Utilizzando l'API, senza codice, puoi creare e addestrare un modello Speech-to-Text personalizzato per migliorare l'accuratezza del riconoscimento da un modello Speech-to-Text esistente. Questo servizio completamente gestito esegue automaticamente il provisioning delle risorse di calcolo, esegue il codice dell'applicazione di addestramento e garantisce l'eliminazione delle risorse di calcolo dopo il job di addestramento. Ottieni un modello di trascrizione completamente ottimizzato utile per qualsiasi applicazione downstream.
Analogamente ai modelli di machine learning, l'addestramento di un modello Speech-to-Text personalizzato è in genere iterativo e prevede la selezione di un modello di base come punto di partenza, l'ottimizzazione con i set di dati di testo e audio e il test della qualità del riconoscimento del modello. Se i risultati non sono quelli che ti aspettavi, puoi addestrare un nuovo modello con una diversa combinazione di dati, eseguire nuovamente il test o utilizzarlo direttamente per la trascrizione nel tuo dominio.
Prima di iniziare
Assicurati di aver creato un account Google Cloud , un progetto Google Cloud e di aver abilitato l'API Speech-to-Text: vai a Speech nella console Google Cloud e vai all'API Speech-to-Text. Operare nella sezione Modelli personalizzati della barra di navigazione a sinistra.
Crea un modello personalizzato
Inizia creando un modello Speech-to-Text personalizzato e definendo i relativi parametri, come il modello di base e la lingua della trascrizione:
- Fai clic su Crea per creare un modello personalizzato.
- Inserisci un nome modello, che verrà utilizzato per la visualizzazione e a cui verrà fatto riferimento nelle richieste API e nella console Speech. Google Cloud
- Inserisci una Descrizione per il modello.
- Seleziona un modello di base più adatto al tuo caso d'uso.
- Seleziona la lingua della trascrizione del modello.
- Seleziona la Regione in cui deve avvenire l'addestramento.
- Fai clic su Continua.
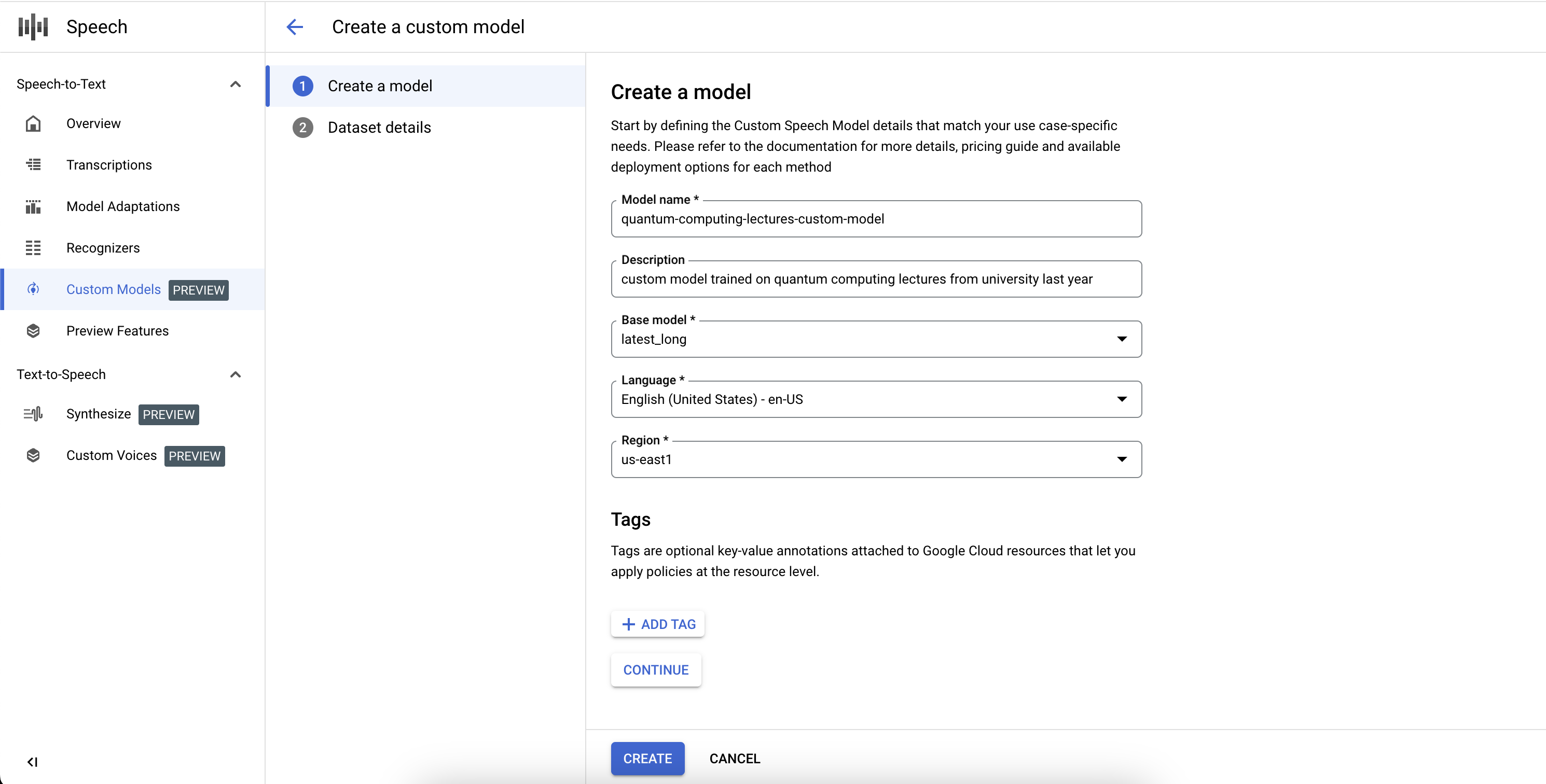
Per completare la definizione del job del modello Custom Speech-to-Text e avviare l'addestramento, devi definire i set di dati di addestramento e convalida.
- Seleziona un set di dati di addestramento fornendo un URI di directory Cloud Storage valido. Assicurati che siano presenti solo file audio e di testo e che la durata totale dell'audio rispetti i requisiti del set di dati di addestramento.
- Seleziona un set di dati di convalida fornendo un URI di directory Cloud Storage valido. Assicurati che siano presenti solo file audio e di testo e che la durata totale dell'audio rispetti i requisiti del set di dati di convalida.
- Fai clic su Crea per avviare la procedura di addestramento.
Se non vengono indicizzate ore di audio sufficienti o se i file non rispettano le linee guida, il job di addestramento non andrà a buon fine.
I job di addestramento possono essere messi in coda dietro ad altri job nel nostro sistema e l'addestramento di un modello può richiedere da un paio d'ore a qualche giorno, a seconda delle dimensioni del set di dati. Dopo l'addestramento del modello, il suo stato verrà contrassegnato come Attivo.
Eliminare un modello personalizzato
Prima di iniziare, assicurati che non ci sia traffico indirizzato al tuo modello Custom Speech-to-Text tramite alcun endpoint, perché l'eliminazione impedirà di gestire le richieste.
- Vai alla scheda Modelli della sezione Modelli personalizzati.
- Fai clic per espandere le opzioni e poi fai clic su Elimina. Tra qualche istante, il modello Custom Speech-to-Text verrà eliminato, insieme a tutti i relativi endpoint, e non gestirà più il traffico.
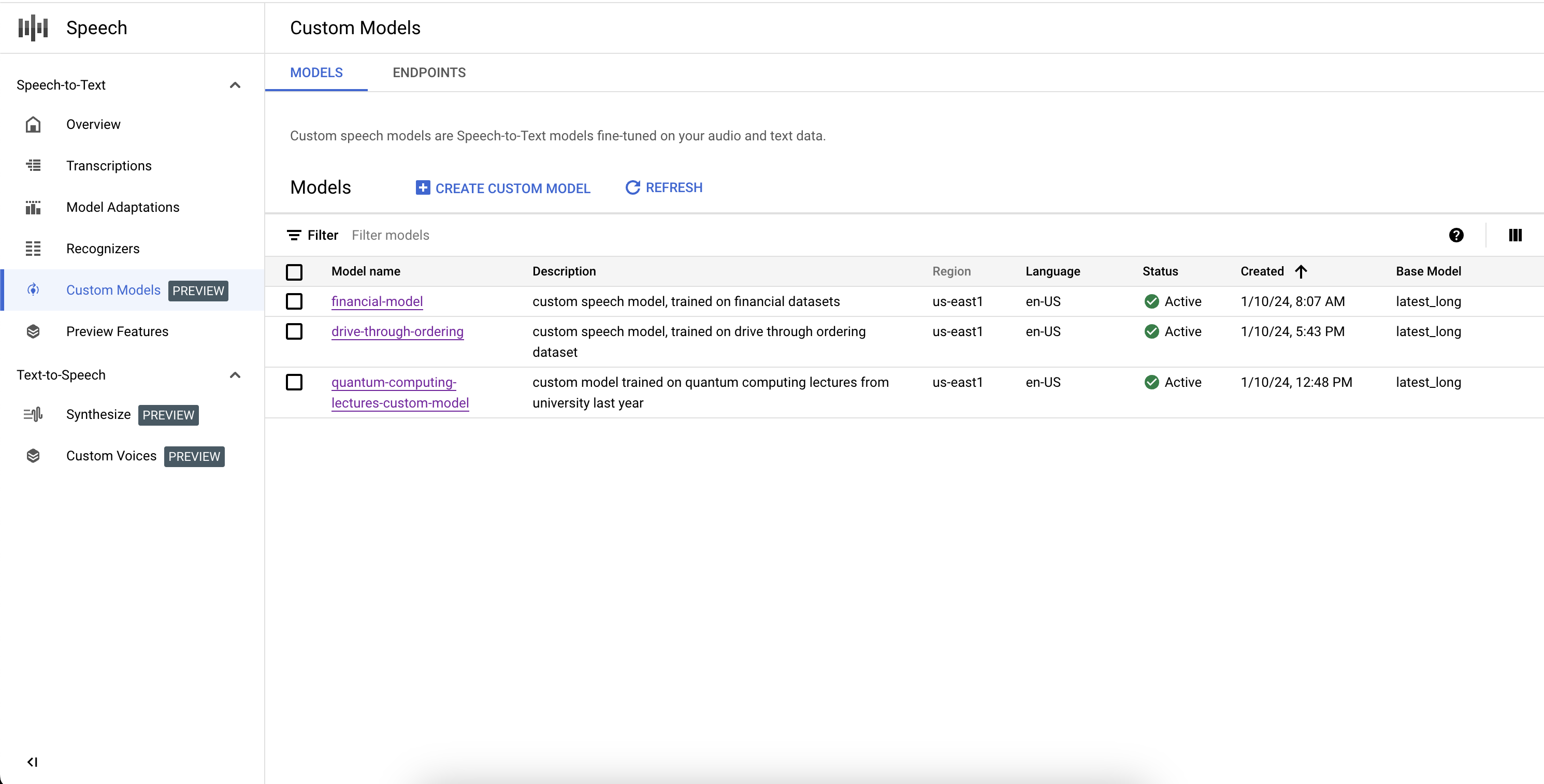
Elencare i modelli personalizzati
Se selezioni Modelli nella sezione Modelli personalizzati, puoi anche elencare tutti i tuoi modelli personalizzati di Speech-to-Text, inclusi quelli in fase di addestramento, attivi ed eliminati.
Passaggi successivi
Consulta le risorse per sfruttare i modelli vocali personalizzati nella tua applicazione:
- Esegui il deployment e gestisci gli endpoint dei modelli .
- Utilizzare i modelli personalizzati
- Valutare i modelli personalizzati