Ce guide vous permet de comprendre les fonctionnalités de fiabilité de Pub/Sub et d'en obtenir une vue d'ensemble.
Pourquoi Pub/Sub ?
En tant que modèle de messagerie, la publication/souscription est conçue pour dissocier les producteurs de messages des consommateurs de ces messages. Au lieu d'envoyer des requêtes directes aux consommateurs avec les données, les producteurs publient ces données dans un service Pub/Sub tel que Pub/Sub. Le service envoie ces messages de manière asynchrone aux consommateurs intéressés qui se sont abonnés.
Le service absorbe ainsi toutes les subtilités liées à la recherche de consommateurs intéressés par les données. Le service gère également la fréquence à laquelle les consommateurs reçoivent les données, en fonction de leur capacité. Ce découplage permet aux producteurs de données d'écrire des messages à grande échelle avec une faible latence, indépendamment du comportement des consommateurs.
Pub/Sub offre une distribution de messages fiable et hautement évolutive. Bien que le service gère la plupart de ces aspects automatiquement, vous pouvez contrôler différents aspects de vos éditeurs et abonnés qui peuvent avoir une incidence sur la disponibilité et les performances. Le reste de ce guide fournit des informations sur ces aspects.
Isolation
Par défaut, Pub/Sub est un service mondial : les thèmes et les abonnements ne sont pas intrinsèquement liés à des régions spécifiques, et les messages circulent au sein du service Pub/Sub entre les régions si nécessaire. Lorsque vous utilisez le point de terminaison global, pubsub.googleapis.com, les éditeurs et les abonnés se connectent à la région la plus proche du réseau où Pub/Sub s'exécute. Lorsque vous utilisez des points de terminaison régionaux, tels que us-central1-pubsub.googleapis.com, ou des points de terminaison géographiques, tels que pubsub.us-central1.rep.googleapis.com, les éditeurs et les abonnés se connectent à Pub/Sub dans la région spécifiée. Lorsque vous exécutez des éditeurs ou des abonnés en dehors de Google Cloud, il est préférable d'utiliser des points de terminaison régionaux ou géographiques pour vous assurer que les messages circulent de manière cohérente entre les régions attendues.
Isolation régionale
Pour minimiser l'infrastructure dont dépendent les opérations de publication et d'abonnement en dehors d'une même région, et pour vous assurer que toutes les données restent isolées dans cette région, procédez comme suit :
Créez un sujet par région.
Bien que l'espace de noms de Pub/Sub soit global et que vous ne puissiez pas associer de sujets ni d'abonnements à une région spécifique, les métadonnées de toutes les ressources sont répliquées dans des data stores locaux de la région. Par conséquent, une fois que vous avez créé une ressource, sa configuration est disponible même en cas de problème dans une autre région. Notez que les modifications apportées aux configurations des thèmes ou des abonnements ne sont pas immédiatement propagées en cas d'indisponibilité.
Évitez d'utiliser des points de terminaison globaux.
Utilisez plutôt des points de terminaison régionaux lorsqu'ils sont disponibles et des points de terminaison géographiques lorsqu'ils ne le sont pas. Les points de terminaison régionaux offrent une meilleure isolation régionale, mais ne sont pas encore disponibles dans toutes les régions.
Utilisez une règle de stockage des messages et définissez
enforceInTransitsurTrue.Lorsque l'option Appliquer en transit est activée, les données ne quittent jamais la région. Tous les clients qui se connectent au sujet dans une région spécifique définissent la règle de stockage des messages sur cette région.
Avec des thèmes configurés de cette manière, vous pouvez être sûr que toutes les opérations de publication et d'abonnement écrivent et lisent des données exclusivement dans la région. En cas de défaillance de l'éditeur, de l'abonné ou de Pub/Sub dans une seule région, la distribution des messages s'arrête dans cette région. La diffusion de messages sur les thèmes et les abonnements pour les autres régions n'est pas affectée.
Si vous avez également besoin que les opérations administratives et l'espace de noms de vos sujets et abonnements soient isolés au niveau régional, envisagez d'utiliser Managed Service pour Apache Kafka.
Basculement
Si vous n'avez pas besoin d'isolation régionale, vous pouvez profiter de la capacité de Pub/Sub à distribuer efficacement des messages dans plusieurs régions afin d'obtenir des capacités de basculement multirégionales. Le reste de cette section explique comment créer des sujets et des abonnements, et comment placer des éditeurs et des abonnés afin de prendre en charge différents types de basculement et de redondance des données.
Sémantique de basculement par défaut
Prenons l'exemple d'un sujet et d'un abonnement uniques. Les éditeurs sont situés dans des régions des États-Unis et d'Australie, et les abonnés dans les régions Google Cloud d'Europe et d'Australie. Si tous les abonnés ont une capacité suffisante pour recevoir des messages, le flux de messages se présente comme suit :
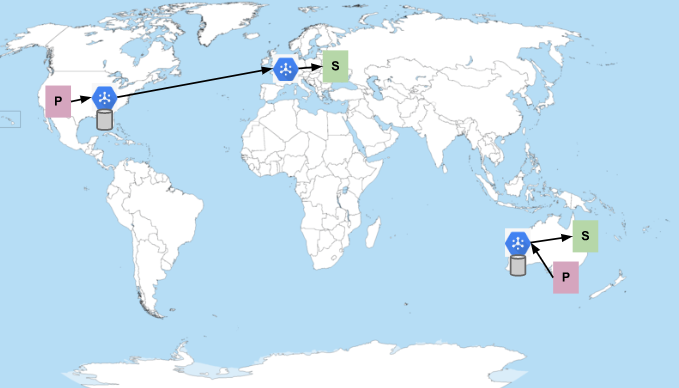
Les P représentent les éditeurs, et les S représentent les abonnés. L'hexagone bleu représente le service Pub/Sub. Les cylindres représentent les emplacements où les messages sont stockés (ils sont toujours conservés dans plusieurs zones de la région où ils sont publiés). Pub/Sub préfère envoyer les messages dans la même région où ils ont été publiés lorsque des abonnés sont disponibles. Sinon, il envoie les messages à la région la plus proche du réseau disposant d'abonnés ayant de la capacité. Par conséquent, comme le montre l'image précédente, les messages publiés aux États-Unis sont distribués aux abonnés en Europe, et les messages publiés en Australie restent en Australie.
Les sections suivantes décrivent ce qui se passe dans différents scénarios d'échec.
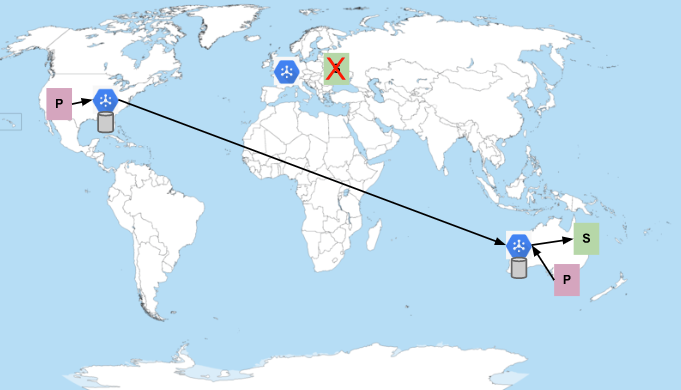
Abonnés en Europe indisponibles
Imaginons que des abonnés en Europe aient été refusés ou que leur application plante fréquemment et qu'ils ne parviennent pas à maintenir une connexion à Pub/Sub. Si cela s'était produit, le service aurait commencé à envoyer des messages aux abonnés en Australie :
Abonnés en Europe et en Australie indisponibles
Si tous les abonnés sont indisponibles, Pub/Sub stocke les messages jusqu'à la durée de conservation des messages configurée.
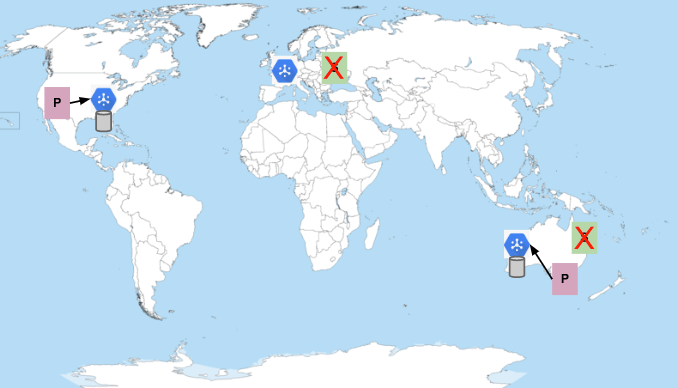
Une fois que les abonnés se reconnectent, les messages sont distribués, sauf si l'indisponibilité dure plus longtemps que la durée de conservation des messages configurée. Par défaut, la durée de conservation des messages d'abonnement est de sept jours. Vous pouvez également configurer la conservation des messages sur un sujet pendant 31 jours maximum. Ne choisissez pas une durée de conservation des messages inférieure à la durée maximale d'indisponibilité que vous prévoyez ou êtes prêt à tolérer.
Pub/Sub n'est pas disponible en Europe
Bien que cela soit rare, vous pouvez également être amené à gérer les cas où Pub/Sub lui-même n'est pas disponible. L'indisponibilité de Pub/Sub se manifeste par des périodes prolongées d'erreurs inattendues sur les requêtes de publication ou d'abonnement, ou par l'incapacité à distribuer les messages publiés aux abonnés. Par exemple, si Pub/Sub était indisponible dans la région Europe, le scénario serait très semblable à celui où les abonnés sont indisponibles :
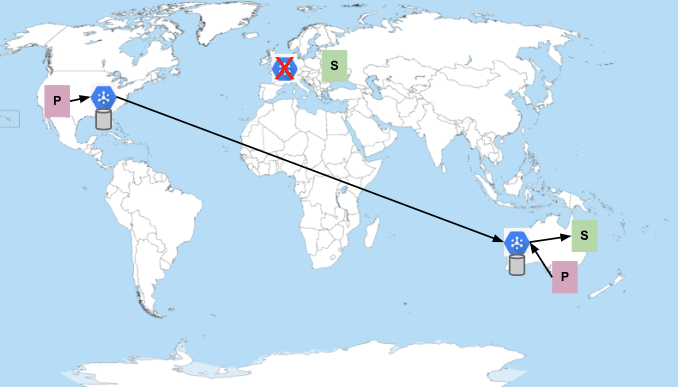
Notez que, dans ce cas, les abonnés en Europe ne basculent pas vers une autre région, même s'ils utilisent le point de terminaison mondial. Pub/Sub ne bascule pas automatiquement. Imaginez que ce soient les abonnés eux-mêmes qui provoquent un problème inattendu dans Pub/Sub, entraînant une indisponibilité. Un tel problème est considéré comme une panne majeure. Toutefois, l'étendue de l'impact de la panne peut être limitée à la région à laquelle les abonnés sont connectés. Si le service leur permettait de basculer vers une autre région, les abonnés pourraient également provoquer une indisponibilité dans cette région, ce qui entraînerait une défaillance en cascade dans l'ensemble du service.
Éditeurs indisponibles en Australie
Si les éditeurs d'une région deviennent indisponibles, les messages déjà publiés sont toujours distribués aux abonnés les plus proches :
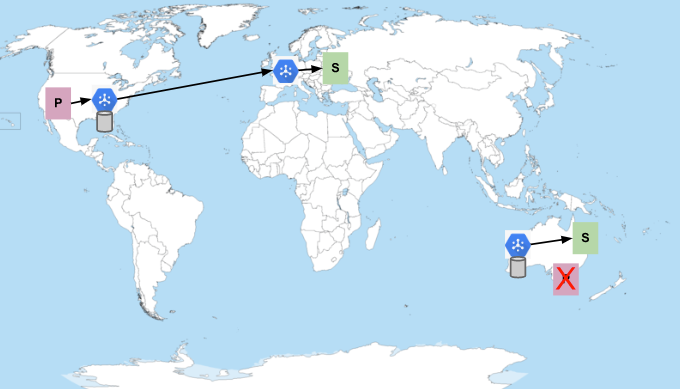
À terme, tous les messages sont consommés et confirmés par les abonnés. Lors de l'envoi de messages, Pub/Sub tente de minimiser la distance réseau. Par conséquent, les abonnés de la région australienne peuvent cesser de recevoir des messages si les abonnés européens ont suffisamment de capacité pour gérer tous les messages publiés aux États-Unis.
Pub/Sub n'est pas disponible aux États-Unis
Pub/Sub écrit de manière synchrone les messages dans plusieurs zones d'une même région. Par conséquent, une panne zonale ne suffit pas à empêcher la diffusion des messages. C'est l'indisponibilité de la région entière qui est nécessaire. Si Pub/Sub devient indisponible dans une région où des éditeurs envoient des messages, il est possible que les messages de cette région ne soient pas distribués tant que le service n'est pas entièrement restauré :
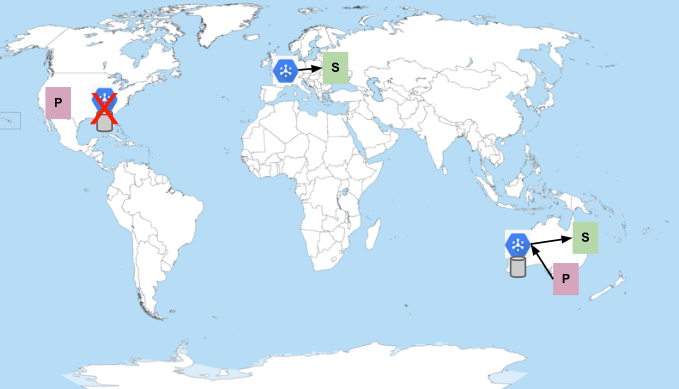
Le message est finalement distribué (à condition que la période de conservation des messages ne soit pas écoulée), avec un retard correspondant à la durée de l'indisponibilité. Notez que, comme pour les abonnés, les éditeurs aux États-Unis ne basculent pas vers une autre région en cas d'échec du service. Ce comportement permet d'éviter les défaillances en cascade dans les régions en raison d'un éditeur ou d'un abonné défectueux.
Basculement et redondance contrôlés par le client
La sémantique de basculement par défaut de Pub/Sub ne garantit pas toujours que les messages peuvent toujours transiter des éditeurs vers les abonnés en cas de panne n'importe où entre les deux. Des pannes peuvent se produire à différents endroits, y compris dans vos clients, dans le service sur lequel vos éditeurs ou abonnés s'exécutent, dans le réseau ou même, rarement, dans Pub/Sub lui-même. Si vous avez besoin que vos services soient résilients à de telles interruptions, vous devez implémenter vos propres redondances. En général, ces redondances incluent l'utilisation de plusieurs instances de clients éditeurs et abonnés, où chacun utilise un point de terminaison de localisation différent.
Vous pouvez souhaiter une résilience à deux types d'impact : zonal ou régional. Voici les options de configuration pour chacun d'eux.
Résilience zonale
Pub/Sub dispose d'une réplication multizone intégrée. Vous n'avez pas besoin de prendre de mesures spécifiques pour faire face aux pannes d'une seule zone qui affectent le service lui-même. Toutefois, pour assurer la résilience en cas de panne pour vos clients ou votre réseau, il est préférable d'exécuter les éditeurs et les abonnés avec une capacité suffisante dans plusieurs zones de la région. Si une zone est hors service, les clients de l'autre zone peuvent prendre le relais et traiter les messages. Il est recommandé de ne pas publier simultanément les modifications apportées à ces clients. Ainsi, si un bug est introduit, les autres zones non modifiées peuvent continuer à traiter les messages.
Résilience régionale
Pour faire face aux défaillances régionales, configurez des redondances supplémentaires dans vos éditeurs et abonnés. Vous pouvez exécuter des éditeurs et des abonnés dans plusieurs régions pour faire face à d'éventuelles pannes dans ces clients ou dans le réseau.
Si vous souhaitez être résilient face à d'éventuelles défaillances Pub/Sub dans une région, vous devez disposer d'un mécanisme de basculement prêt à faire face à une telle panne. Les approches possibles représentent un compromis entre la latence de remise des messages de bout en bout et vos coûts.
Pour minimiser la latence si le coût n'est pas un problème, la meilleure stratégie consiste à toujours publier et s'abonner simultanément dans différentes régions. Commencez par choisir le nombre de régions dans lesquelles vous souhaitez bénéficier d'une redondance. Ensuite, bien que cela ne soit pas strictement nécessaire, vous pouvez configurer un sujet et un abonnement pour chacune de ces régions.
Chaque éditeur crée autant de clients éditeur que de régions (un pour chaque région) et utilise un point de terminaison géographique différent pour s'assurer que les messages sont dirigés vers des régions distinctes. Si vous utilisez des sujets distincts, chaque client éditeur doit publier dans le sujet correspondant à la région. Pour chaque message, l'éditeur appelle la publication sur chaque client. Avec les publications redondantes, il n'est pas nécessaire de réessayer de publier si l'une d'elles échoue.
De même, chaque abonné crée autant de clients abonnés (un pour chaque région) et utilise un point de terminaison de localisation pour se connecter à une autre région. Si vous utilisez des abonnements différents pour chaque région, chaque client abonné doit utiliser l'abonnement correspondant. Notez que les régions utilisées pour les éditeurs et les abonnés ne doivent pas nécessairement être les mêmes. Les abonnés reçoivent les messages des trois abonnements et les traitent.
Cette configuration présente plusieurs fonctionnalités et exigences clés :
- Les pannes limitées à une seule région n'affectent pas le traitement des messages déjà publiés ni de ceux publiés pendant la panne. Étant donné que les messages ont été publiés dans plusieurs régions, ils restent disponibles dans les autres régions en cas de panne dans l'une d'elles. Pendant l'indisponibilité, les appels de publication échouent dans la région concernée, mais aboutissent dans les autres.
- La latence de traitement des messages n'est pas affectée tant qu'au moins l'une des régions par lesquelles transitent les messages est disponible.
- Le traitement des messages doit être idempotent. Étant donné que chaque message sera distribué plusieurs fois, le traitement des messages doit être résistant aux doublons. En cas d'indisponibilité régionale, certains de ces doublons peuvent arriver beaucoup plus tard que la première remise du message. Ces doublons proviennent probablement d'une autre région qui n'a pas subi de panne.
L'exécution avec ce type de redondance offre la plus grande résilience à tout type de panne. Cette configuration est recommandée pour les services Google internes qui s'appuient sur Pub/Sub et qui nécessitent la plus haute disponibilité. Toutefois, cette configuration multiplie le coût de distribution des messages par le nombre de régions utilisées. Il existe également un coût supplémentaire lié à l'utilisation du réseau interrégional pour les messages qui doivent être transférés d'une région à une autre.
Une autre approche de la redondance consiste à ne basculer que lorsque les requêtes échouent ou que les messages ne sont pas transmis des éditeurs aux abonnés comme prévu. Dans ce scénario, vous disposez d'une région principale vers laquelle vous redirigez vos éditeurs et abonnés via des points de terminaison géographiques. Comme précédemment, ces régions n'ont pas besoin d'être identiques. Vous disposez également d'une région de secours pour les éditeurs et les abonnés, qui est utilisée lorsque la région principale n'est pas disponible.
Les éditeurs ne publient que dans la région principale (via le point de terminaison géographique) lorsque leurs demandes sont envoyées avec succès. Chaque fois qu'une région est considérée comme indisponible, les éditeurs commencent à publier dans la région de secours. Il existe deux façons de déterminer si la région est hors service et de basculer vers une autre région. Cela peut être fait manuellement, et la configuration est mise à jour de manière dynamique chez les éditeurs. Les éditeurs peuvent également mettre à jour eux-mêmes la configuration si le taux d'erreurs dans les demandes de publication est suffisamment élevé.
Les abonnés doivent toujours se connecter à la région principale via le point de terminaison géographique. Vous pouvez décider que l'abonné peut utiliser la région de secours avec un ou plusieurs des déclencheurs suivants :
- Abonnez-vous toujours à la région de secours. Dans ce cas, l'abonné maintient une connexion à la région principale et à la région de secours à tout moment. Les mêmes régions peuvent être utilisées pour les sources principale et de secours, à la fois pour les éditeurs et les abonnés. Dans ce cas, l'abonné ne doit recevoir des messages que par le biais de la région de sauvegarde si l'éditeur a basculé.
- Détectez manuellement les abonnés et basculez-les vers la région de secours à l'aide d'une configuration. Si vous détectez une panne, vous pouvez basculer vers la région de secours, puis revenir à la région principale une fois la panne résolue.
- Basculement en cas d'erreurs d'abonné. Si les requêtes des abonnés renvoient des erreurs, vous pouvez les utiliser comme indication que vous devez basculer vers la région de secours. Notez que les bibliothèques clientes Pub/Sub réessaient les requêtes pull de flux en interne en cas d'erreurs temporaires. Vous ne pourrez donc peut-être pas détecter les longues périodes d'erreurs inattendues. De plus, le taux d'erreur de StreamingPull devrait être de 100 %, même en fonctionnement normal.
- Basculez si l'abonné ne reçoit pas de messages pendant une période anormalement longue. En supposant que les messages soient publiés de manière cohérente, les abonnés peuvent toujours en recevoir. Si elles ne reçoivent aucun message pendant une longue période, il peut s'agir d'un problème lié à l'abonnement dans Pub/Sub dans la région principale. Ce problème est résolu en basculant vers la région de secours.
Parmi les quatre options, la première est idéale. Une connexion d'abonné n'entraîne aucun frais si aucun message ne transite par celle-ci. Le seul coût est lié à l'empreinte de l'instance supplémentaire de la bibliothèque cliente de l'abonné, qui peut être négligeable. Vous devez également tenir compte du quota de connexions StreamingPull ouvertes par région.
L'avantage de ce deuxième modèle est qu'il n'y a pas de multiplicateur dans le coût Pub/Sub, car les messages ne sont publiés qu'une seule fois. Toutefois, le compromis est que, pour certains types de pannes, les messages publiés avant le début de la panne peuvent ne pas être disponibles tant que la panne n'est pas résolue. Il est possible que les messages stockés dans la région indisponible ne puissent pas être distribués aux abonnés, quel que soit leur emplacement de connexion. Les messages publiés dans la région de secours pendant l'indisponibilité peuvent être disponibles. En outre, il est possible que les éditeurs ou les abonnés connaissent une période d'indisponibilité avec des taux d'erreur plus élevés. Cela dépend de la méthode utilisée pour détecter une panne et du temps nécessaire pour basculer vers la région de secours.
Quelle que soit l'option choisie, soyez conscient de la façon dont elle peut interagir avec les fonctionnalités de Pub/Sub. La distribution ordonnée et la distribution de type "exactement une fois" offrent leurs garanties dans une région. Par exemple, si vous utilisez la technique de redondance de basculement, l'ordre de remise des messages n'est garanti que pour les messages publiés dans la même région. L'abonné peut recevoir des messages publiés dans la région de secours avant ceux publiés dans la région principale, même si les messages ont été publiés en premier dans la région principale.
Affiner les éditeurs
Quelle que soit l'option de basculement que vous choisissez, vous devez effectuer des étapes de réglage supplémentaires au niveau des éditeurs eux-mêmes. Le réglage du comportement des éditeurs garantit des performances optimales sous forte charge. Le traitement par lot des messages est un moyen de réduire les coûts au détriment de la latence. Il ne s'agit pas d'un problème de fiabilité en soi, et il n'est donc pas abordé ici. Concentrez-vous plutôt sur d'autres paramètres utiles pour la fiabilité, y compris les paramètres de nouvelle tentative et de contrôle du flux.
La publication peut échouer pour différentes raisons, y compris des raisons temporaires comme l'indisponibilité du réseau ou des raisons qui nécessitent l'intervention de l'utilisateur, comme des modifications d'autorisation. La bibliothèque cliente Pub/Sub réessaie en cas d'erreurs temporaires à l'aide des paramètres spécifiés dans les paramètres de nouvelle tentative. Ces paramètres contrôlent le comportement de l'intervalle exponentiel entre les tentatives de publication des RPC qui échouent pour des raisons temporaires. Bien que les paramètres par défaut fonctionnent généralement bien dans la plupart des scénarios, il peut arriver que vous souhaitiez ajuster ces valeurs.
Les deux propriétés que vous souhaiterez probablement ajuster sont le délai avant expiration RPC initial et le délai avant expiration total. Le délai RPC avant expiration initial correspond au temps accordé au premier RPC de publication pour se terminer. Si un RPC échoue ou expire, un autre est tenté avec un délai d'attente plus long jusqu'à ce que le nombre total de requêtes ou le délai d'attente total soient dépassés.
Le délai avant expiration initial peut être ajusté si votre éditeur est limité par le réseau ou s'il est éloigné du centre de données Google Cloud le plus proche qui exécute Pub/Sub. Les contraintes réseau peuvent être des limitations du débit de la machine sur laquelle l'éditeur s'exécute ou le résultat d'autres services gourmands en bande passante s'exécutant sur la même machine. Si le délai avant expiration est trop court, les RPC initiaux peuvent échouer à plusieurs reprises, ce qui nécessite davantage de tentatives (avec des délais avant expiration plus longs) pour publier correctement. La nécessité de réessayer à plusieurs reprises augmente la latence de publication. Dans ce cas, l'augmentation du délai avant expiration initial peut accélérer les publications.
Si la connexion réseau n'est pas fiable, il peut être utile d'augmenter le délai avant expiration total et le délai avant expiration initial. Un délai d'attente total plus long donne au RPC de publication plus de temps pour se terminer correctement. Lorsque les RPC de publication échouent systématiquement avec des erreurs de délai dépassé, envisagez d'ajuster ces valeurs.
Des erreurs continues de dépassement du délai lors de la publication peuvent également indiquer la nécessité d'ajuster le contrôle du flux de l'éditeur. Ces paramètres vous permettent de vous assurer que vos éditeurs sont résilients aux pics de trafic entrant qui génèrent davantage de messages à envoyer à Pub/Sub. Une forte augmentation des requêtes sortantes peut surcharger la capacité du processeur, de la mémoire ou du réseau de l'éditeur. Lorsque la publication est surchargée, elle ne peut pas traiter les demandes ni les réponses de publication avant les délais d'expiration. Cela entraîne encore plus de demandes de publication et, en fin de compte, atteint le délai d'expiration total. Le contrôle de flux de l'éditeur limite le nombre de messages ou d'octets qui peuvent être en attente sans réponse à la demande de publication. Limiter le nombre de requêtes de cette manière permet de maintenir l'utilisation des ressources à un niveau gérable, même en cas de pics. Selon le fonctionnement de votre éditeur, vous pouvez autoriser les RPC de publication ultérieurs à attendre la capacité en autorisant la publication à bloquer d'autres requêtes. Vous pouvez également renvoyer la requête aux appelants de votre service en faisant en sorte que le contrôle du flux renvoie une erreur lorsque la capacité est atteinte. Vous configurez la façon dont la bibliothèque cliente de l'éditeur répond au comportement de dépassement de limite.
Abonnés gagnés grâce à l'affinage
Un réglage de l'abonné peut également être nécessaire pour garantir un fonctionnement fiable. Comme pour les éditeurs, vous pouvez ajuster les paramètres de contrôle de flux des abonnés pour vous assurer qu'ils ne sont pas submergés. La bibliothèque cliente de l'abonné utilise l'extraction de flux, où le client ouvre un flux persistant vers le serveur et le serveur envoie des messages dès qu'ils sont disponibles. En cas de forte augmentation du nombre de messages publiés, l'abonné peut recevoir plus de messages qu'il ne peut en traiter. Avec le contrôle de flux en place, le nombre de messages non confirmés en attente pour le client à un moment donné est limité. Cela réduit le nombre de messages traités simultanément et répartit leur traitement sur une période plus longue. La répartition de la charge permet aux abonnés de respecter les limites de ressources qui ont un impact sur le traitement des messages, ce qui peut entraîner un effet domino et rendre impossible le traitement des messages.
Le contrôle du flux seul suffit si vous ne vous attendez qu'à des pics de quantité de données à traiter qui finissent par diminuer. Si le trafic augmente généralement au fil du temps en raison d'une utilisation accrue, le contrôle du flux protège les abonnés. Toutefois, cela peut entraîner un backlog qui continue de s'accumuler et qui empêche la distribution des messages avant l'expiration de la durée de conservation des messages. Dans ce cas, vous pouvez également définir l'autoscaling pour augmenter le nombre d'abonnés en réponse à un nombre croissant de messages non confirmés. La procédure de configuration dépend de la plate-forme de calcul que vous utilisez pour vos abonnés. Par exemple, le scaler automatique de Compute Engine vous permet d'effectuer le scaling en fonction de métriques telles que le nombre de messages non distribués. L'utilisation de l'autoscaling et du contrôle de flux vous permet de vous assurer que vos abonnés sont résilients aux autres pics à court terme du débit de messages et à la croissance à long terme qui nécessite plus de puissance de calcul. Assurez-vous de suivre les bonnes pratiques pour utiliser les métriques Pub/Sub comme signal de scaling.
Utiliser les instantanés et la recherche pour des déploiements sécurisés
La perte de messages est généralement un événement catastrophique. Pub/Sub propose une distribution "au moins une fois" pour tous les messages publiés. Toutefois, le traitement correct de ces messages dépend du comportement des abonnés. Si les messages sont correctement confirmés, Pub/Sub ne les renvoie pas. Par conséquent, un bug introduit dans le nouveau code d'abonné que vous déployez et qui confirme la réception de messages sans les avoir traités correctement peut entraîner une perte de messages induite par l'abonné. Pub/Sub propose la fonctionnalité Instantané et recherche, qui peut vous aider à vous assurer de traiter correctement chaque message, même en cas de bugs d'abonné.
Le modèle de déploiement de chaque abonné doit être le suivant :
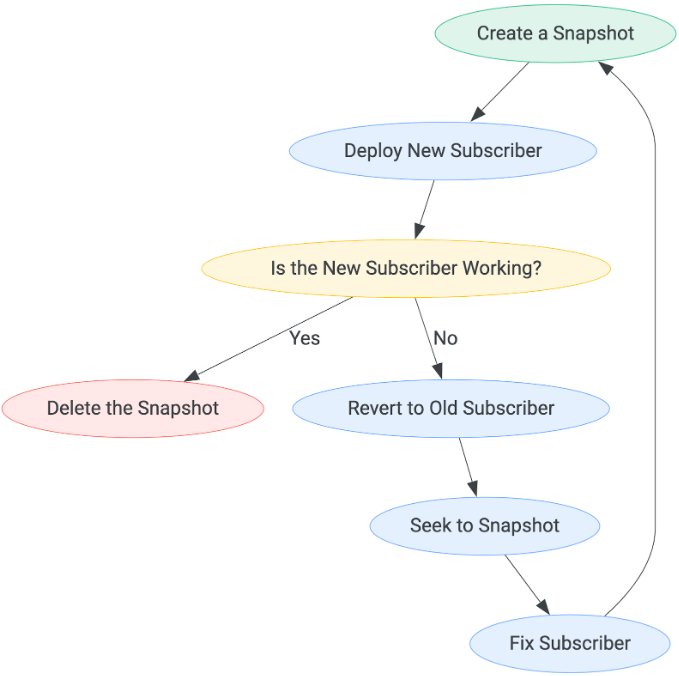
Le temps d'attente avant de déterminer si le nouvel abonné fonctionne peut varier en fonction de votre cas d'utilisation. La seule façon de quitter le flux d'étapes est lorsqu'un abonné est considéré comme fonctionnel, auquel cas l'instantané peut être supprimé.
L'utilisation de l'instantané et de la recherche n'est pas destinée à remplacer les bonnes pratiques concernant l'exécution du logiciel pour la première fois dans un environnement hors production et le déploiement progressif en production. Elles offrent un niveau de protection supplémentaire pour garantir le traitement fiable des données. L'inconvénient est que la recherche de l'instantané peut entraîner la distribution de messages en double que votre abonné a déjà traités. Toutefois, étant donné que Pub/Sub utilise par défaut la sémantique de distribution "au moins une fois", vos abonnés sont déjà résilients à la redistribution des messages.