Übersicht
In Text-to-Speech werden rohe Audiodaten mit natürlicher, menschlicher Sprache erstellt. Das heißt, die generierten Audiodaten klingen, als ob ein Mensch spricht. Wenn Sie eine Syntheseanfrage an Text-to-Speech senden, müssen Sie eine Stimme festlegen, welche die Wörter "spricht".
Text-to-Speech bietet eine Vielzahl von benutzerdefinierten Stimmen. Die Stimmen variieren je nach Sprache, Geschlecht und Akzent (bei bestimmten Sprachen). Bei einigen Sprachen können Sie aus mehreren Stimmen wählen. Eine vollständige Liste der in Ihrer Sprache verfügbaren Stimmen finden Sie auf der Seite Unterstützte Stimmen. Sie können Text-to-Speech anweisen, eine bestimmte Stimme aus dieser Liste zu verwenden. Legen Sie dazu beim Senden einer Anfrage an die API die Felder VoiceSelectionParams fest. Weitere Informationen zum Senden einer synthesize-Anfrage finden Sie in den Kurzanleitungen zu Text-to-Speech.
Standardstimmen
Die von Text-to-Speech angebotenen Stimmen werden zum Teil mit unterschiedlichen Sprachsynthesetechnologien für das Maschinenmodell der Stimme generiert. Bei der gängigen Sprachtechnologie der parametrischen Sprachausgabe werden zum Generieren von Audiodaten in der Regel Ausgaben mit Signalverarbeitungsalgorithmen – sogenannten Vocodern – übergeben. Viele der in Text-to-Speech verfügbaren Standardstimmen basieren auf einer Variante dieser Technologie.
WaveNet-Stimmen
Die Text-to-Speech API bietet auch eine Gruppe von Premiumstimmen, die mit einem WaveNet-Modell generiert werden. Diese Technologie wird auch für die Sprachausgabe für Google Assistant, die Google-Suche und Google Übersetzer verwendet. Die WaveNet-Technologie bietet nicht nur eine Reihe von synthetischen Stimmen, sondern stellt auch eine neue Art der synthetischen Sprachgenerierung dar.
Mit WaveNet generierte Sprache klingt natürlicher als bei anderen Sprachausgabesystemen. Die Silben, Phoneme und Wörter der synthetisierten Sprache haben eine menschenähnliche Betonung und einen natürlichen Tonfall. Allgemein bevorzugen Nutzer die mit WaveNet generierte Sprache gegenüber den Sprachen von anderen Sprachausgabetechnologien.
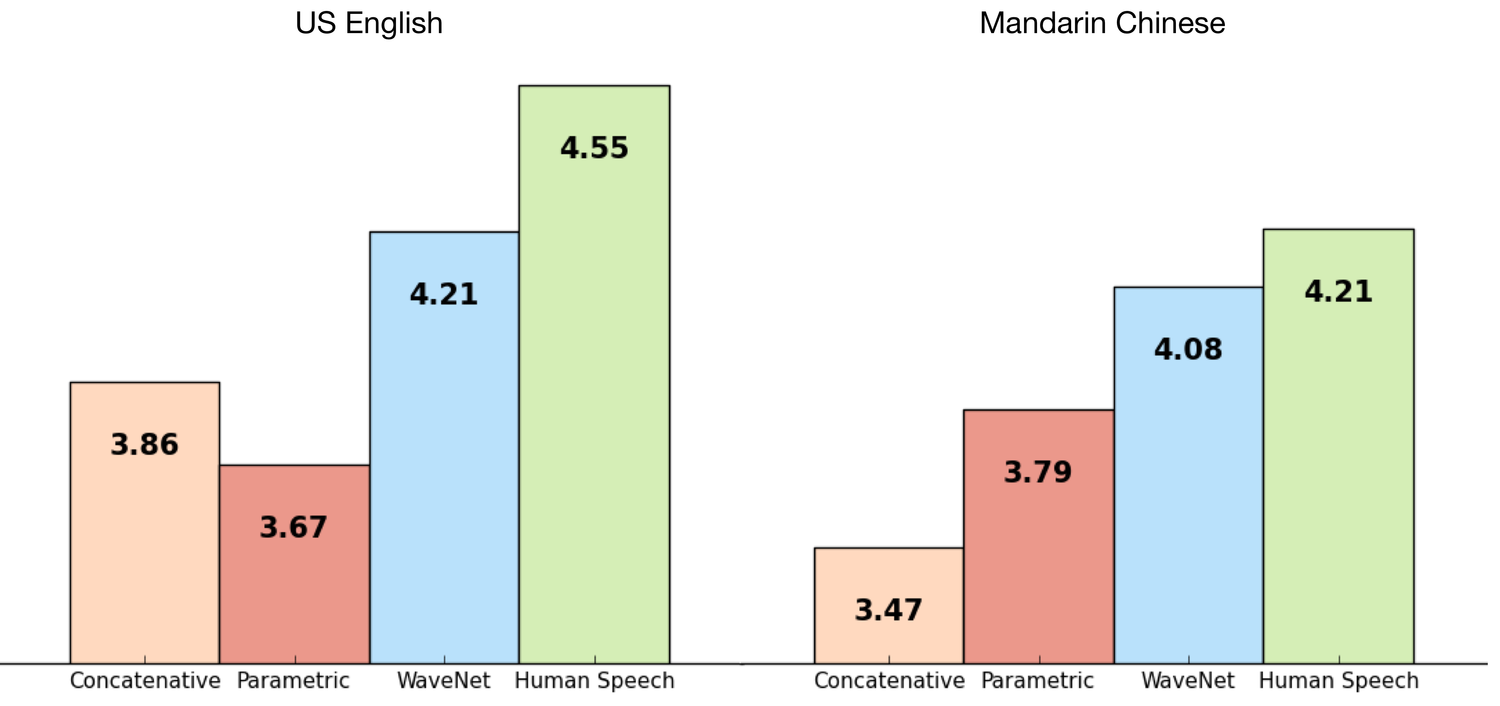 Abbildung 1. Vergleich von WaveNet mit anderen synthetischen Stimmen und menschlicher Sprache Die y-Achsen-Werte stellen den mittleren Umfragewert (MOS) für jede Stimme dar.
Die Testpersonen stuften jede Stimme auf einer Skala von 1 bis 5 ein, je nachdem, wie sehr sie sich wie natürliche Sprache anhörte. Weitere Informationen zu MOS-Bewertungen und WaveNet-Technologie finden Sie auf der Seite DeepMind WaveNet.
Abbildung 1. Vergleich von WaveNet mit anderen synthetischen Stimmen und menschlicher Sprache Die y-Achsen-Werte stellen den mittleren Umfragewert (MOS) für jede Stimme dar.
Die Testpersonen stuften jede Stimme auf einer Skala von 1 bis 5 ein, je nachdem, wie sehr sie sich wie natürliche Sprache anhörte. Weitere Informationen zu MOS-Bewertungen und WaveNet-Technologie finden Sie auf der Seite DeepMind WaveNet.
Im Unterschied zu den meisten anderen Sprachausgabesystemen werden bei einem WaveNet-Modell rohe Audiowellenformen von Grund auf neu erstellt. Das Modell verwendet ein neuronales Netzwerk, das mit einer großen Menge von Sprachsamples trainiert wurde. Während des Trainings extrahiert das Netzwerk die zugrunde liegende Struktur der Sprache, wie etwa die Tonfolge und den Aufbau einer realitätsnahen Sprechwellenform. Bei einer Texteingabe kann das trainierte WaveNet-Modell die entsprechenden Sprechwellenformen Sample für Sample von Grund auf neu generieren. Möglich sind bis zu 24.000 Samples pro Sekunde mit nahtlosen Übergängen zwischen den einzelnen Tönen.
Vergleichen Sie die folgenden beiden Audioclips, um den Unterschied zwischen einem mit WaveNet generierten Audioclip und einem durch ein anderes Sprachausgabeverfahren generierten Clip zu hören.
1. Beispiel Hohe Qualität, keine WaveNet-Stimme
2. Beispiel WaveNet-Stimme
Weitere Informationen zu WaveNet-Modellen finden Sie im Blogpost von DeepMind.
Jetzt testen
Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie einfach ein Konto, um die Leistung von Text-to-Speech in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
Text-to-Speech kostenlos testen