Introducción a Multislice de la TPU de Cloud
Multislice de TPU de Cloud es una tecnología de escalado del rendimiento de pila completa que permite que un trabajo de entrenamiento use varios slices de TPU en un solo slice o en slices de varios pods con paralelismo de datos estándar. Con los chips TPU v4, esto significa que los trabajos de entrenamiento pueden usar más de 4096 chips en una sola ejecución. En el caso de las tareas de entrenamiento que requieren menos de 4096 chips, un solo segmento puede ofrecer el mejor rendimiento. Sin embargo, varias porciones más pequeñas están disponibles más fácilmente, lo que permite que el tiempo de inicio sea más rápido cuando se usa Multislice con porciones más pequeñas.
Cuando se implementan en configuraciones de Multislice, los chips de TPU de cada slice se comunican a través de una interconexión entre chips (ICI). Los chips de TPU de diferentes slices se comunican transfiriendo datos a las CPUs (hosts), que a su vez transmiten los datos a través de la red del centro de datos (DCN). Para obtener más información sobre cómo escalar con Multislice, consulta Cómo escalar el entrenamiento de la IA a decenas de miles de chips de TPU de Cloud con Multislice.
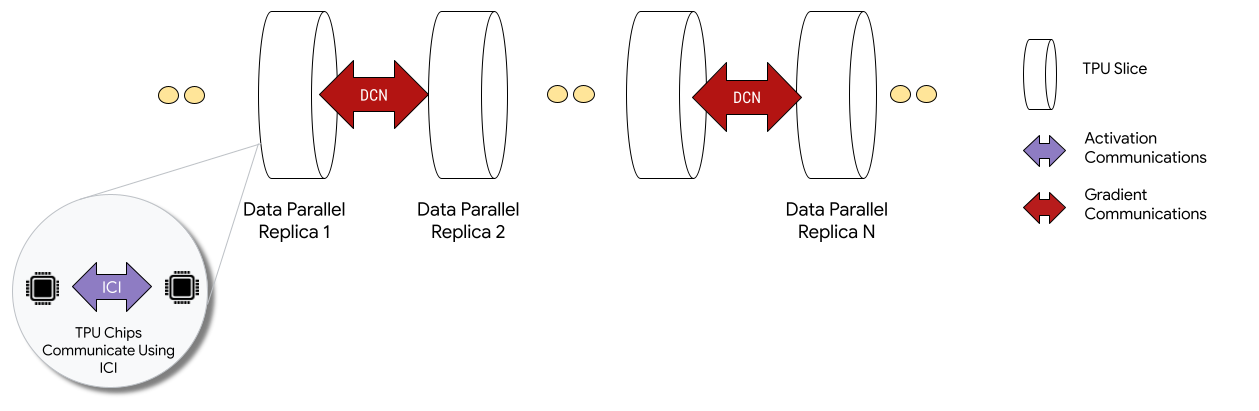
Los desarrolladores no tienen que escribir código para implementar la comunicación DCN entre slices. El compilador XLA genera ese código y superpone la comunicación con el cálculo para obtener el máximo rendimiento.
Conceptos
- Tipo de acelerador
- La forma de cada slice de TPU
que compone un Multislice. Cada segmento de una solicitud de varios segmentos es del mismo tipo de acelerador. Un tipo de acelerador consta de un tipo de TPU (versión 4 o posterior) seguido del número de Tensor Cores.
Por ejemplo,
v5litepod-128especifica una TPU v5e con 128 Tensor Cores. - Reparación automática
- Cuando una porción se enfrenta a un evento de mantenimiento, una expropiación o un fallo de hardware, TPU de Cloud creará una nueva porción. Si no hay recursos suficientes para crear una nueva partición, la creación no se completará hasta que haya hardware disponible. Una vez creada la nueva porción, se reiniciarán todas las demás porciones del entorno Multislice para que el entrenamiento pueda continuar. Si se configura correctamente un script de inicio, el script de entrenamiento se puede volver a iniciar automáticamente sin que el usuario tenga que hacer nada, y se carga y se reanuda desde el último punto de control.
- Redes de centros de datos (DCN)
- Una red con mayor latencia y menor rendimiento (en comparación con ICI) que conecta sectores de TPU en una configuración Multislice.
- Programación de bandas
- Cuando se aprovisionan todas las rebanadas de TPU al mismo tiempo, se garantiza que se aprovisionan todas o ninguna correctamente.
- Interconexión entre chips (ICI)
- Enlaces internos de alta velocidad y baja latencia que conectan las TPUs de un pod de TPU.
- Multicorte
- Dos o más porciones de chips de TPU que pueden comunicarse a través de DCN.
- Nodo
- En el contexto de Multislice, el término "nodo" hace referencia a una sola slice de TPU. A cada porción de TPU de un Multislice se le asigna un ID de nodo.
- Script de inicio
- Una secuencia de comandos de inicio de Compute Engine estándar que se ejecuta cada vez que se inicia o reinicia una máquina virtual. En el caso de Multislice, se especifica en la solicitud de creación del código QR. Para obtener más información sobre las secuencias de comandos de inicio de las TPU de Cloud, consulta Gestionar recursos de TPU.
- Tensor
- Estructura de datos que se usa para representar datos multidimensionales en un modelo de aprendizaje automático.
- Tipos de capacidad de TPU de Cloud
Las TPUs se pueden crear a partir de diferentes tipos de capacidad (consulta las opciones de uso en Cómo funcionan los precios de las TPUs):
Reserva: para consumir una reserva, debes tener un contrato de reserva con Google. Usa la marca
--reservedal crear tus recursos.Spot: se dirige a la cuota interrumpible mediante máquinas virtuales de acceso puntual. Es posible que se interrumpan tus recursos para dejar espacio a las solicitudes de un trabajo de mayor prioridad. Usa la marca
--spotal crear tus recursos.Bajo demanda: se dirige a la cuota bajo demanda, que no necesita una reserva y no se va a anticipar. La solicitud de TPU se pondrá en cola en una cola de cuotas bajo demanda ofrecida por TPU de Cloud. No se garantiza la disponibilidad de los recursos. Seleccionado de forma predeterminada, no se necesitan marcas.
Empezar
Configura tu entorno de TPU de Cloud.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
ici_data_parallelismici_fsdp_parallelismici_tensor_parallelismConfigura el entorno:
$ gcloud auth login $ export QR_ID=your-queued-resource-id $ export TPU_NAME=your-tpu-name $ export PROJECT=your-project-name $ export ZONE=us-central1-a $ export NETWORK_NAME=your-network-name $ export SUBNETWORK_NAME=your-subnetwork-name $ export RUNTIME_VERSION=v2-alpha-tpuv5-lite $ export ACCELERATOR_TYPE=v5litepod-16 $ export EXAMPLE_TAG_1=your-tag-1 $ export EXAMPLE_TAG_2=your-tag-2 $ export SLICE_COUNT=4 $ export STARTUP_SCRIPT='#!/bin/bash\n'
Descripciones de las variables
Entrada Descripción QR_ID Es el ID asignado por el usuario del recurso en cola. TPU_NAME El nombre que has asignado a tu TPU. PROYECTO Google Cloud nombre del proyecto ZONE Especifica la zona en la que se van a crear los recursos. NETWORK_NAME Nombre de las redes de VPC. SUBNETWORK_NAME Nombre de la subred en las redes de VPC RUNTIME_VERSION La versión de software de TPU de Cloud. ACCELERATOR_TYPE v4-16 EXAMPLE_TAG_1, EXAMPLE_TAG_2 … Etiquetas que se usan para identificar los orígenes o los destinos válidos en los cortafuegos de la red SLICE_COUNT Número de porciones. Se limita a un máximo de 256 segmentos. STARTUP_SCRIPT Si especificas una secuencia de comandos de inicio, se ejecutará cuando se aprovisione o se reinicie el segmento de TPU. Crea claves SSH para
gcloud. Te recomendamos que dejes la contraseña en blanco (pulsa Intro dos veces después de ejecutar el siguiente comando). Si se te indica que el archivogoogle_compute_engineya existe, sustituye la versión actual.$ ssh-keygen -f ~/.ssh/google_compute_engine
Aprovisiona tus TPUs:
gcloud
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-id=${TPU_NAME} \ --zone=${ZONE} \ [--reserved |--spot]
La CLI de Google Cloud no admite todas las opciones de creación de códigos QR, como las etiquetas. Para obtener más información, consulta Crear QRs.
Consola
En la Google Cloud consola, ve a la página TPUs:
Haz clic en Crear TPU.
En el campo Name (Nombre), introduce un nombre para tu TPU.
En el cuadro Zona, selecciona la zona en la que quieras crear la TPU.
En el cuadro Tipo de TPU, selecciona un tipo de acelerador. El tipo de acelerador especifica la versión y el tamaño de la TPU de Cloud que quieres crear. Para obtener más información sobre los tipos de aceleradores admitidos para cada versión de TPU, consulta Versiones de TPU.
En el cuadro Versión de software de la TPU, selecciona una versión de software. Al crear una máquina virtual de TPU de Cloud, la versión del software de TPU especifica la versión del tiempo de ejecución de TPU que se va a instalar. Para obtener más información, consulta Versiones de software de TPU.
Haz clic en el interruptor Habilitar colas.
En el campo Queued resource name (Nombre del recurso en cola), introduce un nombre para tu solicitud de recurso en cola.
Haz clic en Crear para crear tu solicitud de recurso en cola.
Espera hasta que el recurso en cola esté en el estado
ACTIVE, lo que significa que los nodos de trabajador están en el estadoREADY. Una vez que se inicie el aprovisionamiento de recursos en cola, puede tardar entre uno y cinco minutos en completarse, en función del tamaño del recurso en cola. Puedes consultar el estado de una solicitud de recurso en cola mediante la CLI de gcloud o la consola de Google Cloud :gcloud
$ gcloud compute tpus queued-resources \ list --filter=${QR_ID} --zone=${ZONE}
Consola
En la Google Cloud consola, ve a la página TPUs:
Haz clic en la pestaña Recursos en cola.
Haga clic en el nombre de la solicitud de recurso en cola.
Conéctate a la VM de TPU mediante SSH:
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} --zone=${ZONE}
Clona MaxText (que incluye
shardings.py) en tu VM de TPU:$ git clone https://github.com/AI-Hypercomputer/maxtext && cd maxtext
Instala Python 3.10:
$ sudo apt-get update $ sudo apt install python3.10 $ sudo apt install python3.10-venv
Crea y activa un entorno virtual:
.$ python3 -m venv your-venv-name $ source your-venv-name/bin/activate
En el directorio del repositorio MaxText, ejecuta la secuencia de comandos de configuración para instalar JAX y otras dependencias en tu segmento de TPU. El script de configuración tarda unos minutos en ejecutarse.
$ bash setup.sh
Ejecuta el siguiente comando para ejecutar
shardings.pyen tu segmento de TPU.$ python3 -m pedagogical_examples.shardings \ --ici_fsdp_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Puedes ver los resultados en los registros. Tus TPUs deberían alcanzar unos 260 TFLOPs por segundo o un impresionante 90%de utilización de FLOPs. En este caso, hemos seleccionado aproximadamente el lote máximo que cabe en la memoria de alto ancho de banda (HBM) de la TPU.
Puedes consultar otras estrategias de fragmentación en ICI. Por ejemplo, puedes probar la siguiente combinación:
$ python3 -m pedagogical_examples.shardings \ --ici_tensor_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Elimina el recurso en cola y el segmento de TPU cuando hayas terminado. Debes ejecutar estos pasos de limpieza en el entorno en el que has configurado el segmento (primero, ejecuta
exitpara salir de la sesión SSH). El proceso de eliminación tardará entre dos y cinco minutos en completarse. Si usas la CLI de gcloud, puedes ejecutar este comando en segundo plano con la marca opcional--async.gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --force (--async)
Consola
En la Google Cloud consola, ve a la página TPUs:
Haz clic en la pestaña Recursos en cola.
Seleccione la casilla situada junto a la solicitud de recursos en cola.
Haz clic en Eliminar.
- dcn_data_parallelism
- dcn_fsdp_parallelism
- dcn_tensor_parallelism
Clona MaxText en tu máquina runner:
$ git clone https://github.com/AI-Hypercomputer/maxtext
Ve al directorio del repositorio.
$ cd maxtext
Crea claves SSH para
gcloud. Te recomendamos que dejes la contraseña en blanco (pulsa Intro dos veces después de ejecutar el siguiente comando). Si se te indica que el archivogoogle_compute_engineya existe, selecciona que no quieres conservar la versión que ya tienes.$ ssh-keygen -f ~/.ssh/google_compute_engine
Añade una variable de entorno para definir el número de slices de TPU en
2.$ export SLICE_COUNT=2
Crea un entorno Multislice con el comando
queued-resources createo la consola Google Cloud .gcloud
El siguiente comando muestra cómo crear una TPU Multislice v5e. Para usar otra versión de TPU, especifica un
accelerator-typey unruntime-versiondiferentes.$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-count=${SLICE_COUNT} \ --node-prefix=${TPU_NAME} \ --zone=${ZONE} \ [--reserved|--spot]
Consola
En la Google Cloud consola, ve a la página TPUs:
Haz clic en Crear TPU.
En el campo Name (Nombre), introduce un nombre para tu TPU.
En el cuadro Zona, selecciona la zona en la que quieras crear la TPU.
En el cuadro Tipo de TPU, selecciona un tipo de acelerador. El tipo de acelerador especifica la versión y el tamaño de la TPU de Cloud que quieres crear. Multislice solo se admite en la versión 4 de TPU de Cloud y en versiones posteriores de TPU. Para obtener más información sobre las versiones de TPU, consulta Versiones de TPU.
En el cuadro Versión de software de la TPU, selecciona una versión de software. Al crear una máquina virtual de TPU de Cloud, la versión del software de TPU especifica la versión del tiempo de ejecución de TPU que se va a instalar en las máquinas virtuales de TPU. Para obtener más información, consulta Versiones de software de TPU.
Haz clic en el interruptor Habilitar colas.
En el campo Queued resource name (Nombre del recurso en cola), introduce un nombre para tu solicitud de recurso en cola.
Marca la casilla Convertir en TPU Multislice.
En el campo Número de porciones, introduce el número de porciones que quieras crear.
Haz clic en Crear para crear tu solicitud de recurso en cola.
Cuando se inicie el aprovisionamiento de recursos en cola, puede tardar hasta cinco minutos en completarse, en función del tamaño del recurso en cola. Espera hasta que el recurso en cola esté en el estado
ACTIVE. Puedes consultar el estado de una solicitud de recurso en cola mediante la CLI de gcloud o la consola de Google Cloud :gcloud
$ gcloud compute tpus queued-resources list \ --filter=${QR_ID} --zone=${ZONE} --project=${PROJECT}
Debería generar un resultado similar al siguiente:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central2-b 4 v5litepod-16 ACTIVE ...
Consola
En la Google Cloud consola, ve a la página TPUs:
Haz clic en la pestaña Recursos en cola.
Haga clic en el nombre de la solicitud de recurso en cola.
Ponte en contacto con tu Google Cloud representante de cuentas si el estado del código QR es
WAITING_FOR_RESOURCESoPROVISIONINGdurante más de 15 minutos.Instala las dependencias.
$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="bash setup.sh"
Ejecuta
shardings.pyen cada trabajador conmultihost_runner.py.$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="python3 -m pedagogical_examples.shardings \ --dcn_data_parallelism ${SLICE_COUNT} \ --ici_fsdp_parallelism 16 \ --batch_size 131072 \ --embedding_dimension 2048"
Verás aproximadamente 230 TFLOPS por segundo de rendimiento en los archivos de registro.
Para obtener más información sobre cómo configurar el paralelismo, consulta Fragmentación de varias porciones mediante el paralelismo de DCN y
shardings.py.Limpia las TPUs y los recursos en cola cuando hayas terminado. El proceso de eliminación tardará entre dos y cinco minutos en completarse. Si usas la CLI de gcloud, puedes ejecutar este comando en segundo plano con la marca opcional
--async.- Usa jax.experimental.mesh_utils.create_hybrid_device_mesh en lugar de jax.experimental.mesh_utils.create_device_mesh al crear tu malla.
- Con la secuencia de comandos del ejecutor de experimentos,
multihost_runner.py - Con la secuencia de comandos del runner de producción,
multihost_job.py - Usar un método manual
Crea una solicitud de recurso en cola con el siguiente comando:
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --project=${PROJECT} \ --zone=${ZONE} \ --node-count=${SLICE_COUNT} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --network=${NETWORK_NAME} \ --subnetwork=${SUBNETWORK_NAME} \ --tags=${EXAMPLE_TAG_1},${EXAMPLE_TAG_2} \ --metadata=startup-script="${STARTUP_SCRIPT}" \ [--reserved|--spot]
Crea un archivo llamado
queued-resource-req.jsony copia el siguiente JSON en él.{ "guaranteed": { "reserved": true }, "tpu": { "node_spec": [ { "parent": "projects/your-project-number/locations/your-zone", "node": { "accelerator_type": "accelerator-type", "runtime_version": "tpu-vm-runtime-version", "network_config": { "network": "your-network-name", "subnetwork": "your-subnetwork-name", "enable_external_ips": true }, "tags" : ["example-tag-1"] "metadata": { "startup-script": "your-startup-script" } }, "multi_node_params": { "node_count": slice-count, "node_id_prefix": "your-queued-resource-id" } } ] } }
Sustituye los siguientes valores:
- your-project-number - Número de proyecto Google Cloud
- your-zone: la zona en la que quieres crear el recurso en cola.
- accelerator-type: versión y tamaño de un solo segmento. Multislice solo se admite en la versión 4 de TPU de Cloud y en versiones posteriores.
- tpu-vm-runtime-version: la versión del entorno de ejecución de la VM de TPU que quieras usar.
- your-network-name - Opcional, una red a la que se adjuntará el recurso en cola
- your-subnetwork-name: es opcional y se trata de una subred a la que se adjuntará el recurso en cola.
- example-tag-1: cadena de etiqueta arbitraria opcional.
- your-startup-script: secuencia de comandos de inicio que se ejecutará cuando se asigne el recurso en cola.
- slice-count: número de slices de TPU de tu entorno Multislice.
- your-queued-resource-id: ID que ha proporcionado el usuario para el recurso en cola.
Para obtener más información, consulta la documentación de la API REST Queued Resource, donde se describen todas las opciones disponibles.
Para usar la capacidad de Spot, sustituye lo siguiente:
"guaranteed": { "reserved": true }con"spot": {}Quita la línea para usar la capacidad bajo demanda predeterminada.
Envía la solicitud de creación de recursos en cola con la carga útil de JSON:
$ curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d @queuedresourcereq.json \ https://tpu.googleapis.com/v2alpha1/projects/your-project-id/locations/your-zone/queuedResources\?queued_resource_id\=your-queued-resource-id
Sustituye los siguientes valores:
- your-project-id: tu ID de proyecto Google Cloud
- your-zone: la zona en la que quieres crear el recurso en cola.
- your-queued-resource-id: ID que ha proporcionado el usuario para el recurso en cola.
En la Google Cloud consola, ve a la página TPUs:
Haz clic en Crear TPU.
En el campo Name (Nombre), introduce un nombre para tu TPU.
En el cuadro Zona, selecciona la zona en la que quieras crear la TPU.
En el cuadro Tipo de TPU, selecciona un tipo de acelerador. El tipo de acelerador especifica la versión y el tamaño de la TPU de Cloud que quieres crear. Multislice solo se admite en la versión 4 de TPU de Cloud y en versiones posteriores. Para obtener más información sobre los tipos de aceleradores compatibles con cada versión de TPU, consulta Versiones de TPU.
En el cuadro Versión de software de la TPU, selecciona una versión de software. Al crear una máquina virtual de TPU de Cloud, la versión del software de TPU especifica la versión del tiempo de ejecución de TPU que se va a instalar. Para obtener más información, consulta Versiones de software de TPU.
Haz clic en el interruptor Habilitar colas.
En el campo Queued resource name (Nombre del recurso en cola), introduce un nombre para tu solicitud de recurso en cola.
Marca la casilla Convertir en TPU Multislice.
En el campo Número de porciones, introduce el número de porciones que quieras crear.
Haz clic en Crear para crear tu solicitud de recurso en cola.
En la Google Cloud consola, ve a la página TPUs:
Haz clic en la pestaña Recursos en cola.
Haga clic en el nombre de la solicitud de recurso en cola.
En la Google Cloud consola, ve a la página TPUs:
Haz clic en la pestaña Recursos en cola.
En la Google Cloud consola, ve a la página TPUs:
Haz clic en la pestaña Recursos en cola.
Seleccione la casilla situada junto a la solicitud de recursos en cola.
Haz clic en Eliminar.
- B es el tamaño del lote en tokens
- P es el número de parámetros
- Se produce una "burbuja de la canalización" en la que los chips están inactivos porque están esperando datos.
- Requiere micro-lotes, lo que reduce el tamaño de lote efectivo, la intensidad aritmética y, en última instancia, la utilización de FLOPs del modelo.
Para usar Multislice, tus recursos de TPU deben gestionarse como recursos en cola.
Ejemplo introductorio
En este tutorial se usa código del repositorio de GitHub MaxText. MaxText es un LLM básico de alto rendimiento, escalable de forma arbitraria, de código abierto y bien probado escrito en Python y Jax. MaxText se ha diseñado para entrenar de forma eficiente en las TPU de Cloud.
El código de shardings.py
se ha diseñado para ayudarte a empezar a experimentar con diferentes opciones de paralelismo. Por ejemplo, el paralelismo de datos, el paralelismo de datos totalmente fragmentado (FSDP) y el paralelismo de tensores. El código se adapta a entornos de una sola porción y de varias porciones.
Paralelismo de ICI
ICI hace referencia a la interconexión de alta velocidad que conecta las TPUs de un mismo slice. La fragmentación de ICI se corresponde con la fragmentación dentro de un segmento. shardings.py
proporciona tres parámetros de paralelismo de ICI:
Los valores que especifiques para estos parámetros determinan el número de particiones de cada método de paralelismo.
Estas entradas deben estar restringidas de forma que ici_data_parallelism * ici_fsdp_parallelism * ici_tensor_parallelism sea igual al número de chips del segmento.
En la siguiente tabla se muestran ejemplos de entradas de usuario para el paralelismo de ICI de los cuatro chips disponibles en la versión 4-8:
| ici_data_parallelism | ici_fsdp_parallelism | ici_tensor_parallelism | |
| FSDP de 4 vías | 1 | 4 | 1 |
| Paralelismo de tensores de cuatro dimensiones | 1 | 1 | 4 |
| FSDP bidireccional + paralelismo de tensores bidireccional | 1 | 2 | 2 |
Ten en cuenta que, en la mayoría de los casos, ici_data_parallelism debe ser 1, ya que la red ICI es lo suficientemente rápida como para preferir casi siempre FSDP al paralelismo de datos.
En este ejemplo, se da por hecho que sabes cómo ejecutar código en un solo sector de TPU, como se explica en el artículo Ejecutar un cálculo en una VM de TPU de Cloud con JAX.
En este ejemplo se muestra cómo ejecutar shardings.py en una sola porción.
Fragmentación de varias porciones mediante el paralelismo de DCN
La secuencia de comandos shardings.py usa tres parámetros que especifican el paralelismo de DCN, que corresponde al número de particiones de cada tipo de paralelismo de datos:
Los valores de estos parámetros deben estar restringidos de forma que dcn_data_parallelism * dcn_fsdp_parallelism * dcn_tensor_parallelism sea igual al número de porciones.
Por ejemplo, para dos porciones, usa --dcn_data_parallelism = 2.
| dcn_data_parallelism | dcn_fsdp_parallelism | dcn_tensor_parallelism | Número de porciones | |
| Paralelismo de datos bidireccional | 2 | 1 | 1 | 2 |
dcn_tensor_parallelism siempre debe tener el valor 1, ya que la DCN no es adecuada para este tipo de fragmentación. En el caso de las cargas de trabajo típicas de LLMs en chips v4, dcn_fsdp_parallelism también debe definirse como 1 y, por lo tanto, dcn_data_parallelism debe definirse como el número de slices, pero esto depende de la aplicación.
Si aumentas el número de segmentos (suponiendo que mantienes constantes el tamaño del segmento y el tamaño del lote por segmento), aumentará el paralelismo de datos.
Ejecutar shardings.py en un entorno Multislice
Puedes ejecutar shardings.py en un entorno de varios segmentos con multihost_runner.py o ejecutando shardings.py en cada VM de TPU. Aquí usamos multihost_runner.py. Los pasos siguientes son muy similares a los que se indican en Getting Started: Quick Experiments on Multiple slices (Empezar: experimentos rápidos en varios segmentos) del repositorio MaxText, excepto que aquí ejecutamos shardings.py en lugar del LLM más complejo de train.py.
La herramienta multihost_runner.py se ha optimizado para realizar experimentos rápidos y reutilizar las mismas TPUs repetidamente. Como la secuencia de comandos multihost_runner.py depende de conexiones SSH de larga duración, no se recomienda para tareas de larga duración.
Si quieres ejecutar un trabajo más largo (por ejemplo, de horas o días), te recomendamos que uses multihost_job.py.
En este tutorial, usamos el término runner para indicar la máquina en la que ejecutas la secuencia de comandos multihost_runner.py. Usamos el término trabajadores para referirnos a las VMs de TPU que componen tus slices. Puedes ejecutar multihost_runner.py en una máquina local o en cualquier máquina virtual de Compute Engine que esté en el mismo proyecto que tus segmentos. No se admite ejecutar multihost_runner.py en un trabajador.
multihost_runner.py se conecta automáticamente a los trabajadores de TPU mediante SSH.
En este ejemplo, ejecutas shardings.py en dos porciones de v5e-16, lo que supone un total de cuatro máquinas virtuales y 16 chips de TPU. Puedes modificar el ejemplo para que se ejecute en más TPUs.
Configurar un entorno
Escalar una carga de trabajo a Multislice
Antes de ejecutar el modelo en un entorno de Multislice, haz los siguientes cambios en el código:
Estos deberían ser los únicos cambios de código necesarios al pasar a Multislice. Para conseguir un alto rendimiento, la DCN debe asignarse a ejes paralelos de datos, paralelos de datos totalmente fragmentados o paralelos de canalización. Las consideraciones sobre el rendimiento y las estrategias de partición se explican con más detalle en el artículo Partición con multirebanado para obtener el máximo rendimiento.
Para validar que tu código puede acceder a todos los dispositivos, puedes afirmar que len(jax.devices()) es igual al número de chips de tu entorno Multislice. Por ejemplo, si usas cuatro porciones de v4-16, tienes ocho patatas fritas por porción * 4 porciones, por lo que len(jax.devices()) debería devolver 32.
Elegir tamaños de segmento para entornos Multislice
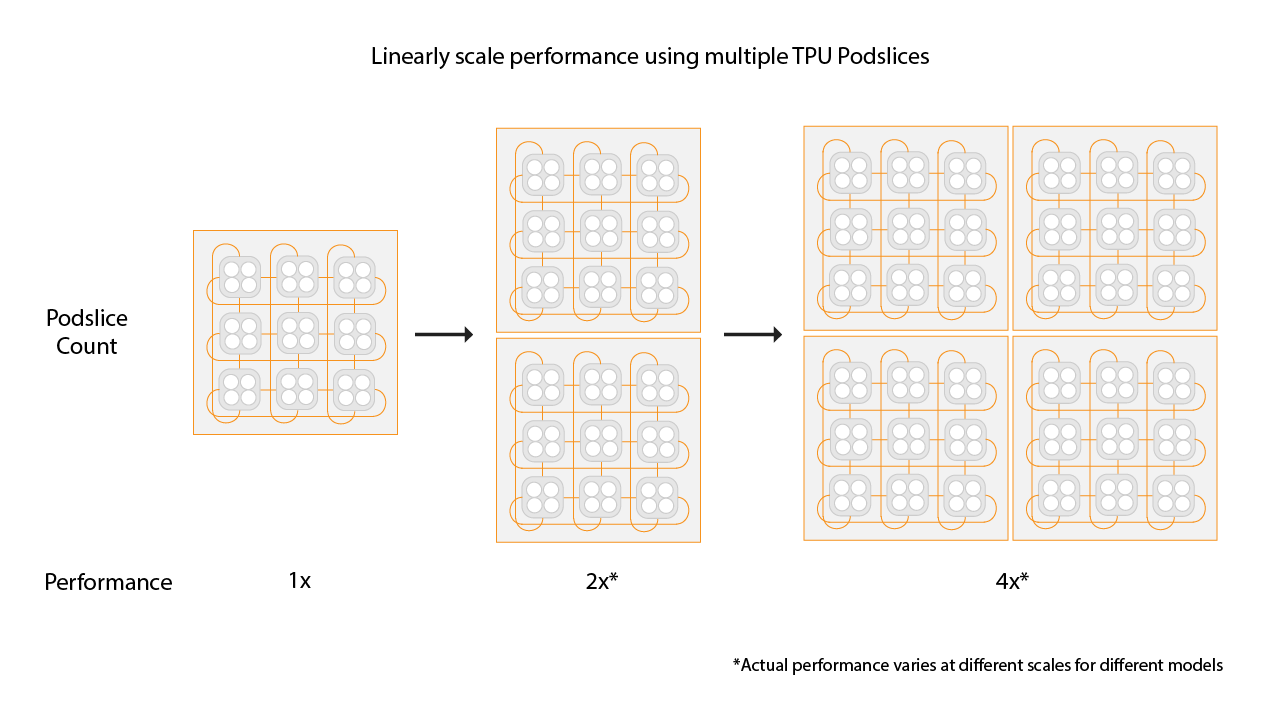
Para conseguir una aceleración lineal, añade nuevas porciones del mismo tamaño que la porción que ya tienes. Por ejemplo, si usas un segmento v4-512, Multislice conseguirá aproximadamente el doble de rendimiento añadiendo un segundo segmento v4-512 y duplicando el tamaño de lote global. Para obtener más información, consulta Sharding con Multislice para conseguir el máximo rendimiento.
Ejecutar un trabajo en varios segmentos
Hay tres enfoques diferentes para ejecutar tu carga de trabajo personalizada en un entorno de Multislice:
Secuencia de comandos de ejecución de experimentos
La secuencia de comandos multihost_runner.py
distribuye el código a un entorno de Multislice y ejecuta
el comando en cada host, copia los registros y monitoriza el estado de error de cada comando. La secuencia de comandos multihost_runner.py se describe en el archivo LÉAME de MaxText.
Como multihost_runner.py mantiene conexiones SSH persistentes, solo es adecuado para experimentos de tamaño moderado y duración relativamente corta. Puedes adaptar los pasos del multihost_runner.pytutorial
a tu carga de trabajo y configuración de hardware.
Secuencia de comandos de ejecución de producción
En el caso de los trabajos de producción que necesiten resistencia frente a fallos de hardware y otras suspensiones, lo mejor es integrar directamente la API Create Queued Resource. Usa multihost_job.py como ejemplo práctico
que activa la llamada a la API de recursos en cola creados con la secuencia de comandos de inicio adecuada para ejecutar el entrenamiento y reanudarlo en caso de expropiación. El script multihost_job.py
se describe en el
README de MaxText.
Como multihost_job.py debe aprovisionar recursos para cada ejecución, no proporciona un ciclo de iteración tan rápido como multihost_runner.py.
Método manual
Te recomendamos que uses o adaptes multihost_runner.py o multihost_job.py para ejecutar tu carga de trabajo personalizada en tu configuración de Multislice. Sin embargo, si prefieres aprovisionar y gestionar tu entorno directamente con comandos QR, consulta Gestionar un entorno Multislice.
Gestionar un entorno de Multislice
Para aprovisionar y gestionar manualmente los QRs sin usar las herramientas proporcionadas en el repositorio MaxText, consulta las siguientes secciones.
Crear recursos en cola
gcloud
Asegúrate de que tienes la cuota correspondiente antes de seleccionar --reserved,
--spot o la cuota predeterminada bajo demanda. Para obtener información sobre los tipos de cuotas, consulta la política de cuotas.
curl
La respuesta debería tener el siguiente aspecto:
{ "name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qr-guid>", "metadata": { "@type": "type.googleapis.com/google.cloud.common.OperationMetadata", "createTime": "2023-11-01T00:17:05.742546311Z", "target": "projects/<your-project-id>/locations/<your-zone>/queuedResources/<your-qa-id>", "verb": "create", "cancelRequested": false, "apiVersion": "v2alpha1" }, "done": false }
Use el valor GUID al final del valor de cadena del atributo name para obtener información sobre la solicitud de recursos en cola.
Consola
Recuperar el estado de un recurso en cola
gcloud
$ gcloud compute tpus queued-resources describe ${QR_ID} --zone=${ZONE}
En el caso de un recurso en cola que se encuentra en el estado ACTIVE, el resultado es similar al siguiente:
...
state:
state: ACTIVE
...
curl
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/queuedResources/${YOUR_QR_ID}
En el caso de un recurso en cola que se encuentra en el estado ACTIVE, el resultado es similar al siguiente:
{
"name": your-queued-res,
"tpu": {
"nodeSpec": [
{
... // node 1
},
{
... // node 2
},
...
]
},
...
"state": "ACTIVE"
}
Consola
Una vez que se haya aprovisionado tu TPU, también puedes ver los detalles de tu solicitud de recurso en cola. Para ello, ve a la página TPUs (TPUs), busca tu TPU y haz clic en el nombre de la solicitud de recurso en cola correspondiente.
En un caso excepcional, es posible que el recurso en cola esté en estado FAILED mientras que algunos segmentos estén en estado ACTIVE. Si esto ocurre, elimina los recursos que se hayan creado y vuelve a intentarlo en unos minutos o ponte en contacto con el Google Cloud equipo de Asistencia.
Conéctate por SSH e instala las dependencias
En Ejecutar código JAX en sectores de TPU se describe cómo conectarse a las máquinas virtuales de TPU mediante SSH en un solo sector. Para conectarte a todas las máquinas virtuales de TPU de tu entorno Multislice a través de SSH e instalar las dependencias, usa el siguiente comando gcloud:
$ gcloud compute tpus queued-resources ssh ${QR_ID} \ --zone=${ZONE} \ --node=all \ --worker=all \ --command="command-to-run" \ --batch-size=4
Este comando gcloud envía el comando especificado a todos los workers y nodos de
QR mediante SSH. El comando se agrupa en lotes de cuatro y se envía simultáneamente. El siguiente lote de comandos se envía cuando se completa la ejecución del lote actual. Si se produce un error con uno de los comandos, se detiene el procesamiento y no se envían más lotes. Para obtener más información, consulta la referencia de la API de recursos en cola.
Si el número de segmentos que utilizas supera el límite de subprocesos de tu ordenador local (también llamado límite de procesamiento por lotes), se producirá un interbloqueo. Por ejemplo, supongamos que el límite de procesamiento por lotes de tu máquina local es 64. Si intentas ejecutar una secuencia de comandos de entrenamiento en más de 64 segmentos (por ejemplo, 100), el comando SSH dividirá los segmentos en lotes. Ejecutará la secuencia de comandos de entrenamiento en el primer lote de 64 segmentos y esperará a que se complete antes de ejecutarla en el lote restante de 36 segmentos. Sin embargo, el primer lote de 64 segmentos no puede completarse hasta que los 36 segmentos restantes empiecen a ejecutar la secuencia de comandos, lo que provoca un bloqueo.
Para evitar que se produzca esta situación, puedes ejecutar la secuencia de comandos de entrenamiento en segundo plano en cada VM añadiendo una ampersand (&) al comando de la secuencia de comandos que especifiques con la marca --command. Cuando lo hagas, después de iniciar la secuencia de comandos de entrenamiento en el primer lote de segmentos, el control volverá inmediatamente al comando SSH. El comando SSH puede empezar a ejecutar la secuencia de comandos de entrenamiento en el lote restante de 36 segmentos. Deberás canalizar tus flujos stdout y stderr
de forma adecuada al ejecutar los comandos en segundo plano. Para aumentar el paralelismo en el mismo QR, puede seleccionar segmentos específicos con el parámetro --node.
Configuración de red
Para asegurarte de que las porciones de TPU pueden comunicarse entre sí, sigue estos pasos.
Instala JAX en cada una de las porciones. Para obtener más información, consulta el artículo Ejecutar código JAX en sectores de TPUs. Afirma que len(jax.devices()) es igual al número de chips de tu entorno Multislice. Para ello, ejecuta lo siguiente en cada segmento:
$ python3 -c 'import jax; print(jax.devices())'
Si ejecutas este código en cuatro porciones de v4-16, habrá ocho chips por porción y cuatro porciones, por lo que jax.devices() debería devolver un total de 32 chips (dispositivos).
Mostrar recursos en cola
gcloud
Puedes ver el estado de los recursos en cola con el comando queued-resources list:
$ gcloud compute tpus queued-resources list --zone=${ZONE}
El resultado es similar al siguiente:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central1-a 4 v5litepod-16 ACTIVE ...
Consola
Iniciar un trabajo en un entorno aprovisionado
Puedes ejecutar manualmente las cargas de trabajo conectándote a todos los hosts de cada segmento a través de SSH y ejecutando el siguiente comando en todos los hosts.
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone=${ZONE} \ --worker=all \ --command="command-to-run"
Restablecer QRs
La API ResetQueuedResource se puede usar para restablecer todas las máquinas virtuales de un ACTIVE QR. Si restableces las VMs, se borrará por la fuerza la memoria de la máquina y se restablecerá el estado inicial de la VM. Los datos almacenados localmente permanecerán intactos y la secuencia de comandos de inicio se invocará después de restablecer el dispositivo. La API ResetQueuedResource puede ser útil cuando quieras reiniciar todas las TPUs. Por ejemplo, cuando el entrenamiento se bloquea y es más fácil restablecer todas las VMs que depurar.
Los reinicios de todas las máquinas virtuales se realizan en paralelo y una ResetQueuedResource
operación tarda entre uno y dos minutos en completarse. Para invocar la API, usa el siguiente comando:
$ gcloud compute tpus queued-resources reset ${QR_ID} --zone=${ZONE}
Eliminar recursos en cola
Para liberar recursos al final de la sesión de entrenamiento, elimina el recurso en cola. El proceso de eliminación tardará entre dos y cinco minutos en completarse. Si usas la CLI de gcloud, puedes ejecutar este comando en segundo plano con la marca opcional --async.
gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --zone=${ZONE} --force [--async]
Consola
Recuperación automática tras fallos
En caso de interrupción, Multislice ofrece una reparación sin intervención de la porción afectada y restablece todas las porciones después. La porción afectada se sustituye por una nueva y las porciones restantes que no se han visto afectadas se restablecen. Si no hay capacidad disponible para asignar una porción de sustitución, se detendrá el entrenamiento.
Para reanudar el entrenamiento automáticamente después de una interrupción, debes especificar un script de inicio que compruebe y cargue los últimos puntos de control guardados. La secuencia de comandos de inicio se ejecuta automáticamente cada vez que se reasigna una porción o se reinicia una VM. Puedes especificar una secuencia de comandos de inicio en la carga útil JSON que envías a la API de solicitud de creación de QR.
La siguiente secuencia de comandos de inicio (que se usa en Crear QRs) te permite recuperarte automáticamente de los errores y reanudar el entrenamiento a partir de los puntos de control almacenados en un segmento de Cloud Storage durante el entrenamiento de MaxText:
{
"tpu": {
"node_spec": [
{
...
"metadata": {
"startup-script": "#! /bin/bash \n pwd \n runuser -l user1 -c 'cd /home/user1/MaxText && python3 -m MaxText.train MaxText/configs/base.yml run_name=run_test_failure_recovery dcn_data_parallelism=4 ici_fsdp_parallelism=8 steps=10000 save_period=10 base_output_directory='gs://user1-us-central2'' EOF"
}
...
}
]
}
}
Clona el repositorio MaxText antes de probarlo.
Elaboración de perfiles y depuración
El perfilado es el mismo en entornos de una sola porción y de varias porciones. Para obtener más información, consulta Crear perfiles de programas JAX.
Optimiza la formación
En las siguientes secciones se describe cómo optimizar el entrenamiento de Multislice.
Partición con Multislice para obtener el máximo rendimiento
Para conseguir el máximo rendimiento en entornos de Multislice, es necesario tener en cuenta cómo fragmentar los datos en los distintos slices. Normalmente, hay tres opciones (paralelismo de datos, paralelismo de datos totalmente fragmentados y paralelismo de la canalización). No recomendamos fragmentar las activaciones en las dimensiones del modelo (a veces se denomina paralelismo de tensores) porque requiere demasiado ancho de banda entre fragmentos. En todas estas estrategias, puedes mantener la misma estrategia de fragmentación en una porción que te haya funcionado en el pasado.
Te recomendamos que empieces con el paralelismo de datos puro. Usar el paralelismo de datos totalmente fragmentados es útil para liberar memoria. El inconveniente es que la comunicación entre las porciones usa la red DCN y ralentizará tu carga de trabajo. Usa el paralelismo de la canalización solo cuando sea necesario en función del tamaño del lote (como se analiza más abajo).
Cuándo usar el paralelismo de datos
El paralelismo de datos puro funcionará bien en los casos en los que tengas una carga de trabajo que funcione bien, pero quieras mejorar su rendimiento escalando en varias porciones.
Para conseguir un escalado eficaz en varias porciones, el tiempo necesario para realizar la operación de reducción total en DCN debe ser inferior al tiempo necesario para realizar un pase hacia atrás. DCN se usa para la comunicación entre slices y es un factor limitante en el rendimiento de las cargas de trabajo.
Cada chip de TPU v4 tiene un rendimiento máximo de 275 * 1012 FLOPS por segundo.
Cada host de TPU tiene cuatro chips y un ancho de banda de red máximo de 50 Gbps.
Esto significa que la intensidad aritmética es 4 * 275 * 1012 FLOPS / 50 Gbps = 22.000 FLOPS/bit.
Tu modelo usará entre 32 y 64 bits de ancho de banda de DCN por cada parámetro y paso. Si usas dos slices, tu modelo usará 32 bits de ancho de banda de DCN. Si usas más de dos segmentos, el compilador realizará una operación de reducción total con barajado completo y utilizarás hasta 64 bits de ancho de banda de DCN por cada parámetro y paso. La cantidad de FLOPS necesaria para cada parámetro variará en función de tu modelo. En concreto, en los modelos de lenguaje basados en transformadores, el número de FLOPS necesarios para una pasada hacia delante y otra hacia atrás es aproximadamente 6 * B * P, donde:
El número de FLOPS por parámetro es 6 * B y el número de FLOPS por parámetro durante el pase hacia atrás es 4 * B.
Para asegurar un escalado sólido en varias porciones, asegúrate de que la intensidad operativa supere la intensidad aritmética del hardware de la TPU. Para calcular la intensidad operativa, divide el número de FLOPS por parámetro durante el pase hacia atrás entre el ancho de banda de la red (en bits) por parámetro por paso:
Operational Intensity = FLOPSbackwards_pass / DCN bandwidth
Por lo tanto, en un modelo de lenguaje basado en Transformer, si usas dos segmentos:
Operational intensity = 4 * B / 32
Si usas más de dos porciones: Operational intensity = 4 * B/64
Esto sugiere un tamaño de lote mínimo de entre 176.000 y 352.000 para los modelos de lenguaje basados en Transformer. Como la red DCN puede perder paquetes brevemente, es mejor mantener un margen de error significativo y desplegar el paralelismo de datos solo si el tamaño del lote por pod es de al menos 350.000 (dos pods) a 700.000 (muchos pods).
En el caso de otras arquitecturas de modelos, tendrás que estimar el tiempo de ejecución de tu pase hacia atrás por segmento (ya sea cronometrándolo con un generador de perfiles o contando las FLOPS). Después, puedes comparar ese tiempo con el tiempo de ejecución esperado para reducir la sobrecarga de la DCN y hacerte una idea de si el paralelismo de datos te resultará útil.
Cuándo usar el paralelismo de datos totalmente fragmentado (FSDP)
El paralelismo de datos totalmente fragmentado (FSDP) combina el paralelismo de datos (fragmentación de los datos entre nodos) con la fragmentación de los pesos entre nodos. En cada operación de las pasadas hacia delante y hacia atrás, se recogen todos los pesos para que cada segmento tenga los pesos que necesita. En lugar de sincronizar los gradientes mediante la reducción total, los gradientes se dispersan a medida que se producen. De esta forma, cada segmento solo obtiene los gradientes de los pesos de los que es responsable.
Al igual que el paralelismo de datos, FSDP requerirá que el tamaño de lote global se escale de forma lineal con el número de segmentos. FSDP reducirá la presión de memoria a medida que aumentes el número de segmentos. Esto se debe a que el número de pesos y el estado del optimizador por segmento disminuyen, pero a costa de un mayor tráfico de red y una mayor posibilidad de bloqueo debido a un colectivo retrasado.
En la práctica, el FSDP en los slices es la mejor opción si aumentas el tamaño de lote por slice, almacenas más activaciones para minimizar la rematerialización durante el pase hacia atrás o aumentas el número de parámetros de tu red neuronal.
Las operaciones de recogida y reducción completas de FSDP funcionan de forma similar a las de DP, por lo que puedes determinar si la carga de trabajo de FSDP está limitada por el rendimiento de DCN de la misma forma que se describe en la sección anterior.
Cuándo usar el paralelismo de la fase
El paralelismo de la canalización se vuelve relevante cuando se consigue un alto rendimiento con otras estrategias de paralelismo que requieren un tamaño de lote global superior al tamaño de lote máximo preferido. El paralelismo de la canalización permite que las porciones que componen una canalización compartan un lote. Sin embargo, el paralelismo de la canalización tiene dos desventajas importantes:
El paralelismo de la canalización solo debe usarse si las otras estrategias de paralelismo requieren un tamaño de lote global demasiado grande. Antes de probar el paralelismo de la canalización, merece la pena experimentar para ver empíricamente si la convergencia por muestra se ralentiza con el tamaño de lote necesario para conseguir un FSDP de alto rendimiento. FSDP tiende a conseguir una mayor utilización de FLOP del modelo, pero si la convergencia por muestra se ralentiza a medida que aumenta el tamaño del lote, el paralelismo de la canalización puede seguir siendo la mejor opción. La mayoría de las cargas de trabajo pueden tolerar tamaños de lote suficientemente grandes para no beneficiarse del paralelismo de la canalización, pero tu carga de trabajo puede ser diferente.
Si es necesario el paralelismo de la canalización, recomendamos combinarlo con el paralelismo de datos o FSDP. De esta forma, podrás minimizar la profundidad de la canalización y, al mismo tiempo, aumentar el tamaño del lote por canalización hasta que la latencia de DCN deje de ser un factor importante en el rendimiento. En concreto, si tienes N segmentos, considera las canalizaciones de profundidad 2 y N/2 réplicas de paralelismo de datos, luego las canalizaciones de profundidad 4 y N/4 réplicas de paralelismo de datos, y así sucesivamente, hasta que el lote por canalización sea lo suficientemente grande como para que los colectivos de DCN se puedan ocultar tras la aritmética en el pase hacia atrás. De esta forma, se minimizará la ralentización que introduce el paralelismo de la canalización y, al mismo tiempo, podrás superar el límite de tamaño de lote global.
Prácticas recomendadas para usar la función de multirebanado
En las siguientes secciones se describen las prácticas recomendadas para el entrenamiento de Multislice.
Carga de datos
Durante el entrenamiento, cargamos repetidamente lotes de un conjunto de datos para introducirlos en el modelo. Es importante tener un cargador de datos asíncrono y eficiente que fragmenta el lote en varios hosts para evitar que las TPUs se queden sin trabajo. El cargador de datos actual de MaxText hace que cada host cargue un subconjunto de ejemplos igual. Esta solución es adecuada para el texto, pero requiere un reshard en el modelo. Además, MaxText aún no ofrece la creación de instantáneas deterministas, lo que permitiría que el iterador de datos cargara los mismos datos antes y después de la expropiación.
Creación de puntos de control
La biblioteca de puntos de control Orbax proporciona primitivas para crear puntos de control de JAX PyTrees en el almacenamiento local o en el almacenamiento de Google Cloud .
Proporcionamos una integración de referencia con el registro de puntos de control síncrono en MaxText en checkpointing.py.
Configuraciones admitidas
En las siguientes secciones se describen las formas de las porciones, la orquestación, los frameworks y el paralelismo admitidos en Multislice.
Formas
Todas las porciones deben tener la misma forma (por ejemplo, el mismo AcceleratorType).
No se admiten porciones con formas diferentes.
Orquestación
La orquestación es compatible con GKE. Para obtener más información, consulta TPUs en GKE.
Frameworks
Multislice solo admite cargas de trabajo de JAX y PyTorch.
Paralelismo
Recomendamos que los usuarios prueben Multislice con paralelismo de datos. Para obtener más información sobre cómo implementar el paralelismo de la canalización con Multislice, ponte en contacto con tuGoogle Cloud representante de cuentas.
Asistencia y comentarios
Agradecemos todos los comentarios. Para enviarnos comentarios o solicitar asistencia, ponte en contacto con nosotros a través del formulario de asistencia o de comentarios de Cloud TPU.