Exporter des recommandations vers BigQuery
Présentation
Avec l'exportation BigQuery, vous pouvez afficher les instantanés quotidiens des recommandations pour votre organisation. Pour ce faire, utilisez le service de transfert de données BigQuery. Consultez cette documentation pour savoir quels outils de recommandation sont actuellement inclus dans BigQuery Export.
Avant de commencer
Avant de créer un transfert de données pour les recommandations, procédez comme suit :
- Autorisez le service de transfert de données BigQuery à gérer le transfert de données. Si vous utilisez l'interface utilisateur Web de BigQuery pour créer le transfert, vous devez autoriser les fenêtres pop-up de
console.cloud.google.comdans votre navigateur pour pouvoir afficher les autorisations. Pour en savoir plus, consultez la section Activer un service de transfert de données BigQuery. - Créez un ensemble de données BigQuery pour y stocker vos données.
- Le transfert de données utilise la même région que celle où l'ensemble de données est créé. L'emplacement est immuable une fois l'ensemble de données et le transfert créés.
- L'ensemble de données contiendra des insights et des recommandations provenant de toutes les régions du monde. Ainsi, au cours du processus, cette opération agrège toutes ces données dans une région globale. Veuillez consulter la page Google Cloud Customer Care en cas de problème de résidence des données.
- Si l'emplacement de l'ensemble de données vient d'être lancé, la disponibilité initiale des données d'exportation peut prendre quelques instants.
Tarifs
L'exportation des recommandations vers BigQuery est disponible pour tous les clients de l'outil de recommandation en fonction de leur niveau de tarification de l'outil de recommandation.
Autorisations requises
Lors de la configuration du transfert de données, vous avez besoin des autorisations suivantes au niveau du projet dans lequel vous créez un transfert de données :
bigquery.transfers.update: permet de créer le transfert.bigquery.datasets.update: permet de mettre à jour les actions sur l'ensemble de données cible.resourcemanager.projects.update: permet de sélectionner un projet dans lequel vous souhaitez stocker les données d'exportation.pubsub.topics.list: permet de sélectionner un sujet Pub/Sub afin de recevoir des notifications concernant votre exportation.
L'autorisation suivante est requise au niveau de l'organisation. Cette organisation correspond à celle pour laquelle l'exportation est configurée.
recommender.resources.export: permet d'exporter des recommandations vers BigQuery.
Pour exporter des prix négociés afin de réaliser des économies, vous aurez besoin des permissions suivantes :
billing.resourceCosts.get at project level: permet d'exporter les prix négociés pour les recommandations au niveau du projet.billing.accounts.getSpendingInformation at billing account level: permet d'exporter les prix négociés pour les recommandations au niveau du compte de facturation.
Sans ces autorisations, les recommandations de réduction des coûts seront exportées avec les prix standards plutôt qu'avec les prix négociés.
Octroyer des autorisations
Les rôles suivants doivent être attribués au projet dans lequel vous créez le transfert de données :
- Rôle d'administrateur BigQuery :
roles/bigquery.admin - Rôle de propriétaire du projet :
roles/owner - Rôle de propriétaire du projet :
roles/owner - Rôle de lecteur du projet :
roles/viewer - Rôle d'éditeur du projet :
roles/editor - Rôle d'administrateur de compte de facturation :
roles/billing.admin - Rôle de gestionnaire des coûts du compte de facturation :
roles/billing.costsManager - Rôle de lecteur de compte de facturation :
roles/billing.viewer
Pour pouvoir créer des actions de transfert et de mise à jour sur l'ensemble de données cible, vous devez attribuer le rôle suivant :
Plusieurs rôles contiennent des autorisations permettant de sélectionner un projet pour stocker vos données d'exportation et sélectionner un sujet Pub/Sub pour recevoir des notifications. Pour accorder ces deux autorisations, vous pouvez attribuer le rôle suivant :
Plusieurs rôles contiennent l'autorisation billing.resourceCosts.get permettant d'exporter les prix négociés pour obtenir des recommandations de réduction des coûts. Vous pouvez attribuer n'importe lequel de ces rôles :
Plusieurs rôles contiennent l'autorisation "billing.accounts.getSpendingInfo" pour exporter les tarifs négociés pour les recommandations de réduction des coûts au niveau du compte de facturation. Vous pouvez attribuer n'importe lequel de ces rôles :
Vous devez attribuer le rôle suivant au niveau de l'organisation :
- Le rôle Exportateur de recommandations (
roles/recommender.exporter) dans la console Google Cloud .
Vous pouvez également créer des rôles personnalisés contenant les autorisations requises.
Créer un transfert de données pour les recommandations
Connectez-vous à la console Google Cloud .
Sur l'écran Accueil, cliquez sur l'onglet Recommandations.
Cliquez sur Exporter pour afficher le formulaire d'exportation BigQuery.
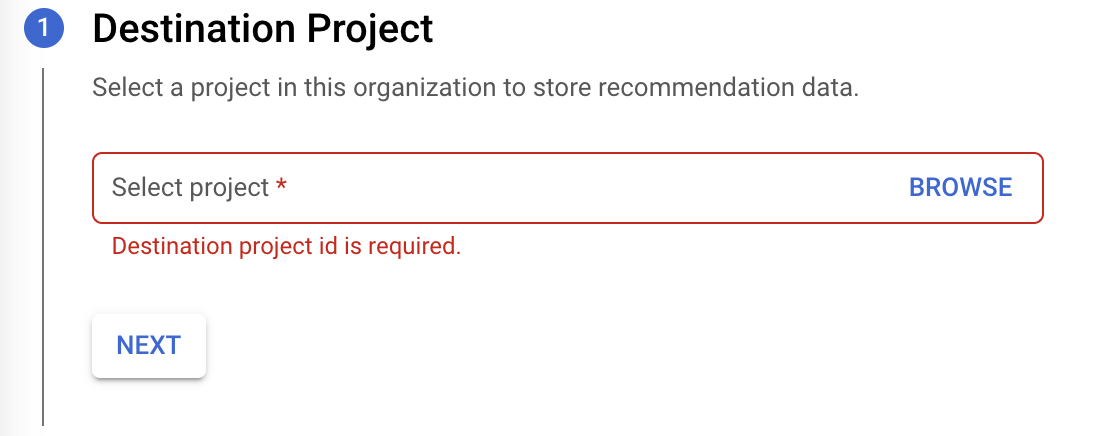
Sélectionnez un projet projet de destination pour stocker les données de recommandations, puis cliquez sur Suivant.
Cliquez sur Activer les API pour activer les API BigQuery pour l'exportation. Cette opération peut prendre quelques secondes. Lorsque vous avez terminé, cliquez sur Continuer.
Dans le formulaire Configurer le transfert, fournissez les informations suivantes :
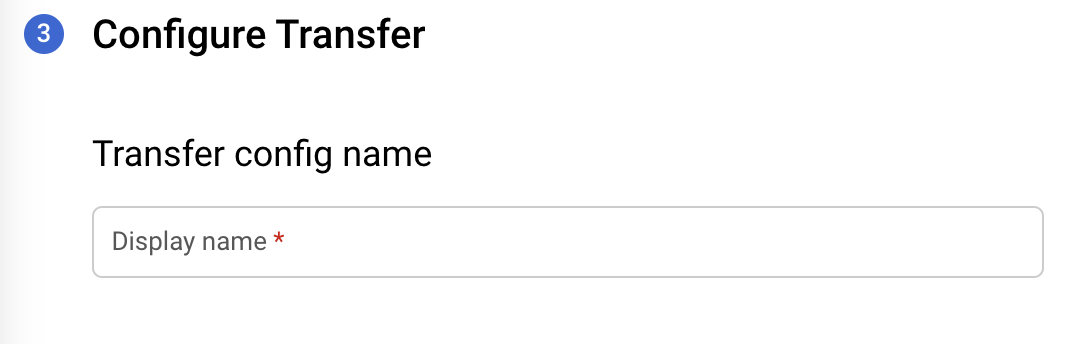
Dans la section Nom de la configuration de transfert, sous Nom à afficher, saisissez le nom du transfert. Ce nom peut correspondre à n'importe quelle valeur permettant d'identifier facilement le transfert si vous devez le modifier ultérieurement.
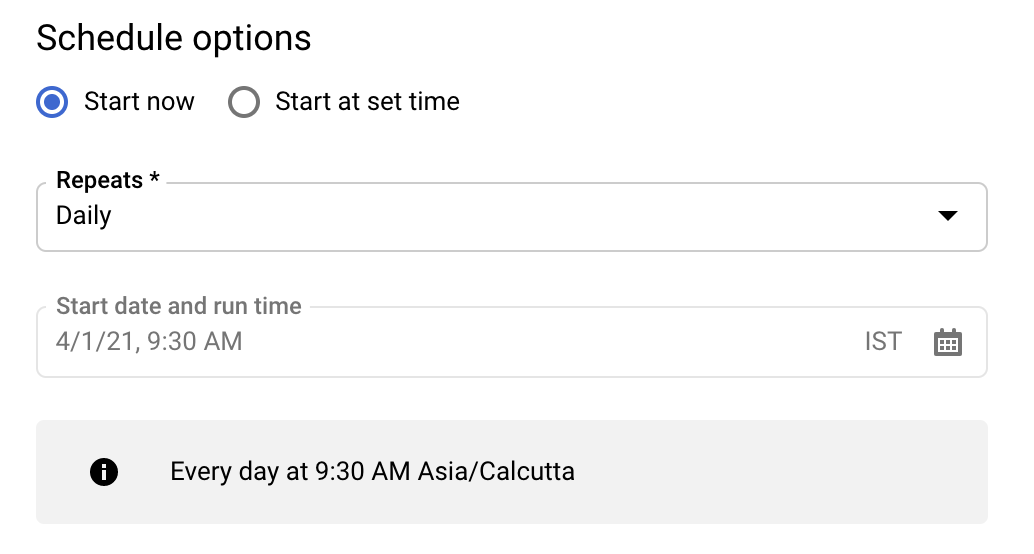
Dans la section Schedule options (Options de programmation), pour le champ Custom Schedule (Programmation personnalisée), laissez la valeur par défaut Start now (Commencer), ou cliquez sur Start at a set time (Démarrer à l'heure définie).
Pour le champ Repeats (Périodicité), choisissez l'une des options suivantes pour la fréquence d'exécution du transfert.
- Daily (Tous les jours) (par défaut)
- Toutes les semaines
- Tous les mois
- Personnalisé
- À la demande
Pour le champ Start date and run time (Date de début et heure d'exécution), saisissez la date et l'heure de début du transfert. Cette option est désactivée si vous choisissez Start now (Commencer).
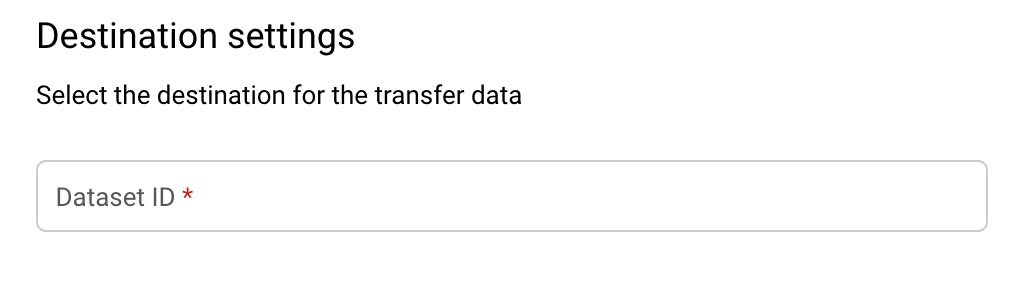
Dans la section Destination settings (Paramètres de destination), pour le champ Destination dataset (Ensemble de données de destination), choisissez l'ID d'ensemble de données que vous avez créé pour stocker vos données.
Dans la section Data source details (Détails de la source de données) :
La valeur par défaut de organization_id est l'organisation pour laquelle vous consultez actuellement des recommandations. Si vous souhaitez exporter des recommandations vers une autre organisation, vous pouvez modifier cette option en haut de la console dans le lecteur de l'organisation.

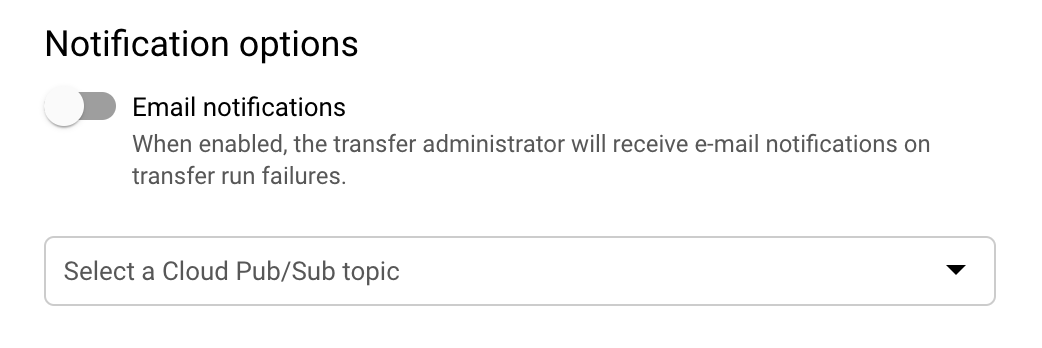
(Facultatif) Dans la section Notification options (Options de notification) :
- Cliquez sur le bouton pour activer les notifications par e-mail. Lorsque vous activez cette option, l'administrateur de transfert reçoit une notification par e-mail en cas d'échec de l'exécution du transfert.
- Pour le champ Select a Pub/Sub topic (Sélectionner un sujet Pub/Sub), choisissez le nom de votre sujet ou cliquez sur Create a topic (Créer un sujet). Cette option configure les notifications d'exécution Cloud Pub/Sub pour votre transfert.
Cliquez sur Créer pour créer le transfert.
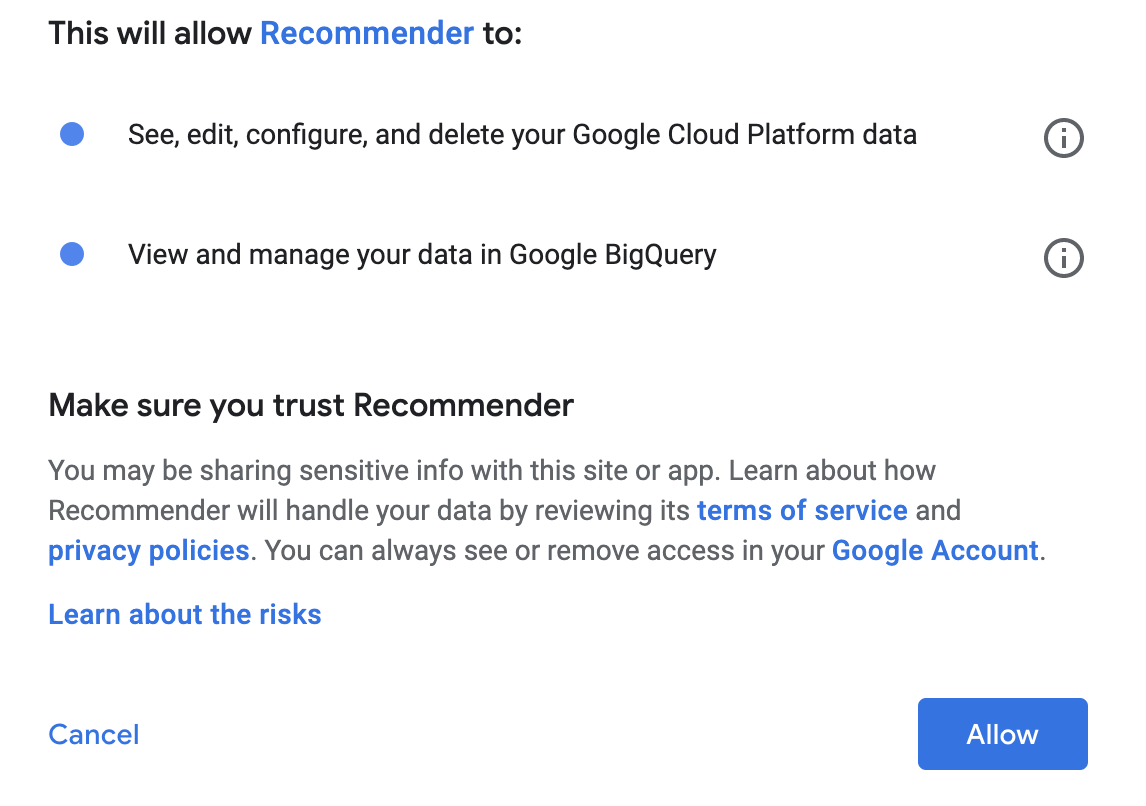
Cliquez sur Allow (Autoriser) dans le pop-up d'autorisation.
Une fois le transfert créé, vous êtes redirigé vers Active Assist. Vous pouvez cliquer sur le lien pour accéder aux informations de configuration du transfert. Vous pouvez également accéder aux transferts en procédant comme suit :
Accédez à la page BigQuery de la console Google Cloud .
Cliquez sur Transferts de données. Vous pouvez afficher tous les transferts de données disponibles.
Afficher l'historique d'exécution d'un transfert
Pour afficher l'historique d'exécution d'un transfert, procédez comme suit :
Accédez à la page BigQuery de la console Google Cloud .
Cliquez sur Transferts de données. Vous pouvez afficher tous les transferts de données disponibles.
Cliquez sur le transfert approprié dans la liste.
Dans la liste des transferts exécutés affichée dans l'onglet HISTORIQUE D'EXÉCUTION, sélectionnez le transfert dont vous souhaitez afficher les détails.
Le panneau Détails d'exécution s'affiche pour chaque transfert exécuté sélectionné. Voici quelques-uns des détails d'exécution affichés :
- Transfert différé dû à l'indisponibilité des données sources.
- Tâche indiquant le nombre de lignes exportées dans une table.
- Autorisations manquantes pour une source de données pour laquelle vous devez accorder et programmer plus tard un remplissage.
Quand vos données sont-elles exportées ?
Lorsque vous créez un transfert de données, la première exportation a lieu deux jours plus tard. Après la première exportation, les jobs d'exportation s'exécutent à la fréquence que vous avez demandée au moment de la configuration. Les conditions suivantes s'appliquent :
Le job d'exportation d'un jour spécifique (J) exporte les données de fin de la journée (J) vers votre ensemble de données BigQuery, qui se termine généralement à la fin du jour suivant (J+1). La tâche d'exportation s'exécute dans le fuseau horaire PST et un délai supplémentaire peut apparaître pour les autres fuseaux horaires.
Le job d'exportation quotidienne ne s'exécute que lorsque toutes les données pour l'exportation sont disponibles. Cela peut entraîner des variations et parfois des retards sur le jour et l'heure de mise à jour de l'ensemble de données. Par conséquent, il est préférable d'utiliser le dernier instantané de données disponible plutôt que d'avoir une dépendance marquée sur les données temporelles, pour des tables datées spécifiques.
Le job d'exportation transfère les dernières données disponibles par région. Cela signifie qu'il peut y avoir une différence dans la dernière date pour laquelle les recommandations sont disponibles dans différentes régions.
Messages d'état courants lors d'une exportation
Découvrez les messages d'état courants que vous pourrez voir s'afficher lors de l'exportation de recommandations vers BigQuery.
L'utilisateur ne dispose pas de l'autorisation requise
Ce message s'affiche lorsque l'utilisateur ne dispose pas de l'autorisation recommender.resources.export requise. Le message s'affiche comme suit :
User does not have required permission "recommender.resources.export". Please, obtain the required permissions for the datasource and try again by triggering a backfill for this date
Pour résoudre ce problème, accordez le rôle IAM roles/recommender.exporter à l'utilisateur/au compte de service (user/service account) qui configure l'exportation au niveau de l'organisation, pour l'organisation pour laquelle l'exportation a été configurée. L'octroi de ce rôle peut s'effectuer via les commandes gcloud ci-dessous :
Dans le cas d'un utilisateur :
gcloud organizations add-iam-policy-binding *<organization_id>* --member='user:*<user_name>*' --role='roles/recommender.exporter'Dans le cas d'un compte de service :
gcloud organizations add-iam-policy-binding *<organization_id>* --member='serviceAccount:*<service_acct_name>*' --role='roles/recommender.exporter'
Transfert différé en raison d'une indisponibilité des données sources
Ce message s'affiche lorsque le transfert est reprogrammé, car les données sources ne sont pas encore disponibles. Il ne s'agit pas d'une erreur. Cela signifie que les pipelines d'exportation ne sont pas encore terminés pour la journée. Le transfert sera réexécuté à la nouvelle heure planifiée et réussira une fois les pipelines d'exportation terminés. Le message s'affiche comme suit :
Transfer deferred due to source data not being available
Données sources introuvables
Ce message s'affiche lorsque les pipelines F1toPlacer sont terminés, mais qu'aucune recommandation ni aucun insight n'ont été trouvés pour l'organisation pour laquelle l'exportation a été configurée. Le message s'affiche comme suit :
Source data not found for 'recommendations_export$<date>'insights_export$<date>
Son apparition est due aux raisons suivantes :
- L'utilisateur a configuré l'exportation il y a moins de deux jours. Le guide client indique aux clients qu'un délai d'une journée s'applique avant que leur exportation soit disponible.
- Aucune recommandation ni aucun insight ne sont disponibles pour l'organisation, pour le jour en question. Il peut s'agir du cas réel, ou bien des pipelines ont peut-être été exécutés avant que toutes les recommandations ou tous les insights ne soient disponibles pour la journée.
Afficher les tables d'un transfert
Lorsque vous exportez des recommandations vers BigQuery, l'ensemble de données contient deux tables partitionnées par date :
- recommendations_export
- insight_export
Pour en savoir plus sur les tables et le schéma, consultez les pages Créer et utiliser des tables et Spécifier un schéma.
Pour afficher les tables d'un transfert de données, procédez comme suit :
Accédez à la page BigQuery de la console Google Cloud . Accéder à la page BigQuery
Cliquez sur Transferts de données. Vous pouvez afficher tous les transferts de données disponibles.
Cliquez sur le transfert approprié dans la liste.
Cliquez sur l'onglet CONFIGURATION, puis sur l'ensemble de données.
Dans le panneau Explorateur, développez votre projet et sélectionnez un ensemble de données. La description et les détails s'affichent dans le panneau de détails. Les tables d'un ensemble de données sont répertoriées avec le nom de l'ensemble de données dans le panneau Explorateur.
Programmez un remplissage.
Les recommandations pour une date antérieure (ultérieure à la date à laquelle l'organisation a été activée pour l'exportation) peuvent être exportées en planifiant un remplissage. Pour planifier un remplissage, procédez comme suit :
Accédez à la page BigQuery de la console Google Cloud .
Cliquez sur Transferts de données.
Sur la page Transferts, cliquez sur le transfert approprié dans la liste.
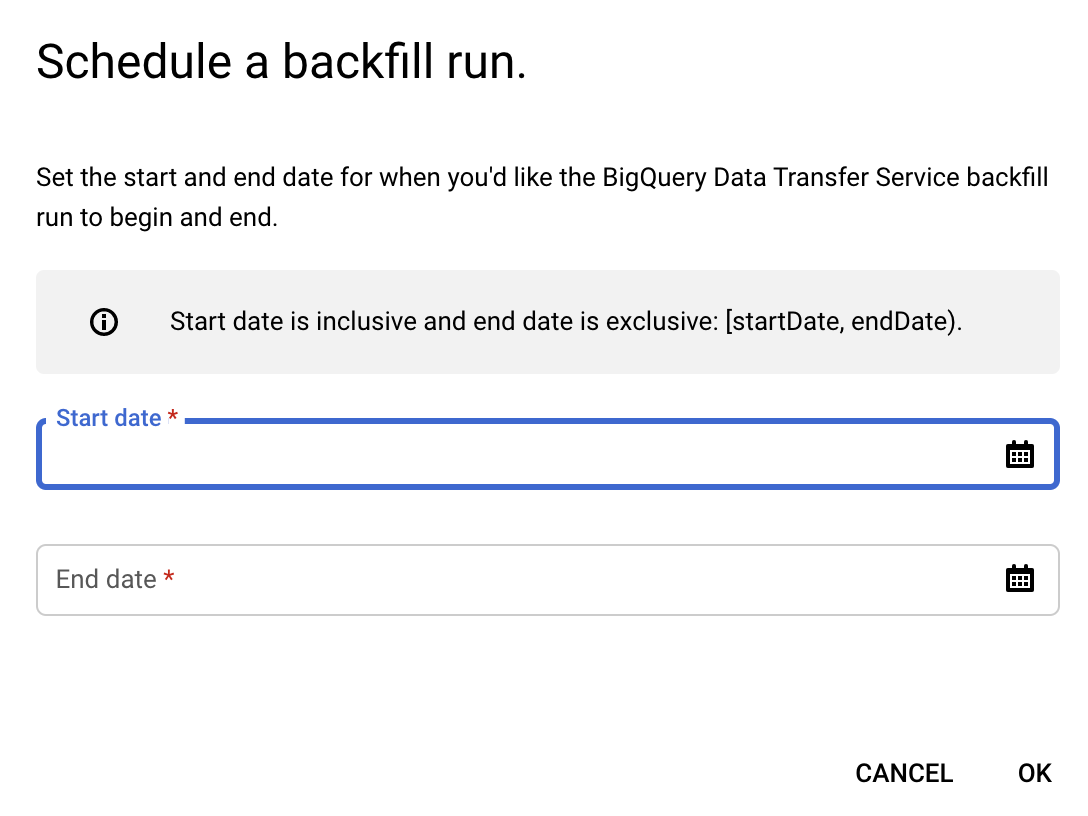
Cliquez sur Schedule Backfill (Programmer un remplissage).
Dans la boîte de dialogue Programmer le remplissage, sélectionnez la date de début et la date de fin.
Pour en savoir plus sur l'utilisation des transferts, consultez la page Utiliser les transferts.
Schéma d'exportation
Table d'exportation des recommandations :
schema:
fields:
- name: cloud_entity_type
type: STRING
description: |
Represents what cloud entity type the recommendation was generated for - eg: project number, billing account
- name: cloud_entity_id
type: STRING
description: |
Value of the project number or billing account id
- name: name
type: STRING
description: |
Name of recommendation. A project recommendation is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/recommenders/[RECOMMENDER_ID]/recommendations/[RECOMMENDATION_ID]
- name: location
type: STRING
description: |
Location for which this recommendation is generated
- name: recommender
type: STRING
description: |
Recommender ID of the recommender that has produced this recommendation
- name: recommender_subtype
type: STRING
description: |
Contains an identifier for a subtype of recommendations produced for the
same recommender. Subtype is a function of content and impact, meaning a
new subtype will be added when either content or primary impact category
changes.
Examples:
For recommender = "google.iam.policy.Recommender",
recommender_subtype can be one of "REMOVE_ROLE"/"REPLACE_ROLE"
- name: target_resources
type: STRING
mode: REPEATED
description: |
Contains the fully qualified resource names for resources changed by the
operations in this recommendation. This field is always populated. ex:
[//cloudresourcemanager.googleapis.com/projects/foo].
- name: description
type: STRING
description: |
Required. Free-form human readable summary in English.
The maximum length is 500 characters.
- name: last_refresh_time
type: TIMESTAMP
description: |
Output only. Last time this recommendation was refreshed by the system that created it in the first place.
- name: primary_impact
type: RECORD
description: |
Required. The primary impact that this recommendation can have while trying to optimize
for one category.
schema:
fields:
- name: category
type: STRING
description: |
Category that is being targeted.
Values can be the following:
CATEGORY_UNSPECIFIED:
Default unspecified category. Do not use directly.
COST:
Indicates a potential increase or decrease in cost.
SECURITY:
Indicates a potential increase or decrease in security.
PERFORMANCE:
Indicates a potential increase or decrease in performance.
RELIABILITY:
Indicates a potential increase or decrease in reliability.
- name: cost_projection
type: RECORD
description: Optional. Use with CategoryType.COST
schema:
fields:
- name: cost
type: RECORD
description: |
An approximate projection on amount saved or amount incurred.
Negative cost units indicate cost savings and positive cost units indicate
increase. See google.type.Money documentation for positive/negative units.
schema:
fields:
- name: currency_code
type: STRING
description: The 3-letter currency code defined in ISO 4217.
- name: units
type: INTEGER
description: |
The whole units of the amount. For example if `currencyCode` is `"USD"`,
then 1 unit is one US dollar.
- name: nanos
type: INTEGER
description: |
Number of nano (10^-9) units of the amount.
The value must be between -999,999,999 and +999,999,999 inclusive.
If `units` is positive, `nanos` must be positive or zero.
If `units` is zero, `nanos` can be positive, zero, or negative.
If `units` is negative, `nanos` must be negative or zero.
For example $-1.75 is represented as `units`=-1 and `nanos`=-750,000,000.
- name: cost_in_local_currency
type: RECORD
description: |
An approximate projection on amount saved or amount incurred in the local currency.
Negative cost units indicate cost savings and positive cost units indicate
increase. See google.type.Money documentation for positive/negative units.
schema:
fields:
- name: currency_code
type: STRING
description: The 3-letter currency code defined in ISO 4217.
- name: units
type: INTEGER
description: |
The whole units of the amount. For example if `currencyCode` is `"USD"`,
then 1 unit is one US dollar.
- name: nanos
type: INTEGER
description: |
Number of nano (10^-9) units of the amount.
The value must be between -999,999,999 and +999,999,999 inclusive.
If `units` is positive, `nanos` must be positive or zero.
If `units` is zero, `nanos` can be positive, zero, or negative.
If `units` is negative, `nanos` must be negative or zero.
For example $-1.75 is represented as `units`=-1 and `nanos`=-750,000,000.
- name: duration
type: RECORD
description: Duration for which this cost applies.
schema:
fields:
- name: seconds
type: INTEGER
description: |
Signed seconds of the span of time. Must be from -315,576,000,000
to +315,576,000,000 inclusive. Note: these bounds are computed from:
60 sec/min * 60 min/hr * 24 hr/day * 365.25 days/year * 10000 years
- name: nanos
type: INTEGER
description: |
Signed fractions of a second at nanosecond resolution of the span
of time. Durations less than one second are represented with a 0
`seconds` field and a positive or negative `nanos` field. For durations
of one second or more, a non-zero value for the `nanos` field must be
of the same sign as the `seconds` field. Must be from -999,999,999
to +999,999,999 inclusive.
- name: pricing_type_name
type: STRING
description: |
A pricing type can either be based on the price listed on GCP (LIST) or a custom
price based on past usage (CUSTOM).
- name: reliability_projection
type: RECORD
description: Optional. Use with CategoryType.RELIABILITY
schema:
fields:
- name: risk_types
type: STRING
mode: REPEATED
description: |
The risk associated with the reliability issue.
RISK_TYPE_UNSPECIFIED:
Default unspecified risk. Do not use directly.
SERVICE_DISRUPTION:
Potential service downtime.
DATA_LOSS:
Potential data loss.
ACCESS_DENY:
Potential access denial. The service is still up but some or all clients
can not access it.
- name: details_json
type: STRING
description: |
Additional reliability impact details that is provided by the recommender in JSON
format.
- name: state
type: STRING
description: |
Output only. The state of the recommendation:
STATE_UNSPECIFIED:
Default state. Do not use directly.
ACTIVE:
Recommendation is active and can be applied. Recommendations content can
be updated by Google.
ACTIVE recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
CLAIMED:
Recommendation is in claimed state. Recommendations content is
immutable and cannot be updated by Google.
CLAIMED recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
SUCCEEDED:
Recommendation is in succeeded state. Recommendations content is
immutable and cannot be updated by Google.
SUCCEEDED recommendations can be marked as SUCCEEDED, or FAILED.
FAILED:
Recommendation is in failed state. Recommendations content is immutable
and cannot be updated by Google.
FAILED recommendations can be marked as SUCCEEDED, or FAILED.
DISMISSED:
Recommendation is in dismissed state.
DISMISSED recommendations can be marked as ACTIVE.
- name: ancestors
type: RECORD
description: |
Ancestry for the recommendation entity
schema:
fields:
- name: organization_id
type: STRING
description: |
Organization to which the recommendation project
- name: folder_ids
type: STRING
mode: REPEATED
description: |
Up to 5 levels of parent folders for the recommendation project
- name: associated_insights
type: STRING
mode: REPEATED
description: |
Insights associated with this recommendation. A project insight is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/insightTypes/[INSIGHT_TYPE_ID]/insights/[insight_id]
- name: recommendation_details
type: STRING
description: |
Additional details about the recommendation in JSON format.
schema:
- name: overview
type: RECORD
description: Overview of the recommendation in JSON format
- name: operation_groups
type: OperationGroup
mode: REPEATED
description: Operations to one or more Google Cloud resources grouped in such a way
that, all operations within one group are expected to be performed
atomically and in an order. More here: https://cloud.google.com/recommender/docs/key-concepts#operation_groups
- name: operations
type: Operation
description: An Operation is the individual action that must be performed as one of the atomic steps in a suggested recommendation. More here: https://cloud.google.com/recommender/docs/key-concepts?#operation
- name: state_metadata
type: map with key: STRING, value: STRING
description: A map of STRING key, STRING value of metadata for the state, provided by user or automations systems.
- name: additional_impact
type: Impact
mode: REPEATED
description: Optional set of additional impact that this recommendation may have when
trying to optimize for the primary category. These may be positive
or negative. More here: https://cloud.google.com/recommender/docs/key-concepts?#recommender_impact
- name: priority
type: STRING
description: |
Priority of the recommendation:
PRIORITY_UNSPECIFIED:
Default unspecified priority. Do not use directly.
P4:
Lowest priority.
P3:
Second lowest priority.
P2:
Second highest priority.
P1:
Highest priority.
Table d'exportation des insights :
schema:
- fields:
- name: cloud_entity_type
type: STRING
description: |
Represents what cloud entity type the recommendation was generated for - eg: project number, billing account
- name: cloud_entity_id
type: STRING
description: |
Value of the project number or billing account id
- name: name
type: STRING
description: |
Name of recommendation. A project recommendation is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/recommenders/[RECOMMENDER_ID]/recommendations/[RECOMMENDATION_ID]
- name: location
type: STRING
description: |
Location for which this recommendation is generated
- name: insight_type
type: STRING
description: |
Recommender ID of the recommender that has produced this recommendation
- name: insight_subtype
type: STRING
description: |
Contains an identifier for a subtype of recommendations produced for the
same recommender. Subtype is a function of content and impact, meaning a
new subtype will be added when either content or primary impact category
changes.
Examples:
For recommender = "google.iam.policy.Recommender",
recommender_subtype can be one of "REMOVE_ROLE"/"REPLACE_ROLE"
- name: target_resources
type: STRING
mode: REPEATED
description: |
Contains the fully qualified resource names for resources changed by the
operations in this recommendation. This field is always populated. ex:
[//cloudresourcemanager.googleapis.com/projects/foo].
- name: description
type: STRING
description: |
Required. Free-form human readable summary in English.
The maximum length is 500 characters.
- name: last_refresh_time
type: TIMESTAMP
description: |
Output only. Last time this recommendation was refreshed by the system that created it in the first place.
- name: category
type: STRING
description: |
Category being targeted by the insight. Can be one of:
Unspecified category.
CATEGORY_UNSPECIFIED = Unspecified category.
COST = The insight is related to cost.
SECURITY = The insight is related to security.
PERFORMANCE = The insight is related to performance.
MANAGEABILITY = The insight is related to manageability.
RELIABILITY = The insight is related to reliability.;
- name: state
type: STRING
description: |
Output only. The state of the recommendation:
STATE_UNSPECIFIED:
Default state. Do not use directly.
ACTIVE:
Recommendation is active and can be applied. Recommendations content can
be updated by Google.
ACTIVE recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
CLAIMED:
Recommendation is in claimed state. Recommendations content is
immutable and cannot be updated by Google.
CLAIMED recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
SUCCEEDED:
Recommendation is in succeeded state. Recommendations content is
immutable and cannot be updated by Google.
SUCCEEDED recommendations can be marked as SUCCEEDED, or FAILED.
FAILED:
Recommendation is in failed state. Recommendations content is immutable
and cannot be updated by Google.
FAILED recommendations can be marked as SUCCEEDED, or FAILED.
DISMISSED:
Recommendation is in dismissed state.
DISMISSED recommendations can be marked as ACTIVE.
- name: ancestors
type: RECORD
description: |
Ancestry for the recommendation entity
schema:
fields:
- name: organization_id
type: STRING
description: |
Organization to which the recommendation project
- name: folder_ids
type: STRING
mode: REPEATED
description: |
Up to 5 levels of parent folders for the recommendation project
- name: associated_recommendations
type: STRING
mode: REPEATED
description: |
Insights associated with this recommendation. A project insight is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/insightTypes/[INSIGHT_TYPE_ID]/insights/[insight_id]
- name: insight_details
type: STRING
description: |
Additional details about the insight in JSON format
schema:
fields:
- name: content
type: STRING
description: |
A struct of custom fields to explain the insight.
Example: "grantedPermissionsCount": "1000"
- name: observation_period
type: TIMESTAMP
description: |
Observation period that led to the insight. The source data used to
generate the insight ends at last_refresh_time and begins at
(last_refresh_time - observation_period).
- name: state_metadata
type: STRING
description: |
A map of metadata for the state, provided by user or automations systems.
- name: severity
type: STRING
description: |
Severity of the insight:
SEVERITY_UNSPECIFIED:
Default unspecified severity. Do not use directly.
LOW:
Lowest severity.
MEDIUM:
Second lowest severity.
HIGH:
Second highest severity.
CRITICAL:
Highest severity.
Exemples de requêtes
Vous pouvez utiliser les exemples de requêtes suivants pour analyser vos données exportées.
Afficher les économies réalisées pour les recommandations dont la durée est affichée en jours
SELECT name, recommender, target_resources,
case primary_impact.cost_projection.cost.units is null
when true then round(primary_impact.cost_projection.cost.nanos * power(10,-9),2)
else
round( primary_impact.cost_projection.cost.units +
(primary_impact.cost_projection.cost.nanos * power(10,-9)), 2)
end
as dollar_amt,
primary_impact.cost_projection.duration.seconds/(60*60*24) as duration_in_days
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and primary_impact.category = "COST"
Afficher la liste des rôles IAM inutilisés
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and recommender = "google.iam.policy.Recommender"
and recommender_subtype = "REMOVE_ROLE"
Afficher une liste des rôles attribués devant être remplacés par des rôles moins importants
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and recommender = "google.iam.policy.Recommender"
and recommender_subtype = "REPLACE_ROLE"
Afficher les insights d'une recommandation
SELECT recommendations.name as recommendation_name,
insights.name as insight_name,
recommendations.cloud_entity_id,
recommendations.cloud_entity_type,
recommendations.recommender,
recommendations.recommender_subtype,
recommendations.description,
recommendations.target_resources,
recommendations.recommendation_details,
recommendations.state,
recommendations.last_refresh_time as recommendation_last_refresh_time,
insights.insight_type,
insights.insight_subtype,
insights.category,
insights.description,
insights.insight_details,
insights.state,
insights.last_refresh_time as insight_last_refresh_time
FROM `<project>.<dataset>.recommendations_export` as recommendations,
`<project>.<dataset>.insights_export` as insights
WHERE DATE(recommendations._PARTITIONTIME) = "<date>"
and DATE(insights._PARTITIONTIME) = "<date>"
and insights.name in unnest(recommendations.associated_insights)
Afficher les recommandations pour les projets appartenant à un dossier spécifique
Cette requête renvoie les dossiers parents en remontant à jusqu'à cinq niveaux du projet.
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and "<folder_id>" in unnest(ancestors.folder_ids)
Afficher les recommandations pour la dernière date disponible exportée jusqu'à présent
DECLARE max_date TIMESTAMP;
SET max_date = (
SELECT MAX(_PARTITIONTIME) FROM
`<project>.<dataset>.recommendations_export`
);
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE _PARTITIONTIME = max_date
Utiliser Sheets pour explorer les données BigQuery
Au lieu d'exécuter des requêtes sur BigQuery, vous pouvez accéder, analyser, visualiser et partager des milliards de lignes de données BigQuery depuis votre feuille de calcul avec les feuilles connectées, le nouveau connecteur de données BigQuery. Pour en savoir plus, consultez la section Premiers pas avec les données BigQuery dans Google Sheets.
Configurer l'exportation en utilisant la ligne de commande BigQuery et l'API REST
Obtenir les autorisations requises
Vous pouvez obtenir les autorisations IAM (Identity and Access Management) requises en utilisant la consoleGoogle Cloud ou la ligne de commande.
- Ligne de commande pour les comptes de service
- Ligne de commande pour les utilisateurs :
Par exemple, pour utiliser la ligne de commande afin d'obtenir l'autorisation recommander.resources.export au niveau du compte de service, procédez comme suit :
gcloud organizations add-iam-policy-binding *<organization_id>* --member=serviceAccount:*<service_acct_name>*' --role='roles/recommender.exporter'Enregistrez le projet dans la source de données BigQuery
Datasource to use: 6063d10f-0000-2c12-a706-f403045e6250Créez l'exportation :
Avec la ligne de commande BigQuery :
bq mk \ --transfer_config \ --project_id=project_id \ --target_dataset=dataset_id \ --display_name=name \ --params='parameters' \ --data_source=data_source \ --service_account_name=service_account_name
Où :
- project_id est l'ID de votre projet.
- dataset est l'ID de l'ensemble de données cible pour la configuration de transfert.
- name est le nom à afficher pour la configuration de transfert. Ce nom peut correspondre à toute valeur permettant d'identifier facilement le transfert si vous devez le modifier ultérieurement.
- parameters contient les paramètres de la configuration de transfert créée au format JSON. Pour les recommandations et les insights BigQuery Export, vous devez fournir l'ID de l'organisation pour laquelle les recommandations et les insights doivent être exportés. Format des paramètres : '{"organization_id":"<org id>"}'
- data_source Source de données à utiliser : "6063d10f-0000-2c12-a706-f403045e6250"
- service_account_name est le nom du compte de service utilisé pour authentifier votre exportation. Le compte de service doit appartenir au même
project_idque celui utilisé pour créer le transfert et doit disposer de toutes les autorisations requises répertoriées ci-dessus.
Gérez une exportation existante via l'interface utilisateur ou la ligne de commande BigQuery :
Remarque : L'exportation est exécutée au nom de l'utilisateur qui a configuré le compte, quelle que soit la personne qui met à jour la configuration d'exportation par la suite. Par exemple, si l'exportation est configurée en utilisant un compte de service, et qu'un utilisateur met ensuite à jour la configuration d'exportation en utilisant l'interface utilisateur du service de transfert de données BigQuery, l'exportation continue de s'exécuter au nom du compte de service. Dans ce cas, la vérification de l'autorisation "recommender.resources.export" est effectuée pour le compte de service à chaque exécution de l'exportation.