Questa pagina descrive come funziona Cloud TPU con Google Kubernetes Engine (GKE), inclusi la terminologia, i vantaggi delle Tensor Processing Unit (TPU) e le considerazioni sulla pianificazione dei workload. Le TPU sono circuiti integrati specifici per le applicazioni (ASIC) sviluppati da Google per accelerare i carichi di lavoro di machine learning che utilizzano framework come TensorFlow, PyTorch e JAX.
Questa pagina è dedicata agli amministratori e agli operatori della piattaforma e agli specialisti di dati e AI che eseguono modelli di machine learning (ML) con caratteristiche quali larga scala, lunga durata o dominati da calcoli matriciali. Per scoprire di più sui ruoli comuni e sulle attività di esempio a cui facciamo riferimento nei contenuti, consulta Ruoli e attività comuni degli utenti di GKE Enterprise. Google Cloud
Prima di leggere questa pagina, assicurati di avere familiarità con il funzionamento degli acceleratori ML. Per maggiori dettagli, vedi Introduzione a Cloud TPU.
Vantaggi dell'utilizzo delle TPU in GKE
GKE fornisce il supporto completo per la gestione del ciclo di vita dei nodi TPU e pool di nodi, inclusa la creazione, la configurazione e l'eliminazione delle VM TPU. GKE supporta anche le VM spot e l'utilizzo di Cloud TPU riservate. Per maggiori informazioni, consulta Opzioni di consumo di Cloud TPU. I vantaggi dell'utilizzo delle TPU in GKE includono:
- Ambiente operativo coerente: puoi utilizzare una singola piattaforma per tutto il machine learning e altri carichi di lavoro.
- Upgrade automatici: GKE automatizza gli aggiornamenti delle versioni, il che riduce il sovraccarico operativo.
- Bilanciamento del carico: GKE distribuisce il carico, riducendo così la latenza e migliorando l'affidabilità.
- Scalabilità reattiva: GKE scala automaticamente le risorse TPU per soddisfare le esigenze dei tuoi carichi di lavoro.
- Gestione delle risorse: con Kueue, un sistema di gestione delle code dei job nativo di Kubernetes, puoi gestire le risorse in più tenant all'interno della tua organizzazione utilizzando la gestione delle code, la preemption, la definizione delle priorità e la condivisione equa.
- Opzioni di sandboxing: GKE Sandbox contribuisce a proteggere i tuoi carichi di lavoro con gVisor. Per saperne di più, consulta la pagina GKE Sandbox.
Vantaggi dell'utilizzo di TPU Trillium
Trillium è la TPU di sesta generazione di Google. Trillium offre i seguenti vantaggi:
- Trillium aumenta le prestazioni di calcolo per chip rispetto a TPU v5e.
- Trillium aumenta la capacità e la larghezza di banda della High Bandwidth Memory (HBM) e aumenta anche la larghezza di banda dell'interconnessione interchip (ICI) rispetto alla TPU v5e.
- Trillium è dotato di SparseCore di terza generazione, un acceleratore specializzato per l'elaborazione di incorporamenti di dimensioni molto grandi comuni nei workload di ranking e raccomandazione avanzati.
- Trillium è oltre il 67% più efficiente dal punto di vista energetico rispetto a TPU v5e.
- Trillium può scalare fino a 256 TPU in una singola sezione TPU a bassa latenza e larghezza di banda elevata.
- Trillium supporta la pianificazione della raccolta. La pianificazione della raccolta consente di dichiarare un gruppo di TPU (node pool di slice TPU single-host e multi-host) per garantire l'alta disponibilità per le esigenze dei tuoi workload di inferenza.
In tutte le superfici tecniche come API e log e in parti specifiche della
documentazione di GKE, utilizziamo v6e o TPU Trillium (v6e) per fare riferimento
alle TPU Trillium. Per scoprire di più sui vantaggi di Trillium, leggi il post del blog sull'annuncio di Trillium. Per
iniziare la configurazione delle TPU, consulta Pianificare le TPU in GKE.
Terminologia relativa alle TPU in GKE
Questa pagina utilizza la seguente terminologia relativa alle TPU:
- Tipo di TPU: il tipo di Cloud TPU, ad esempio v5e.
- Nodo di sezione TPU:un nodo Kubernetes rappresentato da una singola VM con uno o più chip TPU interconnessi.
- Pool di nodi di sezioni TPU: un gruppo di nodi Kubernetes all'interno di un cluster che condividono la stessa configurazione TPU.
- Topologia TPU: il numero e la disposizione fisica dei chip TPU in una sezione TPU.
- Atomico: GKE considera tutti i nodi interconnessi come una singola unità. Durante le operazioni di scalabilità, GKE ridimensiona l'intero insieme di nodi a 0 e crea nuovi nodi. Se una macchina nel gruppo non funziona o viene terminata, GKE ricrea l'intero insieme di nodi come nuova unità.
- Immutable: non puoi aggiungere manualmente nuovi nodi all'insieme di nodi interconnessi. Tuttavia, puoi creare un nuovo pool di nodi con la topologia TPU che preferisci e pianificare i carichi di lavoro nel nuovopool di nodil.
Tipi di pool di nodi di sezioni TPU
GKE supporta due tipi di node pool TPU:
Il tipo e la topologia di TPU determinano se il nodo della sezione TPU può essere multi-host o single-host. Ti consigliamo di:
- Per i modelli su larga scala, utilizza i nodi slice TPU multi-host
- Per i modelli su piccola scala, utilizza nodi slice TPU single-host
- Per l'addestramento o l'inferenza su larga scala, utilizza Pathways. Pathways semplifica i calcoli di machine learning su larga scala consentendo a un singolo client JAX di orchestrare i carichi di lavoro su più sezioni di TPU di grandi dimensioni. Per saperne di più, consulta Percorsi.
Node pool TPU multi-host
Un node pool di sezioni TPU multi-host è un pool di nodi che contiene due o più VM TPU interconnesse. A ogni VM è collegato un dispositivo TPU. Le TPU in
una sezione TPU multihost sono connesse tramite un'interconnessione ad alta velocità (ICI). Una volta creato un pool di nodi slice TPU multi-host, non puoi aggiungervi nodi. Ad esempio,
non puoi creare un pool di nodi v4-32 e poi aggiungere un nodo Kubernetes (VM TPU) al pool di nodi. Per aggiungere una slice TPU aggiuntiva a un
cluster GKE, devi creare un nuovo pool di nodi.
Le VM in un pool di nodi di sezioni TPU multi-host vengono trattate come una singola unità atomica. Se GKE non riesce a eseguire il deployment di un nodo nella sezione, non viene eseguito il deployment di alcun nodo nel nodo della sezione TPU.
Se un nodo all'interno di una sezione TPU multihost richiede la riparazione, GKE arresta tutte le VM nella sezione TPU, forzando l'espulsione di tutti i pod Kubernetes nel workload. Dopo che tutte le VM nella sezione TPU sono in esecuzione, i pod Kubernetes possono essere pianificati sulle VM nella nuova sezione TPU.
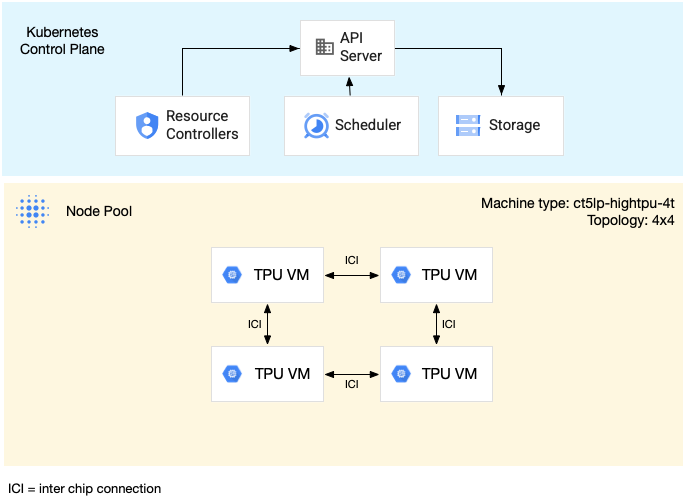
Il seguente diagramma mostra una sezione di TPU multi-host v5litepod-16 (v5e). Questa sezione TPU ha quattro VM. Ogni VM nella sezione TPU ha quattro chip TPU v5e connessi
con interconnessioni ad alta velocità (ICI) e ogni chip TPU v5e ha un TensorCore.
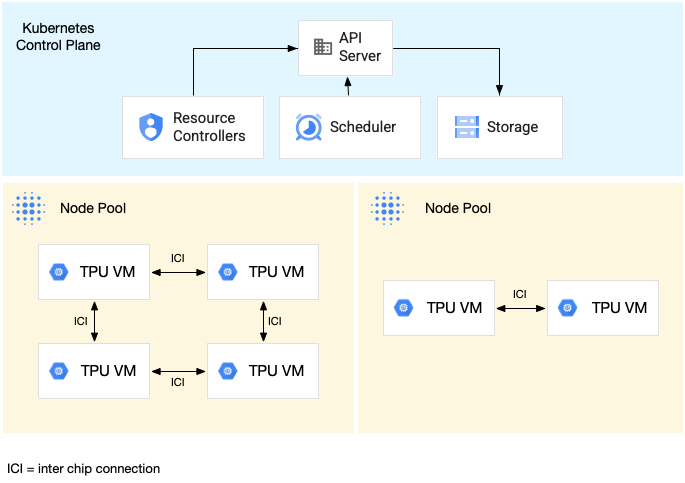
Il seguente diagramma mostra un cluster GKE che contiene una sezione TPU v5litepod-16 (v5e) (topologia: 4x4) e una sezione TPU v5litepod-8 (v5e) (topologia: 2x4):
Pool di nodi di sezioni TPU single-host
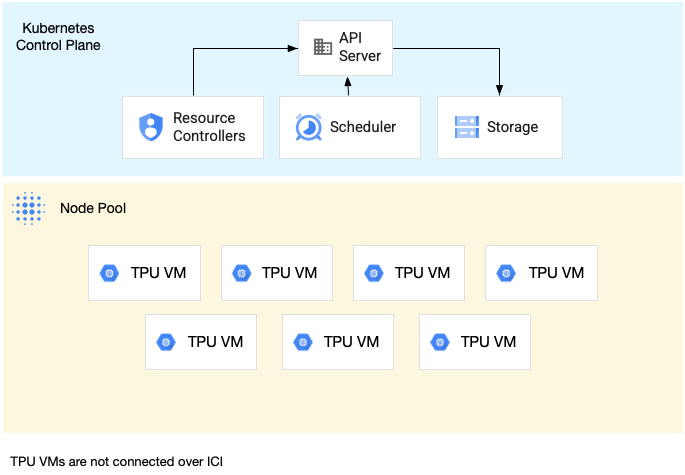
Un pool di nodi single-host slice è un pool di nodi che contiene una o più VM TPU indipendenti. A ogni VM è collegato un dispositivo TPU. Anche se le VM all'interno di un pool di nodi slice a singolo host possono comunicare tramite la rete del data center (DCN), le TPU collegate alle VM non sono interconnesse.
Il seguente diagramma mostra un esempio di slice TPU a un solo host che contiene sette macchine v4-8:
Caratteristiche delle TPU in GKE
Le TPU hanno caratteristiche uniche che richiedono una pianificazione e una configurazione speciali.
Topologia
La topologia definisce la disposizione fisica delle TPU all'interno di una sezione TPU. GKE esegue il provisioning di una sezione TPU in topologie bidimensionali o tridimensionali, a seconda della versione della TPU. Specifichi una topologia come numero di chip TPU in ogni dimensione, nel seguente modo:
Per le TPU v4 e v5p pianificate nei node pool delle sezioni TPU multi-host, definisci la
topologia in tuple di tre elementi ({A}x{B}x{C}), ad esempio 4x4x4. Il prodotto di
{A}x{B}x{C} definisce il numero di chip TPU nel pool di nodi. Ad esempio, puoi definire topologie piccole con meno di 64 chip TPU con forme di topologia come 2x2x2, 2x2x4 o 2x4x4. Se utilizzi topologie più grandi con più di 64 chip TPU, i valori che assegni a {A}, {B} e {C} devono soddisfare le seguenti condizioni:
- {A}, {B} e {C} devono essere multipli di quattro.
- La topologia più grande supportata per v4 è
12x16x16e per v5p è16x16x24. - I valori assegnati devono mantenere il pattern A ≤ B ≤ C. Ad esempio,
4x4x8o8x8x8.
Tipo di macchina
I tipi di macchina che supportano le risorse TPU seguono una convenzione di denominazione che
include la versione di TPU e il numero di chip TPU per sezione di nodi, ad esempio
ct<version>-hightpu-<node-chip-count>t. Ad esempio, il tipo di macchina ct5lp-hightpu-1t supporta TPU v5e e contiene un solo chip TPU.
Modalità con privilegi
Se utilizzi versioni di GKE precedenti alla 1.28, devi configurare
i tuoi container con funzionalità speciali per accedere alle TPU. Nei cluster in modalità Standard, puoi utilizzare la modalità con privilegi per concedere questo accesso. La modalità Con privilegi
ignora molte delle altre impostazioni di sicurezza in securityContext. Per
maggiori dettagli, vedi Esegui container senza modalità privilegiata.
Le versioni 1.28 e successive non richiedono la modalità con privilegi o funzionalità speciali.
Come funzionano le TPU in GKE
La gestione e la definizione delle priorità delle risorse Kubernetes trattano le VM sulle TPU allo stesso modo degli altri tipi di VM. Per richiedere chip TPU, utilizza il nome risorsa google.com/tpu:
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
Quando utilizzi le TPU in GKE, considera le seguenti caratteristiche delle TPU:
- Una VM può accedere a un massimo di 8 chip TPU.
- Una sezione TPU contiene un numero fisso di chip TPU, con il numero che dipende dal tipo di macchina TPU scelto.
- Il numero di
google.com/tpurichiesti deve essere uguale al numero totale di chip TPU disponibili sul nodo della sezione TPU. Qualsiasi container in un pod GKE che richiede TPU deve utilizzare tutti i chip TPU nel nodo. In caso contrario, il deployment non riesce perché GKE non può utilizzare parzialmente le risorse TPU. Considera i seguenti scenari:- Il tipo di macchina
ct5lp-hightpu-4tcon una topologia2x4contiene due nodi di sezioni TPU con quattro chip TPU ciascuno, per un totale di otto chip TPU. Con questo tipo di macchina, puoi:- Non è possibile eseguire il deployment di un pod GKE che richiede otto chip TPU sui nodi di questopool di nodil.
- Può eseguire il deployment di due pod che richiedono quattro chip TPU ciascuno, ogni pod su uno dei due nodi in questo pool di nodi.
- TPU v5e con topologia 4x4 ha 16 chip TPU in quattro nodi. Il carico di lavoro GKE Autopilot che seleziona questa configurazione deve richiedere quattro chip TPU in ogni replica, per un massimo di quattro repliche.
- Il tipo di macchina
- Nei cluster Standard, è possibile pianificare più pod Kubernetes su una VM, ma solo un container in ogni pod può accedere ai chip TPU.
- Per creare pod kube-system, come kube-dns, ogni cluster Standard deve avere almeno unpool di nodil di slice non TPU.
- Per impostazione predefinita, i nodi della sezione TPU hanno l'
google.com/tputaint che impedisce la pianificazione di workload non TPU sui nodi della sezione TPU. I workload che non utilizzano le TPU vengono eseguiti su nodi non TPU, liberando la capacità di calcolo sui nodi delle sezioni TPU per il codice che utilizza le TPU. Tieni presente che la taint non garantisce che le risorse TPU vengano utilizzate completamente. - GKE raccoglie i log emessi dai container in esecuzione sui nodi delle sezioni TPU. Per saperne di più, vedi Logging.
- Le metriche di utilizzo della TPU, come le prestazioni del runtime, sono disponibili in Cloud Monitoring. Per scoprire di più, consulta Osservabilità e metriche.
- Puoi mettere in sandbox i tuoi carichi di lavoro TPU con GKE Sandbox. GKE Sandbox funziona con i modelli TPU v4 e versioni successive. Per saperne di più, consulta Sandbox di GKE.
Come funziona la pianificazione della raccolta
In TPU Trillium, puoi utilizzare la pianificazione della raccolta per raggruppare i nodi delle sezioni TPU. Il raggruppamento di questi nodi slice TPU semplifica la regolazione del numero di repliche per soddisfare la domanda del carico di lavoro. Google Cloud controlla gli aggiornamenti software per garantire che siano sempre disponibili slice sufficienti all'interno della raccolta per gestire il traffico.
TPU Trillium supporta la pianificazione della raccolta per i node pool single-host e multi-host che eseguono carichi di lavoro di inferenza. Di seguito viene descritto come il comportamento di pianificazione della raccolta dipende dal tipo di sezione TPU che utilizzi:
- Sezione TPU multi-host:GKE raggruppa le sezioni TPU multi-host per formare una raccolta. Ogni pool di nodi GKE è una replica all'interno di questa raccolta. Per definire una raccolta, crea uno slice TPU multihost e assegna un nome univoco alla raccolta. Per aggiungere altre sezioni di TPU alla raccolta, crea un altro pool di nodi di sezioni di TPU multi-host con lo stesso nome della raccolta e tipo di carico di lavoro.
- Sezione TPU single-host:GKE considera l'intero pool di nodil della sezione TPU single-host come una raccolta. Per aggiungere altre sezioni TPU alla raccolta, puoi ridimensionare ilpool di nodil di sezioni TPU single-host.
La pianificazione della raccolta presenta le seguenti limitazioni:
- Puoi pianificare le raccolte solo per TPU Trillium.
- Puoi definire le raccolte solo durante la creazione del pool di nodi.
- Le VM spot non sono supportate.
- Le raccolte che contengono node pool di sezioni di TPU multi-host devono utilizzare lo stesso tipo di macchina, la stessa topologia e la stessa versione per tutti i node pool all'interno della raccolta.
Puoi configurare la pianificazione della raccolta nei seguenti scenari:
- Quando crei un pool di nodi di sezioni TPU in GKE Standard
- Quando esegui il deployment dei carichi di lavoro su GKE Autopilot
- Quando crei un cluster che abilita il provisioning automatico dei nodi
Passaggi successivi
Per scoprire come configurare Cloud TPU in GKE, consulta le seguenti pagine:
- Pianifica le TPU in GKE per iniziare la configurazione delle TPU.
- Esegui il deployment dei carichi di lavoro TPU in GKE Autopilot
- Esegui il deployment dei carichi di lavoro TPU in GKE Standard
- Scopri le best practice per l'utilizzo di Cloud TPU per le tue attività di machine learning.
- Video: Build large-scale machine learning on Cloud TPU with GKE.
- Eroga modelli linguistici di grandi dimensioni con KubeRay sulle TPU.
- Scopri di più sul sandboxing dei carichi di lavoro GPU con GKE Sandbox