Prácticas recomendadas de escalado para Cloud Service Mesh en GKE
En esta guía se describen las prácticas recomendadas para resolver problemas de escalado en arquitecturas de Cloud Service Mesh gestionadas en Google Kubernetes Engine. El objetivo principal de estas recomendaciones es asegurar un rendimiento, una fiabilidad y un uso de recursos óptimos para tus aplicaciones de microservicios a medida que crecen.
Para conocer las limitaciones de escalabilidad, consulta los límites de escalabilidad de Cloud Service Mesh.
La escalabilidad de Cloud Service Mesh en GKE depende del funcionamiento eficiente de sus dos componentes principales: el plano de datos y el plano de control. Este documento se centra principalmente en escalar el plano de datos.
Identificar problemas de escalado del plano de control y del plano de datos
En Cloud Service Mesh, los problemas de escalado pueden producirse en el plano de control o en el plano de datos. Para identificar el tipo de problema de escalado que tienes, sigue estos pasos:
Síntomas de problemas de escalado del plano de control
Descubrimiento de servicios lento: los nuevos servicios o endpoints tardan mucho en descubrirse y estar disponibles.
Retrasos en la configuración: los cambios en las reglas de gestión del tráfico o en las políticas de seguridad tardan mucho en propagarse.
Aumento de la latencia en las operaciones del plano de control: las operaciones como la creación, la actualización o la eliminación de recursos de Cloud Service Mesh se vuelven lentas o no responden.
Errores relacionados con Traffic Director: es posible que observes errores en los registros de Cloud Service Mesh o en las métricas del plano de control que indiquen problemas de conectividad, agotamiento de recursos o limitación de la API.
Ámbito del impacto: los problemas del plano de control suelen afectar a toda la malla, lo que provoca una degradación generalizada del rendimiento.
Síntomas de problemas de escalado del plano de datos
Mayor latencia en la comunicación entre servicios: las solicitudes a un servicio de la malla experimentan una mayor latencia o tiempos de espera, pero no hay un uso elevado de CPU o memoria en los contenedores del servicio.
Uso elevado de CPU o memoria en los proxies de Envoy: un uso elevado de CPU o memoria puede indicar que los proxies tienen dificultades para gestionar la carga de tráfico.
Impacto localizado: los problemas del plano de datos suelen afectar a servicios o cargas de trabajo específicos, en función de los patrones de tráfico y la utilización de recursos de los proxies de Envoy.
Escalar el plano de datos
Para escalar el plano de datos, prueba las siguientes técnicas:
- Configurar el autoescalado de pods horizontal (HPA)
- Optimizar la configuración del proxy de Envoy
- Monitorizar y optimizar
Configurar el autoescalado horizontal de pods (HPA) para cargas de trabajo
Usa el autoescalado horizontal de pods (HPA) para escalar dinámicamente las cargas de trabajo con pods adicionales en función del uso de los recursos. Ten en cuenta lo siguiente al configurar HPA:
Usa el parámetro
--horizontal-pod-autoscaler-sync-periodparakube-controller-managerajustar la frecuencia de sondeo del controlador HPA. La frecuencia de sondeo predeterminada es de 15 segundos, pero puedes reducirla si esperas picos de tráfico más rápidos. Para obtener más información sobre cuándo usar HPA con GKE, consulta Autoescalado horizontal de pods.El comportamiento de escalado predeterminado puede provocar que se despliegue (o se finalice) un gran número de pods a la vez, lo que puede provocar un pico en el uso de recursos. Plantéate usar políticas de escalado para limitar la velocidad a la que se pueden implementar los pods.
Usa EXIT_ON_ZERO_ACTIVE_CONNECTIONS para evitar que se interrumpan las conexiones durante la reducción.
Para obtener más información sobre HPA, consulta la sección Autoescalado de pods horizontal de la documentación de Kubernetes.
Optimizar la configuración del proxy Envoy
Para optimizar la configuración del proxy Envoy, ten en cuenta las siguientes recomendaciones:
Límites de recursos
Puedes definir solicitudes y límites de recursos para los sidecars de Envoy en las especificaciones de tu pod. De esta forma, se evita la contención de recursos y se garantiza un rendimiento constante.
También puedes configurar los límites de recursos predeterminados de todos los proxies de Envoy de tu malla mediante anotaciones de recursos.
Los límites de recursos óptimos para tus proxies de Envoy dependen de factores como el volumen de tráfico, la complejidad de la carga de trabajo y los recursos de los nodos de GKE. Monitoriza y ajusta continuamente tu malla de servicios para asegurar un rendimiento óptimo.
Consideración importante:
- Calidad del servicio (QoS): si defines tanto las solicitudes como los límites, te aseguras de que tus proxies de Envoy tengan una calidad del servicio predecible.
Dependencias de servicios de ámbito
Te recomendamos que recortes el gráfico de dependencias de tu malla declarando todas tus dependencias a través de la API Sidecar. Esto limita el tamaño y la complejidad de la configuración enviada a una carga de trabajo determinada, lo cual es fundamental para las mallas más grandes.
Por ejemplo, a continuación se muestra el gráfico de tráfico de la aplicación de ejemplo de una boutique online.
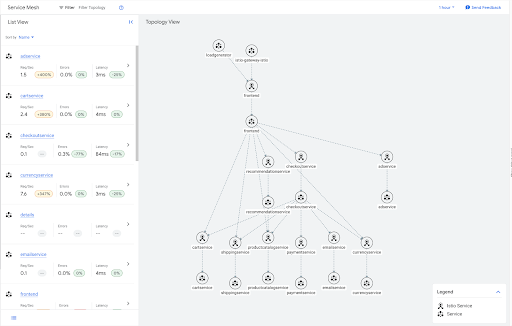
Muchos de estos servicios son hojas del gráfico y, como tales, no necesitan tener información de salida para ninguno de los demás servicios de la malla. Puedes aplicar un recurso Sidecar que limite el ámbito de la configuración de Sidecar para estos servicios hoja, como se muestra en el siguiente ejemplo.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: leafservices
namespace: default
spec:
workloadSelector:
labels:
app: cartservice
app: shippingservice
app: productcatalogservice
app: paymentservice
app: emailservice
app: currencyservice
egress:
- hosts:
- "~/*"
Consulta la aplicación de ejemplo Online Boutique para obtener información sobre cómo desplegarla.
Otra ventaja del ámbito de sidecar es que se reducen las consultas de DNS innecesarias. Las dependencias de servicio de ámbito aseguran que un sidecar de Envoy solo haga consultas de DNS para los servicios con los que se va a comunicar en lugar de para todos los clústeres de la malla de servicios.
En el caso de los despliegues a gran escala que tengan problemas con tamaños de configuración grandes en sus sidecars, se recomienda encarecidamente acotar las dependencias de los servicios para mejorar la escalabilidad de la malla.
Para limitar el ámbito de configuración de todas las cargas de trabajo de un mismo espacio de nombres, crea un recurso Sidecar en ese espacio de nombres. De esta forma, se indica a todos los proxies de Envoy de ese espacio de nombres que solo reciban la configuración de los servicios de su propio espacio de nombres.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidecar
namespace: my-app
spec:
egress:
- hosts:
- "my-app/*"
Puedes aplicar un comportamiento predeterminado a todos los espacios de nombres de tu malla aplicando un único recurso Sidecar al espacio de nombres raíz, normalmente istio-system.
El siguiente Sidecar restringe el tráfico de salida de cada sidecar de la malla a los servicios ubicados en su propio espacio de nombres.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidear
namespace: istio-system
spec:
egress:
- hosts:
- "./*"
Ten en cuenta que Cloud Service Mesh impone un límite en el número total de recursos de Sidecar que se pueden crear en una sola malla. Debido a esta restricción, se recomienda crear Sidecars a nivel de espacio de nombres.
Monitorizar y optimizar
Después de definir los límites de recursos iniciales, es fundamental monitorizar tus proxies de Envoy para asegurarte de que funcionan de forma óptima. Usa los paneles de control de GKE para monitorizar el uso de CPU y memoria, y ajusta los límites de recursos según sea necesario.
Para determinar si un proxy de Envoy requiere límites de recursos más altos, monitoriza su consumo de recursos en condiciones de tráfico típicas y máximas. Esto es lo que debes buscar:
Uso elevado de la CPU: si el uso de la CPU de Envoy se acerca o supera constantemente su límite, puede que tenga problemas para procesar las solicitudes, lo que provoca un aumento de la latencia o la pérdida de solicitudes. Te recomendamos que aumentes el límite de CPU.
En este caso, puede que te inclines por escalar horizontalmente, pero si el proxy sidecar no puede procesar las solicitudes tan rápido como el contenedor de la aplicación, ajustar los límites de CPU puede dar los mejores resultados.
Uso elevado de memoria: si el uso de memoria de Envoy se acerca o supera su límite, puede que empiece a perder conexiones o que se produzcan errores de falta de memoria. Aumenta el límite de memoria para evitar estos problemas.
Registros de errores: examina los registros de Envoy para detectar errores relacionados con el agotamiento de recursos, como upstream connect error, disconnect or reset before headers o too many open files. Estos errores pueden indicar que el proxy necesita más recursos. Consulta los documentos de solución de problemas de escalado para ver otros errores relacionados con problemas de escalado.
Métricas de rendimiento: monitoriza métricas de rendimiento clave, como la latencia de las solicitudes, las tasas de error y el rendimiento. Si observas una degradación del rendimiento relacionada con una alta utilización de recursos, puede que sea necesario aumentar los límites.
Si defines y monitorizas de forma activa los límites de recursos de tus proxies del plano de datos, puedes asegurarte de que tu malla de servicios se escale de forma eficiente en GKE.
Escalar el plano de control
En esta sección se describen los ajustes que se deben realizar para escalar el plano de control.
Selectores de descubrimiento
Los selectores de descubrimiento son un campo de MeshConfig que te permite especificar el conjunto de espacios de nombres que los planos de control tienen en cuenta al calcular las actualizaciones de configuración de los sidecars.
De forma predeterminada, Cloud Service Mesh monitoriza todos los espacios de nombres del clúster. Esto puede suponer un cuello de botella para los clústeres grandes que no necesitan monitorizar todos los recursos.
Usa discoverySelectors para reducir la carga computacional del plano de control limitando el número de recursos de Kubernetes (como servicios, pods y endpoints) que se monitorizan y procesan.
Cuando se usa la implementación del plano de control TRAFFIC_DIRECTOR, Cloud Service Mesh solo crea recursos Google Cloud , como BackendServices y Network Endpoint Groups, para los recursos de Kubernetes de los espacios de nombres especificados en discoverySelectors.
Para obtener más información, consulta la sección Selectores de descubrimiento de la documentación de Istio.
Desarrollar la resiliencia
Puedes ajustar los siguientes ajustes para aumentar la resiliencia de tu malla de servicios:
Detección de valores atípicos
La detección de valores atípicos monitoriza los hosts de un servicio upstream y los elimina del grupo de balanceo de carga cuando alcanzan un determinado umbral de error.
- Configuración clave:
outlierDetection: ajustes que controlan la expulsión de los hosts que no están en buen estado del grupo de balanceo de carga.
- Ventajas: mantiene un conjunto de hosts en buen estado en el grupo de balanceo de carga.
Para obtener más información, consulta Detección de valores atípicos en la documentación de Istio.
Reintentos
Mitiga los errores transitorios reintentando automáticamente las solicitudes fallidas.
- Configuración clave:
attempts: número de intentos.perTryTimeout: tiempo de espera por intento. Define un valor inferior al tiempo de espera general. Determina cuánto tiempo esperará en cada intento de reintento.retryBudget: número máximo de reintentos simultáneos.
- Ventajas: mayor porcentaje de éxito de las solicitudes y menor impacto de los fallos intermitentes.
Factores que debes tener en cuenta:
- Idempotencia: asegúrate de que la operación que se está reintentando sea idempotente, es decir, que se pueda repetir sin efectos secundarios no deseados.
- Número máximo de reintentos: limita el número de reintentos (por ejemplo, 3 reintentos como máximo) para evitar bucles infinitos.
- Interrupción de circuitos: integra los reintentos con los interruptores para evitar que se reintente cuando un servicio falle de forma constante.
Para obtener más información, consulta la sección Reintentos de la documentación de Istio.
Tiempos de espera
Usa tiempos de espera para definir el tiempo máximo permitido para procesar las solicitudes.
- Configuración clave:
timeout: tiempo de espera de la solicitud de un servicio específico.idleTimeout: tiempo que una conexión puede permanecer inactiva antes de cerrarse.
- Ventajas: mejora la capacidad de respuesta del sistema, previene las fugas de recursos y refuerza la protección contra el tráfico malicioso.
Factores que debes tener en cuenta:
- Latencia de red: ten en cuenta el tiempo de ida y vuelta (RTT) previsto entre los servicios. Deja un margen por si hay retrasos inesperados.
- Gráfico de dependencias de servicios: en las solicitudes encadenadas, asegúrate de que el tiempo de espera de un servicio de llamada sea inferior al tiempo de espera acumulativo de sus dependencias para evitar errores en cascada.
- Tipos de operaciones: las tareas de larga duración pueden necesitar tiempos de espera significativamente más largos que las recuperaciones de datos.
- Gestión de errores: los tiempos de espera agotados deben activar la lógica de gestión de errores adecuada (por ejemplo, reintentos, alternativas o interrupción de circuitos).
Para obtener más información, consulta la sección Tiempos de espera de la documentación de Istio.
Monitorizar y optimizar
Te recomendamos que empieces con los ajustes predeterminados de los tiempos de espera, la detección de valores atípicos y los reintentos, y que los vayas ajustando gradualmente en función de los requisitos específicos de tu servicio y de los patrones de tráfico observados. Por ejemplo, consulta datos reales sobre cuánto suelen tardar tus servicios en responder. A continuación, ajusta los tiempos de espera para que coincidan con las características específicas de cada servicio o endpoint.
Telemetría
Usa la telemetría para monitorizar continuamente tu malla de servicios y ajustar su configuración para optimizar el rendimiento y la fiabilidad.
- Métricas: usa métricas completas, en concreto, volúmenes de solicitudes, latencia y tasas de error. Integración con Cloud Monitoring para la visualización y las alertas.
- Trazas distribuidas: habilita la integración de trazas distribuidas con Cloud Trace para obtener información valiosa sobre los flujos de solicitudes en tus servicios.
- Registro: configura el registro de acceso para obtener información detallada sobre las solicitudes y las respuestas.
Lecturas complementarias
- Para obtener más información sobre Cloud Service Mesh, consulta la información general sobre Cloud Service Mesh.
- Para obtener directrices generales sobre Site Reliability Engineering (SRE) en relación con la escalabilidad, consulta los capítulos Handling Overload (Gestionar la sobrecarga) y Addressing Cascading Failures (Abordar los fallos en cascada) del libro de SRE de Google.