Einführung in Cloud TPU
Tensor Processing Units (TPUs) sind speziell von Google entwickelte anwendungsspezifische Integrierte Schaltungen (ASICs), die verwendet werden, um Arbeitslasten beim maschinellen Lernen zu beschleunigen. Weitere Informationen zu TPU-Hardware finden Sie unter Systemarchitektur. Cloud TPU ist ein Webdienst, der TPUs als skalierbare Rechenressourcen in Google Cloud zur Verfügung stellt.
TPUs trainieren Ihre Modelle effizienter mit Hardware, die für die Ausführung großer Matrixvorgänge entwickelt wurde, die oft in Algorithmen für maschinelles Lernen verwendet werden. TPUs haben On-Chip-Speicher mit hoher Bandbreite (HBM), mit dem Sie größere Modelle und Batch- Größen. TPUs können in Gruppen verbunden werden, die als Pods bezeichnet werden und die Ihnen das Skalieren Ihrer Arbeitslasten mit wenig oder ohne Codeänderungen ermöglichen.
Funktionsweise
Damit Sie verstehen, wie TPUs funktionieren, sollten Sie wissen, wie andere Beschleuniger die Rechenaufgaben beim Trainieren von ML-Modellen bewältigen.
Funktionsweise einer CPU
Eine CPU ist ein Universalprozessor, der auf der Von-Neumann-Architektur basiert. Das bedeutet, dass eine CPU mit Software und Speicher arbeitet, wie hier gezeigt:
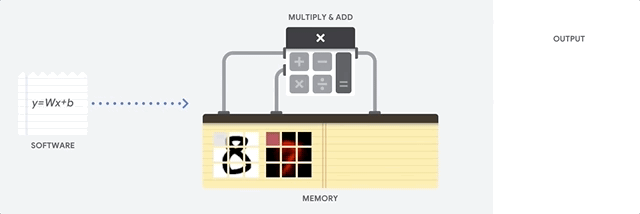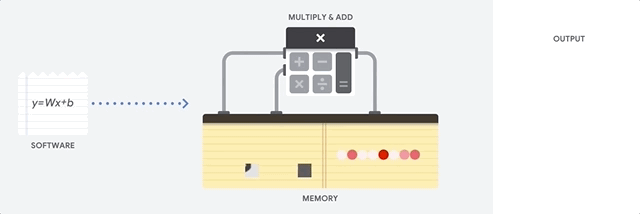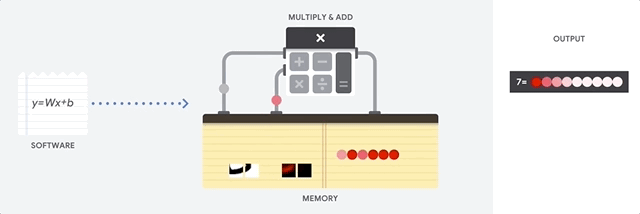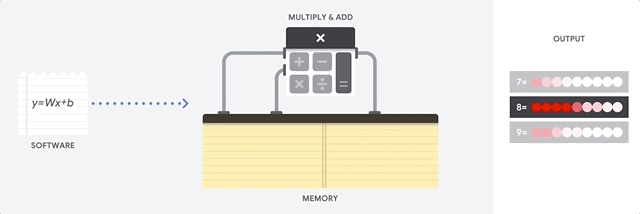
Der größte Vorteil von CPUs ist ihre Flexibilität. Sie können jede Art von Software auf einer CPU für viele verschiedene Arten von Anwendungen laden. Sie können beispielsweise eine CPU auf einem PC für die Textverarbeitung verwenden, Raketentriebwerke steuern, Banktransaktionen tätigen oder Bilder mit einem neuronalen Netzwerk klassifizieren.
Eine CPU lädt Werte aus dem Arbeitsspeicher, führt eine Berechnung der Werte durch und speichert das Ergebnis jeder Berechnung wieder im Arbeitsspeicher. Langsamer Arbeitsspeicherzugriff im Vergleich zur Berechnungsgeschwindigkeit und kann den Gesamtdurchsatz der CPUs begrenzen. Dies wird oft als Von-Neumann-Engpass bezeichnet.
Funktionsweise einer GPU
GPUs bieten Tausende arithmetisch-logische Einheiten (Arithmetic Logic Units, ALUs) in einem einzigen Prozessor, um einen höheren Durchsatz zu erzielen. Eine moderne GPU enthält in der Regel zwischen 2.500 und 5.000 ALUs. Dank der großen Anzahl von Prozessoren können Sie Tausende von Multiplikationen ausführen und Ergänzungen gleichzeitig.

Eine GPU-Architektur eignet sich gut für Anwendungen mit massiver Parallelität, z. B. Matrixvorgänge in einem neuronalen Netz. Im Vergleich zu einer CPU liefert eine GPU für eine typische Deep-Learning-Trainingsarbeitslast einen um Größenordnungen höheren Durchsatz.
Die GPU ist jedoch ein Allzweckprozessor, der viele verschiedene Anwendungen und Software. Daher haben GPUs das gleiche Problem wie CPUs. Für jede Berechnung in den Tausenden von ALUs muss eine GPU auf Register oder gemeinsam genutzten Arbeitsspeicher zugreifen, um Operanden zu lesen und Zwischenergebnisse von Berechnungen zu speichern.
Funktionsweise einer TPU
Google hat Cloud TPUs als Matrixprozessoren konzipiert, die auf Arbeitslasten für neuronale Netze spezialisiert sind. TPUs können keine Textverarbeitungsprogramme ausführen, keine Raketentriebwerke steuern Banktransaktionen, können aber riesige Matrixoperationen in neuronalen Netzwerke mit hoher Geschwindigkeit.
Die Hauptaufgabe für TPUs ist die Matrixverarbeitung, bei der es sich um eine Kombination von Multiplikations- und Akkumulationsvorgängen handelt. TPUs enthalten Tausende von Multiplikationsakkumulatoren, die direkt miteinander verbunden sind, um eine große physische Matrix zu bilden. Dies wird als systolische Arrayarchitektur bezeichnet. Cloud TPU v3, die zwei systolische Arrays 128 × 128 ALUs auf einem einzigen Prozessor.
Der TPU-Host streamt Daten in eine Einspeisewarteschlange. Die TPU lädt Daten aus der Einspeisewarteschlange und speichert sie im HBM-Arbeitsspeicher. Wenn die Berechnung abgeschlossen ist, lädt die TPU die Ergebnisse in die Ausspeisewarteschlange. Der TPU-Host liest dann die Ergebnisse aus der Ausspeisewarteschlange und speichert sie im Arbeitsspeicher des Hosts.
Zur Durchführung der Matrixvorgänge lädt die TPU die Parameter aus dem HBM-Speicher. in die Matrixmultiplikationseinheit (MXU) übertragen.

Dann lädt die TPU die Daten aus dem HBM-Speicher. Wenn eine Multiplikation ausgeführt wird, wird das Ergebnis an den nächsten Multiplikations-Akkumulator weitergeleitet. Die Ausgabe ist die Summe aller Multiplikationsergebnisse zwischen den Daten und Parametern. Während des Prozesses der Matrixmultiplikation ist kein Speicherzugriff erforderlich.
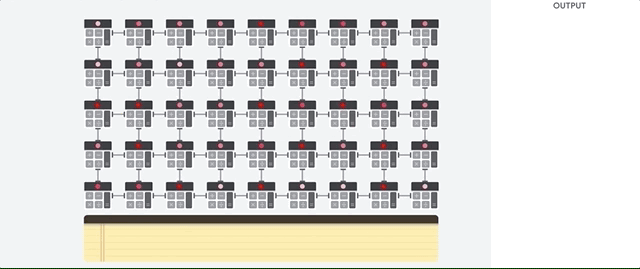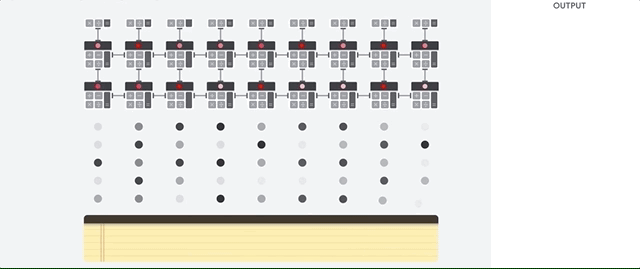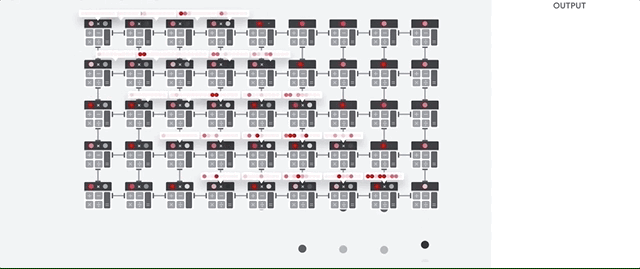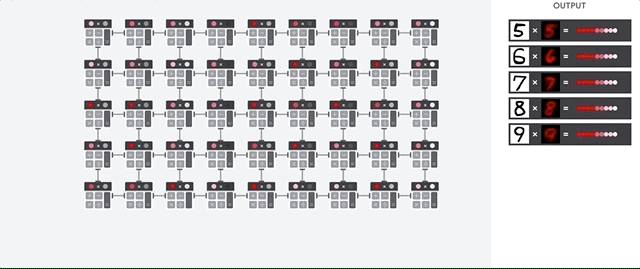
Infolgedessen können TPUs bei Berechnungen in neuronalen Netzen einen hohen rechnerischen Durchsatz erzielen.
XLA-Compiler
Code, der auf TPUs ausgeführt wird, muss vom XLA-Compiler (Accelerator Linear Algebra) kompiliert werden. XLA ist ein Just-in-Time-Compiler, der den von einer ML-Framework-Anwendung gesendeten Graphen verwendet und die linearen Algebra-, Verlust- und Gradientenkomponenten des Graphen in TPU-Maschinencode kompiliert. Der Rest des Programms wird auf dem TPU-Hostcomputer ausgeführt. Der XLA-Compiler ist Teil des TPU-VM-Images, das auf einem TPU-Hostcomputer ausgeführt wird.
Verwendung von TPUs
Cloud TPUs sind für bestimmte Arbeitslasten optimiert. In einigen Situationen möchten Sie möglicherweise GPUs oder CPUs auf Compute Engine-Instanzen verwenden, um Ihre Arbeitslasten für maschinelles Lernen auszuführen. Im Allgemeinen können Sie basierend auf den folgenden Richtlinien entscheiden, welche Hardware für Ihre Arbeitslast am besten geeignet ist:
CPUs
- Schnelles Prototyping, das maximale Flexibilität erfordert
- Einfache Modelle, die nicht lange trainiert werden müssen
- Kleine Modelle mit kleinen, effektiven Batchgrößen
- Modelle, die viele benutzerdefinierte TensorFlow-Vorgänge enthalten geschrieben in C++
- Modelle, die durch die verfügbare E/A oder die Netzwerkbandbreite des Hostsystems begrenzt sind
GPUs
- Modelle mit einer erheblichen Anzahl von benutzerdefinierten TensorFlow-/PyTorch-/JAX-Vorgängen, die mindestens teilweise auf CPUs ausgeführt werden müssen
- Modelle mit TensorFlow-Operationen, die nicht auf Cloud TPU verfügbar sind (siehe die Liste der verfügbaren TensorFlow-Operationen)
- Mittlere bis große Modelle mit größeren effektiven Batchgrößen
TPUs
- Modelle, die von Matrixberechnungen dominiert werden
- Modelle ohne benutzerdefinierte TensorFlow-/PyTorch-/JAX-Vorgänge innerhalb der Haupttrainingsschleife
- Modelle, die Wochen oder Monate lang trainiert werden
- Große Modelle mit großen, effektiven Batchgrößen
Cloud TPUs sind für folgende Arbeitslasten nicht geeignet:
- Lineare Algebraprogramme, die häufige Verzweigungen erfordern oder viele elementweise Algebraoperationen
- Arbeitslasten, die nur wenig auf Arbeitsspeicher zugreifen
- Arbeitslasten, die eine hochpräzise Arithmetik erfordern
- Neuronale Netzwerkarbeitslasten, die benutzerdefinierte Vorgänge in der Haupttrainingsschleife enthalten
Best Practices für die Modellentwicklung
Ein Programm, dessen Berechnung von Nicht-Matrixoperationen wie Hinzufügen, Umformen oder Verketten dominiert wird, erreicht wahrscheinlich keine hohe MXU-Auslastung. Die folgenden Richtlinien helfen Ihnen bei der Auswahl und die für Cloud TPU geeignet sind.
Layout
Der XLA-Compiler führt Codetransformationen durch, einschließlich einer Matrixmultiplikation in kleinere Blöcke, um Berechnungen auf der Matrixeinheit (MXU) effizient auszuführen. Die Struktur der MXU-Hardware, ein 128-x-128-systolischer Array und das TPU-Design Subsystem des Speichersubsystems, das Dimensionen bevorzugt, die ein Vielfaches von 8 sind, werden von XLA-Compiler für die Tiling-Effizienz. Folglich sind bestimmte Layouts besser für das Kacheln geeignet, während andere eine Umformung erfordern, bevor sie gekachelt werden können. Umformungsvorgänge sind auf der Cloud TPU häufig speichergebunden.
Formen
Der XLA-Compiler kompiliert eine ML-Grafik genau rechtzeitig für den ersten Batch. Wenn nachfolgende Stapel unterschiedliche Formen haben, funktioniert das Modell nicht. (Wenn der Graph bei jeder Änderung der Form neu kompiliert wird, ist dies zu langsam.) Daher kann jedes Modell, Tensoren mit dynamischen Formen ist nicht gut für TPUs geeignet.
Padding
In einem Cloud TPU-Programm mit hoher Leistung werden in Blöcke von 128 x 128 gekachelt. Wenn eine Matrixberechnung keine vollständige MXU belegen kann, füllt der Compiler Tensoren mit Nullen auf. Padding hat zwei Nachteile:
- Tensoren, die mit Nullen aufgefüllt sind, lasten den TPU-Kern nicht voll aus.
- Das Padding erhöht den für einen Tensor erforderlichen On-Chip-Arbeitsspeicher und kann im Extremfall zu einem Fehler aufgrund fehlenden Arbeitsspeichers führen.
Während das Padding bei Bedarf automatisch vom XLA-Compiler durchgeführt wird, kann der Umfang des Paddings mit dem Werkzeug op_profile ermittelt werden. Padding kann durch Auswahl von Tensordimensionen vermieden werden, die für TPUs gut geeignet sind.
Dimensionen
Die Wahl geeigneter Tensordimensionen hilft bei der Maximierung der Leistung der TPU-Hardware, insbesondere der MXU. Der XLA-Compiler versucht entweder die Batchgröße oder eine Feature-Dimension zu verwenden, um die MXU maximal zu nutzen. Daher muss eine von diesen ein Vielfaches von 128 sein. Andernfalls füllt der Compiler eine von ihnen auf 128 auf. Idealerweise sollten sowohl die Batchgröße als auch die Feature-Dimensionen ein Vielfaches von 8 sein, wodurch eine hohe Leistung aus dem Speichersubsystem extrahiert werden kann.
VPC Service Controls einbinden
Mit Cloud TPU VPC Service Controls können Sie Sicherheitsbereiche um Cloud TPU-Ressourcen verwalten und Datenbewegungen über den Perimeter steuern Grenze. Weitere Informationen zu VPC Service Controls finden Sie in der Übersicht zu VPC Service Controls. Welche Einschränkungen sich bei Verwendung von Cloud TPU mit VPC Service Controls ergeben, erfahren Sie unter Unterstützte Produkte und Einschränkungen.
Edge TPU
Modelle für das maschinelle Lernen, die in der Cloud trainiert werden, müssen immer öfter Inferencing auf Edge-Geräten ausführen, d. h. auf Geräten, die am Rande des Internets der Dinge ausgeführt werden. Zu diesen Geräten gehören Sensoren und andere Smart-Home-Geräte, die Echtzeitdaten erfassen, intelligente Entscheidungen treffen und dann Maßnahmen ergreifen oder ihre Informationen an andere Geräte oder die Cloud weitergeben.
Da solche Geräte nur mit begrenzter Stromzufuhr betrieben werden können (einschließlich Akkuleistung), hat Google den Edge TPU-Coprozessor entwickelt, um ML-Inferencing auf Geräten mit geringer Leistung zu beschleunigen. Eine einzelne Edge-TPU kann 4 Billionen Vorgänge pro Sekunde ausführen (4 TOPS) und verbraucht nur 2 Watt Strom, Sie erhalten also 2 TOPS pro Watt. Beispielsweise kann die Edge TPU hochauflösende Mobile-Vision-Modelle wie MobileNet V2 mit fast 400 Bildern pro Sekunde und auf energieeffiziente Weise ausführen.
Dieser energiesparende ML-Beschleuniger erweitert Cloud TPU und Cloud IoT für eine End-to-End-Infrastruktur (Cloud-to-Edge, Hardware und Software), die um Ihre KI-basierten Lösungen zu vereinfachen.
Die Edge TPU ist für Ihre eigenen Prototyping- und Produktionsgeräte in verschiedenen Formfaktoren verfügbar, darunter ein Single-Board-Computer, ein System-on-Module, eine PCIe/M.2-Karte und ein SMD-Modul. Weitere Informationen zur Edge TPU und zu allen verfügbaren Produkten finden Sie unter coral.ai.
Einstieg in Cloud TPU
- Google Cloud-Konto einrichten
- Cloud TPU API aktivieren
- Cloud TPU-Zugriff auf Ihre Cloud Storage-Buckets gewähren
- Grundlegende Berechnungen auf einer TPU ausführen
- Referenzmodell auf einer TPU trainieren
- Modell analysieren
Hilfe anfordern
Wenden Sie sich an den Cloud TPU-Support. Wenn Sie ein aktives Google Cloud-Projekt haben, müssen Sie die folgenden Informationen angeben:
- Ihre Google Cloud-Projekt-ID
- Der Name Ihrer TPU, sofern vorhanden
- Weitere Informationen, die Sie angeben möchten
Nächste Schritte
Möchten Sie mehr über Cloud TPU erfahren? Die folgenden Ressourcen könnten hilfreich sein: