Preservare i progressi dell'addestramento utilizzando Autocheckpoint
In passato, quando una VM TPU richiedeva manutenzione, la procedura veniva avviata immediatamente, senza lasciare il tempo agli utenti di eseguire azioni di conservazione dello stato, come il salvataggio di un checkpoint. Ciò è mostrato nella Figura 1(a).
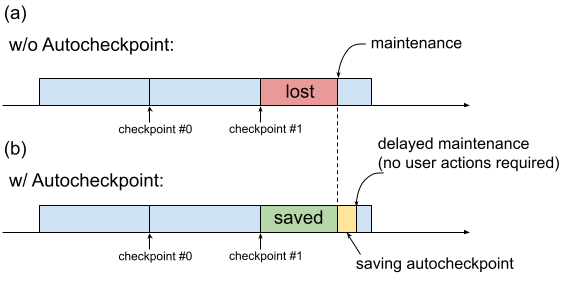
Fig. 1. Illustrazione della funzionalità di checkpoint automatico: (a) Senza il checkpoint automatico, l'avanzamento dell'addestramento dall'ultimo checkpoint viene perso quando è previsto un evento di manutenzione. (b) Con Autocheckpoint, i progressi dell'addestramento dall'ultimo checkpoint possono essere conservati in caso di evento di manutenzione imminente.
Puoi utilizzare Autocheckpoint (Figura 1(b)) per preservare l'avanzamento dell'addestramento configurando il codice in modo da salvare un checkpoint non pianificato quando si verifica un evento di manutenzione. Quando si verifica un evento di manutenzione, i progressi dall'ultimo checkpoint vengono salvati automaticamente. La funzionalità è disponibile sia per le singole fette che per le fette multiple.
La funzionalità di checkpoint automatico funziona con i framework in grado di acquisire i segnali SIGTERM e salvare successivamente un checkpoint. I framework supportati includono:
Utilizzo di Autocheckpoint
La funzionalità di salvataggio automatico è disattivata per impostazione predefinita. Quando crei una
TPU o richiedi una risorsa in coda,
puoi attivare Autocheckpoint aggiungendo il flag --autocheckpoint-enabled durante il provisioning
della TPU.
Con la funzionalità attivata, Cloud TPU
esegue i seguenti passaggi una volta ricevuta la notifica di un
evento di manutenzione:
- Acquisizione del segnale SIGTERM inviato al processo utilizzando il dispositivo TPU
- Attendi l'uscita del processo o che siano trascorsi 5 minuti, a seconda dell'eventualità che si verifica per prima.
- Esegui la manutenzione delle sezioni interessate
L'infrastruttura utilizzata da Autocheckpoint è indipendente dal framework ML. Qualsiasi framework ML può supportare Autocheckpoint se è in grado di acquisire il segnale SIGTERM e avviare un processo di checkpoint.
Nel codice dell'applicazione, devi attivare le funzionalità di Autocheckpoint fornite dal framework ML. In Pax, ad esempio, ciò significa attivare i flag della riga di comando durante l'avvio dell'addestramento. Per saperne di più, consulta la guida rapida di Autocheckpoint con Pax. Dietro le quinte, i framework salvano un checkpoint non pianificato quando viene ricevuto un segnale SIGTERM e la VM TPU interessata viene sottoposta a manutenzione quando la TPU non è più in uso.
Guida rapida: checkpoint automatico con MaxText
MaxText è un LLM open source ad alte prestazioni, scalabile in modo arbitrario e ben testato scritto in Python/JAX puro e destinato alle Cloud TPU. MaxText contiene tutta la configurazione necessaria per utilizzare la funzionalità di salvataggio automatico.
Il file MaxText READMEdescrive
due modi per eseguire MaxText su larga scala:
- Utilizzo di
multihost_runner.py, consigliato per la sperimentazione - Utilizzo di
multihost_job.py, consigliato per la produzione
Quando utilizzi multihost_runner.py, attiva Autocheckpoint impostando
il flag autocheckpoint-enabled durante il provisioning della risorsa in coda.
Quando utilizzi
multihost_job.py, attiva Autocheckpoint specificando il
flag della riga di comando ENABLE_AUTOCHECKPOINT=true quando avvii il job.
Guida rapida: checkpoint automatico con Pax su una singola sezione
Questa sezione fornisce un esempio di come configurare e utilizzare Autocheckpoint con Pax su una singola sezione. Con la configurazione appropriata:
- Un checkpoint verrà salvato quando si verifica un evento di manutenzione.
- Cloud TPU eseguirà la manutenzione delle VM TPU interessate dopo il salvataggio del checkpoint.
- Al termine della manutenzione di Cloud TPU, puoi utilizzare la VM TPU come di consueto.
Utilizza il flag
autocheckpoint-enabledquando crei la VM TPU o richiedi una risorsa in coda.Ad esempio:
Imposta le variabili di ambiente:
export PROJECT_ID=your-project-id export TPU_NAME=your-tpu-name export ZONE=zone-you-want-to-use export ACCELERATOR_TYPE=your-accelerator-type export RUNTIME_VERSION=tpu-ubuntu2204-base
Descrizioni delle variabili di ambiente
Variabile Descrizione PROJECT_IDL'ID progetto Google Cloud . Utilizza un progetto esistente o creane uno nuovo. TPU_NAMEIl nome della TPU. ZONELa zona in cui creare la VM TPU. Per saperne di più sulle zone supportate, consulta Regioni e zone TPU. ACCELERATOR_TYPEIl tipo di acceleratore specifica la versione e le dimensioni della Cloud TPU che vuoi creare. Per saperne di più sui tipi di acceleratore supportati per ogni versione di TPU, consulta la sezione Versioni di TPU. RUNTIME_VERSIONLa versione software di Cloud TPU. Imposta l'ID progetto e la zona nella configurazione attiva:
gcloud config set project $PROJECT_ID gcloud config set compute/zone $ZONE
Crea una TPU:
gcloud alpha compute tpus tpu-vm create $TPU_NAME \ --accelerator-type $ACCELERATOR_TYPE \ --version $RUNTIME_VERSION \ --autocheckpoint-enabled
Connettiti alla TPU utilizzando SSH:
gcloud compute tpus tpu-vm ssh $TPU_NAMEInstallare Pax su una singola sezione
La funzionalità di controllo automatico funziona su Pax versione 1.1.0 e successive. Nella VM TPU, installa
jax[tpu]e l'ultima versione dipaxml:pip install paxml && pip install jax[tpu] -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
Configura il modello
LmCloudSpmd2B. Prima di eseguire lo script di addestramento, modificaICI_MESH_SHAPEin[1, 8, 1]:@experiment_registry.register class LmCloudSpmd2B(LmCloudSpmd): """SPMD model with 2B params. Global batch size = 2 * 2 * 1 * 32 = 128 """ PERCORE_BATCH_SIZE = 8 NUM_LAYERS = 18 MODEL_DIMS = 3072 HIDDEN_DIMS = MODEL_DIMS * 4 CHECKPOINT_POLICY = layers.AutodiffCheckpointType.SAVE_NOTHING ICI_MESH_SHAPE = [1, 8, 1]
Avvia l'addestramento con la configurazione appropriata.
L'esempio seguente mostra come configurare il modello
LmCloudSpmd2Bper salvare i checkpoint attivati da Autocheckpoint in un bucket Cloud Storage. Sostituisci your-storage-bucket con il nome di un bucket esistente o creane uno nuovo.export JOB_LOG_DIR=gs://your-storage-bucket { python3 .local/lib/python3.10/site-packages/paxml/main.py \ --jax_fully_async_checkpoint=1 \ --exit_after_ondemand_checkpoint=1 \ --exp=tasks.lm.params.lm_cloud.LmCloudSpmd2B \ --job_log_dir=$JOB_LOG_DIR; } 2>&1 | tee pax_logs.txt
Prendi nota dei due flag passati al comando:
jax_fully_async_checkpoint: Se questo flag è attivo, verrà utilizzatoorbax.checkpoint.AsyncCheckpointer. La classeAsyncCheckpointersalva automaticamente un checkpoint quando lo script di addestramento riceve un segnale SIGTERM.exit_after_ondemand_checkpoint: Se questo flag è attivo, il processo TPU termina dopo il salvataggio del checkpoint automatico, il che attiva l'esecuzione immediata della manutenzione. Se non utilizzi questo flag, l'addestramento continuerà dopo il salvataggio del checkpoint e Cloud TPU attenderà il timeout (5 minuti) prima di eseguire la manutenzione richiesta.
Checkpoint automatico con Orbax
La funzionalità di salvataggio automatico non è limitata a MaxText o Pax. Qualsiasi framework in grado di acquisire il segnale SIGTERM e avviare un processo di checkpointing funziona con l'infrastruttura fornita da Autocheckpoint. Orbax, uno spazio dei nomi che fornisce librerie di utilità comuni per gli utenti JAX, offre queste funzionalità.
Come spiegato nella documentazione di Orbax,
queste funzionalità sono attivate per impostazione predefinita per gli utenti
di orbax.checkpoint.CheckpointManager. Il metodo save
chiamato dopo ogni passaggio controlla automaticamente se è imminente un evento di manutenzione e, in caso affermativo, salva un checkpoint anche se il numero di passaggi non è un multiplo di save_interval_steps.
La documentazione di GitHub
mostra anche come uscire dall'addestramento dopo aver salvato un
Autocheckpoint, con una modifica nel codice utente.