クライアント
Spanner は SQL クエリをサポートします。クエリの例を次に示します。
SELECT s.SingerId, s.FirstName, s.LastName, s.SingerInfo
FROM Singers AS s
WHERE s.FirstName = @firstName;
@firstName は、クエリパラメータの参照です。クエリ パラメータは、リテラル値を使用できる場所であればどこでも使用できます。プログラマティック API のパラメータを使用することをおすすめします。クエリ パラメータを使用すると SQL インジェクション攻撃の防止に役立ち、生成されるクエリでさまざまなサーバー側キャッシュのメリットを活用できる可能性が高くなります。以下のキャッシュをご覧ください。
クエリ パラメータは、クエリが実行されるときに値にバインドされる必要があります。次に例を示します。
Statement statement =
Statement.newBuilder("SELECT s.SingerId...").bind("firstName").to("Jimi").build();
try (ResultSet resultSet = dbClient.singleUse().executeQuery(statement)) {
while (resultSet.next()) {
...
}
}
Spanner は、API 呼び出しを受け取ると、クエリとバインドされたパラメータを分析して、クエリを処理する必要がある Spanner ノードを決定します。サーバーは、ResultSet.next() の呼び出しによって消費された結果行のストリームを返送します。
クエリ実行
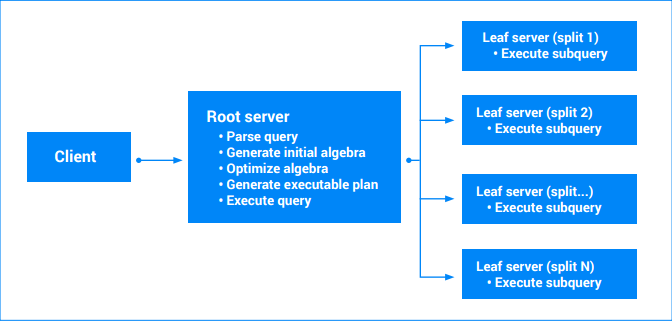
クエリの実行は、Spanner サーバーに「クエリ実行」リクエストが到着すると開始されます。サーバーは次の手順を実行します。
- リクエストを検証します
- クエリテキストを解析します
- 初期クエリ代数を生成します
- 最適化されたクエリ代数を生成します
- 実行可能なクエリプランを生成します
- プランを実行します(権限の確認、データの読み取り、結果のエンコードなど)
解析
SQL パーサーはクエリテキストを解析し、それを抽象構文ツリーに変換します。基本的なクエリ構造 (SELECT …
FROM … WHERE …) を抽出し、構文チェックを行います。
代数
Spanner の型システムは、スカラー、配列、構造体などを表すことができます。クエリ代数は、テーブル スキャン、フィルタリング、並べ替え / グループ化、あらゆる種類の結合、集計などの演算子を定義します。初期クエリ代数は、パーサーの出力から構築されます。解析ツリー内のフィールド名の参照は、データベース スキーマを使用して解決されます。また、このコードでは、セマンティック エラー(パラメータの数が正しくない、型の不一致など)がチェックされます。
次のステップ(クエリの最適化)では、初期代数から、より最適な代数が生成されます。最適化された代数は、より簡単、より効率的、または実行エンジンの機能により適している可能性があります。たとえば、初期代数では「結合」だけが指定されている一方、最適化された代数では「ハッシュ結合」が指定されている場合があります。
実行
最後の実行可能なクエリプランは、書き換えられた代数から作成されます。基本的に、実行可能なプランは、「イテレータ」の有向非巡回グラフです。各イテレータは一連の値を公開します。イテレータは、入力を使用して出力を生成する場合があります(並べ替えイテレータなど)。単一のスプリットを含むクエリは、単一のサーバー(データを保持するサーバー)で実行できます。サーバーは、さまざまなテーブルから範囲をスキャンし、結合、集計、クエリ代数によって定義されている他のすべてのオペレーションを実行します。
複数のスプリットを含むクエリは、複数の部分に分割されます。クエリの一部は、引き続きメイン(ルート)サーバー上で実行されます。他の部分的なサブクエリは、リーフノード(読み取られるスプリットを所有しているノード)に渡されます。複雑なクエリではこの引き渡しを再帰的に適用することができ、サーバー実行のツリーが生成されます。すべてのサーバーは、照会結果がデータの一貫したスナップショットになるように、タイムスタンプで同期を取ります。各リーフサーバーは、部分的な結果のストリームを返送します。集計を含むクエリでは、これらは部分的に集計された結果である場合があります。クエリ ルートサーバーはリーフサーバーからの結果を処理し、残りのクエリプランを実行します。詳細については、クエリ実行プランをご覧ください。
クエリに複数のスプリットが含まれる場合、Spanner はスプリット間でクエリを並行して実行できます。並列処理の程度は、クエリがスキャンするデータ範囲、クエリ実行プラン、スプリット間でのデータ分散によって異なります。Spanner では、最適なクエリ パフォーマンスを実現し、CPU の過負荷を避けるために、インスタンスのサイズとインスタンス構成(リージョンまたはマルチリージョン)に基づいて、クエリの最大並列度が自動的に設定されます。
キャッシュ
クエリ処理のアーティファクトの多くは、自動的にキャッシュされて、後続のクエリに再利用されます。これには、クエリ代数、実行可能なクエリプランなどが含まれます。キャッシュは、クエリテキスト、バインドされたパラメータの名前と型などに基づきます。クエリテキストでリテラル値を使用するよりも、バインドされたパラメータ(上の例での @firstName など)を使用する方が適切であるのはこのためです。前者は、一度キャッシュされると、バインドされた実際の値に関係なく再利用できます。詳細については、Spanner のクエリ パフォーマンスの最適化をご覧ください。
エラー処理
executeQuery メソッドからの結果行のストリームは、一時的なネットワーク エラー、あるサーバーから別のサーバーへのスプリットの引き渡し(負荷分散など)、サーバーの再起動(新しいバージョンへのアップグレードなど)など、さまざまな理由で中断される可能性があります。このようなエラーからの回復に役立つように、Spanner では、部分的な結果データのバッチとともに、不透明な「再開トークン」を送信します。これらの再開トークンは、クエリを中断されたところから続行するために使用できます。Spanner クライアント ライブラリを使用している場合、これは自動的に行われます。したがって、クライアント ライブラリのユーザーは、この種の一時的な障害を心配する必要はありません。