PyTorch XLA 워크로드 프로파일링
프로파일링은 모델 성능을 분석하고 개선하는 방법 중 하나입니다. 이외에도 훨씬 더 많은 기능이 있지만, 때로는 기기(TPU)와 호스트(CPU) 양쪽에서 다 실행되는 타이밍 작업 및 코드 부분이라고 생각하면 도움이 됩니다. 이 가이드에서는 학습 또는 추론을 위해 코드를 프로파일링하는 방법을 간략하게 설명합니다. 생성된 프로필을 분석하는 방법에 관한 자세한 내용은 다음 가이드를 참고하세요.
시작하기
TPU 만들기
환경 변수 내보내기
$ export TPU_NAME=your_tpu_name $ export ZONE=us-central2-b $ export PROJECT_ID=project-id $ export ACCELERATOR_TYPE=v4-8 $ export RUNTIME_VERSION=tpu-vm-v4-pt-2.0
변수 설명 내보내기
TPU 리소스 실행
$ gcloud compute tpus tpu-vm create ${TPU_NAME} \ --zone us-central2-b \ --accelerator-type ${ACCELERATOR_TYPE} \ --version ${RUNTIME_VERSION} \ --project $PROJECT_ID \ --subnetwork=tpusubnet
gcloud scp명령어를 사용하여 TPU VM의 홈 디렉터리로 코드를 이동합니다. 예를 들면 다음과 같습니다.$ gcloud compute tpus tpu-vm scp my-code-file ${TPU_NAME}: --zone ${ZONE}
프로파일링
프로필은 capture_profile.py를 통해 수동으로 캡처하거나 torch_xla.debug.profiler API를 사용하여 학습 스크립트 내에서 프로그래매틱 방식으로 캡처할 수 있습니다.
프로필 서버 시작
프로필을 캡처하려면 프로필 서버가 학습 스크립트 내에서 실행 중이어야 합니다. 다음 명령어와 같이 원하는 포트 번호(예: 9012)로 서버를 시작합니다.
import torch_xla.debug.profiler as xp server = xp.start_server(9012)
main 함수의 시작 부분에서 서버를 시작할 수 있습니다.
이제 다음 섹션에 설명된 대로 프로필을 캡처할 수 있습니다. 이 스크립트는 하나의 TPU 기기에서 발생하는 모든 내용을 프로파일링합니다.
Trace 추가
호스트 머신에서 작업을 프로파일링하려면 코드에 xp.StepTrace 또는 xp.Trace를 추가하면 됩니다. 이러한 함수는 호스트 머신에서 Python 코드를 추적합니다.
(이는 TPU 기기로 "그래프"를 전달하기 전 호스트(CPU)에서 Python 코드를 실행하는 데 걸리는 시간을 측정하는 것과 같습니다. 따라서 추적 오버헤드를 분석할 때 가장 유용합니다.) 예를 들어 코드가 데이터 배치를 처리하는 학습 루프 내에 이를 추가할 수 있습니다.
for step, batch in enumerate(train_dataloader):
with xp.StepTrace('Training_step', step_num=step):
...
또는 다음으로 코드의 개별 부분을 래핑할 수 있습니다.
with xp.Trace('loss'):
loss = ...
Lighting을 사용하는 경우 코드의 일부에서 자동으로 수행되기 때문에 추적 추가를 건너뛸 수 있습니다. 하지만 trace를 추가하려면 이를 학습 루프 내에 삽입해도 됩니다.
초기 컴파일 후 기기 활동을 캡처할 수 있습니다. 모델이 학습 또는 추론 단계를 시작할 때까지 기다리세요.
수동 캡처
Pytorch XLA 저장소의 capture_profile.py 스크립트를 사용하면 프로필을 빠르게 캡처할 수 있습니다. 이렇게 하려면 캡처 프로필 파일을 TPU VM에 직접 복사합니다. 다음 명령어는 캡처 프로필 파일을 홈 디렉터리에 복사합니다.
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone us-central2-b \ --worker=all \ --command="wget https://raw.githubusercontent.com/pytorch/xla/master/scripts/capture_profile.py"
학습이 실행되는 동안 다음을 실행하여 프로필을 캡처합니다.
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone us-central2-b \ --worker=all \ --command="python3 capture_profile.py --service_addr "localhost:9012" --logdir ~/profiles/ --duration_ms 2000"
이 명령어는 .xplane.pb 파일을 logdir에 저장합니다. 로깅 디렉터리 ~/profiles/를 원하는 위치 및 이름으로 변경할 수 있습니다. Cloud Storage 버킷에 직접 저장할 수도 있습니다. 이렇게 하려면 logdir을 gs://your_bucket_name/으로 설정하세요.
프로그래매틱 캡처
스크립트를 트리거하여 프로필을 수동으로 캡처하는 대신 학습 스크립트 내부 torch_xla.debug.profiler.trace_detached API를 사용하여 프로필을 자동으로 트리거하도록 학습 스크립트를 구성할 수 있습니다.
예를 들어 특정 에포크 및 단계에서 프로필을 자동으로 캡처하려면 PROFILE_STEP, PROFILE_EPOCH, PROFILE_LOGDIR 환경 변수를 사용하도록 학습 스크립트를 구성하면 됩니다.
import os
import torch_xla.debug.profiler as xp
# Within the training script, read the step and epoch to profile from the
# environment.
profile_step = int(os.environ.get('PROFILE_STEP', -1))
profile_epoch = int(os.environ.get('PROFILE_EPOCH', -1))
...
for epoch in range(num_epoch):
...
for step, data in enumerate(epoch_dataloader):
if epoch == profile_epoch and step == profile_step:
profile_logdir = os.environ['PROFILE_LOGDIR']
# Use trace_detached to capture the profile from a background thread
xp.trace_detached('localhost:9012', profile_logdir)
...
그러면 PROFILE_LOGDIR 환경 변수로 지정한 디렉터리에 .xplane.pb 파일이 저장됩니다.
텐서보드의 분석
프로필을 추가로 분석하려면 동일한 머신이나 다른 머신(권장)에서
TPU 텐서보드 플러그인과 함께 TensorBoard를 사용할 수 있습니다.
원격 머신에서 텐서보드를 실행하려면 SSH를 사용하여 원격 머신에 연결하고 포트 전달을 사용 설정합니다. 예를 들면 다음과 같습니다.
$ ssh -L 6006:localhost:6006 remote server address
또는
$ gcloud compute tpus tpu-vm ssh $TPU_NAME --zone=$ZONE --ssh-flag="-4 -L 6006:localhost:6006"
원격 머신에서 필요한 패키지를 설치하고 텐서보드를 실행합니다(해당 머신의 ~/profiles/ 아래에 프로필이 있다고 가정). 프로필을 다른 디렉터리 또는 Cloud Storage 버킷에 저장한 경우 경로를 올바르게 지정했는지 확인합니다(예: gs://your_bucket_name/profiles).
(vm)$ pip install tensorflow-cpu tensorboard-plugin-profile
(vm)$ tensorboard --logdir ~/profiles/ --port 6006
(vm)$ pip uninstall tensorflow tf-nightly tensorboard tb-nightly tbp-nightly
텐서보드 실행
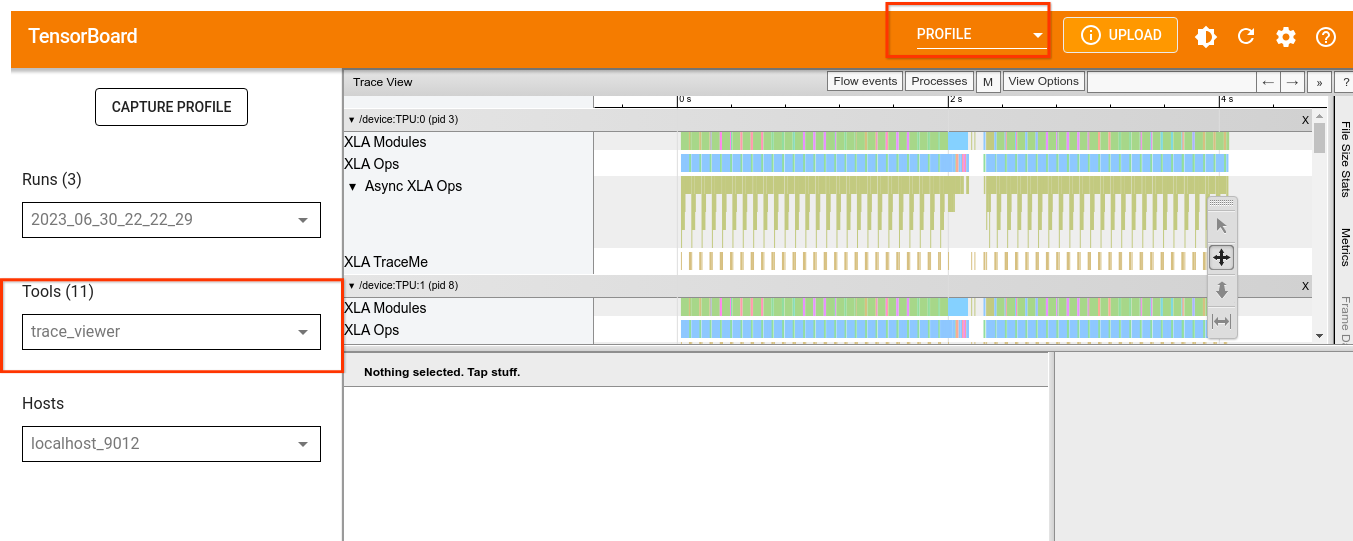
로컬 브라우저에서 http://localhost:6006/으로 이동하고 드롭다운 메뉴에서 PROFILE을 선택하여 프로필을 로드합니다.
텐서보드 도구 및 출력 해석 방법에 관한 자세한 내용은 TPU 도구를 참고하세요.