Google Cloud コンソールまたは Cloud Monitoring API を使用して Pub/Sub をモニタリングできます。
このドキュメントでは、Monitoring を使用して Google Cloud コンソールで Pub/Sub の使用状況をモニタリングする方法について説明します。
Pub/Sub の指標に加えて他の Google Cloud リソースの指標も表示するには、Monitoring を使用します。
それ以外の場合は、Pub/Sub 内で提供されるモニタリング ダッシュボードを使用できます。トピックをモニタリングするとサブスクリプションをモニタリングするをご覧ください。
自動スケーリングで指標を使用する際のベスト プラクティスについては、Pub/Sub 指標をスケーリング シグナルとして使用する際のベスト プラクティスをご覧ください。
始める前に
Monitoring を使用する前に、次のものが準備されていることを確認します。
Cloud 請求先アカウント
課金が有効になっている Pub/Sub プロジェクト
Cloud コンソールを使用したクイックスタートを完了すると、両方を確実に取得できます。
既存のダッシュボードを表示する
ダッシュボードを使用すると、同じコンテキストで異なるソースからのデータを表示して分析できます。Google Cloud には、事前定義されたダッシュボードとカスタム ダッシュボードの両方が用意されています。たとえば、事前定義された Pub/Sub ダッシュボードの表示や、Pub/Sub に関連する指標データ、アラート ポリシー、ログエントリを表示するカスタム ダッシュボードの作成が行えます。
Cloud Monitoring を使用して Pub/Sub プロジェクトをモニタリングする手順は次のとおりです。
Google Cloud コンソールで、[モニタリング] ページに移動します。
ページ上部でまだプロジェクトの名前を選択していない場合はここで選択します。
ナビゲーション メニューで [ダッシュボード] をクリックします。
[ダッシュボードの概要] ページで、新しいダッシュボードを作成するか、既存の Pub/Sub ダッシュボードを選択します。
既存の Pub/Sub ダッシュボード検索するには、すべてのダッシュボードのフィルタで名前プロパティを選択して「
Pub/Sub」と入力します。
カスタム ダッシュボードの作成、編集、管理方法については、カスタム ダッシュボードの管理をご覧ください。
単一の Pub/Sub 指標を表示する
Google Cloud コンソールを使用して 1 つの Pub/Sub 指標を表示するには、次の操作を行います。
Google Cloud コンソールで、[モニタリング] ページに移動します。
ナビゲーション パネルで、[Metrics Explorer] を選択します。
[構成] セクションで [指標を選択] をクリックします。
フィルタに「
Pub/Sub」と入力します。[有効なリソース] で、[Pub/Sub サブスクリプション] または [Pub/Sub トピック] を選択します。
特定の指標にドリルダウンして [Apply] をクリックします。
特定の指標のページが開きます。
モニタリング ダッシュボードの詳細については、Cloud Monitoring のドキュメントをご覧ください。
Pub/Sub の指標とリソースタイプを表示する
Pub/Sub が Cloud Monitoring に報告する指標を確認するには、Cloud Monitoring ドキュメントの Pub/Sub 指標の一覧をご覧ください。
モニタリング対象リソースタイプ
pubsub_topic、pubsub_subscription、またはpubsub_snapshotの詳細を確認する方法については、Cloud Monitoring ドキュメントのモニタリング対象リソースタイプをご覧ください。
PromQL エディタにアクセスする
Metrics Explorer は、指標データの探索と可視化用に設計された Cloud Monitoring 内のインターフェースです。Metrics Explorer では、Prometheus Query Language(PromQL)を使用して Pub/Sub 指標をクエリして分析できます。
Metrics Explorer でコードエディタにアクセスして PromQL で Cloud Monitoring の指標をクエリするには、PromQL のコードエディタを使用するをご覧ください。
たとえば、PromQL クエリを入力して、過去 1 時間に特定のサブスクリプションに送信されたメッセージの数をモニタリングできます。
sum(
increase({
"__name__"="pubsub.googleapis.com/subscription/sent_message_count",
"monitored_resource"="pubsub_subscription",
"project_id"="your-project-id",
"subscription_id"="your-subscription-id"
}[1h])
)
割り当て使用量をモニタリングする
特定のプロジェクトについて、現在の割り当てと使用状況を確認するには、IAM と管理の割り当てダッシュボードを使用します。
過去の割り当ての使用状況は、次の指標を使用して確認できます。
これらの指標では、consumer_quota モニタリング対象リソース タイプが使用されます。割り当てに関連するその他の指標については、指標の一覧をご覧ください。
たとえば、次の PromQL クエリにより、各リージョンで使用されているパブリッシャー割り当ての割合を示すグラフを作成できます。
sum by (quota_metric, location) (
rate({
"__name__"="serviceruntime.googleapis.com/quota/rate/net_usage",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com",
"quota_metric"="pubsub.googleapis.com/regionalpublisher"
}[${__interval}])
)
/
(max by (quota_metric, location) (
max_over_time({
"__name__"="serviceruntime.googleapis.com/quota/limit",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com",
"quota_metric"="pubsub.googleapis.com/regionalpublisher"
}[${__interval}])
) / 60 )
使用量がデフォルトの割り当て上限を超えることが予想される場合は、関連するすべての割り当てに対してアラート ポリシーを作成します。このアラートは、使用量が上限の一定割合に達したときに起動します。たとえば、次の PromQL クエリでは、いずれかの Pub/Sub 割り当ての使用率が 80% を超えるとアラート ポリシーがトリガーされます。
sum by (quota_metric, location) (
increase({
"__name__"="serviceruntime.googleapis.com/quota/rate/net_usage",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com"
}[1m])
)
/
max by (quota_metric, location) (
max_over_time({
"__name__"="serviceruntime.googleapis.com/quota/limit",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com"
}[1m])
)
> 0.8
割り当て指標のモニタリングとアラートをカスタマイズする方法について詳しくは、割り当て指標の使用をご覧ください。
割り当てについて詳しくは、割り当てと上限をご覧ください。
健全なサブスクリプションを維持する
正常なサブスクリプションを維持するには、Pub/Sub が提供する指標を使用して、いくつかのサブスクリプション プロパティをモニタリングします。たとえば、確認応答されていないメッセージの量、メッセージの確認応答の期限切れなどをモニタリングできます。また、メッセージ配信レイテンシが低く、正常なサブスクリプションであるかどうかを確認することもできます。
特定の指標の詳細については、次のセクションをご覧ください。
メッセージのバックログをモニタリングする
サブスクライバーがメッセージのフローに確実に対応できるようにするには、ダッシュボードを作成します。ダッシュボードには、すべてのサブスクリプションについて、リソース別に集計された次のバックログ指標が表示されます。
確認応答されていないメッセージ(
subscription/num_unacked_messages_by_region)。確認応答されていないメッセージの数を確認できます。最も古い未確認応答メッセージの経過時間(
subscription/oldest_unacked_message_age_by_region)。サブスクリプションのバックログ内で最も古い未確認応答メッセージの経過時間を表示します。配信レイテンシの健全性スコア(
subscription/delivery_latency_health_score)。配信レイテンシに関連するサブスクリプションの全体的な健全性を確認します。この指標の詳細については、このドキュメントの関連セクションをご覧ください。
これらの値がシステムのコンテキストで許容範囲外になった場合にトリガーされるアラート ポリシーを作成します。たとえば、確認応答されていないメッセージの絶対数は必ずしも意味を持つとは限りません。100 万件のメッセージのバックログは、1 秒あたり 100 万件のメッセージのサブスクリプションでは許容できる可能性がありますが、1 秒あたり 1 件のメッセージのサブスクリプションでは許容できません。
バックログに関する一般的な問題
| 現象 | 問題 | ソリューション |
|---|---|---|
oldest_unacked_message_age_by_region と num_unacked_messages_by_region の両方が連動して増加しています。 |
サブスクライバーがメッセージの量についていけていない |
|
バックログのサイズが安定的で小さく、かつ oldest_unacked_message_age_by_region が着実に増加している場合、処理できないメッセージが存在する可能性があります。 |
メッセージが溜まる |
|
oldest_unacked_message_age_by_region がサブスクリプションのメッセージ保持期間を超えています。 |
永続的なデータ損失 |
|
配信レイテンシの健全性をモニタリングする
Pub/Sub では、配信レイテンシは、パブリッシュされたメッセージがサブスクライバーに配信されるまでにかかる時間です。メッセージ バックログが増加している場合は、配信レイテンシの健全性スコア(subscription/delivery_latency_health_score)を使用して、レイテンシの増加の原因となっている要因を確認できます。
この指標は、10 分のローリング期間における単一サブスクリプションの健全性を測定します。この指標により、サブスクリプションが一貫した低レイテンシを実現するために必要な、次の基準に関する分析情報が得られます。
無視できるシーク リクエスト。
無視できる否定応答メッセージ(nack メッセージ)。
期限切れのメッセージの確認応答期限。
一貫して 30 秒未満の確認応答のレイテンシ。
一貫して低い使用率。つまり、サブスクリプションが新しいメッセージを処理するのに十分な容量が常にある。
配信レイテンシの健全性スコアの指標は、指定された基準ごとに 0 または 1 のスコアを報告します。スコア 1 は正常な状態、スコア 0 は異常な状態を示します。
シーク リクエスト: 過去 10 分間にサブスクリプションがシーク リクエストを受けた場合、スコアは 0 に設定されます。サブスクリプションをシークすると、古いメッセージが最初にパブリッシュされたかなり後から再生され、配信のレイテンシが長くなる可能性があります。
否定応答(nack)メッセージ: 過去 10 分間にサブスクリプションに否定応答(nack)リクエストがあった場合、スコアは 0 に設定されます。否定応答が返されたメッセージは、配信レイテンシを増加して再配信されます。
確認応答期限が経過している: 過去 10 分間に、サブスクリプションに期限切れの確認応答期限があった場合、スコアは 0 に設定されます。確認応答期限が切れたメッセージは、配信レイテンシを増加して再配信されます。
確認応答レイテンシ: 過去 10 分間のすべての確認応答レイテンシの 99.9 パーセンタイルが 30 秒を超えた場合、スコアは 0 に設定されます。確認応答レイテンシが高い場合、サブスクライバー クライアントがメッセージの処理に異常に長い時間を要していることを示しています。このスコアは、サブスクライバーのクライアント側にバグやリソース制約があることを意味する場合があります。
使用率が低い: 使用率は、サブスクリプション タイプごとに異なる方法で計算されます。
StreamingPull: 十分なストリームを開いていない場合、スコアは 0 に設定されます。さらにストリームを開いて、新しいメッセージに十分な容量を確保します。
Push: push エンドポイントに未処理のメッセージが多すぎる場合、スコアは 0 に設定されます。新しいメッセージに対応できるように、プッシュ エンドポイントの容量を増やします。
Pull: 未解決の pull リクエストが十分にない場合、スコアは 0 に設定されます。新しいメッセージを受信できるように、同時プルリクエストをさらに開きます。
この指標を表示するには、Metrics Explorer で、Pub/Sub サブスクリプション リソースタイプの [配信レイテンシの健全性スコア] の指標を選択します。フィルタを追加して、一度に 1 つの定期購入のみを選択します。Stacked area chart を選択して特定の時間にカーソルを合わせると、その時点のサブスクリプションの基準スコアを確認できます。
次に示すのは、積み上げ面グラフを使用して 1 時間にプロットされた指標のスクリーンショットです。統合ヘルススコアは、午前 4 時 15 分に 5 に増加し、各基準のスコアは 1 になります。その後、合計スコアは午前 4 時 20 分に 4 に減少し、使用率スコアが 0 に低下します。
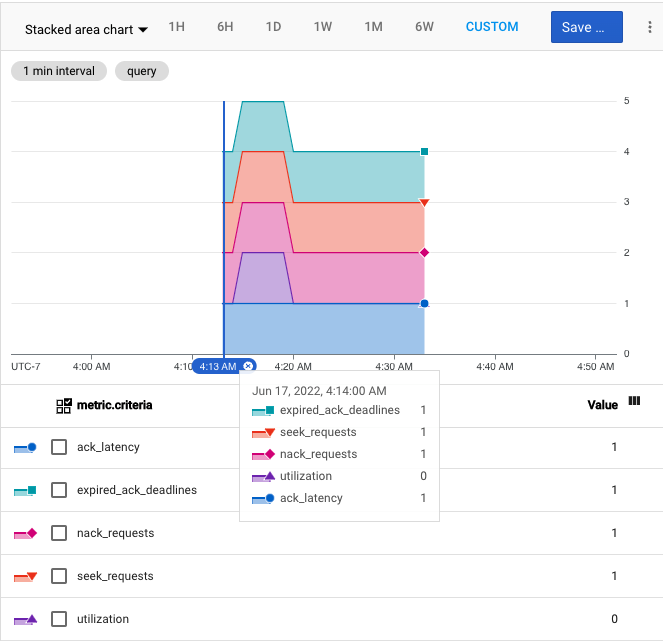
PromQL は、表現力の高いテキストベースのインターフェースを Cloud Monitoring の時系列データに提供します。次の PromQL クエリは、サブスクリプションの配信レイテンシの健全性スコアを測定するグラフを作成します。
sum_over_time(
{
"__name__"="pubsub.googleapis.com/subscription/delivery_latency_health_score",
"monitored_resource"="pubsub_subscription",
"subscription_id"="$SUBSCRIPTION"
}[${__interval}]
)
確認応答の期限切れをモニタリングする
メッセージ配信のレイテンシを短縮するために、Pub/Sub では、サブスクライバーのクライアントは限られた時間内に特定のメッセージの確認応答(ack)ができます。この期間は ack 期限と呼ばれます。サブスクライバーでのメッセージの確認応答に時間がかかりすぎると、メッセージが再配信され、サブスクライバーに重複するメッセージが表示されます。これには、いくつかの要因が考えられます。
サブスクライバーのプロビジョニングが不足している(スレッドまたはマシンがさらに必要)。
各メッセージの処理に、メッセージの確認応答期限よりも時間がかかる。Google Cloud クライアント ライブラリは、通常、個々のメッセージの期限を構成可能な上限まで延長します。ただし、最大延長期限はライブラリにも適用されます。
一貫してクライアントをクラッシュするメッセージがある。
サブスクライバーがどれくらいの割合で確認応答期限を逃しているかを測定できます。具体的な指標は、サブスクリプション タイプによって異なります。
pull と StreamingPull:
subscription/expired_ack_deadlines_countpush:
response_code != "success"でフィルタされたsubscription/push_request_count
確認応答期限切れの割合が過度に高いと、システムのコスト効率が悪くなることがあります。各再配信と、各メッセージの繰り返しの処理試行は課金の対象となります。逆に、期限切れの割合が低い場合(たとえば、0.1~1%)は正常です。
メッセージ スループットをモニタリングする
pull サブスクライバーと StreamingPull サブスクライバーは、各 pull レスポンスでメッセージのバッチを受信することがあります。push サブスクリプションは、push リクエストごとに 1 つのメッセージを受信します。次の指標を使用して、サブスクライバーによって処理されるバッチ メッセージのスループットをモニタリングできます。
pull:
subscription/pull_request_count(この指標には、メッセージなしで返された pull リクエストも含まれる場合があります)StreamingPull:
subscription/streaming_pull_response_count
delivery_type ラベルでフィルタされた指標 subscription/sent_message_count を使用して、サブスクライバーによって処理されている個々の(つまり、バッチされていない)メッセージ スループットをモニタリングできます。
次の PromQL クエリは、特定の Pub/Sub サブスクリプションに送信されたメッセージの総数を 10 分間のローリング期間で示す時系列グラフを返します。$PROJECT_NAME と $SUBSCRIPTION_NAME のプレースホルダ値を、実際のプロジェクトとトピックの ID に置き換えます。
sum(
increase({
"__name__"="pubsub.googleapis.com/subscription/sent_message_count",
"monitored_resource"="pubsub_subscription",
"project_id"="$PROJECT_NAME",
"subscription_id"="$SUBSCRIPTION_NAME"
}[10m])
)
push サブスクリプションをモニタリングする
push サブスクリプションの場合は、次の指標をモニタリングします。
subscription/push_request_countresponse_codeとsubscription_idで指標をグループ化します。Pub/Sub の push サブスクリプションでは、メッセージの暗黙の確認応答としてレスポンス コードを使用するため、push リクエストのレスポンス コードをモニタリングすることが重要です。push サブスクリプションでは、タイムアウトまたはエラーが発生すると、指数バックオフが行われるため、エンドポイントの応答に基づいてバックログが急速に増加することがあります。エラー率が高い場合は配信の遅延とバックログの増加につながるため、アラートを設定することを検討してください。レスポンス クラスでフィルタされた指標を作成できます。ただし、push リクエストの数のほうが、バックログのサイズと経過時間の増加を調査するツールとして役立つ傾向があります。
subscription/num_outstanding_messages一般に、Pub/Sub は未処理のメッセージの数を制限します。ほとんどの場合、未処理のメッセージは 1,000 件未満にする必要があります。スループットが 1 秒あたり 10,000 メッセージのレートに達すると、サービスでは未処理のメッセージ数の制限が設定されます。この制限は 1,000 単位で行われます。最大値を超えると明確な保証はないため、1,000 件の未処理のメッセージが適切な目安になります。
subscription/push_request_latenciesこの指標は、push エンドポイントのレスポンスのレイテンシ分布を把握するのに役立ちます。未処理のメッセージの数に制限があるため、エンドポイントのレイテンシはサブスクリプションのスループットに影響します。各メッセージの処理に 100 ミリ秒かかる場合、一般的に、スループットの上限は 1 秒あたり 10 メッセージになります。
未処理のメッセージの上限にアクセスするには、push サブスクライバーが、受信したメッセージの 99% を超える確認応答を行う必要があります。
PromQL を使用して、サブスクライバーが確認応答するメッセージの比率を計算できます。次の PromQL クエリは、サブスクライバーがサブスクリプションに確認応答したメッセージの比率のグラフを作成します。
rate({
"__name__"="pubsub.googleapis.com/subscription/push_request_count",
"monitored_resource"="pubsub_subscription",
"subscription_id"="$SUBSCRIPTION",
"response_class"="ack"
}[${__interval}])
/
rate({
"__name__"="pubsub.googleapis.com/subscription/push_request_count",
"monitored_resource"="pubsub_subscription",
"subscription_id"="$SUBSCRIPTION"
}[${__interval}])
フィルタを使用してサブスクリプションをモニタリングする
サブスクリプションにフィルタを構成すると、Pub/Sub はフィルタと一致しないメッセージに自動的に確認応答します。この自動確認応答をモニタリングできます。
バックログ指標には、フィルタに一致するメッセージのみが含まれます。
フィルタと一致しない自動確認メッセージの比率をモニタリングするには、subscription/ack_message_count 指標を使用し、delivery_type ラベルを filter に設定します。
フィルタと一致しない自動確認応答メッセージのスループットとコストをモニタリングするには、subscription/byte_cost 指標を使用し、operation_type ラベルを filter_drop に設定します。これらのメッセージの料金の詳細については、Pub/Sub の料金ページをご覧ください。
SMT でサブスクリプションをモニタリングする
サブスクリプションにメッセージをフィルタする SMT が含まれている場合、バックログ指標には、SMT が実際に実行されるまで、フィルタされたメッセージが含まれます。つまり、バックログが大きく表示され、最も古い未確認応答メッセージの経過時間が、サブスクライバーに配信されるメッセージよりも長く表示される可能性があります。これらの指標を使用してサブスクライバーを自動スケーリングする場合は、特にこの点に注意してください。
転送済みの配信不能メッセージをモニタリングする
Pub/Sub がデッドレター トピックに転送する配信不能メッセージをモニタリングするには、subscription/dead_letter_message_count 指標を使用します。この指標は、Pub/Sub がサブスクリプションから転送する未配信メッセージの数を示します。
Pub/Sub が配信不能メッセージを転送していることを確認するには、subscription/dead_letter_message_count 指標と topic/send_request_count 指標を比較します。Pub/Sub がこれらのメッセージを転送するデッドレター トピックの比較を行います。
また、デッドレター トピックにサブスクリプションを添付し、次の指標を使用して、このサブスクリプションで転送された転送不能メッセージをモニタリングすることもできます。
subscription/num_unacked_messages_by_region- サブスクリプションで累積された転送メッセージ数
subscription/oldest_unacked_message_age_by_region- サブスクリプション内で転送された最も古いメッセージの経過時間
正常なパブリッシャーを維持する
パブリッシャーの主な目標は、メッセージ データを迅速に保持することです。このパフォーマンスは、response_code でグループ化された topic/send_request_count を使用してモニタリングします。この指標は、Pub/Sub が正常であり、リクエストを受け入れているかどうかを示します。
ほとんどの Cloud クライアント ライブラリは、失敗したメッセージを再試行するため、再試行可能なエラーのバックグラウンド率(1% 未満)を懸念する必要はありません。エラー率が 1% を超える場合は調査します。再試行不可能なコードは(クライアント ライブラリではなく)アプリケーションで処理されるため、レスポンス コードを確認する必要があります。パブリッシャー アプリケーションで異常な状態を示す適切な方法がない場合、topic/send_request_count の指標に対するアラートを設定することを検討してください。
パブリッシュ クライアントで、失敗したパブリッシュ リクエストを追跡することも同様に重要です。クライアント ライブラリは、通常、失敗したリクエストを再試行しますが、パブリッシュを保証するものではありません。Cloud クライアント ライブラリの使用時に永続的なパブリッシュ エラーを検出する方法については、メッセージのパブリッシュをご覧ください。パブリッシャー アプリケーションでは、少なくとも、永続的なパブリッシュ エラーをログに記録するようにしてください。これらのエラーを Cloud Logging に記録する場合は、アラート ポリシーを使用してログベースの指標を設定できます。
メッセージ スループットをモニタリングする
パブリッシャーはメッセージをバッチで送信できます。パブリッシャーによって送信されるメッセージ スループットを次の指標でモニタリングできます。
topic/send_request_count: パブリッシャーによって送信されたバッチ メッセージの量topic/message_sizesのカウント: パブリッシャーによって送信された個々の(つまり、バッチ処理されていない)メッセージの量。
公開されたメッセージの正確な数を取得するには、次の PromQL クエリを使用します。この PromQL クエリは、定義された時間間隔内に特定の Pub/Sub トピックにパブリッシュされた個々のメッセージの数を効果的に取得します。$PROJECT_NAME と $TOPIC_ID のプレースホルダ値を、実際のプロジェクトとトピックの ID に置き換えます。
sum by (topic_id) (
increase({
"__name__"="pubsub.googleapis.com/topic/message_sizes_count",
"monitored_resource"="pubsub_topic",
"project_id"="$PROJECT_NAME",
"topic_id"="$TOPIC_ID"
}[${__interval}])
)
特に日次指標の可視性を高めるには、次の点を考慮してください。
より長い期間のデータを表示して、日々の傾向をより詳しく把握します。
棒グラフを使用して、1 日のメッセージ数を表します。
次のステップ
特定の指標のアラートを作成するには、指標ベースのアラート ポリシーの管理をご覧ください。
PromQL を使用してモニタリング グラフを作成する方法については、PromQL のコードエディタを使用するをご覧ください。
指標、モニタリング対象リソース、モニタリング対象リソース グループ、アラート ポリシーなどの Monitoring API の API リソースの詳細については、API リソースをご覧ください。