API를 사용하면 코드 없이도 커스텀 Speech-to-Text 모델을 만들고 학습하여 기존 Speech-to-Text 모델의 인식 정확성을 개선할 수 있습니다. 이 완전 관리형 서비스는 컴퓨팅 리소스를 자동으로 프로비저닝하고, 학습 애플리케이션 코드를 실행하며, 학습 작업이 완료된 후 컴퓨팅 리소스를 삭제합니다. 다운스트림 애플리케이션에 유용한 완전히 미세 조정된 텍스트 스크립트 작성 모델을 얻을 수 있습니다.
머신러닝 모델과 마찬가지로 커스텀 Speech-to-Text 모델은 일반적으로 반복적이며, 기본 모델을 시작점으로 선택하고 텍스트 및 오디오 데이터 세트에 맞게 미세 조정한 후 모델의 인식 품질을 테스트합니다. 결과가 예상과 다르면 다른 데이터 조합으로 새 모델을 재학습하거나 다시 테스트하거나 도메인에서 스크립트 작성에 직접 사용합니다.
시작하기 전에
Google Cloud 계정에 가입하고, Google Cloud 프로젝트를 만들고, Speech-to-Text API를 사용 설정했는지 확인합니다. Google Cloud 콘솔에서 음성으로 이동하고 Speech-to-Text API로 이동합니다. 왼쪽 탐색 메뉴의 커스텀 모델 섹션에서 작업합니다.
커스텀 모델 만들기
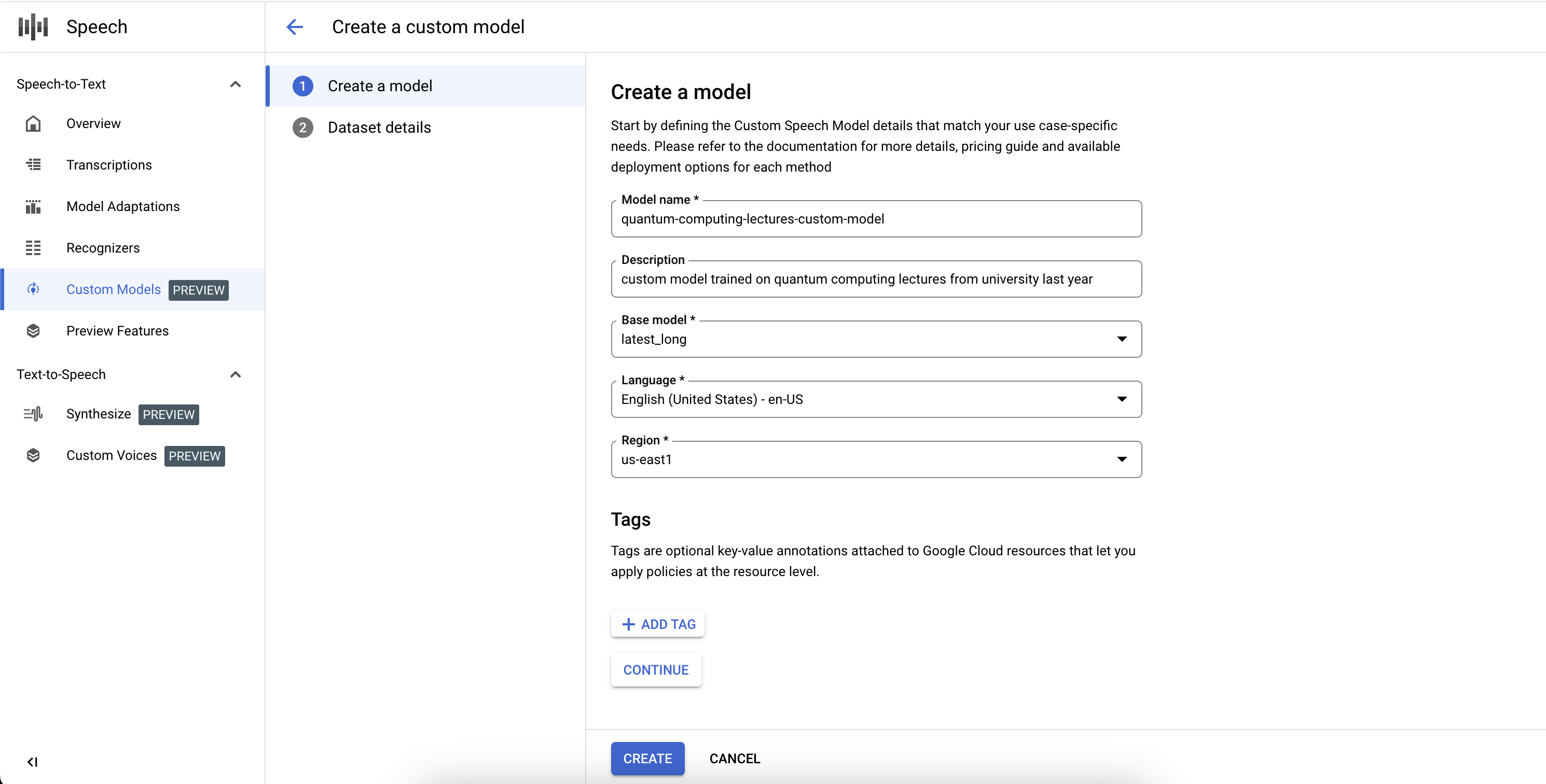
먼저 커스텀 Speech-to-Text 모델을 만들고 기본 모델 및 스크립트 작성 언어와 같은 매개변수를 정의합니다.
만들기를 클릭하여 커스텀 모델을 만듭니다.
디스플레이에 사용되고 API 요청 및 Google Cloud Speech 콘솔에서 참조되는 모델 이름을 입력합니다.
모델의 설명을 입력합니다.
사용 사례에 가장 적합한 기본 모델을 선택합니다.
모델의 스크립트 작성 언어를 선택합니다.
학습이 진행될 리전을 선택합니다.
계속을 클릭합니다.
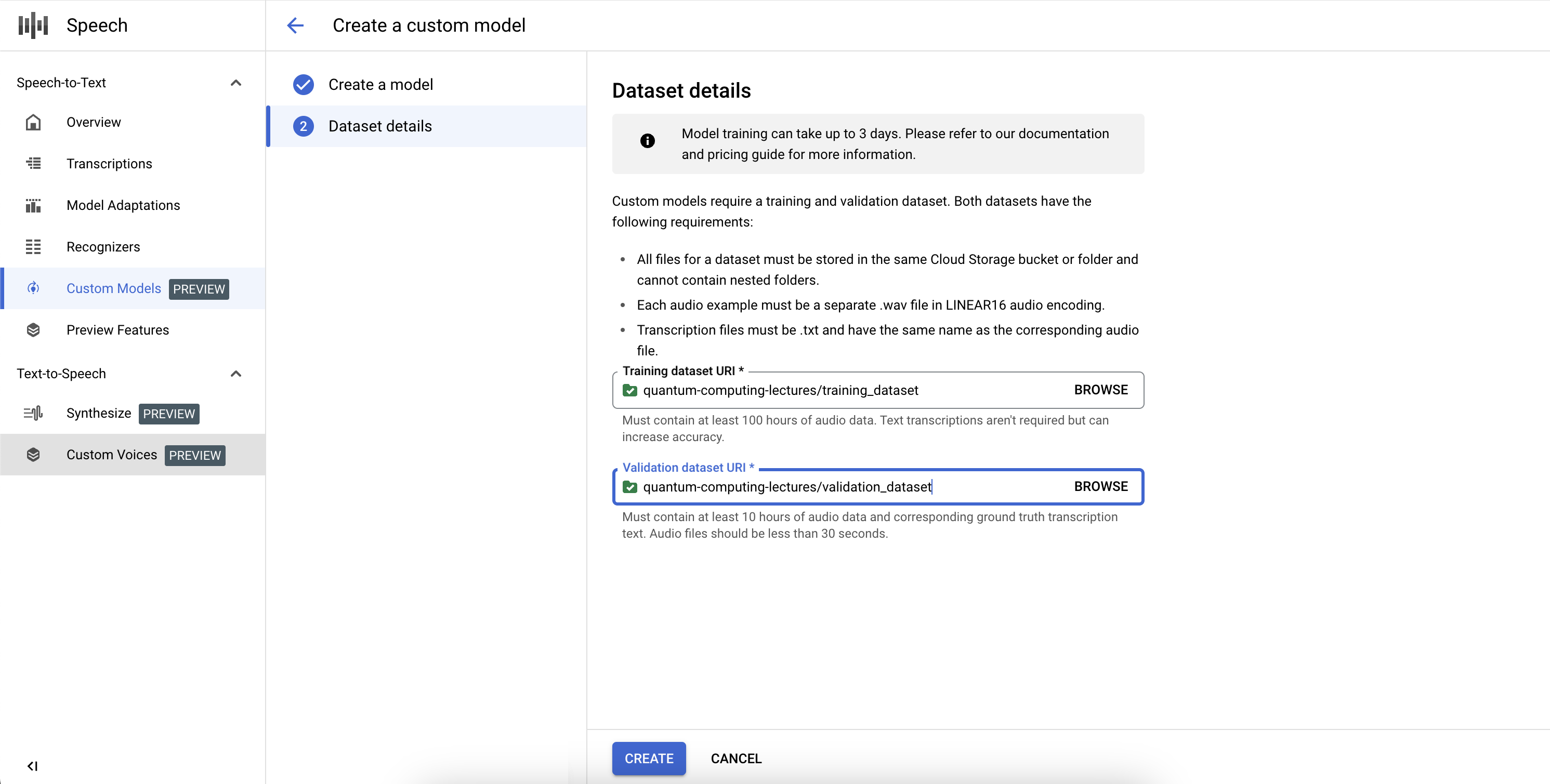
커스텀 Speech-to-Text 모델 작업의 정의를 완료하고 학습을 시작하려면 학습 및 검증 데이터 세트를 정의해야 합니다.
유효한 Cloud Storage 디렉터리 URI를 제공하여 학습 데이터 세트를 선택합니다. 오디오 및 텍스트 파일만 있고 오디오의 총 길이가 학습 데이터 세트 요구사항을 따르는지 확인합니다.
유효한 Cloud Storage 디렉터리 URI를 제공하여 검증 데이터 세트를 선택합니다. 오디오 및 텍스트 파일만 있는지 오디오의 총 길이가 검증 데이터 세트 요구사항을 따르는지 확인합니다.
만들기를 클릭하여 학습 프로세스를 시작합니다.
색인이 생성된 오디오 시간이 충분하지 않거나 파일이 가이드라인을 따르지 않으면 학습 작업이 실패합니다.
학습 작업은 Google 시스템의 다른 작업 후속으로 큐에 추가될 수 있으며 데이터 세트 크기에 따라 모델 학습에 몇 시간에서 며칠이 걸릴 수 있습니다. 모델 학습이 완료되면 상태가 활성으로 표시됩니다.
커스텀 모델 삭제
시작하기 전에 엔드포인트를 통해 커스텀 Speech-to-Text 모델로 라우팅되는 트래픽이 없는지 확인합니다. 모델을 삭제하면 요청 처리가 중지되기 때문입니다.
커스텀 모델 섹션의 커스텀 모델 탭으로 이동합니다.
옵션을 펼치려면 클릭한 다음 삭제를 클릭합니다. 잠시 후 커스텀 Speech-to-Text 모델이 모든 엔드포인트와 함께 삭제되며 더 이상 트래픽을 제공하지 않습니다.
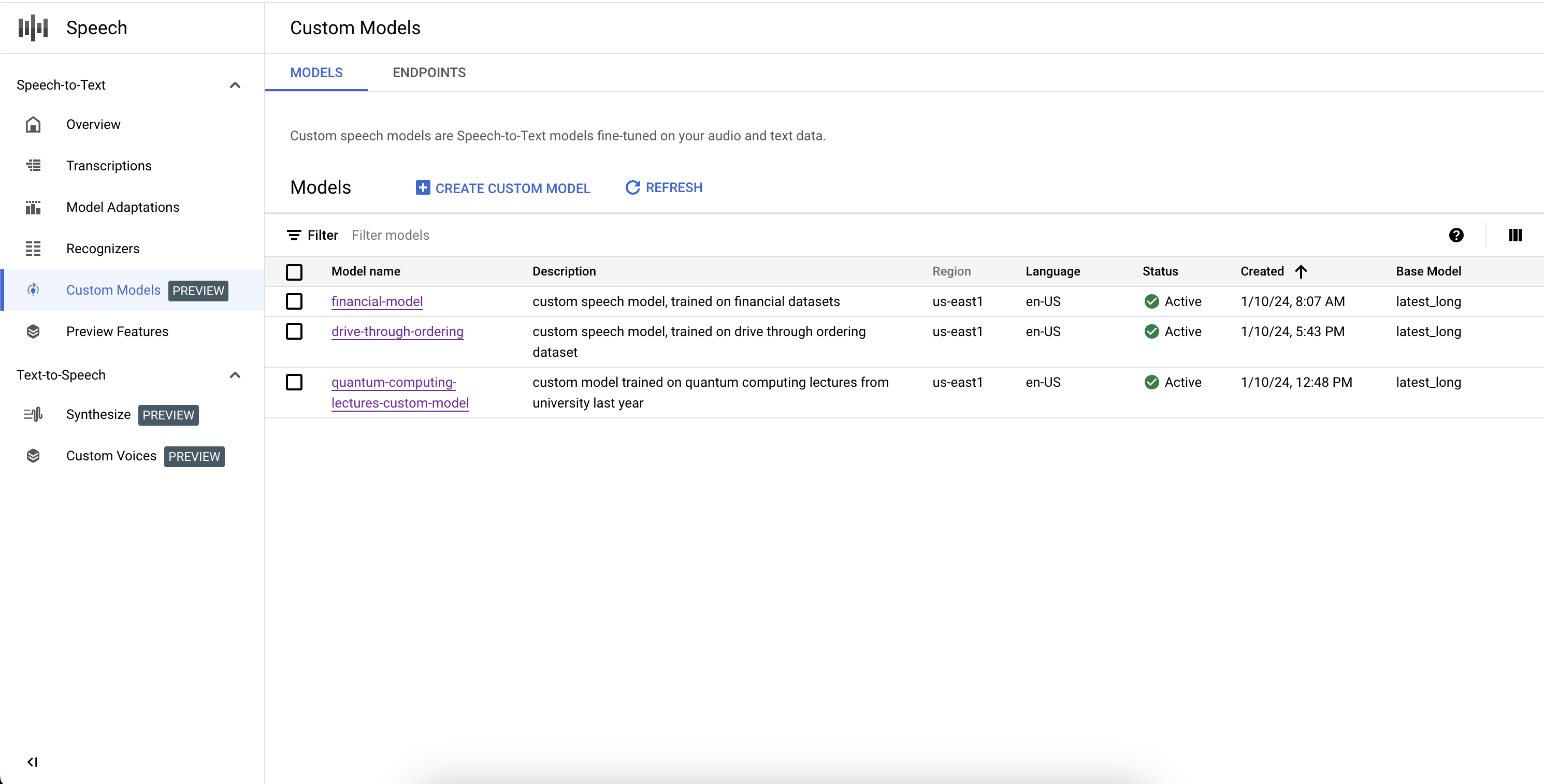
커스텀 모델 나열
커스텀 모델 섹션에서 모델을 선택하여 학습, 활성, 삭제 중인 모델을 포함한 모든 커스텀 Speech-to-Text 모델을 나열할 수도 있습니다.
[[["이해하기 쉬움","easyToUnderstand","thumb-up"],["문제가 해결됨","solvedMyProblem","thumb-up"],["기타","otherUp","thumb-up"]],[["이해하기 어려움","hardToUnderstand","thumb-down"],["잘못된 정보 또는 샘플 코드","incorrectInformationOrSampleCode","thumb-down"],["필요한 정보/샘플이 없음","missingTheInformationSamplesINeed","thumb-down"],["번역 문제","translationIssue","thumb-down"],["기타","otherDown","thumb-down"]],["최종 업데이트: 2025-07-24(UTC)"],[],[],null,["# Train and manage models\n\n| **Preview**\n|\n|\n| This feature is subject to the \"Pre-GA Offerings Terms\" in the General Service Terms section\n| of the [Service Specific Terms](/terms/service-terms#1).\n|\n| Pre-GA features are available \"as is\" and might have limited support.\n|\n| For more information, see the\n| [launch stage descriptions](/products#product-launch-stages).\n\nUsing the API, without any code, you can create and train a Custom Speech-to-Text model to improve recognition accuracy from an existing Speech-to-Text model. This fully managed service automatically provisions compute resources, executes the training application code, and ensures deletion of compute resources after the training job. You get a fully fine-tuned transcription model useful for any downstream application.\n\nSimilar to machine-learning models, training a Custom Speech-to-Text model is typically iterative and involves selecting a base model as a starting point, fine-tuning it with your text and audio datasets, then testing the recognition quality of the model. If the results are not what you expected, you retrain a new model with a different mixture of data, test again, or use it directly for transcription in your domain.\n\nBefore you begin\n----------------\n\nEnsure you have signed up for a Google Cloud account, created a Google Cloud project, and enabled the Speech-to-Text API: Go to **Speech** in the Google Cloud console, and navigate to the Speech-to-Text API. Operate in the **Custom Models** section of the navigation bar on the left.\n\nCreate a custom model\n---------------------\n\nStart by creating a custom Speech-to-Text model and defining its parameters, like base model and transcription language:\n\n1. Click **Create** to create a custom model.\n2. Enter a **Model name**, which will be used for the display and be referenced in your API requests and Google Cloud Speech console.\n3. Enter a **Description** for the model.\n4. Select a **Base model** that is suited best for your use case.\n5. Select the transcription **Language** of the model.\n6. Select the **Region** in which training should take place.\n7. Click **Continue**.\n\nTo complete the definition of the Custom Speech-to-Text model job and start the training, you will need to define the training and validation datasets.\n\n1. Select a **training dataset** , by providing a valid Cloud Storage directory URI. Ensure that only audio and text files are present and that the total duration of audio follows the [training dataset requirements](/speech-to-text/v2/docs/custom-speech-models/prepare-data#training_dataset_guidelines).\n2. Select a **validation dataset** , by providing a valid Cloud Storage directory URI. Ensure that only audio and text files are present and that the total duration of audio follows the [validation dataset requirements](/speech-to-text/v2/docs/custom-speech-models/prepare-data#validation_dataset_guidelines).\n3. Click **Create** to initiate the training process.\n\nIf not enough audio hours are indexed or the files don't follow the guidelines, the training job will fail.\n\nTraining jobs can be queued behind other jobs in our system, and training a model can take anywhere from a couple of hours to a few days depending on the dataset size. After the model training, its state will be flagged as **Active**.\n\nDelete a custom model\n---------------------\n\nBefore you start, make sure that there is no traffic routed to your Custom Speech-to-Text model through any endpoint, because deleting it will stop it from serving any requests.\n\n1. Navigate to the **Models** tab of the **Custom Models** section.\n2. Click to expand options and then click **Delete**. In a few moments the Custom Speech-to-Text model will be deleted, along with all of its endpoints, and will no longer serve any traffic.\n\nList your custom models\n-----------------------\n\nBy selecting the **Models** in the **Custom Models** section, you can also list all of your Custom Speech-to-Text models, including the ones that are training, active, and deleting.\n\nWhat's next\n-----------\n\nFollow the resources to take advantage of custom speech models in your application:\n\n- [Deploy and manage model endpoints](/speech-to-text/v2/docs/custom-speech-models/deploy-model).\n- [Use your custom models](/speech-to-text/v2/docs/custom-speech-models/use-model)\n- [Evaluate your custom models](/speech-to-text/v2/docs/custom-speech-models/evaluate-model)"]]