TPUs in GKE introduction
Google Kubernetes Engine (GKE) customers can now create Kubernetes node pools containing TPU v4 and v5e slices. For more information about TPUs, see System Architecture.
When you work with GKE you first have to create a GKE cluster. You then add node pools to your cluster. GKE node pools are collections of VMs that share the same attributes. For TPU workloads, node pools consist of TPU VMs.
Node pool types
GKE supports two types of TPU node pools:
Multi-host TPU slice node pool
A multi-host TPU slice node pool is a node pool that contains two or more
interconnected TPU VMs. Each VM has a TPU device connected to it. The TPUs in
a multi-host slice are connected over a high speed interconnect (ICI). Once a
multi-host slice node pool is created, you cannot add nodes to it. For example,
you cannot create a v4-32 node pool and then later add an additional Kubernetes
node (TPU VM) to the node pool. To add an additional TPU slice to a
GKE cluster, you must create a new node pool.
The hosts in a multi-host TPU slice node pool are treated as a single atomic unit. If GKE is unable to deploy one node in the slice, no nodes in the slice will be deployed.
If a node within a multi-host TPU slice needs to be repaired, GKE will shutdown all TPU VMs in the slice, forcing all Kubernetes Pods in the workload to be evicted. Once all TPU VMs in the slice are up and running, the Kubernetes Pods can be scheduled on the TPU VMs in the new slice.
The following diagram shows an example of a v5litepod-16 (v5e) multi-host TPU slice. This slice has four TPU VMs. Each TPU VM has four TPU v5e chips connected with high-speed interconnects (ICI), and each TPU v5e chip has one TensorCore.
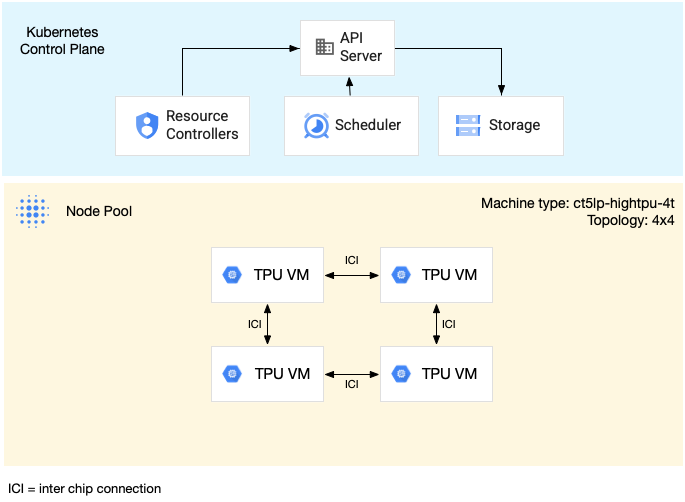
The following diagram shows a GKE cluster containing one
TPU v5litepod-16 (v5e) slice (topology: 4x4) and one TPU v5litepod-8 (v5e)
slice (topology: 2x4):
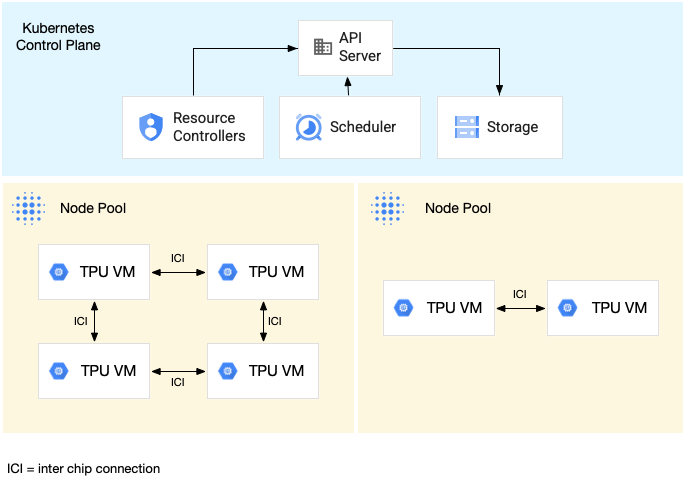
For an example of running a workload on a multi-host TPU slice, see Run your workload on TPUs.
Single-host TPU slice node pools
A single-host slice node pool is a node pool that contains one or more independent TPU VMs. Each VM has a TPU device connected to it. While the VMs within a single-host slice node pool can communicate over the Data Center Network (DCN), the TPUs attached to the VMs are not interconnected.
The following diagram shows an example of a single-host TPU slice with seven
v4-8 machines:
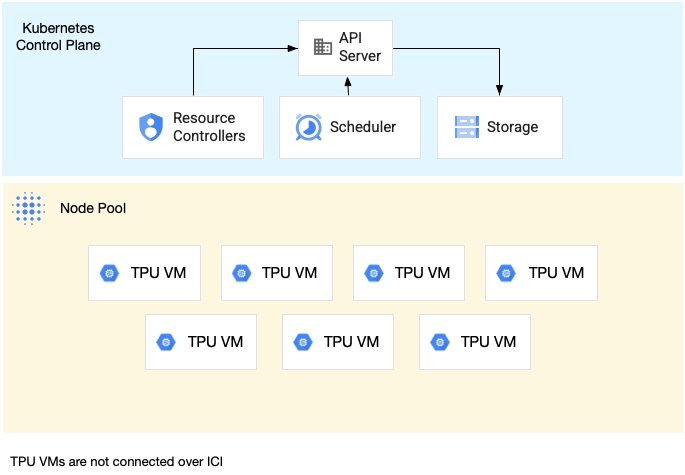
For an example of running a workload on a single-host TPU slice, see Run your workload on TPUs.
TPU machine types for GKE node pools
Before creating node pools, you need to choose the TPU version and size of the
TPU slice your workload requires. TPU v4 is supported in GKE
Standard version 1.26.1-gke.1500 and later, v5e in GKE
Standard version 1.27.2-gke.2100 and later, and v5p in
GKE Standard version 1.28.3-gke.1024000 and later.
TPU v4, v5e and v5p are supported in GKE Autopilot
version 1.29.2-gke.1521000 and later.
For more information about the hardware specifications of the different TPU versions, see System architecture. When creating a TPU node pool, select a TPU slice size (a TPU topology) based on the size of your model and how much memory it requires. The machine type you specify when creating your node pools depends on the version and size of your slices.
v5e
The following are the TPU v5e machine types and topologies that are supported for training and inference use cases:
| Machine Type | Topology | Number of TPU chips | Number of VMs | Recommended use case |
|---|---|---|---|---|
ct5lp-hightpu-1t |
1x1 | 1 | 1 | Training, single-host inference |
ct5lp-hightpu-4t |
2x2 | 4 | 1 | Training, single-host inference |
ct5lp-hightpu-8t |
2x4 | 8 | 1 | Training, single-host inference |
ct5lp-hightpu-4t |
2x4 | 8 | 2 | Training, multi-host inference |
ct5lp-hightpu-4t |
4x4 | 16 | 4 | Large-scale training, multi-host inference |
ct5lp-hightpu-4t |
4x8 | 32 | 8 | Large-scale training, multi-host inference |
ct5lp-hightpu-4t |
8x8 | 64 | 16 | Large-scale training, multi-host inference |
ct5lp-hightpu-4t |
8x16 | 128 | 32 | Large-scale training, multi-host inference |
ct5lp-hightpu-4t |
16x16 | 256 | 64 | Large-scale training, multi-host inference |
Cloud TPU v5e is a combined training and inference product. Training jobs are optimized for throughput and availability while inference jobs are optimized for latency. For more information see v5e Training accelerator types and v5e Inference accelerator types.
TPU v5e machines are available in us-west4-a, us-east5-b and us-east1-c.
GKE Standard clusters must run control plane
version 1.27.2-gke.2100 or later. GKE Autopilot
must run control plane version 1.29.2-gke.1521000 or later. For more information
about v5e, see Cloud TPU v5e training.
Machine type comparison:
| Machine Type | ct5lp-hightpu-1t | ct5lp-hightpu-4t | ct5lp-hightpu-8t |
|---|---|---|---|
| Number of v5e chips | 1 | 4 | 8 |
| Number of vCPUs | 24 | 112 | 224 |
| RAM (GB) | 48 | 192 | 384 |
| Number of NUMA nodes | 1 | 1 | 2 |
| Likelihood of preemption | High | Medium | Low |
To make space for VMs with more chips, the GKE scheduler may preempt and reschedule VMs with fewer chips. So 8-chip VMs are more likely to preempt 1 and 4-chip VMs.
v4 and v5p
The following are the TPU v4 and v5p machine types:
| Machine type | Number of vCPUs | Memory (GB) | Number of NUMA nodes |
|---|---|---|---|
ct4p-hightpu-4t |
240 | 407 | 2 |
ct5p-hightpu-4t |
208 | 448 | 2 |
When creating a TPU v4 slice, use the ct4p-hightpu-4t machine type which has
one host and contains 4 chips. See v4 topologies
and TPU system architecture for more
information. TPU v4 slice machines types are available in us-central2-b. Your
GKE Standard clusters must run control plane
version 1.26.1-gke.1500 or later. GKE Autopilot
clusters must run control plane version 1.29.2-gke.1521000 or later.
When creating a TPU v5p slice, use the ct5p-hightpu-4t machine type which has
one host and contains 4 chips. TPU v5p slice machine types are available in
us-west4-a and us-east5-a. GKE Standard
clusters must run control plane version 1.28.3-gke.1024000 or later.
GKE Autopilot must run 1.29.2-gke.1521000 or
later. For more information about v5p, see v5p training introduction.
Known issues and limitations
- Maximum number of Kubernetes Pods: You can run a maximum of 256 Kubernetes Pods in a single TPU VM.
- SPECIFIC reservations only: When using TPUs in GKE,
SPECIFICis the only supported value for the--reservation-affinityflag of thegcloud container node-pools createcommand. - Only the Spot VMs variant of preemptible TPUs are supported: Spot VMs are similar to preemptible VMs and are subject to the same availability limitations, but don't have a 24h maximum duration.
- No cost allocation support: GKE cost allocation and usage metering don't include any data about the usage or costs of TPUs.
- Autoscaler may calculate capacity: Cluster autoscaler might calculate capacity incorrectly for new nodes containing TPU VMs before those nodes are available. Cluster autoscaler might then perform additional scale up and as a result create more nodes than needed. Cluster autoscaler will scale down additional nodes, if they are not needed, after regular scale down operation.
- Autoscaler cancels scale up: Cluster autoscaler cancels scaling up of TPU node pools that remain in waiting status for more than 10 hours. Cluster Autoscaler will retry such scale up operations later. This behavior might reduce TPU obtainability for customers who don't use reservations.
- Taint may prevent scale down: Non-TPU workloads that have a toleration for the TPU taint may prevent scale down of the node pool if they are recreated during draining of the TPU node pool.
Ensure sufficient TPU and GKE quotas
You may need to increase certain GKE-related quotas in the regions where your resources are created.
The following quotas have default values that will likely need to be increased:
- Persistent Disk SSD (GB) quota: The boot disk of each Kubernetes node requires 100GB by default. Therefore, this quota should be set at least as high as (the maximum number of GKE nodes you anticipate creating) * 100GB.
- In-use IP addresses quota: Each Kubernetes node consumes one IP address. Therefore, this quota should be set at least as high as the maximum number of GKE nodes you anticipate creating.
To request an increase in quota, see Request higher quota. For more information about the types of TPU quotas, see TPU Quota.
It may take a few days for your quota increase requests to be approved. If you experience any difficulty getting your quota increase requests approved within a few days, contact your Google Account team.
Migrate your TPU reservation
If you don't plan to use an existing TPU reservation with TPUs in GKE, skip this section and go to Create a Google Kubernetes Engine cluster.
In order to use reserved TPUs with GKE, you must first migrate your TPU reservation to a new Compute Engine-based reservation system.
There are several important things to know about this migration:
- TPU capacity migrated to the new Compute Engine-based reservation system cannot be used with the Cloud TPU Queued Resource API. If you intend to use TPU queued resources with your reservation, then you will need to migrate a portion of your TPU reservation to the new Compute Engine-based reservation system.
- No workloads can be actively running on TPUs when they are migrated to the new Compute Engine-based reservation system.
- Select a time to perform the migration, and work with your Google Cloud account team to schedule the migration. The migration time window needs to be during business hours (Monday - Friday, 9am-5pm Pacific Time).
Create a Google Kubernetes Engine cluster
See Create a cluster in the Google Kubernetes Engine documentation.
Create a TPU node pool
See Create a node pool in the Google Kubernetes Engine documentation.
Running without privileged mode
If you want to reduce the permission scope on your container see TPU privilege mode.
Run workloads in TPU node pools
See Run your GKE workloads on TPUs in the Google Kubernetes Engine documentation.
Node selectors
In order for Kubernetes to schedule your workload on nodes containing TPU VMs, you must specify two selectors for each workload in your Google Kubernetes Engine manifest:
- Set
cloud.google.com/gke-accelerator-typetotpu-v5-lite-podslice,tpu-v5p-sliceortpu-v4-podslice. - Set
cloud.google.com/gke-tpu-topologyto the TPU topology of the node.
The Training workloads and Inference workloads sections contain example manifests that illustrate using these node selectors.
Workload scheduling considerations
TPUs have unique characteristics that require special workload scheduling and management in Kubernetes. For more information, see Workload scheduling considerations in the GKE documentation.
Node repair
If a node in a multi-host TPU slice node pool is unhealthy, GKE recreates the entire node pool. For more information, see Node auto repair in the GKE documentation.
Multislice - going beyond a single slice
You can aggregate smaller slices together in a multislice to handle larger training workloads. For more information, see Cloud TPU Multislice.
Training workload tutorials
These tutorials focus on training workloads on a multi-host TPU slice (for example, 4 v5e machines). They cover the following models:
- Hugging Face FLAX Models: Train Diffusion on Pokémon
- PyTorch/XLA: GPT2 on WikiText
Download tutorial resources
Download the tutorial Python scripts and YAML specs for each pre-trained model with the following command:
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.git
Create & connect to cluster
Create a regional GKE cluster, so the Kubernetes
control plane is replicated in three zones, providing higher availability.
Create your cluster in us-west4, us-east1 or us-central2 depending upon which
TPU version you are using. For more information about TPUs and zones, see
Cloud TPU regions and zones.
The following command creates a new GKE regional cluster subscribed to the rapid release channel with a node pool that initially contains one node per zone. The command also enables Workload Identity Federation for GKE and Cloud Storage FUSE CSI driver features on your cluster because the example inference workloads in this guide use Cloud Storage buckets to store pre-trained models.
gcloud container clusters create cluster-name \ --region your-region \ --release-channel rapid \ --num-nodes=1 \ --workload-pool=project-id.svc.id.goog \ --addons GcsFuseCsiDriver
To enable Workload Identity Federation for GKE and Cloud Storage FUSE CSI driver features for existing clusters, run the following command:
gcloud container clusters update cluster-name \ --region your-region \ --update-addons GcsFuseCsiDriver=ENABLED \ --workload-pool=project-id.svc.id.goog
The example workloads are configured with the following assumptions:
- the node pool is using
tpu-topology=4x4with four nodes - the node pool is using
machine-typect5lp-hightpu-4t
Run the following command to connect to your newly created cluster:
gcloud container clusters get-credentials cluster-name \ --location=cluster-region
Hugging Face FLAX Models: Train Diffusion on Pokémon
This example trains the Stable Diffusion model from HuggingFace using the Pokémon dataset.
The Stable Diffusion model is a latent text-to-image model that generates photo-realistic images from any text input. For more information about Stable Diffusion, see:
Create Docker image
The Dockerfile is located under the folder
ai-on-gke/tutorials-and-examples/tpu-examples/training/diffusion/.
Before running the following command, ensure that your account has the proper permissions for Docker to push to the repository.
Build and push the Docker image:
cd ai-on-gke/tutorials-and-examples/tpu-examples/training/diffusion/ docker build -t gcr.io/project-id/diffusion:latest . docker push gcr.io/project-id/diffusion:latest
Deploy workload
Create a file with the following content and name it tpu_job_diffusion.yaml.
Fill in the image field with the image that you just created.
apiVersion: v1
kind: Service
metadata:
name: headless-svc
spec:
clusterIP: None
selector:
job-name: tpu-job-diffusion
---
apiVersion: batch/v1
kind: Job
metadata:
name: tpu-job-diffusion
spec:
backoffLimit: 0
# Completions and parallelism should be the number of chips divided by 4.
# (e.g. 4 for a v5litepod-16)
completions: 4
parallelism: 4
completionMode: Indexed
template:
spec:
subdomain: headless-svc
restartPolicy: Never
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice
cloud.google.com/gke-tpu-topology: 4x4
containers:
- name: tpu-job-diffusion
image: gcr.io/${project-id}/diffusion:latest
ports:
- containerPort: 8471 # Default port using which TPU VMs communicate
- containerPort: 8431 # Port to export TPU usage metrics, if supported
command:
- bash
- -c
- |
cd examples/text_to_image
python3 train_text_to_image_flax.py --pretrained_model_name_or_path=duongna/stable-diffusion-v1-4-flax --dataset_name=lambdalabs/pokemon-blip-captions --resolution=128 --center_crop --random_flip --train_batch_size=4 --mixed_precision=fp16 --max_train_steps=1500 --learning_rate=1e-05 --max_grad_norm=1 --output_dir=sd-pokemon-model
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
Then deploy it using:
kubectl apply -f tpu_job_diffusion.yaml
Clean-up
After your Job finishes running you can delete it using:
kubectl delete -f tpu_job_diffusion.yaml
PyTorch/XLA: GPT2 on WikiText
This tutorial shows how to run GPT2 on v5e TPUs using HuggingFace on PyTorch/XLA using the wikitext dataset.
Create Docker image
The Dockerfile is located under the folder ai-on-gke/tutorials-and-examples/tpu-examples/training/gpt/.
Before running the following command, ensure that your account has the proper permissions for Docker to push to the repository.
Build and push the Docker image:
cd ai-on-gke/tutorials-and-examples/tpu-examples/training/gpt/ docker build -t gcr.io/project-id/gpt:latest . docker push gcr.io/project-id/gpt:latest
Deploy workload
Copy the following YAML and save it in a file called tpu_job_gpt.yaml. Fill in
the image field with the image that you just created.
apiVersion: v1
kind: Service
metadata:
name: headless-svc
spec:
clusterIP: None
selector:
job-name: tpu-job-gpt
---
apiVersion: batch/v1
kind: Job
metadata:
name: tpu-job-gpt
spec:
backoffLimit: 0
# Completions and parallelism should be the number of chips divided by 4.
# (for example, 4 for a v5litepod-16)
completions: 4
parallelism: 4
completionMode: Indexed
template:
spec:
subdomain: headless-svc
restartPolicy: Never
volumes:
# Increase size of tmpfs /dev/shm to avoid OOM.
- name: shm
emptyDir:
medium: Memory
# consider adding `sizeLimit: XGi` depending on needs
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice
cloud.google.com/gke-tpu-topology: 4x4
containers:
- name: tpu-job-gpt
image: gcr.io/$(project-id)/gpt:latest
ports:
- containerPort: 8479
- containerPort: 8478
- containerPort: 8477
- containerPort: 8476
- containerPort: 8431 # Port to export TPU usage metrics, if supported.
env:
- name: PJRT_DEVICE
value: 'TPU'
- name: XLA_USE_BF16
value: '1'
command:
- bash
- -c
- |
numactl --cpunodebind=0 python3 -u examples/pytorch/xla_spawn.py --num_cores 4 examples/pytorch/language-modeling/run_clm.py --num_train_epochs 3 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --per_device_train_batch_size 16 --per_device_eval_batch_size 16 --do_train --do_eval --output_dir /tmp/test-clm --overwrite_output_dir --config_name my_config_2.json --cache_dir /tmp --tokenizer_name gpt2 --block_size 1024 --optim adafactor --adafactor true --save_strategy no --logging_strategy no --fsdp "full_shard" --fsdp_config fsdp_config.json
volumeMounts:
- mountPath: /dev/shm
name: shm
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
Deploy the workflow using:
kubectl apply -f tpu_job_gpt.yaml
Clean-up
After your job finishes running you can delete it using:
kubectl delete -f tpu_job_gpt.yaml
Tutorial: Single-Host inference workloads
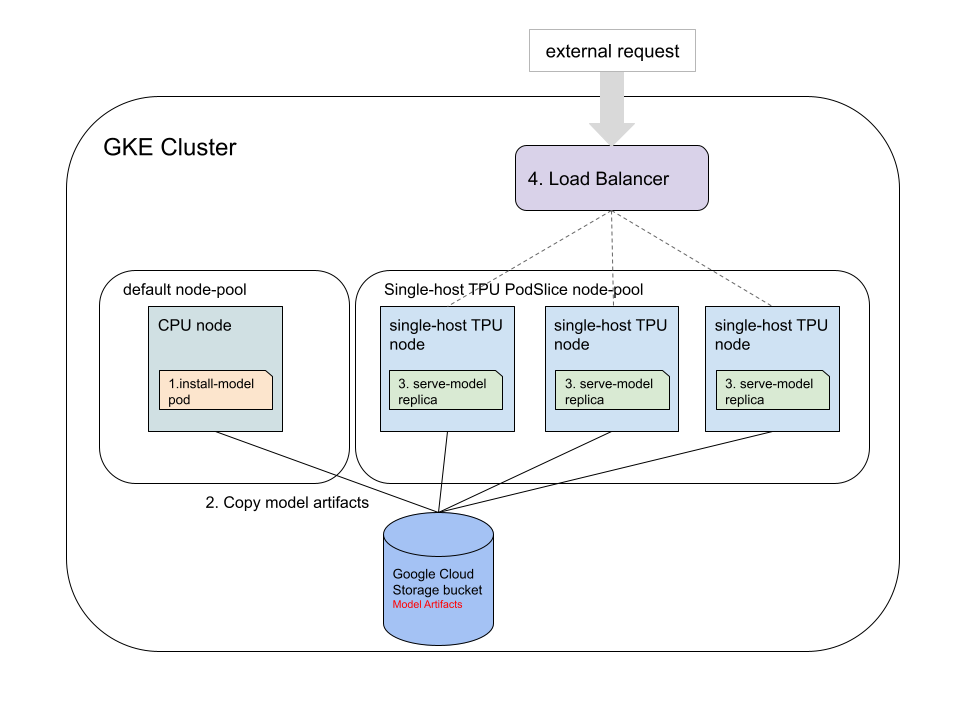
This tutorial shows how to run a single-host inference workload on GKE v5e TPUs for pre-trained models with JAX, TensorFlow, and PyTorch. At a high level, there are four separate steps to perform on the GKE cluster:
Create a Cloud Storage bucket and set up access to the bucket. You use a Cloud Storage bucket is used to store the pre-trained model.
Download and convert a pre-trained model into a TPU-compatible model. Apply a Kubernetes Pod that downloads the pre-trained model, uses the Cloud TPU Converter and stores the converted models into a Cloud Storage bucket using the Cloud Storage FUSE CSI driver. The Cloud TPU Converter doesn't require specialized hardware. This tutorial shows you how to download the model and run the Cloud TPU Converter in the CPU node pool.
Launch the server for the converted model. Apply a Deployment that serves the model using a server framework backed by the volume stored in the ReadOnlyMany (ROX) Persistent Volume. The deployment replicas must be run in a v5e slice node pool with one Kubernetes Pod per node.
Deploy a load balancer to test the model server. The server is exposed to external requests using the LoadBalancer Service. A Python script has been provided with an example request to test out the model server.
The following diagram shows how requests are routed by the Load Balancer.
Server deployment examples
These example workloads are configured with the following assumptions:
- The cluster is running with a TPU v5 node pool with 3 nodes
- The node pool is using machine type
ct5lp-hightpu-1twhere:- topology is 1x1
- number of TPU chips is 1
The following GKE manifest defines a single host server Deployment.
apiVersion: apps/v1
kind: Deployment
metadata:
name: bert-deployment
spec:
selector:
matchLabels:
app: tf-bert-server
replicas: 3 # number of nodes in node pool
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
labels:
app: tf-bert-server
spec:
nodeSelector:
cloud.google.com/gke-tpu-topology: 1x1 # target topology
cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice # target version
containers:
- name: serve-bert
image: us-docker.pkg.dev/cloud-tpu-images/inference/tf-serving-tpu:2.13.0
env:
- name: MODEL_NAME
value: "bert"
volumeMounts:
- mountPath: "/models/"
name: bert-external-storage
ports:
- containerPort: 8500
- containerPort: 8501
- containerPort: 8431 # Port to export TPU usage metrics, if supported.
resources:
requests:
google.com/tpu: 1 # TPU chip request
limits:
google.com/tpu: 1 # TPU chip request
volumes:
- name: bert-external-storage
persistentVolumeClaim:
claimName: external-storage-pvc
If you are using a different number of nodes in your TPU node pool, change the
replicas field to the number of nodes.
If your Standard cluster runs GKE version 1.27 or earlier, add the following field to your manifest:
spec:
securityContext:
privileged: true
You don't need to run Kubernetes Pods in Privileged mode in GKE version 1.28 or later. For details, see Run containers without privileged mode.
If you are using a different machine type:
- Set
cloud.google.com/gke-tpu-topologyto the topology for the machine type you are using. - Set both
google.com/tpufields underresourcesto match the number of chips for the corresponding machine type.
Setup
Download the tutorial Python scripts and YAML manifests using the following command:
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.git
Go to the single-host-inference directory:
cd ai-on-gke/gke-tpu-examples/single-host-inference/
Set up Python environment
The Python scripts you use in this tutorial require Python version 3.9 or greater.
Remember to install the requirements.txt for each tutorial before running the
Python test scripts.
If you don't have the proper Python setup in your local environment, you can use Cloud Shell to download and run the Python scripts in this tutorial.
Set up the cluster
Create a cluster using the
e2-standard-4machine type.gcloud container clusters create cluster-name \ --region your-region \ --release-channel rapid \ --num-nodes=1 \ --machine-type=e2-standard-4 \ --workload-pool=project-id.svc.id.goog \ --addons GcsFuseCsiDriver
The example workloads assume the following:
- Your cluster is running with a TPU v5e node pool with 3 nodes.
- TPU node pool is using machine-type
ct5lp-hightpu-1t.
If you are using a different cluster configuration than previously described, you will need to edit server deployment manifest.
For the JAX Stable Diffusion demo, you will need a CPU node pool with a
machine type that has 16 Gi+ available memory (for example e2-standard-4).
This is configured in the gcloud container clusters create command or by
adding an additional node pool to the existing cluster with the following
command:
gcloud beta container node-pools create your-pool-name \ --zone=your-cluster-zone \ --cluster=your-cluster-name \ --machine-type=e2-standard-4 \ --num-nodes=1
Replace the following:
your-pool-name: The name of the node pool to create.your-cluster-zone: The zone in which your cluster was created.your-cluster-name: The name of the cluster in which to add the node pool.your-machine-type: The machine type of the nodes to create in your node pool.
Set up model storage
There are several ways you can store your model for serving. In this tutorial, we will use the following approach:
- For converting the pre-trained model to work on TPUs, we will use a
Virtual Private Cloud backed by Persistent Disk with
ReadWriteMany(RWX) access. - For serving the model on multiple single-host TPUs, we will use the same VPC backed by the Cloud Storage bucket.
Run the following command to create a Cloud Storage bucket.
gcloud storage buckets create gs://your-bucket-name \ --project=your-bucket-project-id \ --location=your-bucket-location
Replace the following:
your-bucket-name: The name of the Cloud Storage bucket.your-bucket-project-id: The project ID in which you created the Cloud Storage bucket.your-bucket-location: The location of your Cloud Storage bucket. To improve performance, specify the location where your GKE cluster is running.
Use the following steps to give your GKE cluster access to the bucket. To simplify the setup, the following examples use the default namespace and the default Kubernetes service account. For details, see Configure access to Cloud Storage buckets using GKE Workload Identity Federation for GKE.
Create an IAM service account for your application or use an existing IAM service account instead. You can use any IAM service account in your Cloud Storage bucket's project.
gcloud iam service-accounts create your-iam-service-acct \ --project=your-bucket-project-id
Replace the following:
your-iam-service-acct: the name of the new IAM service account.your-bucket-project-id: the ID of the project in which you created your IAM service account. The IAM service account must be in the same project as your Cloud Storage bucket.
Ensure that your IAM service account has the storage roles you need.
gcloud storage buckets add-iam-policy-binding gs://your-bucket-name \ --member "serviceAccount:your-iam-service-acct@your-bucket-project-id.iam.gserviceaccount.com" \ --role "roles/storage.objectAdmin"
Replace the following:
your-bucket-name: The name of your Cloud Storage bucket.your-iam-service-acct: the name of the new IAM service account.your-bucket-project-id: the ID of the project in which you created your IAM service account.
Allow the Kubernetes service account to impersonate the IAM service account by adding an IAM policy binding between the two service accounts. This binding allows the Kubernetes service account to act as the IAM service account.
gcloud iam service-accounts add-iam-policy-binding your-iam-service-acct@your-bucket-project-id.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:your-project-id.svc.id.goog[default/default]"
Replace the following:
your-iam-service-acct: the name of the new IAM service account.your-bucket-project-id: the ID of the project in which you created your IAM service account.your-project-id: the ID of the project in which you created your GKE cluster. Your Cloud Storage buckets and GKE cluster can be in the same or different projects.
Annotate the Kubernetes service account with the email address of the IAM service account.
kubectl annotate serviceaccount default \ --namespace default \ iam.gke.io/gcp-service-account=your-iam-service-acct@your-bucket-project-id.iam.gserviceaccount.com
Replace the following:
your-iam-service-acct: the name of the new IAM service account.your-bucket-project-id: the ID of the project in which you created your IAM service account.
Run the following command to populate your bucket name in the YAML files of this demo:
find . -type f -name "*.yaml" | xargs sed -i "s/BUCKET_NAME/your-bucket-name/g"
Replace
your-bucket-namewith the name of your Cloud Storage bucket.Create the Persistent Volume and Persistent Volume Claim with the following command:
kubectl apply -f pvc-pv.yaml
JAX Model inference and serving
Install Python dependencies for running tutorial Python scripts that send requests to the JAX model service.
pip install -r jax/requirements.txt
Run JAX BERT E2E serving demo:
This demo uses a pre trained BERT model from Hugging Face.
The Kubernetes Pod performs the following steps:
- Downloads and uses the Python script
export_bert_model.pyfrom the example resources to download the pre-trained bert model to a temporary directory. - Uses the Cloud TPU Converter image to convert the pre-trained model from CPU to TPU and stores the model in the Cloud Storage bucket you created during setup.
This Kubernetes Pod is configured to run on the default node pool CPU. Run the Pod with the following command:
kubectl apply -f jax/bert/install-bert.yaml
Verify the model was installed correctly with the following:
kubectl get pods install-bert
It can take a couple of minutes for the STATUS to read Completed.
Launch the TF model server for the model
The example workloads in this tutorial assume the following:
- The cluster is running with a TPU v5 node pool with three nodes
- The node pool is using the
ct5lp-hightpu-1tmachine type that contains one TPU chip.
If you are using a different cluster configuration than previously described, you will need to edit server deployment manifest.
Apply deployment
kubectl apply -f jax/bert/serve-bert.yaml
Verify the server is running with the following:
kubectl get deployment bert-deployment
It can take a minute for AVAILABLE to read 3.
Apply load balancer service
kubectl apply -f jax/bert/loadbalancer.yaml
Verify that the load balancer is ready for external traffic with the following:
kubectl get svc tf-bert-service
It may take a few minutes for EXTERNAL_IP to have an IP listed.
Send the request to the model server
Get external IP from load balancer service:
EXTERNAL_IP=$(kubectl get services tf-bert-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
Run a script for sending a request to the server:
python3 jax/bert/bert_request.py $EXTERNAL_IP
Expected output:
For input "The capital of France is [MASK].", the result is ". the capital of france is paris.."
For input "Hello my name [MASK] Jhon, how can I [MASK] you?", the result is ". hello my name is jhon, how can i help you?."
Clean-up
To clean up resources, run kubectl delete in reverse order.
kubectl delete -f jax/bert/loadbalancer.yaml kubectl delete -f jax/bert/serve-bert.yaml kubectl delete -f jax/bert/install-bert.yaml
Run JAX Stable Diffusion E2E serving demo
This demo uses the pretrained Stable Diffusion model from Hugging Face.
Export TPU-compatible TF2 saved model from Flax Stable Diffusion model
Exporting the stable diffusion models requires that the cluster has a CPU node pool with a machine type that has 16Gi+ available memory as described in Setup cluster.
The Kubernetes Pod executes the following steps:
- Downloads and uses the Python script
export_stable_diffusion_model.pyfrom the example resources to download the pre-trained stable diffusion model to a temporary directory. - Uses the Cloud TPU Converter image to convert the pre-trained model from CPU to TPU and stores the model in the Cloud Storage bucket you created during storage setup.
This Kubernetes Pod is configured to run on the default CPU node pool. Run the Pod with the following command:
kubectl apply -f jax/stable-diffusion/install-stable-diffusion.yaml
Verify the model was installed correctly with the following:
kubectl get pods install-stable-diffusion
It can take a couple of minutes for the STATUS to read Completed.
Launch the TF model server container for the model
The example workloads have been configured with the following assumptions:
- the cluster is running with a TPU v5 node pool with three nodes
- the node pool is using the
ct5lp-hightpu-1tmachine type where:- topology is 1x1
- number of TPU chips is 1
If you are using a different cluster configuration than previously described, you will need to edit server deployment manifest.
Apply the deployment:
kubectl apply -f jax/stable-diffusion/serve-stable-diffusion.yaml
Verify the server is running as expected:
kubectl get deployment stable-diffusion-deployment
It can take a minute for AVAILABLE to read 3.
Apply load balancer service:
kubectl apply -f jax/stable-diffusion/loadbalancer.yaml
Verify that the load balancer is ready for external traffic with the following:
kubectl get svc tf-stable-diffusion-service
It may take a few minutes for EXTERNAL_IP to have an IP listed.
Send the request to the model server
Get an external IP from the load balancer:
EXTERNAL_IP=$(kubectl get services tf-stable-diffusion-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
Run script for sending a request to the server
python3 jax/stable-diffusion/stable_diffusion_request.py $EXTERNAL_IP
Expected output:
The prompt is Painting of a squirrel skating in New York and the output image
will be saved as stable_diffusion_images.jpg in your current directory.
Clean-up
To clean up resources, run kubectl delete in reverse order.
kubectl delete -f jax/stable-diffusion/loadbalancer.yaml kubectl delete -f jax/stable-diffusion/serve-stable-diffusion.yaml kubectl delete -f jax/stable-diffusion/install-stable-diffusion.yaml
Run TensorFlow ResNet-50 E2E serving demo:
Install Python dependencies for running tutorial Python scripts that send requests to the TF model service.
pip install -r tf/resnet50/requirements.txt
Step 1: Convert the model
Apply model conversion:
kubectl apply -f tf/resnet50/model-conversion.yml
Verify the model was installed correctly with the following:
kubectl get pods resnet-model-conversion
It can take a couple of minutes for the STATUS to read Completed.
Step 2: Serve the model with TensorFlow serving
Apply model serving deployment:
kubectl apply -f tf/resnet50/deployment.yml
Verify the server is running as expected with the following command:
kubectl get deployment resnet-deployment
It can take a minute for AVAILABLE to read 3.
Apply load balancer service:
kubectl apply -f tf/resnet50/loadbalancer.yml
Verify that the load balancer is ready for external traffic with the following:
kubectl get svc resnet-service
It may take a few minutes for EXTERNAL_IP to have an IP listed.
Step 3: Send test request to model server
Get the external IP from the load balancer:
EXTERNAL_IP=$(kubectl get services resnet-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
Run the test request (HTTP) script to send request to model server.
python3 tf/resnet50/request.py --host $EXTERNAL_IP
The response should look like the following:
Predict result: ['ImageNet ID: n07753592, Label: banana, Confidence: 0.94921875', 'ImageNet ID: n03532672, Label: hook, Confidence: 0.0223388672', 'ImageNet ID: n07749582, Label: lemon, Confidence: 0.00512695312
Step 4: Clean up
To clean up resources, run the following kubectl delete commands:
kubectl delete -f tf/resnet50/loadbalancer.yml kubectl delete -f tf/resnet50/deployment.yml kubectl delete -f tf/resnet50/model-conversion.yml
Make sure you delete the GKE node pool and cluster when you are done with them.
PyTorch model inference and serving
Install Python dependencies for running tutorial Python scripts that send requests to the PyTorch model service:
pip install -r pt/densenet161/requirements.txt
Run TorchServe Densenet161 E2E serving demo:
Generate model archive.
- Apply model archive:
kubectl apply -f pt/densenet161/model-archive.yml
- Verify the model was installed correctly with the following:
kubectl get pods densenet161-model-archive
It can take a couple of minutes for the
STATUSto readCompleted.Serve the Model with TorchServe:
Apply Model Serving Deployment:
kubectl apply -f pt/densenet161/deployment.yml
Verify the server is running as expected with the following command:
kubectl get deployment densenet161-deployment
It can take a minute for
AVAILABLEto read3.Apply load balancer service:
kubectl apply -f pt/densenet161/loadbalancer.yml
Verify that the load balancer is ready for external traffic with the following command:
kubectl get svc densenet161-service
It may take a few minutes for
EXTERNAL_IPto have an IP listed.
Send test request to model server:
Get external IP from load balancer:
EXTERNAL_IP=$(kubectl get services densenet161-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
Run the test request script to send request (HTTP) to model server.:
python3 pt/densenet161/request.py --host $EXTERNAL_IP
You should see a response like this:
Request successful. Response: {'tabby': 0.47878125309944153, 'lynx': 0.20393909513950348, 'tiger_cat': 0.16572578251361847, 'tiger': 0.061157409101724625, 'Egyptian_cat': 0.04997897148132324
Clean up resources, by running the following
kubectl deletecommands:kubectl delete -f pt/densenet161/loadbalancer.yml kubectl delete -f pt/densenet161/deployment.yml kubectl delete -f pt/densenet161/model-archive.yml
Make sure you delete the GKE node pool and cluster when you are done with them.
Troubleshooting common issues
You can find GKE troubleshooting information at Troubleshoot TPU inGKE.
TPU initialization failed
If you encounter the following error, make sure you are either running your TPU
container in privileged mode or you have increased the ulimit inside your
container. For more information, see Running without privileged mode.
TPU platform initialization failed: FAILED_PRECONDITION: Couldn't mmap: Resource
temporarily unavailable.; Unable to create Node RegisterInterface for node 0,
config: device_path: "/dev/accel0" mode: KERNEL debug_data_directory: ""
dump_anomalies_only: true crash_in_debug_dump: false allow_core_dump: true;
could not create driver instance
Scheduling deadlock
Suppose you have two jobs (Job A and Job B) and both are to be scheduled on TPU
slices with a given TPU topology (say, v4-32). Also suppose that you have
two v4-32 TPU slices within the GKE cluster; we'll
call those slice X and slice Y. Since your cluster has ample capacity to
schedule both jobs, in theory both jobs should be quickly scheduled – one job on
each of the two TPU v4-32 slices.
However, without careful planning, it is possible to get into a scheduling deadlock. Suppose the Kubernetes scheduler schedules one Kubernetes Pod from Job A on slice X and then schedules one Kubernetes Pod from Job B on slice X. In this case, given the Kubernetes Pod affinity rules for Job A, the scheduler will attempt to schedule all remaining Kubernetes Pods for Job A on slice X. Same for Job B. And thus neither Job A nor Job B will be able to be fully scheduled on a single slice. The result will be a scheduling deadlock.
In order to avoid the risk of a scheduling deadlock, you can use Kubernetes Pod
anti-affinity with cloud.google.com/gke-nodepool as the topologyKey as shown
in the following example:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
parallelism: 2
template:
metadata:
labels:
job: pi
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: job
operator: In
values:
- pi
topologyKey: cloud.google.com/gke-nodepool
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: job
operator: NotIn
values:
- pi
topologyKey: cloud.google.com/gke-nodepool
namespaceSelector:
matchExpressions:
- key: kubernetes.io/metadata.name
operator: NotIn
values:
- kube-system
containers:
- name: pi
image: perl:5.34.0
command: ["sleep", "60"]
restartPolicy: Never
backoffLimit: 4
Creating TPU node pool resources with Terraform
You can also use Terraform to manage your cluster and node pool resources.
Create a multi-host TPU slice node pool in an existing GKE Cluster
If you have an existing Cluster in which you want to create a multi-host TPU node pool, you can use the following Terraform snippet:
resource "google_container_cluster" "cluster_multi_host" {
…
release_channel {
channel = "RAPID"
}
workload_identity_config {
workload_pool = "my-gke-project.svc.id.goog"
}
addons_config {
gcs_fuse_csi_driver_config {
enabled = true
}
}
}
resource "google_container_node_pool" "multi_host_tpu" {
provider = google-beta
project = "${project-id}"
name = "${node-pool-name}"
location = "${location}"
node_locations = ["${node-locations}"]
cluster = google_container_cluster.cluster_multi_host.name
initial_node_count = 2
node_config {
machine_type = "ct4p-hightpu-4t"
reservation_affinity {
consume_reservation_type = "SPECIFIC_RESERVATION"
key = "compute.googleapis.com/reservation-name"
values = ["${reservation-name}"]
}
workload_metadata_config {
mode = "GKE_METADATA"
}
}
placement_policy {
type = "COMPACT"
tpu_topology = "2x2x2"
}
}
Replace the following values:
your-project: Your Google Cloud project in which you are running your workload.your-node-pool: The name of the node pool you are creating.us-central2: The region in which you are running your workload.us-central2-b: The zone in which you are running your workload.your-reservation-name: The name of your reservation.
Create a single-host TPU slice node pool in an existing GKE Cluster
Use the following Terraform snippet:
resource "google_container_cluster" "cluster_single_host" {
…
cluster_autoscaling {
autoscaling_profile = "OPTIMIZE_UTILIZATION"
}
release_channel {
channel = "RAPID"
}
workload_identity_config {
workload_pool = "${project-id}.svc.id.goog"
}
addons_config {
gcs_fuse_csi_driver_config {
enabled = true
}
}
}
resource "google_container_node_pool" "single_host_tpu" {
provider = google-beta
project = "${project-id}"
name = "${node-pool-name}"
location = "${location}"
node_locations = ["${node-locations}"]
cluster = google_container_cluster.cluster_single_host.name
initial_node_count = 0
autoscaling {
total_min_node_count = 2
total_max_node_count = 22
location_policy = "ANY"
}
node_config {
machine_type = "ct4p-hightpu-4t"
workload_metadata_config {
mode = "GKE_METADATA"
}
}
}
Replace the following values:
your-project: Your Google Cloud project in which you are running your workload.your-node-pool: The name of the node pool you are creating.us-central2: The region in which you are running your workload.us-central2-b: The zone in which you are running your workload.