Cette page explique comment Cloud TPU fonctionne avec Google Kubernetes Engine (GKE), y compris la terminologie, les avantages des unités de traitement Tensor (TPU) et les considérations liées à la planification des charges de travail. Les TPU sont des circuits intégrés spécifiques aux applications (ASIC) développés spécifiquement par Google pour accélérer les charges de travail de ML qui utilisent des frameworks tels que TensorFlow, PyTorch et JAX.
Cette page s'adresse aux administrateurs et opérateurs de plate-forme, ainsi qu'aux spécialistes des données et de l'IA qui exécutent des modèles de machine learning (ML) présentant des caractéristiques telles que l'évolutivité, la longue durée d'exécution ou la prédominance des calculs matriciels. Pour en savoir plus sur les rôles courants et les exemples de tâches que nous citons dans le contenu Google Cloud, consultez Rôles utilisateur et tâches courantes de GKE.
Avant de lire cette page, assurez-vous de comprendre le fonctionnement des accélérateurs de ML. Pour en savoir plus, consultez la Présentation de Cloud TPU.
Avantages de l'utilisation des TPU dans GKE
GKE fournit une assistance complète pour la gestion du cycle de vie des nœuds TPU et des pools de nœuds, y compris la création, la configuration et la suppression de VM TPU. GKE est également compatible avec les VM Spot et l'utilisation de Cloud TPU réservés. Pour en savoir plus, consultez Options de consommation Cloud TPU.
L'utilisation de TPU dans GKE présente les avantages suivants :
- Environnement opérationnel cohérent : vous pouvez utiliser une plate-forme unique pour toutes les charges de travail et le machine learning.
- Mises à niveau automatiques : GKE automatise les mises à niveau de versions, ce qui réduit les coûts opérationnels.
- Équilibrage de charge : GKE répartit la charge afin de réduire la latence et d'améliorer la fiabilité.
- Scaling réactif : GKE effectue le scaling automatique des ressources TPU pour répondre aux besoins de vos charges de travail.
- Gestion des ressources : avec Kueue, un système de mise en file d'attente de jobs Kubernetes natif, vous pouvez gérer les ressources de plusieurs locataires au sein de votre organisation à l'aide de la mise en file d'attente, de la préemption, de la priorisation et du partage équitable.
- Options de bac à sable : GKE Sandbox vous aide à protéger vos charges de travail avec gVisor. Pour en savoir plus, consultez GKE Sandbox.
Avantages de l'utilisation de TPU Trillium
Trillium est le TPU de sixième génération de Google. Trillium présente les avantages suivants :
- Trillium augmente les performances de calcul par puce par rapport à TPU v5e.
- Trillium augmente la capacité et la bande passante de la mémoire à haut débit (HBM), ainsi que la bande passante de l'interconnexion entre les puces (ICI) par rapport à TPU v5e.
- Trillium est équipé de SparseCore de troisième génération, un accélérateur spécialisé pour le traitement d'intégrations très volumineuses courantes dans les charges de travail de classement et de recommandation avancées.
- Trillium est plus de 67 % plus économe en énergie que TPU v5e.
- Trillium peut évoluer jusqu'à 256 TPU dans une seule tranche de TPU à haut débit et à faible latence.
- Trillium est compatible avec la planification de la collecte. La planification de la collecte vous permet de déclarer un groupe de TPU (pools de nœuds de tranche TPU à hôte unique et multi-hôte) pour garantir une haute disponibilité pour les exigences de vos charges de travail d'inférence.
Sur toutes les surfaces techniques telles que les API et les journaux, ainsi que dans certaines parties de la documentation GKE, nous utilisons v6e ou TPU Trillium (v6e) pour désigner les TPU Trillium. Pour en savoir plus sur les avantages de Trillium, consultez l'article de blog sur l'annonce de Trillium. Pour commencer à configurer vos TPU, consultez Planifier des TPU dans GKE.
Terminologie liée aux TPU dans GKE
Ce document utilise la terminologie suivante liée aux TPU :
- Type de TPU : type de Cloud TPU, tel que v5e
- Nœud de tranche de TPU : nœud Kubernetes représenté par une seule VM disposant d'une ou plusieurs puces TPU interconnectées.
- Pool de nœuds de tranche de TPU : groupe de nœuds Kubernetes au sein d'un cluster qui ont tous la même configuration TPU.
- Topologie de TPU : nombre et disposition physique des puces TPU dans une tranche de TPU.
- Atomique : GKE traite tous les nœuds interconnectés comme une seule unité. Lors des opérations de scaling, GKE met à l'échelle l'intégralité de l'ensemble de nœuds à zéro et crée de nouveaux nœuds. Si une machine du groupe échoue ou s'arrête, GKE recrée l'ensemble des nœuds en tant que nouvelle unité.
- Immuable : vous ne pouvez pas ajouter manuellement de nouveaux nœuds à l'ensemble de nœuds interconnectés. Toutefois, vous pouvez créer un pool de nœuds avec la topologie TPU souhaitée et planifier des charges de travail sur ce pool.
Types de pools de nœuds de tranche de TPU
GKE est compatible avec deux types de pools de nœuds TPU :
Le type et la topologie de TPU déterminent si votre nœud de tranche de TPU peut être multi-hôte ou à hôte unique. Nous vous recommandons les actions suivantes :
- Pour les modèles à grande échelle, utilisez des nœuds de tranche de TPU multi-hôte.
- Pour les modèles à petite échelle, utilisez des nœuds de tranche de TPU à hôte unique.
- Pour l'entraînement ou l'inférence à grande échelle, utilisez Pathways. Pathways simplifie les calculs de machine learning à grande échelle en permettant à un seul client JAX d'orchestrer des charges de travail sur plusieurs grandes tranches de TPU. Pour en savoir plus, consultez Parcours.
Pools de nœuds de tranche de TPU multi-hôtes
Un pool de nœuds de tranche de TPU multi-hôte est un pool de nœuds contenant au moins deux VM TPU interconnectées. Chaque VM est associée à un appareil TPU. Les TPU d'une tranche de TPU multi-hôte sont connectés via une interconnexion à haut débit (ICI). Une fois qu'un pool de nœuds de tranche de TPU multi-hôte est créé, vous ne pouvez plus y ajouter de nœuds. Par exemple, vous ne pouvez pas créer un pool de nœuds v4-32, puis ajouter un nœud Kubernetes (VM TPU) au pool de nœuds. Pour ajouter une tranche de TPU à un cluster GKE, vous devez créer un pool de nœuds.
Les VM d'un pool de nœuds de tranche de TPU de multi-hôte sont traitées comme une seule unité atomique. Si GKE ne parvient pas à déployer un nœud dans la tranche, aucun nœud du nœud de tranche de TPU n'est déployé.
Si un nœud d'une tranche de TPU multi-hôte doit être réparé, GKE arrête toutes les VM de la tranche de TPU, ce qui force l'expulsion de tous les pods Kubernetes de la charge de travail. Une fois que toutes les VM de la tranche de TPU sont opérationnelles, les pods Kubernetes peuvent être planifiés sur les VM de la nouvelle tranche de TPU.
Le schéma suivant illustre une tranche de TPU multi-hôte v5litepod-16 (v5e). Cette tranche de TPU comporte quatre VM. Chaque VM de la tranche de TPU comporte quatre puces TPU v5e connectées par des interconnexions à haut débit (ICI), et chaque puce TPU v5e comporte un TensorCore :
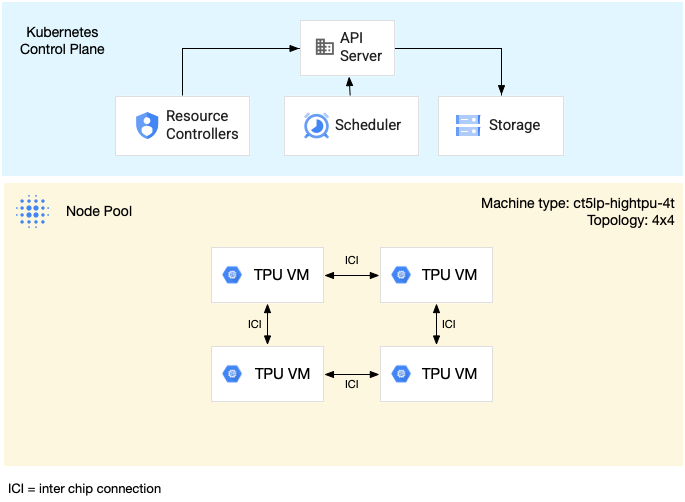
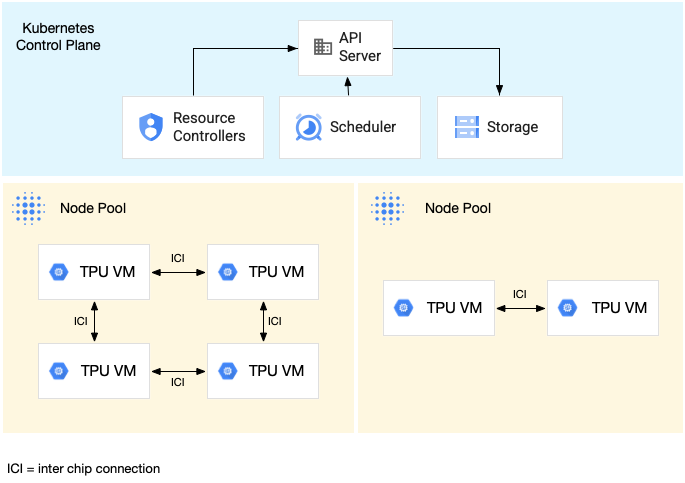
Le schéma suivant montre un cluster GKE contenant une tranche de TPU v5litepod-16 (v5e, topologie : 4x4) et une tranche de TPU v5litepod-8 (v5e, topologie : 2x4) :
Pools de nœuds de tranche de TPU à hôte unique
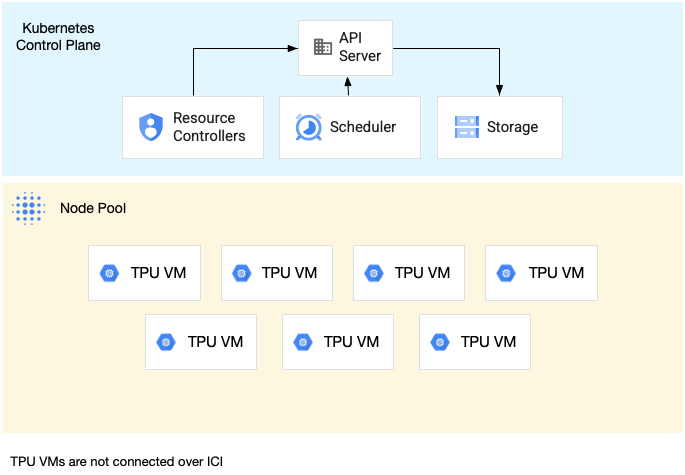
Un pool de nœuds de tranche à hôte unique est un pool de nœuds contenant une ou plusieurs VM TPU indépendantes. Chaque VM est associée à un appareil TPU. Bien que les VM d'un pool de nœuds de tranche à hôte unique puissent communiquer via le réseau de centre de données (DCN), les TPU associés aux VM ne sont pas interconnectés.
Le schéma suivant montre un exemple de tranche de TPU à hôte unique contenant sept machines v4-8 :
Caractéristiques des TPU dans GKE
Les TPU présentent des caractéristiques uniques qui nécessitent une planification et une configuration spécifiques.
Consommation de TPU
Pour optimiser l'utilisation des ressources et les coûts tout en équilibrant les performances de la charge de travail, GKE est compatible avec les options de consommation de TPU suivantes :
- Démarrage flexible : pour sécuriser les ressources pendant sept jours maximum, GKE alloue automatiquement le matériel au mieux en fonction de la disponibilité. Pour en savoir plus, consultez À propos du provisionnement de GPU et de TPU avec le mode de provisionnement à démarrage flexible.
- VM Spot : vous pouvez bénéficier de remises importantes pour provisionner des VM Spot, mais celles-ci peuvent être préemptées à tout moment, avec un avertissement de 30 secondes. Pour en savoir plus, consultez VM Spot.
- Réservation future pour une durée maximale de 90 jours (en mode calendrier) : permet de provisionner des ressources TPU pour une durée maximale de 90 jours, pour une période spécifiée. Pour en savoir plus, consultez Demander des TPU avec une réservation future en mode calendrier.
- Réservations de TPU : pour demander une réservation future d'un an ou plus.
Pour choisir l'option de consommation qui répond aux exigences de votre charge de travail, consultez À propos des options de consommation d'accélérateurs pour les charges de travail d'IA/ML dans GKE.
Avant d'utiliser des TPU dans GKE, choisissez l'option de consommation qui correspond le mieux aux exigences de votre charge de travail.
Topologie
La topologie définit la disposition physique des TPU dans une tranche de pod TPU. GKE provisionne une tranche de TPU dans des topologies à deux ou trois dimensions en fonction de la version du TPU. Vous spécifiez une topologie en tant que nombre de puces TPU dans chaque dimension, comme suit :
Pour un TPU v4 et v5p planifié dans des pools de nœuds TPU à hôtes multiples, vous définissez la topologie à trois tuples ({A}x{B}x{C}), par exemple 4x4x4. Le produit de {A}x{B}x{C} définit le nombre de puces TPU dans le pool de nœuds. Par exemple, vous pouvez définir des topologies de petite taille qui comportent moins de 64 puces TPU avec des formes de topologie telles que 2x2x2, 2x2x4 ou 2x4x4. Si vous utilisez des topologies de plus de 64 puces TPU, les valeurs que vous attribuez à {A}, {B} et {C} doivent répondre aux conditions suivantes :
- {A}, {B} et {C} doivent être des multiples de quatre.
- La topologie la plus grande compatible avec v4 est
12x16x16et avec v5p16x16x24. - Les valeurs attribuées doivent conserver le modèle A ≤ B ≤ C. Par exemple,
4x4x8ou8x8x8.
Type de machine
Les types de machines compatibles avec les ressources TPU suivent une convention d'attribution de noms qui inclut la version de TPU et le nombre de puces par nœud, par exemple ct<version>-hightpu-<node-chip-count>t. Par exemple, le type de machine ct5lp-hightpu-1t est compatible avec les TPU v5e et ne contient qu'une seule puce TPU.
Mode privilégié
Si vous utilisez des versions de GKE antérieures à la version 1.28, vous devez configurer vos conteneurs avec des capacités spéciales pour accéder aux TPU. Dans les clusters en mode standard, vous pouvez utiliser le mode privilégié pour accorder cet accès. Le mode privilégié remplace de nombreux autres paramètres de sécurité dans securityContext. Pour en savoir plus, consultez Exécuter des conteneurs sans mode privilégié.
Les versions 1.28 et ultérieures ne nécessitent pas de mode privilégié ni de capacités spéciales.
Fonctionnement des TPU dans GKE
La gestion et la hiérarchisation des ressources Kubernetes traitent les VM sur les TPU de la même manière que les autres types de VM. Pour demander des puces TPU, utilisez le nom de ressource google.com/tpu :
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
Lorsque vous utilisez des TPU dans GKE, tenez compte des caractéristiques TPU suivantes :
- Une VM peut accéder à huit puces TPU au maximum.
- Une tranche de pod TPU contient un nombre fixe de puces TPU, qui dépend du type de machine TPU que vous choisissez.
- Le nombre de
google.com/tpudemandés doit être égal au nombre total de puces TPU disponibles sur le nœud de tranche de TPU. Tout conteneur d'un pod GKE qui demande des TPU doit consommer toutes les puces TPU du nœud. Sinon, votre déploiement échoue, car GKE ne peut pas consommer partiellement les ressources TPU. Étudions les cas de figure suivants :- Le type de machine
ct5lp-hightpu-4tavec une topologie2x4contient deux nœuds de tranche de TPU avec quatre puces TPU chacun, soit un total de huit puces TPU. Avec ce type de machine, vous pouvez : - Vous ne pouvez pas déployer un pod GKE nécessitant huit puces TPU sur les nœuds de ce pool de nœuds.
- Vous pouvez déployer deux pods nécessitant chacun quatre puces TPU, avec un pod sur chaque nœud de ce pool de nœuds.
- Le TPU v5e avec la topologie 4x4 comporte 16 puces TPU dans quatre nœuds. La charge de travail GKE Autopilot qui sélectionne cette configuration doit demander quatre puces TPU dans chaque réplica, pour un à quatre réplicas.
- Le type de machine
- Dans les clusters Standard, plusieurs pods Kubernetes peuvent être programmés sur une VM, mais un seul conteneur de chaque pod peut accéder aux puces TPU.
- Pour créer des pods kube-system, tels que kube-dns, chaque cluster Standard doit disposer d'au moins un pool de nœuds de tranche non TPU.
- Par défaut, les nœuds de tranche de TPU ont un rejet
google.com/tpuqui empêche la planification des charges de travail non TPU sur les nœuds de tranche de TPU. Les charges de travail qui n'utilisent pas de TPU sont exécutées sur des nœuds non TPU, ce qui libère de la capacité de calcul sur les nœuds de tranche de TPU pour le code qui utilise des TPU. Notez que le rejet ne garantit pas que les ressources TPU sont entièrement utilisées. - GKE collecte les journaux émis par les conteneurs s'exécutant sur des nœuds de tranche de TPU. Pour en savoir plus, consultez Journalisation.
- Les métriques d'utilisation du TPU, telles que les performances d'exécution, sont disponibles dans Cloud Monitoring. Pour en savoir plus, consultez Observabilité et métriques.
- Vous pouvez mettre en bac à sable vos charges de travail TPU avec GKE Sandbox. GKE Sandbox fonctionne avec les modèles TPU v4 et ultérieurs. Pour en savoir plus, consultez GKE Sandbox.
Fonctionnement de la planification de la collecte
Dans TPU Trillium, vous pouvez utiliser la planification de la collecte pour regrouper les nœuds de tranche TPU. Le regroupement de ces nœuds de tranche TPU permet d'ajuster plus facilement le nombre de répliques pour répondre à la demande de charge de travail. Google Cloud contrôle les mises à jour logicielles pour s'assurer que suffisamment de tranches de la collection sont toujours disponibles pour traiter le trafic.
TPU Trillium est compatible avec la planification de la collecte pour les pools de nœuds à hôte unique et multi-hôtes qui exécutent des charges de travail d'inférence. La planification de la collecte dépend du type de tranche TPU que vous utilisez :
- Tranche de TPU multi-hôte : GKE regroupe les tranches de TPU multi-hôtes pour former une collection. Chaque pool de nœuds GKE est une réplique de cette collection. Pour définir une collection, créez une tranche TPU multi-hôte et attribuez-lui un nom unique. Pour ajouter d'autres tranches de TPU à la collection, créez un autre pool de nœuds de tranche TPU multi-hôte avec le même nom de collection et le même type de charge de travail.
- Tranche de TPU à hôte unique : GKE considère l'ensemble du pool de nœuds de tranche de TPU à hôte unique comme une collection. Pour ajouter des tranches de TPU à la collection, vous pouvez redimensionner le pool de nœuds de tranche de TPU à hôte unique.
La programmation des collectes présente les limites suivantes :
- Vous ne pouvez planifier des collections que pour TPU Trillium.
- Vous ne pouvez définir des collections que lors de la création d'un pool de nœuds.
- Les VM Spot ne sont pas compatibles.
- Les collections qui contiennent des pools de nœuds de tranche TPU multi-hôtes doivent utiliser le même type de machine, la même topologie et la même version pour tous les pools de nœuds de la collection.
Vous pouvez configurer la planification de la collecte dans les scénarios suivants :
- Lorsque vous créez un pool de nœuds de tranche TPU dans GKE Standard
- Lors du déploiement de charges de travail sur GKE Autopilot
- Lorsque vous créez un cluster qui active le provisionnement automatique des nœuds
Étapes suivantes
Pour apprendre à configurer Cloud TPU dans GKE, consultez les pages suivantes :
- Planifiez des TPU dans GKE pour commencer à configurer vos TPU.
- Déployez des charges de travail TPU dans GKE Autopilot
- Déployer des charges de travail TPU dans GKE Standard
- Découvrez les bonnes pratiques pour utiliser Cloud TPU pour vos tâches de ML.
- Vidéo : Créer des modèles de machine learning à grande échelle dans Cloud TPU avec GKE
- Diffuser des grands modèles de langage avec KubeRay sur des TPU
- En savoir plus sur la mise en bac à sable des charges de travail GPU avec GKE Sandbox