Preservar o progresso do treinamento usando o Autocheckpoint
Historicamente, quando uma VM da TPU requer manutenção, o procedimento é iniciado imediatamente, sem deixar tempo para que os usuários realizem ações de preservação de progresso, como salvar um ponto de verificação. Isso é mostrado na Figura 1(a).
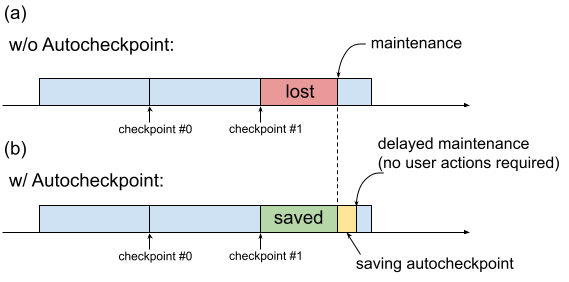
Figura 1 Ilustração do recurso de checkpoint automático: (a) Sem o checkpoint automático, o progresso do treinamento desde o último checkpoint é perdido quando há um evento de manutenção programado. (b) Com o Autocheckpoint, o progresso do treinamento desde o último ponto de verificação pode ser preservado quando há um evento de manutenção futuro.
Use o Autocheckpoint (Figura 1(b)) para preservar o progresso do treinamento configurando seu código para salvar um checkpoint não programado quando um evento de manutenção ocorrer. Quando um evento de manutenção ocorre, o progresso desde o último ponto de verificação é salvo automaticamente. O recurso funciona com fatias únicas e Multislice.
O recurso Autocheckpoint funciona com frameworks que podem capturar sinais SIGTERM e salvar um checkpoint. Os frameworks compatíveis incluem:
Como usar o Autocheckpoint
O recurso de ponto de verificação automática fica desativado por padrão. Ao criar uma TPU ou solicitar um recurso enfileirado, é possível ativar o Autocheckpoint adicionando a flag --autocheckpoint-enabled ao provisionar a TPU.
Com o recurso ativado, o Cloud TPU realiza as seguintes etapas quando recebe a notificação de um evento de manutenção:
- Capturar o sinal SIGTERM enviado ao processo usando o dispositivo TPU
- Aguarde até que o processo seja encerrado ou que 5 minutos tenham se passado, o que ocorrer primeiro.
- Realizar manutenção nas partes afetadas
A infraestrutura usada pelo Autocheckpoint é independente do framework de ML. Qualquer framework de ML pode oferecer suporte ao Autocheckpoint se conseguir capturar o sinal SIGTERM e iniciar um processo de checkpoint.
No código do aplicativo, é necessário ativar os recursos de Autocheckpoint fornecidos pelo framework de ML. No Pax, por exemplo, isso significa ativar flags de linha de comando ao iniciar o treinamento. Para mais informações, consulte o guia de início rápido do Autocheckpoint com Pax. Nos bastidores, os frameworks salvam um ponto de verificação não programado quando um sinal SIGTERM é recebido, e a VM de TPU afetada passa por manutenção quando a TPU não está mais em uso.
Guia de início rápido: checkpoint automático com o MaxText
O MaxText é um LLM de alto desempenho, escalonável de forma arbitrária, de código aberto e bem testado, escrito em Python/JAX puro para Cloud TPUs. O MaxText contém toda a configuração necessária para usar o recurso de ponto de verificação automático.
O arquivo README
MaxText descreve
duas maneiras de executar o MaxText em grande escala:
- Usando
multihost_runner.py, recomendado para experimentos - Usando
multihost_job.py, recomendado para produção
Ao usar multihost_runner.py, ative o Autocheckpoint definindo
a flag autocheckpoint-enabled ao provisionar o recurso enfileirado.
Ao usar
multihost_job.py, ative o Autocheckpoint especificando a
sinalização de linha de comando ENABLE_AUTOCHECKPOINT=true ao iniciar o job.
Guia de início rápido: autocheckpoint com Pax em uma única fração
Nesta seção, mostramos um exemplo de como configurar e usar o Autocheckpoint com o Pax em uma única fração. Com a configuração adequada:
- Um ponto de verificação será salvo quando um evento de manutenção ocorrer.
- A Cloud TPU vai realizar a manutenção nas VMs TPU afetadas depois que o checkpoint for salvo.
- Quando a manutenção do Cloud TPU for concluída, você poderá usar a VM da TPU normalmente.
Use a flag
autocheckpoint-enabledao criar a VM da TPU ou solicitar um recurso em fila.Exemplo:
Defina as variáveis de ambiente:
export PROJECT_ID=your-project-id export TPU_NAME=your-tpu-name export ZONE=zone-you-want-to-use export ACCELERATOR_TYPE=your-accelerator-type export RUNTIME_VERSION=tpu-ubuntu2204-base
Descrições de variáveis de ambiente
Variável Descrição PROJECT_IDO ID do seu projeto Google Cloud . Use um projeto atual ou crie um novo. TPU_NAMEO nome da TPU. ZONEA zona em que a VM da TPU será criada. Para mais informações sobre as zonas compatíveis, consulte Regiões e zonas de TPU. ACCELERATOR_TYPEO tipo de acelerador especifica a versão e o tamanho da Cloud TPU que você quer criar. Para mais informações sobre os tipos de aceleradores compatíveis com cada versão de TPU, consulte Versões de TPU. RUNTIME_VERSIONA versão do software da Cloud TPU. Defina o ID do projeto e a zona na configuração ativa:
gcloud config set project $PROJECT_ID gcloud config set compute/zone $ZONE
Crie uma TPU:
gcloud alpha compute tpus tpu-vm create $TPU_NAME \ --accelerator-type $ACCELERATOR_TYPE \ --version $RUNTIME_VERSION \ --autocheckpoint-enabled
Conecte-se à TPU usando SSH:
gcloud compute tpus tpu-vm ssh $TPU_NAMEInstalar o Pax em uma única fração
O recurso de ponto de verificação automático funciona nas versões 1.1.0 e mais recentes do Pax. Na VM da TPU, instale
jax[tpu]e opaxmlmais recente:pip install paxml && pip install jax[tpu] -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
Configure o modelo
LmCloudSpmd2B. Antes de executar o script de treinamento, mudeICI_MESH_SHAPEpara[1, 8, 1]:@experiment_registry.register class LmCloudSpmd2B(LmCloudSpmd): """SPMD model with 2B params. Global batch size = 2 * 2 * 1 * 32 = 128 """ PERCORE_BATCH_SIZE = 8 NUM_LAYERS = 18 MODEL_DIMS = 3072 HIDDEN_DIMS = MODEL_DIMS * 4 CHECKPOINT_POLICY = layers.AutodiffCheckpointType.SAVE_NOTHING ICI_MESH_SHAPE = [1, 8, 1]
Inicie o treinamento com a configuração adequada.
O exemplo a seguir mostra como configurar o modelo
LmCloudSpmd2Bpara salvar pontos de verificação acionados pelo Autocheckpoint em um bucket do Cloud Storage. Substitua your-storage-bucket pelo nome de um bucket existente ou crie um novo.export JOB_LOG_DIR=gs://your-storage-bucket { python3 .local/lib/python3.10/site-packages/paxml/main.py \ --jax_fully_async_checkpoint=1 \ --exit_after_ondemand_checkpoint=1 \ --exp=tasks.lm.params.lm_cloud.LmCloudSpmd2B \ --job_log_dir=$JOB_LOG_DIR; } 2>&1 | tee pax_logs.txt
Observe as duas flags transmitidas ao comando:
jax_fully_async_checkpoint: com essa flag ativada, oorbax.checkpoint.AsyncCheckpointerserá usado. A classeAsyncCheckpointersalva automaticamente um ponto de verificação quando o script de treinamento recebe um sinal SIGTERM.exit_after_ondemand_checkpoint: com essa flag ativada, o processo da TPU é encerrado depois que o checkpoint automático é salvo, o que aciona a manutenção para ser realizada imediatamente. Se você não usar essa flag, o treinamento vai continuar depois que o checkpoint for salvo e a Cloud TPU vai aguardar um tempo limite (5 minutos) antes de realizar a manutenção necessária.
Autocheckpoint com Orbax
O recurso de ponto de verificação automático não está limitado ao MaxText ou ao Pax. Qualquer framework que possa capturar o sinal SIGTERM e iniciar um processo de criação de pontos de verificação funciona com a infraestrutura fornecida pelo Autocheckpoint. O Orbax, um namespace que oferece bibliotecas de utilitários comuns para usuários do JAX, oferece essas funcionalidades.
Conforme explicado na documentação do Orbax, esses recursos são ativados por padrão para usuários do orbax.checkpoint.CheckpointManager. O método save, que é chamado após cada etapa, verifica automaticamente se um evento de manutenção está prestes a acontecer e, em caso afirmativo, salva um checkpoint mesmo que o número da etapa não seja um múltiplo de save_interval_steps.
A documentação do GitHub
também ilustra como fazer com que o treinamento seja encerrado após salvar um
Autocheckpoint, com uma modificação no código do usuário.