilan dan melihat hasil pesan HTTP POST.
Dokumen Referensi Monitoring Query Language memiliki informasi selengkapnya tentang cara menyesuaikan kueri ini.
Membuat pemberitahuan
Anda dapat membuat kebijakan pemberitahuan yang memberi tahu Cloud Monitoring untuk mengirim pemberitahuan saat suatu kondisi terpenuhi.
Langkah-langkah di bagian ini menunjukkan contoh cara menambahkan kebijakan pemberitahuan untuk metrik Durasi Idle TensorCore. Setiap kali metrik ini melebihi 24 jam, Cloud Monitoring akan mengirimkan email ke alamat email terdaftar.
- Buka konsol Monitoring.
- Di panel navigasi, klik Pemberitahuan.
- Klik Edit saluran notifikasi.
- Di bagian Email, klik Tambahkan baru. Ketik alamat email, nama tampilan, lalu klik Simpan.
- Di halaman Pemberitahuan, klik Buat kebijakan.
- Klik Pilih metrik, lalu pilih Tensorcore Idle Duration, lalu klik Terapkan.
- Klik Berikutnya, lalu Nilai minimum.
- Untuk Pemicu pemberitahuan, pilih Deret waktu mana pun melanggar.
- Untuk Posisi nilai minimum, pilih Di atas nilai minimum.
- Untuk Threshold value, ketik
86400000. - Klik Berikutnya.
- Di bagian Saluran notifikasi, pilih saluran notifikasi email Anda, lalu klik OKE.
- Ketik nama untuk kebijakan pemberitahuan.
- Klik Berikutnya, lalu Buat kebijakan.
Jika Durasi Idle TensorCore melebihi 24 jam, email akan dikirim ke alamat email yang Anda tentukan.
Logging
Entri log ditulis oleh Google Cloud layanan, layanan pihak ketiga, framework ML, atau kode Anda. Anda dapat melihat log menggunakan Logs Explorer atau Logs API. Untuk mengetahui informasi selengkapnya tentang Google Cloud logging, lihat Google Cloud Logging.
Log TPU Worker berisi informasi tentang Cloud TPU worker tertentu di zona tertentu, misalnya jumlah memori yang tersedia di Cloud TPU worker (system_available_memory_GiB).
Log Resource yang Diaudit berisi informasi tentang kapan API Cloud TPU
tertentu dipanggil dan siapa yang melakukan panggilan. Misalnya, Anda dapat menemukan informasi
tentang panggilan ke API CreateNode, UpdateNode, dan DeleteNode.
Framework ML dapat menghasilkan log ke output standar dan error standar. Log ini dikontrol oleh variabel lingkungan dan dibaca oleh skrip pelatihan Anda.
Kode Anda dapat menulis log ke Google Cloud Logging. Untuk mengetahui informasi selengkapnya, lihat Menulis log standar dan Menulis log terstruktur.
Logging port serial
Cloud TPU mengandalkan logging port serial untuk pemecahan masalah, pemantauan, dan proses debug. Setelan defaultnya adalah mengaktifkan logging port serial. Jika logging port serial tidak diaktifkan, proses pembuatan VM TPU akan gagal dan menghasilkan pesan error berikut.
"Cloud TPU received a bad request. Constraint
`constraints/compute.disableSerialPortLogging` violated. Create TPUs with
serial port logging enabled or remove the Organization Policy Constraint."
Pesan ini menunjukkan bahwa batasan,
constraints/compute.disableSerialPortLogging telah dilanggar.
Untuk mencegah error ini, Anda harus memastikan logging port serial diizinkan untuk project TPU Anda. Praktik terbaiknya adalah mengganti kebijakan organisasi di tingkat project.
Untuk mengetahui informasi selengkapnya tentang cara mengaktifkan logging port serial, lihat artikel Mengaktifkan dan menonaktifkan logging output port serial.
Log Google Cloud kueri
Saat Anda melihat log di konsol Google Cloud , halaman akan menjalankan kueri default.
Anda dapat melihat kueri dengan memilih tombol Show query. Anda dapat
mengubah kueri default atau membuat kueri baru. Untuk mengetahui informasi selengkapnya, lihat
Membangun Kueri di Logs Explorer.
Log resource yang diaudit
Untuk melihat log Resource yang Diaudit:
- Buka Google Cloud Logs Explorer.
- Klik drop-down Semua resource.
- Klik Audited Resource, lalu klik Cloud TPU.
- Pilih Cloud TPU API yang Anda inginkan.
- Klik Terapkan. Log ditampilkan di hasil kueri.
Klik entri log mana pun untuk meluaskannya. Setiap entri log memiliki beberapa kolom, termasuk:
- logName: nama log
- protoPayload -> @type: jenis log
- protoPayload -> resourceName: nama Cloud TPU Anda
- protoPayload -> methodName: nama metode yang dipanggil (khusus log audit)
- protoPayload -> request -> @type: jenis permintaan
- protoPayload -> request -> node: detail tentang node Cloud TPU
- protoPayload -> request -> node_id: nama TPU
- severity: tingkat keparahan log
Log TPU Worker
Untuk melihat log TPU Worker:
- Buka Google Cloud Logs Explorer.
- Klik drop-down Semua resource.
- Klik TPU Worker.
- Pilih zona.
- Pilih Cloud TPU yang Anda minati.
- Klik Terapkan. Log ditampilkan di hasil kueri.
Klik entri log mana pun untuk meluaskannya. Setiap entri log memiliki kolom yang disebut
jsonPayload. Luaskan jsonPayload untuk melihat beberapa kolom, termasuk:
- accelerator_type: jenis akselerator
- consumer_project: project tempat Cloud TPU berada
- evententry_timestamp: waktu saat log dibuat
- system_available_memory_GiB: memori yang tersedia di pekerja Cloud TPU (0 ~ 350 GiB)
Membuat metrik berbasis log
Bagian ini menjelaskan cara membuat metrik berbasis log yang digunakan untuk menyiapkan dasbor dan pemberitahuan pemantauan. Untuk mengetahui informasi tentang cara membuat metrik berbasis log secara terprogram, lihat Membuat metrik berbasis log secara terprogram menggunakan Cloud Logging REST API.
Contoh berikut menggunakan sub-bidang system_available_memory_GiB untuk mendemonstrasikan cara membuat metrik berbasis log untuk memantau memori yang tersedia di pekerja Cloud TPU.
- Buka Google Cloud Logs Explorer.
Di kotak kueri, masukkan kueri berikut untuk mengekstrak semua entri log yang memiliki system_available_memory_GiB yang ditentukan untuk worker Cloud TPU utama:
resource.type=tpu_worker resource.labels.project_id=your-project resource.labels.zone=your-tpu-zone resource.labels.node_id=your-tpu-name resource.labels.worker_id=0 logName=projects/your-project/logs/tpu.googleapis.com%2Fruntime_monitor jsonPayload.system_available_memory_GiB:*
Klik Buat metrik untuk menampilkan Editor Metrik.
Di bagian Metric Type, pilih Distribution.
Ketik nama, deskripsi opsional, dan satuan pengukuran untuk metrik Anda. Untuk contoh ini, ketik "matrix_unit_utilization_percent" dan "Penggunaan MXU" di kolom Nama dan Deskripsi. Filter ini sudah diisi otomatis dengan skrip yang Anda masukkan di Logs Explorer.
Klik Create metric.
Klik Lihat di Metrics Explorer untuk melihat metrik baru Anda. Mungkin perlu waktu beberapa menit sebelum metrik Anda ditampilkan.
Membuat metrik berbasis log dengan Cloud Logging REST API
Anda juga dapat membuat metrik berbasis log melalui Cloud Logging API. Untuk mengetahui informasi selengkapnya, lihat Membuat metrik distribusi.
Membuat dasbor dan pemberitahuan menggunakan metrik berbasis log
Dasbor berguna untuk memvisualisasikan metrik (perkiraan penundaan ~2 menit); pemberitahuan berguna untuk mengirim notifikasi saat terjadi error. Untuk informasi selengkapnya, lihat:
- Dasbor pemantauan dan logging
- Mengelola dasbor kustom
- Membuat kebijakan pemberitahuan berbasis metrik
Membuat dasbor
Untuk membuat dasbor di Cloud Monitoring untuk metrik Durasi tidak ada aktivitas Tensorcore:
- Buka konsol Monitoring.
- Di panel navigasi, klik Dasbor.
- Klik Buat dasbor, lalu Tambahkan widget.
- Pilih jenis diagram yang ingin Anda tambahkan. Untuk contoh ini, pilih Garis.
- Ketik judul untuk widget.
- Klik menu drop-down Select a metric dan ketik "Tensorcore idle duration" di kolom filter.
- Di daftar metrik, pilih TPU Worker -> Tpu -> Tensorcore idle duration.
- Untuk memfilter konten dasbor, klik menu drop-down Filter.
- Di bagian Resource labels, pilih project_id.
- Pilih pembanding dan ketik nilai di kolom Nilai.
- Klik Terapkan.