Cloud TPU-VMs überwachen
In diesem Leitfaden wird erläutert, wie Sie mit Google Cloud Monitoring Ihre Cloud TPU-VMs überwachen. Google Cloud Monitoring erfasst automatisch Messwerte und Logs von Ihrer Cloud TPU und dem zugehörigen Compute Engine-Host. Mit diesen Daten können Sie den Zustand Ihrer Cloud TPU und Compute Engine überwachen.
Mit Messwerten können Sie eine numerische Größe im Zeitverlauf verfolgen, z. B. die CPU-Auslastung, die Netzwerknutzung oder die Leerlaufdauer von Tensor-Kernen. In Logs werden Ereignisse zu einem bestimmten Zeitpunkt erfasst. Logeinträge werden von Ihrem eigenen Code, Google CloudDiensten, Anwendungen von Drittanbietern und der Google Cloud Infrastruktur geschrieben. Sie können auch Messwerte aus den Daten in einem Logeintrag generieren, indem Sie einen logbasierten Messwert erstellen. Sie können auch Benachrichtigungsrichtlinien auf Grundlage von Messwerten oder Logeinträgen festlegen.
In diesem Leitfaden wird Google Cloud Monitoring behandelt und es wird gezeigt, wie Sie:
- Cloud TPU-Messwerte ansehen
- Benachrichtigungsrichtlinien für Cloud TPU-Messwerte einrichten
- Cloud TPU-Logs abfragen
- Logbasierte Messwerte erstellen, um Benachrichtigungen einzurichten und Dashboards zu visualisieren
Sie können TPUs auch mit dem Capacity Planner (Vorabversion) überwachen. Mit dem Capacity Planner können Sie Daten zur TPU-Nutzung und ‑Prognose für Ihr Projekt, Ihren Ordner oder Ihre Organisation ansehen. Diese Daten werden alle 24 Stunden aktualisiert. Sie können sie verwenden, um Nutzungstrends zu analysieren und den zukünftigen Kapazitätsbedarf zu planen. Weitere Informationen finden Sie unter Übersicht über den Kapazitätsplaner.
In diesem Dokument werden Grundkenntnisse in Google CloudMonitoring vorausgesetzt. Sie müssen eine Compute Engine-VM und Cloud TPU-Ressourcen erstellt haben, bevor Sie Google Cloud Monitoring verwenden können. Weitere Informationen finden Sie in der Cloud TPU-Kurzanleitung.
Messwerte
Google Cloud -Messwerte werden automatisch von Compute Engine-VMs und der Cloud TPU-Laufzeit generiert. Die folgenden Messwerte werden von Cloud TPU-VMs generiert:
memory/usagenetwork/received_bytes_countnetwork/sent_bytes_countcpu/utilizationtpu/tensorcore/idle_durationaccelerator/tensorcore_utilizationaccelerator/memory_bandwidth_utilizationaccelerator/duty_cycleaccelerator/memory_totalaccelerator/memory_used
Es kann bis zu 180 Sekunden dauern, bis ein Messwert im Messwert-Explorer angezeigt wird.
Eine vollständige Liste der von Cloud TPU generierten Messwerte finden Sie unter Google Cloud Cloud TPU-Messwerte.
Arbeitsspeichernutzung
Der Messwert memory/usage wird für die Ressource TPU Worker generiert und erfasst den von der TPU-VM verwendeten Arbeitsspeicher in Byte. Dieser Messwert wird alle 60 Sekunden abgerufen.
Anzahl der vom Netzwerk empfangenen Byte
Der Messwert network/received_bytes_count wird für die Ressource TPU Worker generiert und erfasst die Anzahl der kumulativen Datenbyte, die die TPU-VM zu einem bestimmten Zeitpunkt über das Netzwerk empfangen hat.
Anzahl der vom Netzwerk gesendeten Byte
Der Messwert network/sent_bytes_count wird für die Ressource TPU Worker generiert und erfasst die Anzahl der kumulativen Byte, die die TPU-VM zu einem bestimmten Zeitpunkt über das Netzwerk gesendet hat.
CPU-Auslastung
Der Messwert cpu/utilization wird für die Ressource TPU Worker generiert und erfasst die aktuelle CPU-Auslastung auf dem TPU-Worker, dargestellt als Prozentsatz, der einmal pro Minute erfasst wird. Die Werte liegen in der Regel zwischen 0,0 und 100,0, können aber auch über 100,0 liegen.
TensorCore-Inaktivitätsdauer
Der Messwert tpu/tensorcore/idle_duration wird für die Ressource TPU Worker generiert und gibt die Anzahl der Sekunden an, in denen der TensorCore jedes TPU-Chips im Leerlauf war. Dieser Messwert ist für jeden Chip auf allen verwendeten TPUs verfügbar. Wenn ein TensorCore verwendet wird, wird der Wert für die Leerlaufdauer auf null zurückgesetzt. Wenn der TensorCore nicht mehr verwendet wird, beginnt der Wert für die Leerlaufdauer zu steigen.
Das folgende Diagramm zeigt den Messwert tpu/tensorcore/idle_duration für eine TPU-VM vom Typ v2-8 mit einem Worker. Jeder Worker hat vier Chips. In diesem Beispiel haben alle vier Chips dieselben Werte für tpu/tensorcore/idle_duration. Die Grafiken werden also übereinander dargestellt.
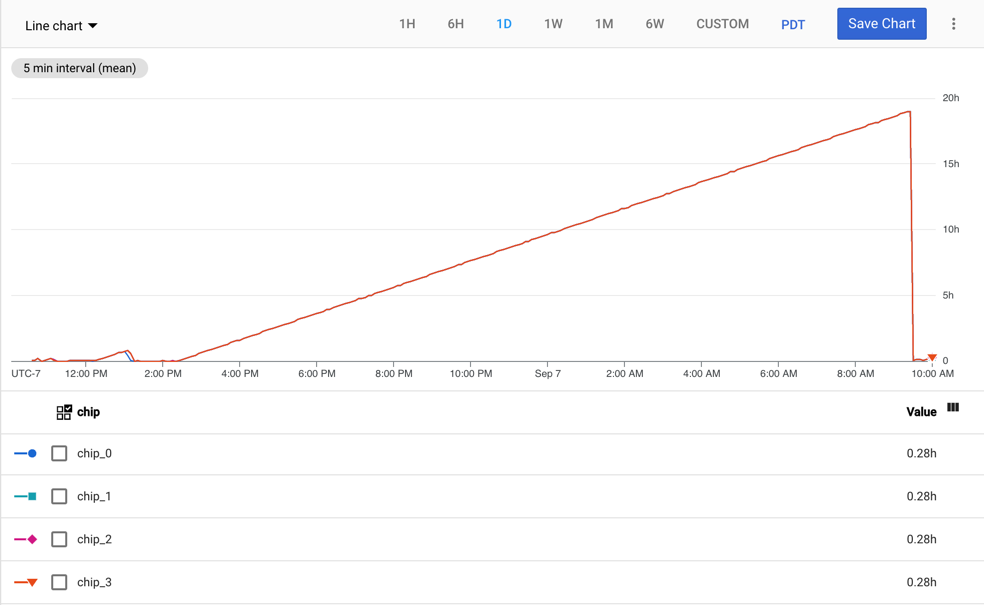
TensorCore-Auslastung
Die Metrik accelerator/tensorcore_utilization wird für die Ressource GCE TPU
Worker generiert und gibt den aktuellen Prozentsatz des verwendeten TensorCore an. Dieser Messwert wird berechnet, indem die Anzahl der TensorCore-Vorgänge, die in einem Stichprobenzeitraum ausgeführt wurden, durch die maximale Anzahl von Vorgängen geteilt wird, die im selben Stichprobenzeitraum ausgeführt werden können. Ein größerer Wert bedeutet eine bessere Auslastung. Der Messwert „TensorCore-Auslastung“ wird von TPU-Generationen ab v4 unterstützt.
Auslastung der Arbeitsspeicherbandbreite
Der Messwert accelerator/memory_bandwidth_utilization wird für die Ressource GCE TPU Worker generiert und gibt den aktuellen Prozentsatz der verwendeten Arbeitsspeicherbandbreite des Beschleunigers an. Dieser Messwert wird berechnet, indem die in einem Stichprobenzeitraum verwendete Arbeitsspeicherbandbreite durch die maximal unterstützte Bandbreite im selben Stichprobenzeitraum geteilt wird. Ein größerer Wert bedeutet eine bessere Auslastung. Die Messwerte zur Arbeitsspeicherbandbreitenauslastung werden von TPU-Generationen ab v4 unterstützt.
Accelerator-Arbeitszyklus
Der Messwert accelerator/duty_cycle wird für die Ressource GCE TPU Worker generiert und gibt den Prozentsatz der Zeit im Stichprobenzeitraum an, in dem der TensorCore des Beschleunigers aktiv verarbeitet wurde. Die Werte liegen zwischen 0 und 100. Ein höherer Wert bedeutet eine bessere TensorCore-Auslastung. Dieser Messwert wird gemeldet, wenn eine ML-Arbeitslast auf der TPU-VM ausgeführt wird. Die Messwert „Accelerator Duty Cycle“ wird für JAX 0.4.14 und höher, PyTorch 2.1 und höher sowie
TensorFlow 2.14.0 und höher unterstützt.
Accelerator-Speicher gesamt
Der Messwert accelerator/memory_total wird für die Ressource GCE TPU Worker generiert und erfasst den gesamten zugewiesenen Arbeitsspeicher des Beschleunigers in Byte.
Dieser Messwert wird gemeldet, wenn eine ML-Arbeitslast auf der TPU-VM ausgeführt wird. Die Messwert „Accelerator Memory Total“ wird für JAX 0.4.14 und höher, PyTorch 2.1 und höher sowie
TensorFlow 2.14.0 und höher unterstützt.
Belegter Accelerator-Speicher
Der Messwert accelerator/memory_used wird für die Ressource GCE TPU Worker generiert und erfasst den gesamten verwendeten Accelerator-Arbeitsspeicher in Byte. Dieser Messwert wird gemeldet, wenn eine ML-Arbeitslast auf der TPU-VM ausgeführt wird. Der Messwert „Accelerator Memory Used“ (Verwendeter Beschleunigerspeicher) wird für JAX 0.4.14 und höher, PyTorch 2.1 und höher sowie
TensorFlow 2.14.0 und höher unterstützt.
Messwerte ansehen
Sie können Messwerte mit dem Metrics Explorer in der Google Cloud -Konsole ansehen.
Klicken Sie im Metrics Explorer auf Messwert auswählen und suchen Sie je nach dem gewünschten Messwert nach TPU Worker oder GCE TPU Worker.
Wählen Sie eine Ressource aus, um alle verfügbaren Messwerte für diese Ressource aufzurufen.
Wenn Aktiv aktiviert ist, werden nur Messwerte mit Zeitreihendaten aus den letzten 25 Stunden aufgeführt. Deaktivieren Sie Aktiv, um alle Messwerte aufzulisten.
Sie können auch über curl-HTTP-Aufrufe auf Messwerte zugreifen.
Verwenden Sie die Schaltfläche Ausprobieren in der Dokumentation zu „projects.timeSeries.query“, um den Wert für einen Messwert im angegebenen Zeitraum abzurufen.
- Geben Sie den Namen im folgenden Format ein:
projects/{project-name}. Fügen Sie dem Abschnitt Anfragetext eine Anfrage hinzu. Im Folgenden finden Sie ein Beispiel für eine Abfrage zum Abrufen des Messwerts für die Leerlaufdauer für die angegebene Zone für die letzten fünf Minuten.
fetch tpu_worker | filter zone = 'us-central2-b' | metric tpu.googleapis.com/tpu/tensorcore/idle_duration | within 5mKlicken Sie auf Ausführen, um den Aufruf auszuführen und die Ergebnisse der HTTP POST-Nachrichte zu sehen.
Weitere Informationen zum Anpassen dieser Abfrage finden Sie in der Referenz zu Monitoring Query Language.
Alerts erstellen
Sie können Benachrichtigungsrichtlinien erstellen, mit denen Cloud Monitoring angewiesen wird, eine Benachrichtigung zu senden, wenn eine Bedingung erfüllt ist.
Die Schritte in diesem Abschnitt zeigen ein Beispiel für das Hinzufügen einer Benachrichtigungsrichtlinie für den Messwert TensorCore Idle Duration. Wenn dieser Messwert 24 Stunden überschreitet, sendet Cloud Monitoring eine E-Mail an die registrierte E-Mail-Adresse.
- Monitoring-Konsole öffnen
- Klicken Sie im Navigationsbereich auf Benachrichtigungen.
- Klicken Sie auf Edit notification channels (Benachrichtigungskanäle bearbeiten).
- Klicken Sie unter E-Mail auf Neu hinzufügen. Geben Sie eine E‑Mail-Adresse und einen Anzeigenamen ein und klicken Sie auf Speichern.
- Klicken Sie auf der Seite Benachrichtigungen auf Richtlinie erstellen.
- Klicken Sie auf Messwert auswählen, wählen Sie Tensorcore-Leerlaufdauer aus und klicken Sie auf Übernehmen.
- Klicken Sie auf Weiter und dann auf Grenzwert.
- Wählen Sie unter Benachrichtigungstrigger die Option Bei jedem Verstoß aus.
- Wählen Sie für Grenzwertposition die Option Über Grenzwert aus.
- Geben Sie für Grenzwert den Wert
86400000ein. - Klicken Sie auf Weiter.
- Wählen Sie unter Benachrichtigungskanäle Ihren E-Mail-Benachrichtigungskanal aus und klicken Sie auf OK.
- Geben Sie einen Namen für die Benachrichtigungsrichtlinie ein.
- Klicken Sie auf Weiter und dann auf Richtlinie erstellen.
Wenn die Leerlaufzeit des TensorCore 24 Stunden überschreitet, wird eine E-Mail an die von Ihnen angegebene E-Mail-Adresse gesendet.
Logging
Logeinträge werden von Google Cloud Diensten, Drittanbieterdiensten, ML-Frameworks oder Ihrem Code geschrieben. Sie können Logs mit dem Log-Explorer oder der Logs API aufrufen. Weitere Informationen zum Google Cloud -Logging finden Sie unter Google Cloud Logging.
TPU-Worker-Logs enthalten Informationen zu einem bestimmten Cloud TPU-Worker in einer bestimmten Zone, z. B. die Menge des auf dem Cloud TPU-Worker verfügbaren Arbeitsspeichers (system_available_memory_GiB).
Logs der geprüften Ressource enthalten Informationen darüber, wann eine bestimmte Cloud TPU-API aufgerufen wurde und wer den Aufruf getätigt hat. Sie können beispielsweise Informationen zu Aufrufen der APIs CreateNode, UpdateNode und DeleteNode abrufen.
ML-Frameworks können Logs in die Standardausgabe und den Standardfehlerkanal schreiben. Diese Logs werden durch Umgebungsvariablen gesteuert und von Ihrem Trainingsskript gelesen.
Ihr Code kann Logs in Google Cloud Logging schreiben. Weitere Informationen finden Sie unter Standardlogs schreiben und Strukturierte Logs schreiben.
Logging des seriellen Ports
Cloud TPU verwendet das Logging für den seriellen Port zur Fehlerbehebung, zum Monitoring und zum Debugging. Standardmäßig ist das Logging des seriellen Ports aktiviert. Wenn das Logging des seriellen Ports nicht aktiviert ist, schlägt die Erstellung der TPU-VM fehl und es wird die folgende Fehlermeldung generiert.
"Cloud TPU received a bad request. Constraint
`constraints/compute.disableSerialPortLogging` violated. Create TPUs with
serial port logging enabled or remove the Organization Policy Constraint."
Diese Meldung weist darauf hin, dass die Einschränkung constraints/compute.disableSerialPortLogging verletzt wurde.
Um diesen Fehler zu vermeiden, müssen Sie dafür sorgen, dass das Logging serieller Ports für Ihre TPU-Projekte zulässig ist. Es empfiehlt sich, die Organisationsrichtlinie auf Projektebene zu überschreiben.
Weitere Informationen zum Aktivieren des Loggings des seriellen Ports finden Sie unter Logging der Ausgabe des seriellen Ports aktivieren und deaktivieren.
Google Cloud -Logs abfragen
Wenn Sie sich Logs in der Google Cloud Console ansehen, wird auf der Seite eine Standardsuchanfrage ausgeführt.
Sie können die Abfrage aufrufen, indem Sie die Ein/Aus-Schaltfläche Show query auswählen. Sie können die Standardanfrage ändern oder eine neue erstellen. Weitere Informationen finden Sie unter Abfragen im Log-Explorer erstellen.
Logs der geprüften Ressource
So rufen Sie Logs von geprüften Ressourcen auf:
- Zum Google Cloud Log-Explorer
- Klicken Sie auf das Drop-down-Menü Alle Ressourcen.
- Klicken Sie auf Geprüfte Ressource und dann auf Cloud TPU.
- Wählen Sie die Cloud TPU API aus, die Sie interessiert.
- Klicken Sie auf Übernehmen. Die Logs werden in den Abfrageergebnissen angezeigt.
Klicken Sie auf einen beliebigen Logeintrag, um ihn zu maximieren. Jeder Logeintrag enthält mehrere Felder, darunter:
- logName: Der Name des Logs.
- protoPayload -> @type: der Typ des Logs
- protoPayload -> resourceName: der Name Ihrer Cloud TPU
- protoPayload -> methodName: der Name der aufgerufenen Methode (nur Audit-Logs)
- protoPayload -> request -> @type: der Anfragetyp
- protoPayload -> request -> node: Details zum Cloud TPU-Knoten
- protoPayload -> request -> node_id: Der Name der TPU
- severity: Der Schweregrad des Logs.
TPU-Worker-Logs
So rufen Sie TPU-Worker-Logs auf:
- Zum Google Cloud Log-Explorer
- Klicken Sie auf das Drop-down-Menü Alle Ressourcen.
- Klicken Sie auf TPU-Worker.
- Wählen Sie eine Zone aus.
- Wählen Sie die gewünschte Cloud TPU aus.
- Klicken Sie auf Übernehmen. Die Logs werden in den Abfrageergebnissen angezeigt.
Klicken Sie auf einen beliebigen Logeintrag, um ihn zu maximieren. Jeder Logeintrag hat ein Feld namens jsonPayload. Maximieren Sie jsonPayload, um mehrere Felder aufzurufen, darunter:
- accelerator_type: der Beschleunigertyp
- consumer_project: Das Projekt, in dem sich die Cloud TPU befindet.
- evententry_timestamp: Der Zeitpunkt, zu dem das Log generiert wurde.
- system_available_memory_GiB: Der verfügbare Speicher auf dem Cloud TPU-Worker (0 bis 350 GiB)
Logbasierte Messwerte erstellen
In diesem Abschnitt wird beschrieben, wie logbasierte Messwerte erstellt werden, die für die Einrichtung von Dashboards und Benachrichtigungen zur Überwachung verwendet werden. Informationen zum programmatischen Erstellen von logbasierten Messwerten finden Sie unter Logbasierte Messwerte programmatisch mit der Cloud Logging REST API erstellen.
Im folgenden Beispiel wird mithilfe des Unterfelds system_available_memory_GiB die Vorgehensweise zum Erstellen eines logbasierten Messwerts zur Überwachung des verfügbaren Speichers von Cloud TPU-Workern veranschaulicht.
- Zum Google Cloud Log-Explorer
Geben Sie im Feld für die Abfrage die folgende Abfrage ein, um alle Logeinträge zu extrahieren, für die system_available_memory_GiB für den primären Cloud TPU-Worker definiert ist:
resource.type=tpu_worker resource.labels.project_id=your-project resource.labels.zone=your-tpu-zone resource.labels.node_id=your-tpu-name resource.labels.worker_id=0 logName=projects/your-project/logs/tpu.googleapis.com%2Fruntime_monitor jsonPayload.system_available_memory_GiB:*
Klicken Sie auf Messwert erstellen, um den Messwerteditor aufzurufen.
Wählen Sie unter Messwerttyp die Option Verteilung aus.
Geben Sie einen Namen, eine optionale Beschreibung und eine Maßeinheit für den Messwert ein. Geben Sie für dieses Beispiel „matrix_unit_utilization_percent“ und „MXU-Auslastung“ in die Felder Name und Beschreibung ein. Der Filter ist bereits mit dem Script ausgefüllt, das Sie im Log-Explorer eingegeben haben.
Klicken Sie auf Messwert erstellen.
Klicken Sie auf Im Metrics Explorer ansehen, um den neuen Messwert aufzurufen. Es kann einige Minuten dauern, bis Ihre Messwerte angezeigt werden.
Logbasierte Messwerte mit der Cloud Logging REST API erstellen
Sie können logbasierte Messwerte auch über die Cloud Logging API erstellen. Weitere Informationen finden Sie unter Verteilungsmesswert erstellen.
Dashboards und Benachrichtigungen mit protokollbasierten Messwerten erstellen
Dashboards eignen sich zur Visualisierung von Messwerten (mit einer Verzögerung von etwa 2 Minuten). Warnungen sind hilfreich, um Benachrichtigungen zu senden, wenn Fehler auftreten. Weitere Informationen finden Sie unter:
- Monitoring- und Logging-Dashboards
- Benutzerdefinierte Dashboards verwalten
- Messwertbasierte Benachrichtigungsrichtlinien erstellen
Dashboards erstellen
So erstellen Sie ein Dashboard in Cloud Monitoring für den Messwert Tensorcore idle duration (Tensorcore-Leerlaufdauer):
- Monitoring-Konsole öffnen
- Klicken Sie im Navigationsbereich auf Dashboards.
- Klicken Sie auf Dashboard erstellen und dann auf Widget hinzufügen.
- Wählen Sie den Diagrammtyp aus, den Sie hinzufügen möchten. Wählen Sie für dieses Beispiel Linie aus.
- Geben Sie einen Titel für das Widget ein.
- Klicken Sie auf das Drop-down-Menü Messwert auswählen und geben Sie „Tensorcore-Leerlaufdauer“ in das Filterfeld ein.
- Wählen Sie in der Liste der Messwerte TPU-Worker -> TPU -> Tensorcore-Leerlaufdauer aus.
- Wenn Sie die Dashboard-Inhalte filtern möchten, klicken Sie auf das Drop-down-Menü Filter.
- Wählen Sie unter Ressourcenlabels die Option project_id aus.
- Wählen Sie einen Vergleichsoperator aus und geben Sie einen Wert in das Feld Wert ein.
- Klicken Sie auf Übernehmen.