Pengantar TPU di GKE
Pelanggan Google Kubernetes Engine (GKE) kini dapat membuat node pool Kubernetes yang berisi slice TPU v4 dan v5e. Untuk informasi selengkapnya tentang TPU, lihat Arsitektur Sistem.
Saat menggunakan GKE, Anda harus membuat cluster GKE terlebih dahulu. Kemudian, Anda menambahkan kumpulan node ke cluster. Node pool GKE adalah kumpulan VM yang memiliki atribut yang sama. Untuk workload TPU, node pool terdiri dari VM TPU.
Jenis node pool
GKE mendukung dua jenis node pool TPU:
Node pool slice TPU multi-host
Node pool slice TPU multi-host adalah node pool yang berisi dua atau beberapa VM TPU yang saling terhubung. Setiap VM memiliki perangkat TPU yang terhubung. TPU dalam
slice multi-host terhubung melalui interkoneksi berkecepatan tinggi (ICI). Setelah node pool slice multi-host dibuat, Anda tidak dapat menambahkan node ke node pool tersebut. Misalnya,
Anda tidak dapat membuat node pool v4-32, lalu menambahkan node Kubernetes tambahan (VM TPU) ke node pool. Untuk menambahkan slice TPU tambahan ke cluster GKE, Anda harus membuat node pool baru.
Host dalam node pool slice TPU multi-host diperlakukan sebagai satu unit atomik. Jika GKE tidak dapat men-deploy satu node dalam slice, tidak ada node dalam slice yang akan di-deploy.
Jika node dalam slice TPU multi-host perlu diperbaiki, GKE akan menonaktifkan semua VM TPU dalam slice, sehingga memaksa semua Pod Kubernetes dalam beban kerja dihapus. Setelah semua VM TPU dalam slice aktif dan berjalan, Pod Kubernetes dapat dijadwalkan di VM TPU dalam slice baru.
Diagram berikut menunjukkan contoh slice TPU multi-host v5litepod-16 (v5e). Slice ini memiliki empat VM TPU. Setiap VM TPU memiliki empat chip TPU v5e yang terhubung dengan interkoneksi berkecepatan tinggi (ICI), dan setiap chip TPU v5e memiliki satu TensorCore.
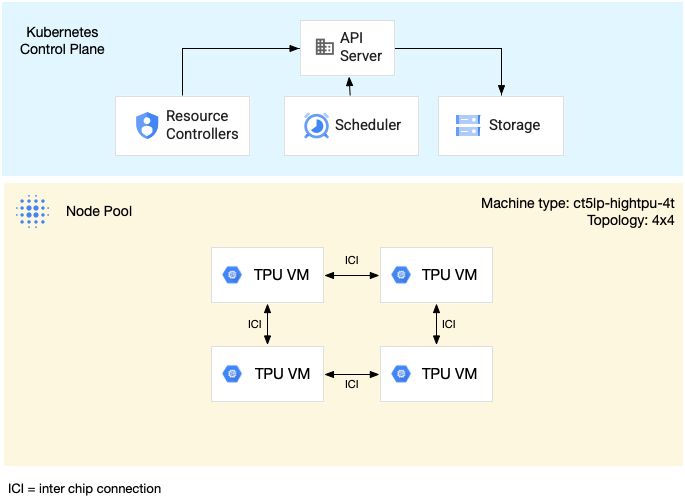
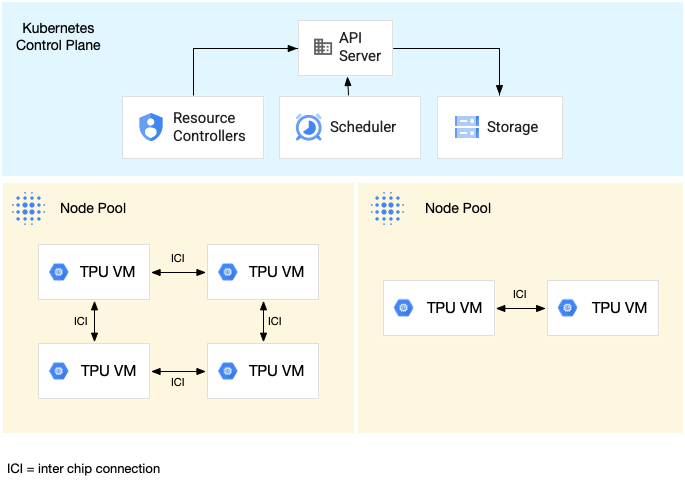
Diagram berikut menunjukkan cluster GKE yang berisi satu
slice TPU v5litepod-16 (v5e) (topologi: 4x4) dan satu slice TPU v5litepod-8 (v5e)
(topologi: 2x4):
Untuk contoh menjalankan beban kerja pada slice TPU multi-host, lihat Menjalankan beban kerja di TPU.
Node pool slice TPU host tunggal
Node pool slice host tunggal adalah node pool yang berisi satu atau beberapa VM TPU independen. Setiap VM memiliki perangkat TPU yang terhubung. Meskipun VM dalam node pool slice host tunggal dapat berkomunikasi melalui Jaringan Data Center (DCN), TPU yang terpasang ke VM tidak saling terhubung.
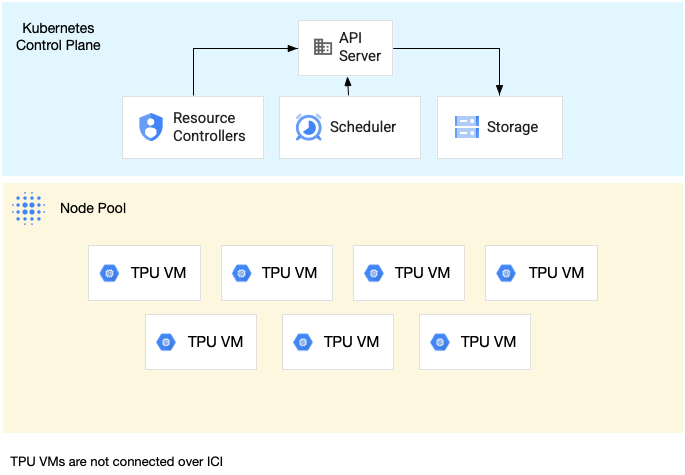
Diagram berikut menunjukkan contoh slice TPU satu host dengan tujuh
mesin v4-8:
Untuk contoh menjalankan workload pada slice TPU host tunggal, lihat Menjalankan workload di TPU.
Jenis mesin TPU untuk node pool GKE
Sebelum membuat node pool, Anda harus memilih versi TPU dan ukuran
slice TPU yang diperlukan oleh workload Anda. TPU v4 didukung di GKE
Standard versi 1.26.1-gke.1500 dan yang lebih baru, v5e di GKE
Standard versi 1.27.2-gke.2100 dan yang lebih baru, serta v5p di
GKE Standard versi 1.28.3-gke.1024000 dan yang lebih baru.
TPU v4, v5e, dan v5p didukung di GKE Autopilot
versi 1.29.2-gke.1521000 dan yang lebih baru.
Untuk informasi selengkapnya tentang spesifikasi hardware dari berbagai versi TPU, lihat Arsitektur sistem. Saat membuat node pool TPU, pilih ukuran slice TPU (topologi TPU) berdasarkan ukuran model dan jumlah memori yang diperlukan. Jenis mesin yang Anda tentukan saat membuat node pool bergantung pada versi dan ukuran slice Anda.
v5e
Berikut adalah jenis mesin dan topologi TPU v5e yang didukung untuk kasus penggunaan pelatihan dan inferensi:
| Machine Type | Topologi | Jumlah TPU chip | Jumlah VM | Kasus penggunaan yang direkomendasikan |
|---|---|---|---|---|
ct5lp-hightpu-1t |
1x1 | 1 | 1 | Pelatihan, inferensi satu host |
ct5lp-hightpu-4t |
2x2 | 4 | 1 | Pelatihan, inferensi satu host |
ct5lp-hightpu-8t |
2x4 | 8 | 1 | Pelatihan, inferensi satu host |
ct5lp-hightpu-4t |
2x4 | 8 | 2 | Pelatihan, inferensi multi-host |
ct5lp-hightpu-4t |
4x4 | 16 | 4 | Pelatihan berskala besar, inferensi multi-host |
ct5lp-hightpu-4t |
4x8 | 32 | 8 | Pelatihan berskala besar, inferensi multi-host |
ct5lp-hightpu-4t |
8x8 | 64 | 16 | Pelatihan berskala besar, inferensi multi-host |
ct5lp-hightpu-4t |
8x16 | 128 | 32 | Pelatihan berskala besar, inferensi multi-host |
ct5lp-hightpu-4t |
16x16 | 256 | 64 | Pelatihan berskala besar, inferensi multi-host |
Cloud TPU v5e adalah produk gabungan pelatihan dan inferensi. Tugas pelatihan dioptimalkan untuk throughput dan ketersediaan, sedangkan tugas inferensi dioptimalkan untuk latensi. Untuk informasi selengkapnya, lihat Jenis akselerator Pelatihan v5e dan Jenis akselerator Inferensi v5e.
Mesin TPU v5e tersedia di us-west4-a, us-east5-b, dan us-east1-c.
Cluster GKE Standard harus menjalankan kontrol
versi 1.27.2-gke.2100 atau yang lebih baru. GKE Autopilot
harus menjalankan control plane versi 1.29.2-gke.1521000 atau yang lebih baru. Untuk mengetahui informasi selengkapnya tentang v5e, lihat Pelatihan Cloud TPU v5e.
Perbandingan jenis mesin:
| Machine Type | ct5lp-hightpu-1t | ct5lp-hightpu-4t | ct5lp-hightpu-8t |
|---|---|---|---|
| Jumlah chip v5e | 1 | 4 | 8 |
| Jumlah vCPU | 24 | 112 | 224 |
| RAM (GB) | 48 | 192 | 384 |
| Jumlah node NUMA | 1 | 1 | 2 |
| Kemungkinan preemption | Tinggi | Sedang | Rendah |
Untuk menyediakan ruang bagi VM dengan lebih banyak chip, penjadwal GKE dapat mengambil alih dan menjadwalkan ulang VM dengan lebih sedikit chip. Jadi, VM 8 chip lebih cenderung mengambil alih VM 1 dan 4 chip.
v4 dan v5p
Berikut adalah jenis mesin TPU v4 dan v5p:
| Jenis mesin | Jumlah vCPU | Memori (GB) | Jumlah node NUMA |
|---|---|---|---|
ct4p-hightpu-4t |
240 | 407 | 2 |
ct5p-hightpu-4t |
208 | 448 | 2 |
Saat membuat slice TPU v4, gunakan jenis mesin ct4p-hightpu-4t yang memiliki satu host dan berisi 4 chip. Lihat topologi v4
dan arsitektur sistem TPU untuk mengetahui informasi
selengkapnya. Jenis mesin slice TPU v4 tersedia di us-central2-b. Cluster GKE Standard Anda harus menjalankan control plane versi 1.26.1-gke.1500 atau yang lebih baru. Cluster GKE Autopilot
harus menjalankan control plane versi 1.29.2-gke.1521000 atau yang lebih baru.
Saat membuat slice TPU v5p, gunakan jenis mesin ct5p-hightpu-4t yang memiliki satu host dan berisi 4 chip. Jenis mesin slice TPU v5p tersedia di
us-west4-a dan us-east5-a. Cluster GKE Standard
harus menjalankan control plane versi 1.28.3-gke.1024000 atau yang lebih baru.
GKE Autopilot harus menjalankan 1.29.2-gke.1521000 atau yang lebih baru. Untuk informasi selengkapnya tentang v5p, lihat pengantar pelatihan v5p.
Masalah umum dan batasan
- Jumlah maksimum Pod Kubernetes: Anda dapat menjalankan maksimum 256 Pod Kubernetes dalam satu VM TPU.
- Khusus pemesanan: Saat menggunakan TPU di GKE,
SPECIFICadalah satu-satunya nilai yang didukung untuk flag--reservation-affinityperintahgcloud container node-pools create. - Hanya varian Spot VM dari TPU preemptible yang didukung: Spot VM mirip dengan preemptible VM dan tunduk pada batasan ketersediaan yang sama, tetapi tidak memiliki durasi maksimum 24 jam.
- Tidak ada dukungan alokasi biaya: Alokasi biaya GKE dan pengukuran penggunaan tidak menyertakan data apa pun terkait penggunaan atau biaya TPU.
- Autoscaler dapat menghitung kapasitas: Autoscaler cluster mungkin salah menghitung kapasitas untuk node baru yang berisi VM TPU sebelum node tersebut tersedia. Autoscaler cluster kemudian dapat melakukan peningkatan skala tambahan dan sebagai hasilnya membuat lebih banyak node daripada yang diperlukan. Autoscaler cluster akan memperkecil skala node tambahan, jika tidak diperlukan, setelah operasi pengecilan skala reguler.
- Autoscaler membatalkan peningkatan skala: Autoscaler cluster membatalkan peningkatan skala TPU node pool yang masih dalam status menunggu selama lebih dari 10 jam. Autoscaler Cluster akan mencoba kembali operasi peningkatan skala tersebut nanti. Perilaku ini dapat mengurangi ketersediaan TPU bagi pelanggan yang tidak menggunakan pemesanan.
- Taint dapat mencegah pengecilan skala: Workload non-TPU yang memiliki toleransi terhadap taint TPU dapat mencegah pengecilan skala node pool jika workload tersebut dibuat ulang selama proses pengosongan TPU node pool.
Memastikan kuota TPU dan GKE yang memadai
Anda mungkin perlu meningkatkan kuota terkait GKE tertentu di region tempat resource dibuat.
Kuota berikut memiliki nilai default yang kemungkinan perlu ditingkatkan:
- Kuota SSD Persistent Disk (GB): Disk booting setiap node Kubernetes memerlukan 100 GB secara default. Oleh karena itu, kuota ini harus ditetapkan setidaknya sebesar (jumlah maksimum node GKE yang Anda perkirakan akan dibuat) * 100 GB.
- Kuota alamat IP yang digunakan: Setiap node Kubernetes menggunakan satu alamat IP. Oleh karena itu, kuota ini harus ditetapkan setidaknya setinggi jumlah maksimum node GKE yang Anda perkirakan akan dibuat.
Untuk meminta penambahan kuota, lihat Meminta kuota yang lebih tinggi. Untuk mengetahui informasi selengkapnya tentang jenis kuota TPU, lihat Kuota TPU.
Mungkin perlu waktu beberapa hari hingga permintaan penambahan kuota Anda disetujui. Jika Anda mengalami kesulitan untuk mendapatkan persetujuan permintaan penambahan kuota dalam beberapa hari, hubungi tim Akun Google Anda.
Memigrasikan pemesanan TPU
Jika Anda tidak berencana menggunakan reservasi TPU yang ada dengan TPU di GKE, lewati bagian ini dan buka Membuat cluster Google Kubernetes Engine.
Untuk menggunakan TPU yang direservasi dengan GKE, Anda harus memigrasikan pemesanan TPU terlebih dahulu ke sistem pemesanan berbasis Compute Engine yang baru.
Ada beberapa hal penting yang perlu diketahui tentang migrasi ini:
- Kapasitas TPU yang dimigrasikan ke sistem pemesanan berbasis Compute Engine yang baru tidak dapat digunakan dengan Queued Resource API Cloud TPU. Jika ingin menggunakan resource dalam antrean TPU dengan pemesanan, Anda harus memigrasikan sebagian pemesanan TPU ke sistem pemesanan berbasis Compute Engine yang baru.
- Tidak ada workload yang dapat berjalan secara aktif di TPU saat dimigrasikan ke sistem pemesanan berbasis Compute Engine yang baru.
- Pilih waktu untuk melakukan migrasi, dan bekerja sama dengan tim akun Google Cloud Anda untuk menjadwalkan migrasi. Periode waktu migrasi harus selama jam kerja (Senin - Jumat, pukul 09.00-17.00 Waktu Pasifik).
Membuat cluster Google Kubernetes Engine
Lihat Membuat cluster di dokumentasi Google Kubernetes Engine.
Membuat node pool TPU
Lihat Membuat kumpulan node dalam dokumentasi Google Kubernetes Engine.
Berjalan tanpa mode dengan hak istimewa
Jika Anda ingin mengurangi cakupan izin di penampung, lihat mode hak istimewa TPU.
Menjalankan workload di TPU node pool
Lihat Menjalankan beban kerja GKE di TPU dalam dokumentasi Google Kubernetes Engine.
Pemilih node
Agar Kubernetes dapat menjadwalkan beban kerja Anda di node yang berisi VM TPU, Anda harus menentukan dua pemilih untuk setiap beban kerja dalam manifes Google Kubernetes Engine:
- Tetapkan
cloud.google.com/gke-accelerator-typeketpu-v5-lite-podslice,tpu-v5p-slice, atautpu-v4-podslice. - Tetapkan
cloud.google.com/gke-tpu-topologyke topologi TPU node.
Bagian Workload pelatihan dan Workload inferensi berisi contoh manifes yang menggambarkan penggunaan pemilih node ini.
Pertimbangan penjadwalan workload
TPU memiliki karakteristik unik yang memerlukan penjadwalan dan pengelolaan beban kerja khusus di Kubernetes. Untuk mengetahui informasi selengkapnya, lihat Pertimbangan penjadwalan workload dalam dokumentasi GKE.
Perbaikan node
Jika node dalam node pool slice TPU multi-host tidak responsif, GKE akan membuat ulang seluruh node pool. Untuk informasi selengkapnya, lihat Perbaikan otomatis node dalam dokumentasi GKE.
Multislice - melampaui satu slice
Anda dapat menggabungkan slice yang lebih kecil dalam multislice untuk menangani workload pelatihan yang lebih besar. Untuk mengetahui informasi selengkapnya, lihat Multislice Cloud TPU.
Tutorial beban kerja pelatihan
Tutorial ini berfokus pada pelatihan beban kerja di slice TPU multi-host (misalnya, 4 mesin v5e). Model tersebut mencakup model berikut:
- Model Hugging Face FLAX: Melatih Difusi di Pokémon
- PyTorch/XLA: GPT2 di WikiText
Mendownload resource tutorial
Download skrip Python tutorial dan spesifikasi YAML untuk setiap model terlatih dengan perintah berikut:
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.git
Membuat & terhubung ke cluster
Buat cluster GKE regional, sehingga panel kontrol Kubernetes direplikasi di tiga zona, sehingga memberikan ketersediaan yang lebih tinggi.
Buat cluster di us-west4, us-east1, atau us-central2, bergantung pada versi TPU yang Anda gunakan. Untuk mengetahui informasi selengkapnya tentang TPU dan zona, lihat
Region dan zona Cloud TPU.
Perintah berikut membuat cluster regional GKE baru yang berlangganan saluran rilis cepat dengan kumpulan node yang awalnya berisi satu node per zona. Perintah ini juga mengaktifkan Workload Identity Federation untuk fitur driver CSI Cloud Storage FUSE dan GKE di cluster Anda karena contoh workload inferensi dalam panduan ini menggunakan bucket Cloud Storage untuk menyimpan model terlatih.
gcloud container clusters create cluster-name \ --region your-region \ --release-channel rapid \ --num-nodes=1 \ --workload-pool=project-id.svc.id.goog \ --addons GcsFuseCsiDriver
Untuk mengaktifkan fitur Workload Identity Federation untuk GKE dan driver CSI Cloud Storage FUSE untuk cluster yang ada, jalankan perintah berikut:
gcloud container clusters update cluster-name \ --region your-region \ --update-addons GcsFuseCsiDriver=ENABLED \ --workload-pool=project-id.svc.id.goog
Contoh beban kerja dikonfigurasi dengan asumsi berikut:
- node pool menggunakan
tpu-topology=4x4dengan empat node - kumpulan node menggunakan
machine-typect5lp-hightpu-4t
Jalankan perintah berikut untuk terhubung ke cluster yang baru dibuat:
gcloud container clusters get-credentials cluster-name \ --location=cluster-region
Model Hugging Face FLAX: Melatih Difusi di Pokémon
Contoh ini melatih model Stable Diffusion dari HuggingFace menggunakan set data Pokémon.
Model Stable Diffusion adalah model teks ke gambar laten yang menghasilkan gambar fotorealistik dari input teks apa pun. Untuk mengetahui informasi selengkapnya tentang Difusi Stabil, lihat:
Membuat image Docker
Dockerfile terletak di folder
ai-on-gke/tutorials-and-examples/tpu-examples/training/diffusion/.
Sebelum menjalankan perintah berikut, pastikan akun Anda memiliki izin yang sesuai agar Docker dapat melakukan push ke repositori.
Build dan kirim image Docker:
cd ai-on-gke/tutorials-and-examples/tpu-examples/training/diffusion/ docker build -t gcr.io/project-id/diffusion:latest . docker push gcr.io/project-id/diffusion:latest
Men-deploy workload
Buat file dengan konten berikut dan beri nama tpu_job_diffusion.yaml.
Isi kolom gambar dengan gambar yang baru saja Anda buat.
apiVersion: v1
kind: Service
metadata:
name: headless-svc
spec:
clusterIP: None
selector:
job-name: tpu-job-diffusion
---
apiVersion: batch/v1
kind: Job
metadata:
name: tpu-job-diffusion
spec:
backoffLimit: 0
# Completions and parallelism should be the number of chips divided by 4.
# (e.g. 4 for a v5litepod-16)
completions: 4
parallelism: 4
completionMode: Indexed
template:
spec:
subdomain: headless-svc
restartPolicy: Never
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice
cloud.google.com/gke-tpu-topology: 4x4
containers:
- name: tpu-job-diffusion
image: gcr.io/${project-id}/diffusion:latest
ports:
- containerPort: 8471 # Default port using which TPU VMs communicate
- containerPort: 8431 # Port to export TPU usage metrics, if supported
command:
- bash
- -c
- |
cd examples/text_to_image
python3 train_text_to_image_flax.py --pretrained_model_name_or_path=duongna/stable-diffusion-v1-4-flax --dataset_name=lambdalabs/pokemon-blip-captions --resolution=128 --center_crop --random_flip --train_batch_size=4 --mixed_precision=fp16 --max_train_steps=1500 --learning_rate=1e-05 --max_grad_norm=1 --output_dir=sd-pokemon-model
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
Kemudian, deploy menggunakan:
kubectl apply -f tpu_job_diffusion.yaml
Pembersihan
Setelah Tugas selesai berjalan, Anda dapat menghapusnya menggunakan:
kubectl delete -f tpu_job_diffusion.yaml
PyTorch/XLA: GPT2 di WikiText
Tutorial ini menunjukkan cara menjalankan GPT2 di TPU v5e menggunakan HuggingFace di PyTorch/XLA menggunakan set data wikitext.
Membuat image Docker
Dockerfile terletak di folder ai-on-gke/tutorials-and-examples/tpu-examples/training/gpt/.
Sebelum menjalankan perintah berikut, pastikan akun Anda memiliki izin yang sesuai agar Docker dapat melakukan push ke repositori.
Build dan kirim image Docker:
cd ai-on-gke/tutorials-and-examples/tpu-examples/training/gpt/ docker build -t gcr.io/project-id/gpt:latest . docker push gcr.io/project-id/gpt:latest
Men-deploy workload
Salin YAML berikut dan simpan dalam file bernama tpu_job_gpt.yaml. Isi
kolom gambar dengan gambar yang baru saja Anda buat.
apiVersion: v1
kind: Service
metadata:
name: headless-svc
spec:
clusterIP: None
selector:
job-name: tpu-job-gpt
---
apiVersion: batch/v1
kind: Job
metadata:
name: tpu-job-gpt
spec:
backoffLimit: 0
# Completions and parallelism should be the number of chips divided by 4.
# (for example, 4 for a v5litepod-16)
completions: 4
parallelism: 4
completionMode: Indexed
template:
spec:
subdomain: headless-svc
restartPolicy: Never
volumes:
# Increase size of tmpfs /dev/shm to avoid OOM.
- name: shm
emptyDir:
medium: Memory
# consider adding `sizeLimit: XGi` depending on needs
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice
cloud.google.com/gke-tpu-topology: 4x4
containers:
- name: tpu-job-gpt
image: gcr.io/$(project-id)/gpt:latest
ports:
- containerPort: 8479
- containerPort: 8478
- containerPort: 8477
- containerPort: 8476
- containerPort: 8431 # Port to export TPU usage metrics, if supported.
env:
- name: PJRT_DEVICE
value: 'TPU'
- name: XLA_USE_BF16
value: '1'
command:
- bash
- -c
- |
numactl --cpunodebind=0 python3 -u examples/pytorch/xla_spawn.py --num_cores 4 examples/pytorch/language-modeling/run_clm.py --num_train_epochs 3 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --per_device_train_batch_size 16 --per_device_eval_batch_size 16 --do_train --do_eval --output_dir /tmp/test-clm --overwrite_output_dir --config_name my_config_2.json --cache_dir /tmp --tokenizer_name gpt2 --block_size 1024 --optim adafactor --adafactor true --save_strategy no --logging_strategy no --fsdp "full_shard" --fsdp_config fsdp_config.json
volumeMounts:
- mountPath: /dev/shm
name: shm
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
Deploy alur kerja menggunakan:
kubectl apply -f tpu_job_gpt.yaml
Pembersihan
Setelah tugas selesai berjalan, Anda dapat menghapusnya menggunakan:
kubectl delete -f tpu_job_gpt.yaml
Tutorial: Workload inferensi Single-Host
Tutorial ini menunjukkan cara menjalankan beban kerja inferensi satu host di TPU GKE v5e untuk model terlatih dengan JAX, TensorFlow, dan PyTorch. Secara umum, ada empat langkah terpisah yang harus dilakukan di cluster GKE:
Buat bucket Cloud Storage dan siapkan akses ke bucket. Anda menggunakan bucket Cloud Storage untuk menyimpan model terlatih.
Download dan konversi model terlatih menjadi model yang kompatibel dengan TPU. Terapkan Pod Kubernetes yang mendownload model terlatih, menggunakan Cloud TPU Converter, dan menyimpan model yang dikonversi ke bucket Cloud Storage menggunakan driver CSI Cloud Storage FUSE. Cloud TPU Converter tidak memerlukan hardware khusus. Tutorial ini menunjukkan cara mendownload model dan menjalankan Konverter Cloud TPU di kumpulan node CPU.
Luncurkan server untuk model yang dikonversi. Terapkan Deployment yang menayangkan model menggunakan framework server yang didukung oleh volume yang disimpan di Volume Persisten ReadOnlyMany (ROX). Replika deployment harus dijalankan di kumpulan node slice v5e dengan satu Pod Kubernetes per node.
Men-deploy load balancer untuk menguji server model. Server diekspos ke permintaan eksternal menggunakan Layanan LoadBalancer. Skrip Python telah disediakan dengan contoh permintaan untuk menguji server model.
Diagram berikut menunjukkan cara permintaan dirutekan oleh Load Balancer.
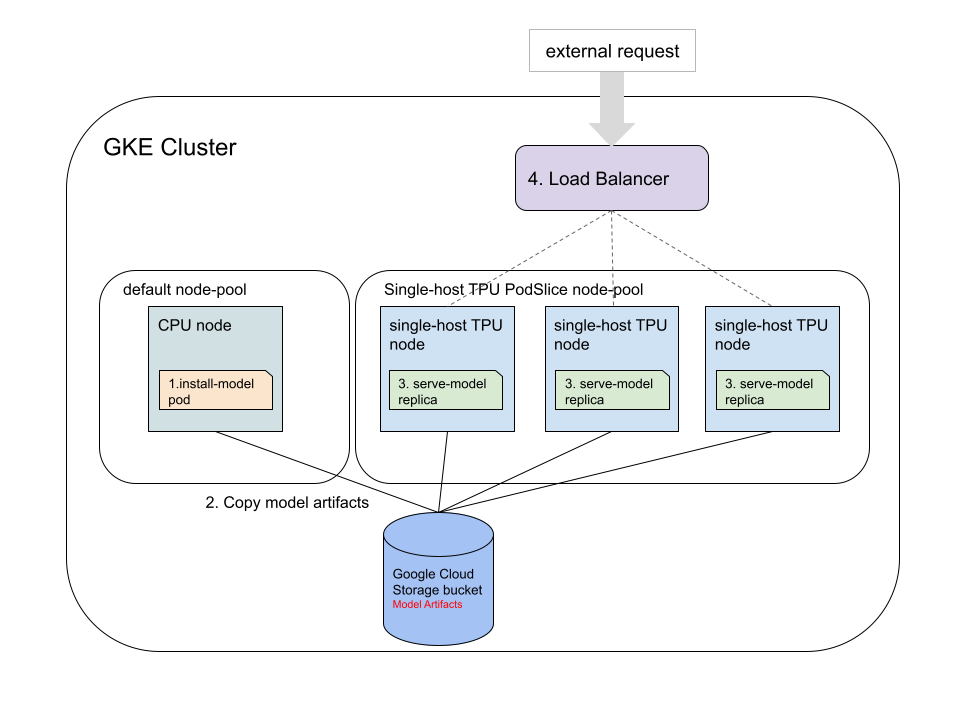
Contoh deployment server
Contoh beban kerja ini dikonfigurasi dengan asumsi berikut:
- Cluster berjalan dengan node pool TPU v5 dengan 3 node
- Node pool menggunakan jenis mesin
ct5lp-hightpu-1tdengan:- topologi adalah 1x1
- jumlah TPU chip adalah 1
Manifes GKE berikut menentukan Deployment server host tunggal.
apiVersion: apps/v1
kind: Deployment
metadata:
name: bert-deployment
spec:
selector:
matchLabels:
app: tf-bert-server
replicas: 3 # number of nodes in node pool
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
labels:
app: tf-bert-server
spec:
nodeSelector:
cloud.google.com/gke-tpu-topology: 1x1 # target topology
cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice # target version
containers:
- name: serve-bert
image: us-docker.pkg.dev/cloud-tpu-images/inference/tf-serving-tpu:2.13.0
env:
- name: MODEL_NAME
value: "bert"
volumeMounts:
- mountPath: "/models/"
name: bert-external-storage
ports:
- containerPort: 8500
- containerPort: 8501
- containerPort: 8431 # Port to export TPU usage metrics, if supported.
resources:
requests:
google.com/tpu: 1 # TPU chip request
limits:
google.com/tpu: 1 # TPU chip request
volumes:
- name: bert-external-storage
persistentVolumeClaim:
claimName: external-storage-pvc
Jika Anda menggunakan jumlah node yang berbeda di kumpulan node TPU, ubah
kolom replicas menjadi jumlah node.
Jika cluster Standard Anda menjalankan GKE versi 1.27 atau yang lebih lama, tambahkan kolom berikut ke manifes Anda:
spec:
securityContext:
privileged: true
Anda tidak perlu menjalankan Pod Kubernetes dalam mode Hak Istimewa di GKE versi 1.28 atau yang lebih baru. Untuk mengetahui detailnya, lihat Menjalankan penampung tanpa mode dengan hak istimewa.
Jika Anda menggunakan jenis mesin yang berbeda:
- Tetapkan
cloud.google.com/gke-tpu-topologyke topologi untuk jenis mesin yang Anda gunakan. - Tetapkan kedua kolom
google.com/tpudi bagianresourcesagar cocok dengan jumlah chip untuk jenis mesin yang sesuai.
Penyiapan
Download skrip Python tutorial dan manifes YAML menggunakan perintah berikut:
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.git
Buka direktori single-host-inference:
cd ai-on-gke/gke-tpu-examples/single-host-inference/
Menyiapkan lingkungan Python
Skrip Python yang Anda gunakan dalam tutorial ini memerlukan Python versi 3.9 atau yang lebih baru.
Jangan lupa untuk menginstal requirements.txt untuk setiap tutorial sebelum menjalankan
skrip pengujian Python.
Jika tidak memiliki penyiapan Python yang tepat di lingkungan lokal, Anda dapat menggunakan Cloud Shell untuk mendownload dan menjalankan skrip Python dalam tutorial ini.
Menyiapkan cluster
Buat cluster menggunakan jenis mesin
e2-standard-4.gcloud container clusters create cluster-name \ --region your-region \ --release-channel rapid \ --num-nodes=1 \ --machine-type=e2-standard-4 \ --workload-pool=project-id.svc.id.goog \ --addons GcsFuseCsiDriver
Contoh beban kerja mengasumsikan hal berikut:
- Cluster Anda berjalan dengan node pool TPU v5e yang berisi 3 node.
- TPU node pool menggunakan jenis mesin
ct5lp-hightpu-1t.
Jika menggunakan konfigurasi cluster yang berbeda dengan yang dijelaskan sebelumnya, Anda harus mengedit manifes deployment server.
Untuk demo JAX Stable Diffusion, Anda memerlukan node pool CPU dengan
jenis mesin yang memiliki memori yang tersedia 16 Gi+ (misalnya e2-standard-4).
Hal ini dikonfigurasi dalam perintah gcloud container clusters create atau dengan
menambahkan node pool tambahan ke cluster yang ada dengan perintah
berikut:
gcloud beta container node-pools create your-pool-name \ --zone=your-cluster-zone \ --cluster=your-cluster-name \ --machine-type=e2-standard-4 \ --num-nodes=1
Ganti kode berikut:
your-pool-name: Nama node pool yang akan dibuat.your-cluster-zone: Zona tempat cluster Anda dibuat.your-cluster-name: Nama cluster tempat node pool akan ditambahkan.your-machine-type: Jenis mesin node yang akan dibuat di node pool Anda.
Menyiapkan penyimpanan model
Ada beberapa cara untuk menyimpan model Anda agar dapat ditayangkan. Dalam tutorial ini, kita akan menggunakan pendekatan berikut:
- Untuk mengonversi model terlatih agar berfungsi di TPU, kita akan menggunakan Virtual Private Cloud yang didukung oleh Persistent Disk dengan akses
ReadWriteMany(RWX). - Untuk menayangkan model di beberapa TPU host tunggal, kita akan menggunakan VPC yang sama yang didukung oleh bucket Cloud Storage.
Jalankan perintah berikut untuk membuat bucket Cloud Storage.
gcloud storage buckets create gs://your-bucket-name \ --project=your-bucket-project-id \ --location=your-bucket-location
Ganti kode berikut:
your-bucket-name: Nama bucket Cloud Storage.your-bucket-project-id: Project ID tempat Anda membuat bucket Cloud Storage.your-bucket-location: Lokasi bucket Cloud Storage Anda. Untuk meningkatkan performa, tentukan lokasi tempat cluster GKE Anda berjalan.
Gunakan langkah-langkah berikut untuk memberi cluster GKE Anda akses ke bucket. Untuk menyederhanakan penyiapan, contoh berikut menggunakan namespace default dan akun layanan Kubernetes default. Untuk mengetahui detailnya, lihat Mengonfigurasi akses ke bucket Cloud Storage menggunakan GKE Workload Identity Federation untuk GKE.
Buat akun layanan IAM untuk aplikasi Anda atau gunakan akun layanan IAM yang ada. Anda dapat menggunakan akun layanan IAM mana pun di project bucket Cloud Storage Anda.
gcloud iam service-accounts create your-iam-service-acct \ --project=your-bucket-project-id
Ganti kode berikut:
your-iam-service-acct: nama akun layanan IAM baru.your-bucket-project-id: ID project tempat Anda membuat akun layanan IAM. Akun layanan IAM harus berada dalam project yang sama dengan bucket Cloud Storage Anda.
Pastikan akun layanan IAM Anda memiliki peran penyimpanan yang Anda butuhkan.
gcloud storage buckets add-iam-policy-binding gs://your-bucket-name \ --member "serviceAccount:your-iam-service-acct@your-bucket-project-id.iam.gserviceaccount.com" \ --role "roles/storage.objectAdmin"
Ganti kode berikut:
your-bucket-name: Nama bucket Cloud Storage Anda.your-iam-service-acct: nama akun layanan IAM baru.your-bucket-project-id: ID project tempat Anda membuat akun layanan IAM.
Izinkan akun layanan Kubernetes meniru identitas akun layanan IAM dengan menambahkan binding kebijakan IAM di antara kedua akun layanan tersebut. Dengan binding ini, akun layanan Kubernetes dapat bertindak sebagai akun layanan IAM.
gcloud iam service-accounts add-iam-policy-binding your-iam-service-acct@your-bucket-project-id.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:your-project-id.svc.id.goog[default/default]"
Ganti kode berikut:
your-iam-service-acct: nama akun layanan IAM baru.your-bucket-project-id: ID project tempat Anda membuat akun layanan IAM.your-project-id: ID project tempat Anda membuat cluster GKE. Bucket Cloud Storage dan cluster GKE Anda dapat berada dalam project yang sama atau berbeda.
Anotasikan akun layanan Kubernetes dengan alamat email akun layanan IAM.
kubectl annotate serviceaccount default \ --namespace default \ iam.gke.io/gcp-service-account=your-iam-service-acct@your-bucket-project-id.iam.gserviceaccount.com
Ganti kode berikut:
your-iam-service-acct: nama akun layanan IAM baru.your-bucket-project-id: ID project tempat Anda membuat akun layanan IAM.
Jalankan perintah berikut untuk mengisi nama bucket Anda dalam file YAML dari demo ini:
find . -type f -name "*.yaml" | xargs sed -i "s/BUCKET_NAME/your-bucket-name/g"
Ganti
your-bucket-namedengan nama bucket Cloud Storage Anda.Buat Persistent Volume dan Persistent Volume Claim dengan perintah berikut:
kubectl apply -f pvc-pv.yaml
Inferensi dan penayangan Model JAX
Instal dependensi Python untuk menjalankan skrip Python tutorial yang mengirim permintaan ke layanan model JAX.
pip install -r jax/requirements.txt
Jalankan demo penayangan JAX BERT E2E:
Demo ini menggunakan model BERT terlatih dari Hugging Face.
Pod Kubernetes melakukan langkah-langkah berikut:
- Mendownload dan menggunakan skrip Python
export_bert_model.pydari resource contoh untuk mendownload model bert terlatih ke direktori sementara. - Menggunakan image Cloud TPU Converter untuk mengonversi model terlatih dari CPU ke TPU dan menyimpan model di bucket Cloud Storage yang Anda buat selama penyiapan.
Pod Kubernetes ini dikonfigurasi untuk berjalan di CPU kumpulan node default. Jalankan Pod dengan perintah berikut:
kubectl apply -f jax/bert/install-bert.yaml
Pastikan model telah diinstal dengan benar dengan langkah-langkah berikut:
kubectl get pods install-bert
Mungkin perlu waktu beberapa menit agar STATUS membaca Completed.
Meluncurkan server model TF untuk model
Contoh workload dalam tutorial ini mengasumsikan hal berikut:
- Cluster berjalan dengan node pool TPU v5 yang memiliki tiga node
- Node pool menggunakan jenis mesin
ct5lp-hightpu-1tyang berisi satu chip TPU.
Jika menggunakan konfigurasi cluster yang berbeda dengan yang dijelaskan sebelumnya, Anda harus mengedit manifes deployment server.
Menerapkan deployment
kubectl apply -f jax/bert/serve-bert.yaml
Pastikan server berjalan dengan hal berikut:
kubectl get deployment bert-deployment
Mungkin perlu waktu beberapa menit bagi AVAILABLE untuk membaca 3.
Menerapkan layanan load balancer
kubectl apply -f jax/bert/loadbalancer.yaml
Pastikan load balancer siap untuk traffic eksternal dengan hal berikut:
kubectl get svc tf-bert-service
Mungkin perlu waktu beberapa menit agar IP tercantum di EXTERNAL_IP.
Mengirim permintaan ke server model
Dapatkan IP eksternal dari layanan load balancer:
EXTERNAL_IP=$(kubectl get services tf-bert-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
Jalankan skrip untuk mengirim permintaan ke server:
python3 jax/bert/bert_request.py $EXTERNAL_IP
Output yang diharapkan:
For input "The capital of France is [MASK].", the result is ". the capital of france is paris.."
For input "Hello my name [MASK] Jhon, how can I [MASK] you?", the result is ". hello my name is jhon, how can i help you?."
Pembersihan
Untuk membersihkan resource, jalankan kubectl delete dalam urutan terbalik.
kubectl delete -f jax/bert/loadbalancer.yaml kubectl delete -f jax/bert/serve-bert.yaml kubectl delete -f jax/bert/install-bert.yaml
Menjalankan demo penayangan E2E Stable Diffusion JAX
Demo ini menggunakan model Stable Diffusion yang telah dilatih sebelumnya dari Hugging Face.
Mengekspor model tersimpan TF2 yang kompatibel dengan TPU dari model Flax Stable Diffusion
Mengekspor model difusi stabil mengharuskan cluster memiliki kumpulan node CPU dengan jenis mesin yang memiliki memori yang tersedia lebih dari 16 Gi seperti yang dijelaskan dalam Menyiapkan cluster.
Pod Kubernetes menjalankan langkah-langkah berikut:
- Mendownload dan menggunakan skrip Python
export_stable_diffusion_model.pydari resource contoh untuk mendownload model difusi stabil yang telah dilatih sebelumnya ke direktori sementara. - Menggunakan image Cloud TPU Converter untuk mengonversi model terlatih dari CPU ke TPU dan menyimpan model di bucket Cloud Storage yang Anda buat selama penyiapan penyimpanan.
Pod Kubernetes ini dikonfigurasi untuk berjalan di kumpulan node CPU default. Jalankan Pod dengan perintah berikut:
kubectl apply -f jax/stable-diffusion/install-stable-diffusion.yaml
Pastikan model telah diinstal dengan benar dengan langkah-langkah berikut:
kubectl get pods install-stable-diffusion
Mungkin perlu waktu beberapa menit agar STATUS membaca Completed.
Meluncurkan penampung server model TF untuk model
Contoh beban kerja telah dikonfigurasi dengan asumsi berikut:
- cluster berjalan dengan node pool TPU v5 dengan tiga node
- kumpulan node menggunakan jenis mesin
ct5lp-hightpu-1tdengan:- topologi adalah 1x1
- jumlah TPU chip adalah 1
Jika menggunakan konfigurasi cluster yang berbeda dengan yang dijelaskan sebelumnya, Anda harus mengedit manifes deployment server.
Terapkan deployment:
kubectl apply -f jax/stable-diffusion/serve-stable-diffusion.yaml
Pastikan server berjalan seperti yang diharapkan:
kubectl get deployment stable-diffusion-deployment
Mungkin perlu waktu beberapa menit bagi AVAILABLE untuk membaca 3.
Terapkan layanan load balancer:
kubectl apply -f jax/stable-diffusion/loadbalancer.yaml
Pastikan load balancer siap untuk traffic eksternal dengan hal berikut:
kubectl get svc tf-stable-diffusion-service
Mungkin perlu waktu beberapa menit agar IP tercantum di EXTERNAL_IP.
Mengirim permintaan ke server model
Dapatkan IP eksternal dari load balancer:
EXTERNAL_IP=$(kubectl get services tf-stable-diffusion-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
Menjalankan skrip untuk mengirim permintaan ke server
python3 jax/stable-diffusion/stable_diffusion_request.py $EXTERNAL_IP
Output yang diharapkan:
Perintahnya adalah Painting of a squirrel skating in New York dan gambar output
akan disimpan sebagai stable_diffusion_images.jpg di direktori Anda saat ini.
Pembersihan
Untuk membersihkan resource, jalankan kubectl delete dalam urutan terbalik.
kubectl delete -f jax/stable-diffusion/loadbalancer.yaml kubectl delete -f jax/stable-diffusion/serve-stable-diffusion.yaml kubectl delete -f jax/stable-diffusion/install-stable-diffusion.yaml
Jalankan demo penayangan E2E TensorFlow ResNet-50:
Instal dependensi Python untuk menjalankan skrip Python tutorial yang mengirim permintaan ke layanan model TF.
pip install -r tf/resnet50/requirements.txt
Langkah 1: Konversikan model
Menerapkan konversi model:
kubectl apply -f tf/resnet50/model-conversion.yml
Pastikan model telah diinstal dengan benar dengan langkah-langkah berikut:
kubectl get pods resnet-model-conversion
Mungkin perlu waktu beberapa menit agar STATUS membaca Completed.
Langkah 2: Menayangkan model dengan TensorFlow Serving
Terapkan deployment penayangan model:
kubectl apply -f tf/resnet50/deployment.yml
Pastikan server berjalan seperti yang diharapkan dengan perintah berikut:
kubectl get deployment resnet-deployment
Mungkin perlu waktu beberapa menit bagi AVAILABLE untuk membaca 3.
Terapkan layanan load balancer:
kubectl apply -f tf/resnet50/loadbalancer.yml
Pastikan load balancer siap untuk traffic eksternal dengan hal berikut:
kubectl get svc resnet-service
Mungkin perlu waktu beberapa menit agar IP tercantum di EXTERNAL_IP.
Langkah 3: Kirim permintaan pengujian ke server model
Dapatkan IP eksternal dari load balancer:
EXTERNAL_IP=$(kubectl get services resnet-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
Jalankan skrip permintaan pengujian (HTTP) untuk mengirim permintaan ke server model.
python3 tf/resnet50/request.py --host $EXTERNAL_IP
Responsnya akan terlihat seperti berikut:
Predict result: ['ImageNet ID: n07753592, Label: banana, Confidence: 0.94921875', 'ImageNet ID: n03532672, Label: hook, Confidence: 0.0223388672', 'ImageNet ID: n07749582, Label: lemon, Confidence: 0.00512695312
Langkah 4: Bersihkan
Untuk membersihkan resource, jalankan perintah kubectl delete berikut:
kubectl delete -f tf/resnet50/loadbalancer.yml kubectl delete -f tf/resnet50/deployment.yml kubectl delete -f tf/resnet50/model-conversion.yml
Pastikan Anda menghapus node pool dan cluster GKE setelah selesai menggunakannya.
Inferensi dan penayangan model PyTorch
Instal dependensi Python untuk menjalankan skrip Python tutorial yang mengirim permintaan ke layanan model PyTorch:
pip install -r pt/densenet161/requirements.txt
Jalankan demo penayangan E2E Densenet161 TorchServe:
Buat arsip model.
- Menerapkan arsip model:
kubectl apply -f pt/densenet161/model-archive.yml
- Pastikan model telah diinstal dengan benar dengan langkah-langkah berikut:
kubectl get pods densenet161-model-archive
Mungkin perlu waktu beberapa menit agar
STATUSmembacaCompleted.Menayangkan Model dengan TorchServe:
Terapkan Deployment Penayangan Model:
kubectl apply -f pt/densenet161/deployment.yml
Pastikan server berjalan seperti yang diharapkan dengan perintah berikut:
kubectl get deployment densenet161-deployment
Mungkin perlu waktu beberapa menit bagi
AVAILABLEuntuk membaca3.Terapkan layanan load balancer:
kubectl apply -f pt/densenet161/loadbalancer.yml
Pastikan load balancer siap untuk traffic eksternal dengan perintah berikut:
kubectl get svc densenet161-service
Mungkin perlu waktu beberapa menit agar IP tercantum di
EXTERNAL_IP.
Mengirim permintaan pengujian ke server model:
Dapatkan IP eksternal dari load balancer:
EXTERNAL_IP=$(kubectl get services densenet161-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
Jalankan skrip permintaan pengujian untuk mengirim permintaan (HTTP) ke server model.:
python3 pt/densenet161/request.py --host $EXTERNAL_IP
Anda akan melihat respons seperti ini:
Request successful. Response: {'tabby': 0.47878125309944153, 'lynx': 0.20393909513950348, 'tiger_cat': 0.16572578251361847, 'tiger': 0.061157409101724625, 'Egyptian_cat': 0.04997897148132324
Bersihkan resource, dengan menjalankan perintah
kubectl deleteberikut:kubectl delete -f pt/densenet161/loadbalancer.yml kubectl delete -f pt/densenet161/deployment.yml kubectl delete -f pt/densenet161/model-archive.yml
Pastikan Anda menghapus node pool dan cluster GKE setelah selesai menggunakannya.
Memecahkan masalah umum
Anda dapat menemukan informasi pemecahan masalah GKE di Memecahkan masalah TPU di GKE.
Inisialisasi TPU gagal
Jika Anda mengalami error berikut, pastikan Anda menjalankan penampung TPU dalam mode dilindungi atau telah meningkatkan ulimit di dalam penampung. Untuk mengetahui informasi selengkapnya, lihat Menjalankan tanpa mode dengan hak istimewa.
TPU platform initialization failed: FAILED_PRECONDITION: Couldn't mmap: Resource
temporarily unavailable.; Unable to create Node RegisterInterface for node 0,
config: device_path: "/dev/accel0" mode: KERNEL debug_data_directory: ""
dump_anomalies_only: true crash_in_debug_dump: false allow_core_dump: true;
could not create driver instance
Deadlock penjadwalan
Misalkan Anda memiliki dua tugas (Tugas A dan Tugas B) dan keduanya akan dijadwalkan di slice TPU dengan topologi TPU tertentu (misalnya, v4-32). Selain itu, anggaplah Anda memiliki dua slice TPU v4-32 dalam cluster GKE; kita akan menyebut slice tersebut sebagai slice X dan slice Y. Karena cluster Anda memiliki kapasitas yang cukup untuk menjadwalkan kedua tugas, secara teori kedua tugas harus dijadwalkan dengan cepat – satu tugas di setiap dua slice TPU v4-32.
Namun, tanpa perencanaan yang cermat, Anda dapat mengalami deadlock penjadwalan. Misalkan penjadwal Kubernetes menjadwalkan satu Pod Kubernetes dari Tugas A di slice X, lalu menjadwalkan satu Pod Kubernetes dari Tugas B di slice X. Dalam hal ini, dengan mempertimbangkan aturan afinitas Pod Kubernetes untuk Tugas A, penjadwal akan mencoba menjadwalkan semua Pod Kubernetes yang tersisa untuk Tugas A di slice X. Sama untuk Tugas B. Dengan demikian, Tugas A maupun Tugas B tidak akan dapat sepenuhnya dijadwalkan di satu slice. Hasilnya adalah deadlock penjadwalan.
Untuk menghindari risiko deadlock penjadwalan, Anda dapat menggunakan anti-afinitas Pod
Kubernetes dengan cloud.google.com/gke-nodepool sebagai topologyKey seperti ditunjukkan
dalam contoh berikut:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
parallelism: 2
template:
metadata:
labels:
job: pi
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: job
operator: In
values:
- pi
topologyKey: cloud.google.com/gke-nodepool
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: job
operator: NotIn
values:
- pi
topologyKey: cloud.google.com/gke-nodepool
namespaceSelector:
matchExpressions:
- key: kubernetes.io/metadata.name
operator: NotIn
values:
- kube-system
containers:
- name: pi
image: perl:5.34.0
command: ["sleep", "60"]
restartPolicy: Never
backoffLimit: 4
Membuat resource node pool TPU dengan Terraform
Anda juga dapat menggunakan Terraform untuk mengelola resource cluster dan node pool.
Membuat node pool slice TPU multi-host di Cluster GKE yang ada
Jika sudah memiliki Cluster tempat Anda ingin membuat node pool TPU multi-host, Anda dapat menggunakan cuplikan Terraform berikut:
resource "google_container_cluster" "cluster_multi_host" {
…
release_channel {
channel = "RAPID"
}
workload_identity_config {
workload_pool = "my-gke-project.svc.id.goog"
}
addons_config {
gcs_fuse_csi_driver_config {
enabled = true
}
}
}
resource "google_container_node_pool" "multi_host_tpu" {
provider = google-beta
project = "${project-id}"
name = "${node-pool-name}"
location = "${location}"
node_locations = ["${node-locations}"]
cluster = google_container_cluster.cluster_multi_host.name
initial_node_count = 2
node_config {
machine_type = "ct4p-hightpu-4t"
reservation_affinity {
consume_reservation_type = "SPECIFIC_RESERVATION"
key = "compute.googleapis.com/reservation-name"
values = ["${reservation-name}"]
}
workload_metadata_config {
mode = "GKE_METADATA"
}
}
placement_policy {
type = "COMPACT"
tpu_topology = "2x2x2"
}
}
Ganti nilai berikut:
your-project: Project Google Cloud tempat Anda menjalankan beban kerja.your-node-pool: Nama node pool yang Anda buat.us-central2: Region tempat Anda menjalankan beban kerja.us-central2-b: Zona tempat Anda menjalankan beban kerja.your-reservation-name: Nama pemesanan Anda.
Membuat node pool slice TPU host tunggal di Cluster GKE yang ada
Gunakan cuplikan Terraform berikut:
resource "google_container_cluster" "cluster_single_host" {
…
cluster_autoscaling {
autoscaling_profile = "OPTIMIZE_UTILIZATION"
}
release_channel {
channel = "RAPID"
}
workload_identity_config {
workload_pool = "${project-id}.svc.id.goog"
}
addons_config {
gcs_fuse_csi_driver_config {
enabled = true
}
}
}
resource "google_container_node_pool" "single_host_tpu" {
provider = google-beta
project = "${project-id}"
name = "${node-pool-name}"
location = "${location}"
node_locations = ["${node-locations}"]
cluster = google_container_cluster.cluster_single_host.name
initial_node_count = 0
autoscaling {
total_min_node_count = 2
total_max_node_count = 22
location_policy = "ANY"
}
node_config {
machine_type = "ct4p-hightpu-4t"
workload_metadata_config {
mode = "GKE_METADATA"
}
}
}
Ganti nilai berikut:
your-project: Project Google Cloud tempat Anda menjalankan beban kerja.your-node-pool: Nama node pool yang Anda buat.us-central2: Region tempat Anda menjalankan beban kerja.us-central2-b: Zona tempat Anda menjalankan beban kerja.