Nesta página, mostraremos informações que devem ser revisadas antes de restaurar uma instância a partir de um backup ou executar uma recuperação pontual (PITR, na sigla em inglês).
O que acontece durante uma restauração?
Ao restaurar uma instância, os seguintes dados da instância principal são restaurados para a nova instância:
- Bancos de dados
- Usuários
A operação de restauração faz com que a instância seja reiniciada.
Recuperação pontual (PITR)
A recuperação pontual (PITR, na sigla em inglês) ajuda a recuperar uma instância em um momento específico. Por exemplo, se houver perda de dados devido a um erro, será possível recuperar um banco de dados no estado anterior a esse evento.
A PITR sempre cria uma nova instância. Não é possível realizar uma PITR em uma instância já existente. A nova instância herda as configurações da instância de origem, semelhante à criação de clones.
O Cloud SQL usa registros de transação para a PITR. Se você ativar a PITR para uma instância e restaurar a instância por um backup, o Cloud SQL excluirá os registros de transação que permitem usar a PITR na instância restaurada.
Para garantir que os registros da sua instância sejam armazenados no Cloud Storage em vez de no disco, siga estas etapas:
- Verifique a arquitetura de rede da instância. Se a instância estiver na arquitetura de rede antiga, faça upgrade para a nova arquitetura de rede.
- Se o tamanho dos registros no disco estiver causando problemas de desempenho para sua instância, desative a PITR e reative-a.
Para instruções detalhadas sobre como realizar a PITR, consulte Usar a recuperação pontual (PITR, na sigla em inglês).
Restaurar uma instância indisponível
É possível usar a PITR para restaurar uma instância do Cloud SQL que não está disponível. A PITR geralmente oferece um objetivo do ponto de recuperação (RPO, na sigla em inglês) de cinco minutos ou menos.
Se a instância não estiver disponível, use a API para receber o horário de recuperação mais antigo e mais recente em que é possível restaurar a instância e executar a recuperação para esse momento. Se a zona em que a instância está configurada não estiver acessível, será possível restaurar a instância em uma zona primária ou secundária diferente fornecendo valores para as zonas preferenciais.
Suponha que uma instância do Cloud SQL fique indisponível às 16h (EST). Se o último horário de recuperação for às 15h55 EST, você poderá recuperar a instância até esse momento.
Restaurar uma instância excluída usando a PITR
É possível usar a PITR para restaurar uma instância do Cloud SQL após a exclusão. Para usar esse recurso, a instância precisa ter PITR e backups retidos ativados antes da exclusão. Quando ativados, os registros da PITR são retidos após a exclusão da instância.
Depois que uma instância é excluída, os registros da PITR continuam seguindo as configurações de retenção definidas pela instância quando ela estava ativa. Os registros da PITR expiram com base nas configurações de retenção de forma contínua após a exclusão da instância. O período contínuo é definido com base no período de retenção da PITR definido na instância antes da exclusão. Por exemplo, se a instância do Cloud SQL Enterprise Plus tiver a retenção da PITR definida como 14 dias, o registro mais recente da PITR será excluído 14 dias após a exclusão da instância. Quando um registro de PITR expira, ele não pode ser recuperado.
Como os nomes de instâncias podem ser reutilizados depois que uma instância é excluída no Cloud SQL, os registros de PITR retidos podem ser identificados em Google Cloud com os seguintes campos:
instance_deletion_timelog_retention_days
Esses campos permitem identificar se um registro de PITR pertence a uma instância excluída.
A janela de recuperação da PITR é definida como os horários de recuperação mais antigos e mais recentes disponíveis para restaurar sua instância usando a PITR. Para encontrar os horários de recuperação mais antigos e mais recentes da sua instância excluída, consulte Conferir o horário de recuperação mais antigo e mais recente.
Para restaurar uma instância usando a PITR após a exclusão, consulte Realizar a PITR em uma instância excluída.
Dicas gerais sobre como fazer uma restauração
Ao restaurar uma instância a partir de um backup, seja para a mesma instância ou uma diferente, tenha em mente os itens a seguir:
- A operação de restauração substitui todos os dados na instância de destino.
- A instância de destino não está disponível para conexões durante a operação de restauração. As conexões atuais se perdem.
- Se estiver restaurando para uma instância com réplicas de leitura, você precisará excluir todas as réplicas e recriá-las após a conclusão da operação de restauração.
- A operação de restauração reinicia a instância.
Para instruções passo a passo sobre como realizar uma restauração, consulte:
Dicas e requisitos de restauração para uma instância diferente
Ao restaurar um backup para uma instância diferente, considere as restrições e as práticas recomendadas a seguir:
A instância de destino precisa ter a mesma versão do banco de dados que a instância da qual o backup foi tirado.
O Cloud SQL sempre define a capacidade de armazenamento da instância de destino como o valor máximo do tamanho do disco configurado e do disco de backup. O disco de backup é o tamanho do disco quando o backup é realizado.
A capacidade de armazenamento da instância de destino precisa ser pelo menos tão grande quanto a capacidade da instância em que o backup é realizado. A quantidade de armazenamento em uso não precisa ser considerada. Confira a capacidade de armazenamento da instância na página de instâncias do Cloud SQL. Esse requisito é aplicável mesmo que você esteja ou não realizando a PITR de um único banco de dados.
A instância de destino deve estar no estado
RUNNABLE.É possível que a instância de destino tenha um número diferente de núcleos ou uma quantidade diferente de memória do que da instância que originou o backup.
A instância de destino pode estar em uma região diferente da instância de origem.
Durante uma interrupção, ainda é possível recuperar uma lista de backups em um projeto específico. Consulte Como visualizar backups durante uma interrupção.
Limitações de taxa de restauração
É permitido um máximo de três operações de restauração a cada 30 minutos por instância por região e por projeto. Se uma operação de restauração falhar, ela não será considerada para essa cota. Se você atingir o limite, a operação falhará com uma mensagem de erro que informa quando é possível executá-la novamente.
Vamos ver como o Cloud SQL executa a limitação de taxa para restaurações.
O Cloud SQL usa tokens de um bucket para determinar quantas operações de restauração estão disponíveis por vez. Para cada backup, há um bucket para cada projeto e região de destino. As instâncias de destino do mesmo projeto compartilham um bucket se estiverem na mesma região. É possível usar no máximo três tokens em cada bucket para operações de restauração. A cada 10 minutos, um novo token é adicionado ao bucket. Se o bucket estiver cheio, o token estourar.
Cada vez que você emite uma operação de restauração, um token é concedido a partir do bucket. Se a operação for bem-sucedida, o token será removido do bucket. Se falhar, o token será retornado. O diagrama a seguir mostra como isso funciona:

Por exemplo, na figura a seguir, os backups Backup1, Backup2 e Backup3 são da mesma instância de origem.
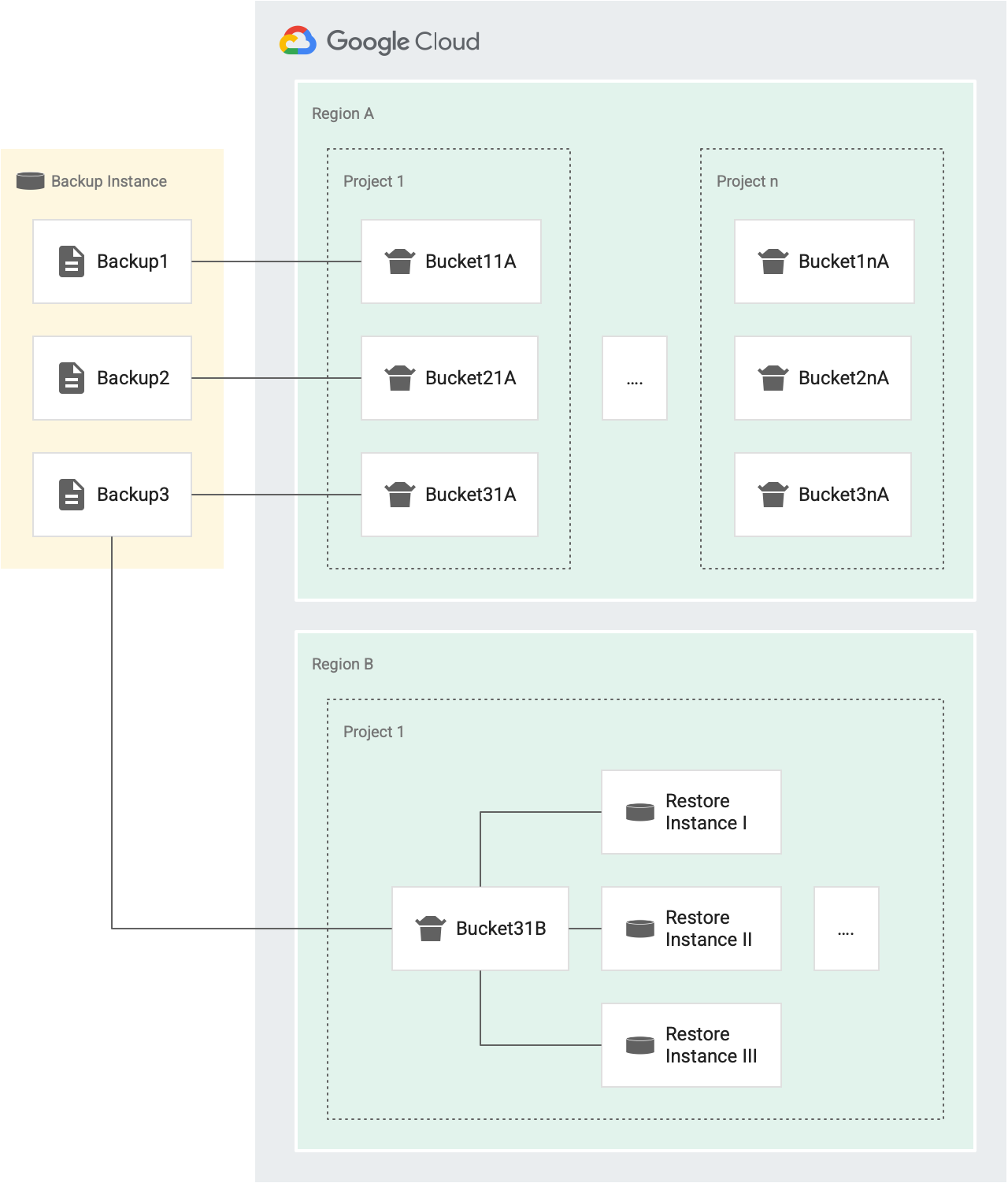
- Cada backup (Backup1, Backup2 e Backup3) tem o próprio bucket de tokens para operações de restauração que visam instâncias diferentes no Projeto 1 na Região A (Bucket11A, Bucket21A e Bucket31A). Como cada backup tem o próprio bucket, é possível restaurar cada backup para a mesma instância três vezes a cada 30 minutos.
- Cada backup tem um bucket para um projeto e uma região separados.
Por exemplo, se houver cinco projetos em uma região, haverá cinco buckets para esse backup nessa região, um em cada projeto. Na figura
anterior, temos dois projetos na região A: Projeto 1 e Projeto n.
- O Backup1 tem dois buckets de tokens para operações de restauração na região A. Um bucket para o projeto 1 (bucket11A) e um bucket para o projeto n (bucket1nA).
- Da mesma forma, o Backup3 tem dois buckets para operações de restauração na região A. Uma para o Projeto 1 (Bucket31A) e outra para o Projeto n (Bucket3nA).
- O Backup3 tem um bucket na região B, para o Projeto 1, porque todas as instâncias no mesmo projeto de destino e na mesma região de destino compartilham um bucket.