En esta página se indican las cuotas y los límites de producción de Spanner. En la consola, los términos "cuota" y "límite" se pueden usar indistintamente. Google Cloud
Los valores de las cuotas y los límites están sujetos a cambios.
Permisos para comprobar y editar cuotas
Para ver tus cuotas, debes tener el permiso serviceusage.quotas.get de Gestión de Identidades y Accesos (IAM).
Para cambiar las cuotas, debes tener el permiso de IAM
serviceusage.quotas.update. que está incluido de forma predeterminada en los siguientes roles predefinidos: Propietario, Editor y Administrador de cuota.
Estos permisos se incluyen de forma predeterminada en los roles básicos de IAM Propietario y Editor, así como en el rol predefinido Administrador de cuota.
Consultar las cuotas
Para consultar las cuotas actuales de los recursos de tu proyecto, usa laGoogle Cloud consola:
Aumentar las cuotas
Las cuotas pueden ir aumentando conforme crece el uso que das a Spanner. Si crees que el uso va a aumentar considerablemente, te recomendamos que solicites un aumento con unos días de antelación para asegurarte de que dispones de las cuotas adecuadas.
También es posible que tengas que aumentar la anulación de la cuota de consumidor. Para obtener más información, consulta el artículo sobre cómo crear una anulación de cuota de consumidor.
Puedes aumentar el límite de nodos de configuración de tu instancia de Spanner actual mediante la consola Google Cloud .
Ve a la página Cuotas.
Selecciona API de Spanner en la lista desplegable Servicio.
Si no ves API de Spanner, significa que la API de Spanner no está habilitada. Para obtener más información, consulta Habilitar APIs.
Elige las cuotas que quieras modificar.
Haz clic en Editar cuotas.
En el panel Cambios en la cuota que aparece, introduce el nuevo límite de cuota.
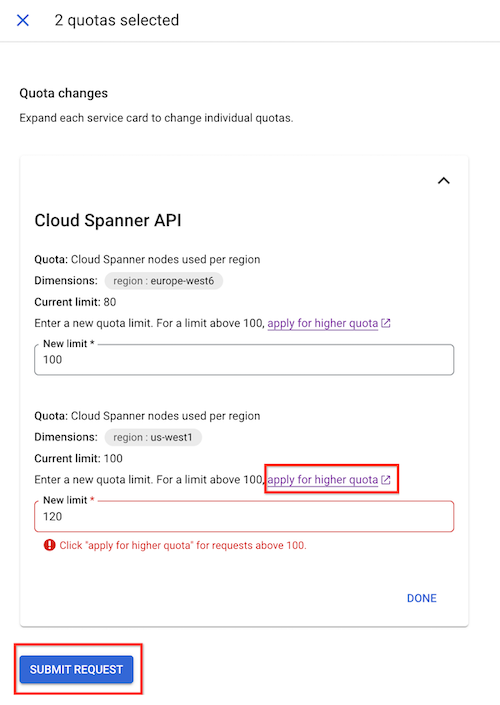
Haz clic en Hecho y, a continuación, en Enviar solicitud.
Si no puedes aumentar el límite de nodos manualmente hasta el valor que quieras, haz clic en Solicitar un aumento de cuota. Rellena el formulario para enviar una solicitud al equipo de Spanner. Recibirás una respuesta en un plazo de 48 horas desde que envíes la solicitud.
Aumentar la cuota de una configuración de instancia personalizada
Puedes aumentar la cuota de nodos de tu configuración de instancia personalizada.
Para comprobar el límite de nodos de una configuración de instancia personalizada, consulta el límite de nodos de la configuración de instancia base.
Usa el comando show instance configurations detail si no sabes o no recuerdas la configuración base de tu configuración de instancia personalizada.
Si el límite de nodos necesario para la configuración de tu instancia personalizada es inferior a 85, sigue las instrucciones de la sección anterior Aumentar las cuotas. Usa la Google Cloud consola para aumentar el límite de nodos de la configuración de instancia base asociada a tu configuración de instancia personalizada.
Si el límite de nodos que necesitas para la configuración de tu instancia personalizada es superior a 85, rellena el formulario Solicitar un aumento de cuota para tus nodos de Spanner. Especifica el ID de tu configuración de instancia personalizada en el formulario.
Límites de los nodos
| Valor | Límite |
|---|---|
| Nodos por configuración de instancia |
Los límites predeterminados varían según la configuración del proyecto y de la instancia. Para cambiar los límites de cuota de un proyecto o solicitar un aumento de los límites, consulta Aumentar las cuotas. |
Límites de las instancias
| Valor | Límite |
|---|---|
| Longitud del ID de la instancia | De 2 a 64 caracteres |
Límites de las instancias de prueba gratuitas
Una instancia de prueba gratuita de Spanner tiene los siguientes límites adicionales. Para aumentar o eliminar estos límites, actualiza tu instancia de prueba gratuita a una de pago.
| Valor | Límite |
|---|---|
| Capacidad de almacenamiento | 10 GiB |
| Límite de la base de datos | Crear hasta cinco bases de datos |
| Funciones no compatibles | Copia de seguridad y restauración |
| Acuerdo de nivel de servicio | Sin SLA |
| Duración de la prueba | Periodo de prueba gratuita de 90 días |
Límites de las particiones geográficas
| Valor | Límite |
|---|---|
| Número máximo de particiones por instancia | 20 |
| Número máximo de filas de colocación por nodo en tu partición | 100 millones |
Límites de las consultas guardadas
| Valor | Límite |
|---|---|
| Número máximo de consultas guardadas por proyecto (incluidas las consultas guardadas de otros productos de Google Cloud ) | 10.000 |
| Tamaño máximo de cada consulta | 1 MiB |
Límites de configuración de instancias
| Valor | Límite |
|---|---|
| Número máximo de configuraciones de instancias personalizadas por proyecto | 100 |
| Longitud del ID de configuración de instancia personalizada | Entre 8 y 64 caracteres Un ID de configuración de instancia personalizado debe empezar por |
Límites de las bases de datos
| Valor | Límite |
|---|---|
| Bases de datos por instancia |
|
| Roles por base de datos | 100 |
| Longitud del ID de la base de datos | De 2 a 30 caracteres |
| Tamaño del almacenamiento1 |
En la mayoría de las configuraciones de instancias de Spanner regionales, birregionales y multirregionales, se puede aumentar la capacidad de almacenamiento a 10 TiB por nodo. Para obtener más información, consulta el artículo Mejoras de rendimiento y almacenamiento. Si usas almacenamiento por niveles, puedes usar un almacenamiento combinado (SSD y HDD) de hasta 10 TiB por nodo. Las copias de seguridad se almacenan por separado y no se tienen en cuenta a la hora de calcular este límite. Para obtener más información, consulta Métricas de utilización del almacenamiento. Ten en cuenta que Spanner factura el almacenamiento real utilizado en una instancia, no el almacenamiento total disponible. |
Límites de copias de seguridad y restauración
| Valor | Límite |
|---|---|
| Número de operaciones de creación de copias de seguridad en curso por base de datos | 1 |
| Número de operaciones de restauración de bases de datos en curso por instancia (en la instancia de la base de datos restaurada, no de la copia de seguridad) | 10 |
| Tiempo máximo de conservación de la copia de seguridad | 1 año (incluido el día extra en los años bisiestos) |
Límites de los esquemas
Objetos de esquema
| Valor | Límite |
|---|---|
| El número total de objetos de esquema de todas las bases de datos de la misma instancia | Los límites predeterminados varían según la configuración de la instancia.2 |
Declaraciones DDL
| Valor | Límite |
|---|---|
| Tamaño de la declaración DDL para un único cambio de esquema | 10 MiB |
Tamaño de la declaración DDL para el esquema completo de una base de datos devuelta por GetDatabaseDdl |
10 MiB |
Gráficos
| Valor | Límite |
|---|---|
| Gráficos de propiedades por base de datos | 16 |
| Longitud del nombre del gráfico de propiedades | De 1 a 128 caracteres |
Tablas
| Valor | Límite |
|---|---|
| Tablas por base de datos | 5000 |
| Longitud del nombre de la tabla | De 1 a 128 caracteres |
| Columnas por tabla | 1024 |
| Longitud del nombre de la columna | De 1 a 128 caracteres |
| Tamaño máximo de los datos por celda | 10 MiB |
Tamaño de una celda STRING |
2.621.440 caracteres Unicode |
| Número de columnas de una clave de tabla | 16 Incluye las columnas de clave compartidas con cualquier tabla principal |
| Profundidad de intercalado de la tabla | 7 Una tabla de nivel superior con tablas secundarias tiene una profundidad de 1. Una tabla de nivel superior con tablas nietas tiene una profundidad de 2, y las tablas anidadas posteriores aumentan la profundidad en consecuencia. |
| Tamaño máximo de una clave principal o de índice por fila | 8 KiB Incluye el tamaño de todas las columnas que componen la clave |
| Tamaño total de las columnas que no son clave por fila | 1600 MiB Incluye el tamaño de todas las columnas que no son de clave por fila de una tabla |
Índices
| Valor | Límite |
|---|---|
| Índices por base de datos | 10.000 |
| Índices por tabla | 128 |
| Longitud del nombre del índice | De 1 a 128 caracteres |
| Número de columnas de una clave de índice | 16 Número de columnas indexadas (salvo las columnas STORING) más el número de columnas de clave principal de la tabla base |
Vistas
| Valor | Límite |
|---|---|
| Vistas por base de datos | 5000 |
| Longitud del nombre de la vista | De 1 a 128 caracteres |
| Profundidad de anidación | 10 Una vista que hace referencia a otra vista tiene una profundidad de anidación de 1. Una vista que hace referencia a otra vista que, a su vez, hace referencia a otra vista tiene una profundidad de anidación de 2, y así sucesivamente. |
Grupos de localidades
| Valor | Límite |
|---|---|
| Número máximo de grupos de localidad por base de datos | 16 (1 grupo de ubicaciones predeterminado y 15 grupos de ubicaciones adicionales opcionales) |
Tiempo mínimo necesario en la opción ssd_to_hdd_spill_timespan |
1 hora |
Tiempo máximo permitido en la opción ssd_to_hdd_spill_timespan |
365 días |
Límites de las consultas
| Valor | Límite |
|---|---|
Columnas en una cláusula GROUP BY |
1000 |
Valores de un operador IN |
10.000 |
| Llamadas de funciones | 1000 |
| Uniones | 20 |
| Llamadas de funciones anidadas | 75 |
Cláusulas GROUP BY anidadas |
35 |
| Expresiones de subconsultas anidadas | 25 |
| Declaraciones de subselección anidadas | 60 |
| Uniones producidas por una consulta de gráfico | 100 |
| Parámetros | 950 |
| Longitud de la declaración de consulta | 1 millón de caracteres |
STRUCT campos |
1000 |
| Elementos secundarios de la expresión de subconsulta | 50 |
| Combinaciones en una consulta | 200 |
| Profundidad del recorrido de rutas cuantificadas de gráficos | 100 |
Límites para crear, leer, actualizar y eliminar datos
| Valor | Límite |
|---|---|
| Tamaño de confirmación (incluidos los índices y los flujos de cambios) | 100 MiB |
| Lecturas simultáneas por sesión | 100 |
| Mutaciones por confirmación (incluidos los índices)3 | 80.000 |
| Mutaciones por grupo de mutaciones en una solicitud de escritura por lotes | 80.000 |
| Declaraciones simultáneas de DML particionado por base de datos | 20.000 |
Límites de las acciones administrativas
| Valor | Límite |
|---|---|
| Tamaño de solicitud de acciones administrativas4 | 1 MiB |
| Límite de frecuencia de acciones administrativas5 | 5 por segundo, proyecto y usuario (promediado durante 100 segundos) |
Límites de solicitudes
| Valor | Límite |
|---|---|
| Tamaño de solicitud excepto confirmaciones6 | 10 MiB |
Cambiar los límites de las emisiones
| Valor | Límite |
|---|---|
| Flujos de cambios por base de datos | 10 |
| Cambiar el flujo de datos de cualquier columna que no sea clave7 | 3 |
| Lectores simultáneos por partición de datos de flujo de cambios8 | 20 |
Límites de Data Boost
| Valor | Límite |
|---|---|
| Solicitudes simultáneas de Data Boost por proyecto en us-central1 | 1000 9 |
| Solicitudes simultáneas de Data Boost por proyecto y región en otras regiones | 400 9 |
Límites de la API de predivisión
| Valor | Límite |
|---|---|
| Puntos de división añadidos por solicitud a la API | 100 |
| Tamaño de la solicitud a la API de punto de división | 1 MiB |
| Puntos de división añadidos por nodo en todas las bases de datos de la instancia. | 50 |
| Puntos de división añadidos o actualizados por minuto y por nodo | 10 |
| Puntos de división añadidos o actualizados por día y por nodo | 200 |
Notas
1. Para ofrecer alta disponibilidad y baja latencia al acceder a una base de datos, Spanner define límites de almacenamiento en función de la capacidad de computación de la instancia:
- En el caso de las instancias más pequeñas que 1 nodo (1000 unidades de procesamiento), Spanner asigna 1024,0 GiB de datos por cada 100 unidades de procesamiento de la base de datos.
- En las instancias de 1 nodo o más, Spanner asigna 10 TiB de datos a cada nodo.
Por ejemplo, para crear una instancia de una base de datos de 1500 GiB, debes definir su capacidad de computación en 200 unidades de procesamiento. Esta cantidad de capacidad de computación mantendrá la instancia por debajo del límite hasta que la base de datos alcance los 2048,0 GiB. Cuando la base de datos alcance este tamaño, tendrás que añadir otras 100 unidades de procesamiento para permitir que la base de datos crezca. De lo contrario, es posible que se rechacen las operaciones de escritura en la base de datos. Para obtener más información, consulta Recomendaciones para el uso del almacenamiento de bases de datos.
Para que el crecimiento sea fluido, añade capacidad de computación antes de que la base de datos alcance el límite.
2. Los objetos de esquema contabilizados incluyen todos los tipos de objetos descritos en DDL, como tablas, columnas, índices, secuencias, etc. El límite de objetos de esquema se aplica a nivel de instancia y depende de las unidades de procesamiento disponibles para tu instancia.
- En las instancias de un nodo o más, el límite predeterminado es de un millón de objetos.
- En el caso de las instancias más pequeñas que un nodo (1000 unidades de procesamiento), el límite se reduce proporcionalmente al tamaño de la instancia. Por ejemplo, el límite es de 100.000 objetos de esquema para instancias con 100 unidades de procesamiento.
Para comprobar el número de objetos de esquema de tus bases de datos y el límite de objetos de tu instancia, busca las métricas spanner.googleapis.com/instance/schema_objects y spanner.googleapis.com/instance/schema_object_count en Explorador de métricas.
Para obtener más información sobre la monitorización, consulta el artículo Monitorizar instancias con Cloud Monitoring.
Si alcanzas el límite, Spanner te impedirá realizar operaciones que lo superen, como las siguientes:
- Modificar el esquema de la base de datos (por ejemplo, añadir un índice).
- Creando una base de datos en la instancia.
- Restaurar una base de datos desde una copia de seguridad en la misma instancia. En este caso, puedes restaurar la copia de seguridad en otra instancia con la misma configuración o crear una instancia con la misma configuración y restaurar la copia de seguridad en la nueva instancia.
3. En las operaciones de inserción y actualización, se tiene en cuenta la multiplicidad del número de columnas a las que afectan. Las columnas de clave principal siempre se ven afectadas. Por ejemplo, si para insertar un nuevo registro se deben insertar valores en cinco columnas, se contabilizará como cinco mutaciones. Si se actualizan tres columnas de un registro, también se pueden contabilizar como cinco mutaciones si el registro tiene dos columnas de clave principal. Las operaciones de eliminación y de eliminación de intervalos cuentan como una sola mutación, independientemente del número de columnas afectadas.
Eliminar una fila de una tabla principal que tiene la anotación ON DELETE
CASCADE también se cuenta como una mutación, independientemente del número de filas secundarias intercaladas que haya. La excepción es que, si se han definido índices secundarios en las filas que se van a eliminar, los cambios en dichos índices se cuentan uno por uno. Por ejemplo, si una tabla tiene 2 índices secundarios, eliminar un intervalo de filas de la tabla se contabilizará como 1 mutación para la tabla, más 2 mutaciones por cada fila que se elimine, ya que las filas del índice secundario pueden estar dispersas por el espacio de claves, lo que impide que Spanner llame a una sola operación de eliminación de intervalo en los índices secundarios. Los índices secundarios incluyen los índices de reserva de las claves externas.
Para consultar el número de mutaciones de una transacción, consulta el artículo Extraer estadísticas de confirmación de una transacción.
Los flujos de cambios no añaden ninguna mutación que se tenga en cuenta para este límite.
4. El límite de las solicitudes de acciones administrativas excluye las confirmaciones, las solicitudes indicadas en la nota 9 y los cambios de esquema.
5. Este límite de frecuencia incluye todas las llamadas a la API de administración, como llamadas a sondeos de operaciones de larga duración en una instancia, una base de datos o una copia de seguridad.
6. Este límite incluye las solicitudes para crear y actualizar una base de datos, realizar operaciones de lectura, transmitir lecturas, ejecutar consultas SQL y ejecutar consultas SQL de transmisión.
7. Un flujo de cambios que monitoriza una tabla o una base de datos completas monitoriza implícitamente todas las columnas de esa tabla o base de datos y, por lo tanto, se tiene en cuenta para este límite.
8. Este límite se aplica a los lectores simultáneos de la misma partición de flujos de cambios, ya sean canalizaciones de Dataflow o consultas directas a la API.
9. Los límites predeterminados varían según el proyecto y la región. Para obtener más información, consulta el artículo Monitorizar y gestionar el uso de la cuota de Data Boost.