analyzeSyntax メソッドは、指定されたテキストの言語構造に関する詳細を返します。テキスト内の各トークンについて、Natural Language API により、その内部構造(形態論)と文におけるその役割(構文)に関する情報が提供されます。
形態論とは、単語の内部構造について研究したものです。形態論は、1 つの単語の構成要素(語幹、語素、接頭辞、接尾辞など)がどのように配置または変更されて、さまざまな意味を持つようになるかに注目しています。たとえば、英語では、可算名詞を複数形にする場合にはその末尾に「-s」や「-es」を付加し、動詞を過去形にする場合にはその末尾に「-d」や「-ed」を付加します。接尾辞「-ly」は、副詞を作成するために形容詞に追加されます(たとえば、形容词「happy」に「-ly」を追加して、副詞「happyfully」を作成する)。
Natural Language API では、形態素解析を使用して、単語の文法情報を推測します。
形態論は言語によって大幅に異なります。ロシア語などの言語では、単語の末尾は、単語の文中での役割を示します(たとえば、主格である場合に本という意味を表す「книга」は、動詞の直接目的語の場合は「книгу」になる)。これは、文の意味を変えずに語順を変更できることを意味しますが、異なる語順は文脈上の妥当性に影響します。品詞を示す接頭辞や接尾辞がない英語や中国語などの言語は、単語のそれぞれの役割を示すために文中の語順に依存します。その結果、形態素解析は、ソース言語と、その言語の中でサポートされる形態論の理解度に大きく依存します。
構文とは、句と文の構造について研究したものです。構文と形態論は連携して文法的な関係を示しますが、言語が異なればその工程も異なります。たとえば、直接目的語の役割を示す場合、ロシア語では接尾辞(「книгу」の「у」)を使用する一方、英語では単語の順序を使用し、動詞の後に直接目的語を続けます(read the book)。
analyzeSyntax レスポンスは、partOfSpeech フィールドで形態論情報を返し、dependencyTree フィールドで単語間の構文関係を返します。
品詞
構文リクエスト内では、品詞と形態論情報はレスポンスの partOfSpeech フィールドで返されます。partOfSpeech フィールドには、より明示的な形態論情報に加えて、品詞(POS)情報が含まれる一連のサブフィールドも含まれます。このサブフィールドについては以下をご覧ください。
tag: 品詞が大まかな POS タグ(NOUN、VERB など)で示され、最上位の表層構文情報が提供されます。POS タグは、パターンを作成したり、以降の言語分析のために曖昧さを取り除いたりするのに役立ちます(「train」に「NOUN」または「VERB」のタグを付けるなど)。number: 単語の文法上の数を示します。英語では、可算名詞に接尾辞「-s」を付加して複数であることを示します(たとえば、「dog+s」は複数の犬を意味します)。複数形の接尾辞がない場合、通常は単数形と呼ばれます。アラビア語などの一部の言語には、両数の概念もあります。このフィールドには次の値が含まれることがあります。SINGULAR(単数): 1 つの数を示します。PLURAL(複数): 複数の数を示します。DUAL(両数): 2 つの数を示します。
person: 単語の文法上の人称を特定します。英語では、「I / me」は一人称単数であり、表現の話し手(または書き手)を指します。一方、「you」は対象とする相手(聞き手)を指し、「she / her」と「he / him」は他の個人を指します。このフィールドには次の値が含まれることがあります。FIRST(一人称): 話し手を示します。SECOND(二人称): 対象とする相手、つまり聞き手を示します。THIRD(三人称): 話し手 / 聞き手以外の個人を示します。REFLEXIVE_PERSON: たとえば「The cat licked itself」のように主語と目的語が同じエンティティを指すことを意味します。この場合、代名詞に「-self」を付加して再帰代名詞であることを示します。ロシア語と日本語では、再帰代名詞は独立した代名詞です。(たとえば「John loves himself」は、ロシア語では「Джон любит себя」となり、「себя」の部分が通性代名詞を示す「self」に相当します。日本語では「太郎は自分を愛している」となり、「自分」の部分が通性代名詞を示す「self」に相当します。再帰代名詞をご覧ください。
gender: 名詞の文法上の性別を示します。このフィールドには次の値が含まれることがあります。FEMININE: 文法上の中性MASCULINE: 文法上の男性NEUTER: 文法上の中性
case: 単語の文法上の格と、句または文におけるその役割を示します。このフィールドには次の値が含まれることがあります。-
ACCUSATIVEcase(対格)は、他動詞の直接目的語を示します。 ADVERBIAL格(副詞格)は、形容詞の副詞形を示します。英語では、明確な副詞格を使用するのではなく、副詞(「well」)と形容詞(「good」)を区別するために別々の単語を使用します。 英語での接尾辞「-ly」は形容詞から副詞を派生させますが(たとえば、「happy」と「happily」)、これは「格」とは見なされません。COMPLEMENTIVE格(補語)(中国語)は、接続助詞を使用して、潜在的、説明的、結果的表現の意味を完成させるために必要な単語を示します。DATIVE格(与格)は、間接目的語を示します。間接目的語とは、直接目的語を受ける対象を指します。英語では多くの場合、前置詞「to」によって間接目的語を示します。たとえば「He gave the ball to Bobby」の場合、「Bobby」が間接目的語となります。つまり、Bobby がボールを受け止める対象です。一方、「Иван дал книгу маше」(イワンがマーシャに本をあげる)というロシア語の例では、「-e」によって「маше」が間接目的語であることを示します。つまり、マーシャが本を与えられる対象です。GENITIVE格(属格)は、所有を示します。ただし、英語では多くの場合、属格ではなく接尾辞「-'s」を使用して所有を示します。接尾辞「-'s」は、句の末尾に付加できます(例: "[The man who ran the bill up]’s wife paid a dear price for his excess.”)。一方、「Где книга Антона?」(アントンの本はどこにある?)というロシア語の例では、「-а」が「Антон-」を属格として示しています。ロシア語では、「several」、「few」といった単語の補語としても属格が使用されます。たとえば、「Зимой здесь мало снега」(冬の間、ここにはほとんど雪が降らない)という例の場合、「снег-」(雪)は「мало」(ほとんど)の補語であるため、「-a」が「снег-」を属格として示しています。この場合、所有は関与していません。INSTRUMENTAL格(具格)は、名詞が行為の手段であるかどうかを示します。「He opened the door with a key」という英語の文は、ロシア語ではたとえば「он открыл дверь ключом」となります。この場合、「ключ」(key)が具格であることを示すために「-om」が付加されています。LOCATIVE格(所格)は、単語が場所を参照するために使用されていることを示します。英語では所格を使用しません。NOMINATIVE格(主格)は、動詞の主語に関連付けられます。英語では、文の主語は格ではなく語順で示されます。「The girl won the race」という文では、「the girl」が主語であり、その後に動詞「won」が続きます。ロシア語では、主語「девушка(the/a girl)が動詞「выиграла」(won)に先行する場合も、動詞の後に続く場合もあります(「девушка выиграла гонку」または「гонку выиграла девушка」)。OBLIQUE格(斜格)は、動詞または前置詞に対する目的語としての、単語の使用を示します。PARTITIVE格(部分詞)は、単語の「部分性」、つまり特定のものを指していないことを示します。たとえば、英語での部分格の例は「three of my friends」です。ロシア語では「трое моих друзей」となります。ここで、「three of」に対応するのは「трое」です(「три друга」と比較してください。「три」は「three」です)。PREPOSITIONAL格(前置格)は、前置詞の目的語を示します。REFLEXIVE_CASE(再帰)は、動詞の主語と同一の目的語を示します。ほとんどの言語は再帰格を使用せず、再帰代名詞(「himself」や「myself」など)を使用しています。RELATIVE_CASE(定語)(中国語)は、動詞または形容詞と名詞を結びつける関係詞節の補部を示します。例: 工作 [的] 地方(英語の「work [] place」、つまり「place [where I] work」)。便宜 的 餐馆(英語の「inexpensive [] restaurants」、つまり「restaurants [that are] inexpensive」)。VOCATIVE格(呼格)は、相手に呼びかけるときに使用する名詞を示します。
-
tense: 動詞の時間における位置を示す文法上の時制を示します。tenseは、動詞と時間との関係も示しているが、位置よりも時間の流れの特性に注目しているaspectとは異なることに注意してください。多くの言語のIMPERFECT(未完了)時制とPLUPERFECT(過去完了)時制は、時制と相の特定の組み合わせを正確に表しています。このフィールドには次の値が含まれることがあります。CONDITIONAL_TENSE(条件文)は形態学用語の「条件法」を一般化した別の用語です(以下のCONDITIONAL_MOODをご覧ください)。FUTURE(未来時制)は、将来行われる行為を示します。英語では、ほとんどの場合、未来形は動詞句に「will」を付加することで示されます。PAST(過去時制)は、過去に行われた行為を示します。PRESENT(現在時制)は、現在行われている行為を示します。IMPERFECT(未完了時制)は、過去に発生したが、その時制の基準時間内には完了しなかった行為を示します。英語では、ほとんどの場合、過去進行形は、「I was walking.」のように、動詞の動名詞形を過去形に付加することで示されます。過去進行形の事象は、過去に発生したが、その過去時制において完了していません。PLUPERFECT(過去完了時制)は、過去に行われ、その時制の基準時間内で完了した行為を示します。たとえば、「I had walked」は過去に発生し、過去の時制の基準時間内に完了しています。
aspect: 動詞の時間の流れを表現する文法上の相を示します。時間内の動詞の位置に注目するtenseとは異なり、aspectは発生した時間の流れの特性に注目します。このフィールドには次の値が含まれることがあります。PERFECTIVE相(完了相)は、事象が過去に完全に発生したか、将来に完全に発生するため、「完了した」事象を示します。IMPERFECTIVE相(未完了相)は、事象の状態が継続しているか、繰り返しているため、完了していない事象を示します。PROGRESSIVE相(進行相)は、継続している事象を示します。通常、進行相は、未完了相(反復も含む)をより一般化した特別な格として扱われます。
mood: 基本的な行為に関する心的態度を表する、動詞の文法上の法を示します。このフィールドには次の値が含まれることがあります。CONDITIONAL_MOOD(条件法)は、条件を伴う行為を示します。英語では、動詞は条件付き形式ではありません。代わりに動詞の不定詞と「would」を組み合わせて条件付き行為を示します。IMPERATIVE(命令法)は、二人称からの命令またはリクエストを示します。INDICATIVE(直接法)は、事実の記述を示します。一般的には「現実法」として知られています。INTERROGATIVE(疑問文)は、疑問を示します。JUSSIVE(命令法)は一人称または三人称からの命令あるいはリクエストを示します。英語には命令法はありませんが、実際に「Let us」で始まる、またはこれを暗示する表現で始まる勧誘文が、この命令法に近い用法です。SUBJUNCTIVE(仮定法)は、ある行為に関する不確実な性質を示し、「非現実」法としても知られています(「現実」直説法とは対照的です)。英語には固有の仮定法はありません。代わりに「want」、「wish」、「hope」などの単語を用いて、仮定法の意味を伝えます。
voice: 行為と主語 / 目的語との関係を表する動詞の文法上の態を示します。このフィールドには次の値が含まれることがあります。ACTIVE態(能動態)は、行為の主語がその行為を行っていることを示します。CAUSATIVE態(受動態)は、行為の影響が主語に及ぶことを示します。英語には、直接使役態はありません。代わりに「Mom made me go to school」のように、動詞「make」を用いて、使役の意味を表します。PASSIVE態(受動態)は、行為の影響が主語に及ぶことを示します。多くの場合、受動態の「主体」は言外か未知です。
reciprocity: 単語(多くは代名詞)が文中の任意の場所の名詞を指していることを意味する相互関係を示します。このフィールドには次の値が含まれることがあります。RECIPROCALは、代名詞が相互代名詞であることを示します。NON_RECIPROCALは、代名詞が相互代名詞ではないことを示します。
proper: 名詞が固有名詞の一部であるかどうかを示します。多くの固有名詞は複数の単語で構成され、この句が固有名詞として検出されると、各トークンも固有名詞として検出されることに注意してください(たとえば、固有名詞「Wrigley Field」の「Wrigley」と「Field」はどちらもその固有属性をPROPERに設定します。このフィールドには次の値が含まれることがあります。PROPERは、トークンが固有名詞の一部であることを示します。NOT_PROPERは、トークンが固有名詞の一部ではないことを示します。
form: 上述の共通形式(tense、mood、personなど)に当てはまらないその他の形態素形式を示します。この形式の多くは、各言語固有のものです。このフィールドには次の値が含まれることがあります。ADNOMIAL(韓国語 / 日本語)は、名詞句を変更する語尾(韓国語)または動詞(日本語)を示します。例: 밥을 먹는 사람 [someone who eats rice]、書く人 [someone who writes]。AUXILIARY(韓国語)は、2 つの隣接する主述部と補助述部を結びつける語尾を示します(例: 밥을 먹게 하다 [make (someone) to eat])。COMPLEMENTIZER(韓国語)は、複数の異なる文節を結びつける語尾を示します(밥을 먹고 물을 마신다 [ (I) eat rice and drink water])。FINAL_ENDING(韓国語 / 日本語)は、文節または文の最後に来る文節または文を確定する語尾を示します。 例: 밥을 먹는다 [(I) eat rice]、手紙を書く [write a letter]。GERUND(韓国語 / 日本語)は、動詞または形容詞を正規化する(韓国語の「밥 먹기」[eating rice])語尾や、動詞をさまざまな助動詞と結びつける(日本語の「書きたい」[want to write])語尾を示します。REALIS(日本語)は、「書けば」[if (I) write] のように、接続助詞「ば」を付けて、条件形または仮定形を示します。IRREALIS(日本語)は、動詞に、否定動詞(書かない [do not write])、受動動詞(書かれる [to be written])、使役補助動詞(書かせる [make (someone) write])を結びつけることを示します。ORDER(日本語)は、命令法に似た命令動詞を示します(例: 書け! [write!])。SPECIFIC(日本語)は、上記の 6 つの分野に含まれない特殊な形式を示します。この形式の代表的なものには、接尾辞を追加することで形容詞から名詞を派生させたものがあります(例: かわいさ [cuteness])。SHORT(ロシア語)は、短形式の形容詞または分詞を示します。LONG(ロシア語)は、上記のSHORT形式とは異なり、長形式の形容詞または分詞を示します。
Natural Language API は(句単位ではなく)トークン単位で形態論情報を提供することに注意してください。単語境界をまたぐ形態論構造はサポートされないことがあります。
依存関係ツリー
構文リクエスト内では、品詞と形態論情報はレスポンスの partOfSpeech フィールドで返されます。
構文解析のために Natural Language API に指定されたテキスト内の各文について、API により、その文の構文構造を示す依存関係ツリーが作成されます。構文情報はレスポンスの dependencyEdge フィールドで返されます。
次の図は、ジョン F. ケネディの大統領就任演説の 1 文の依存関係ツリーを示しています。
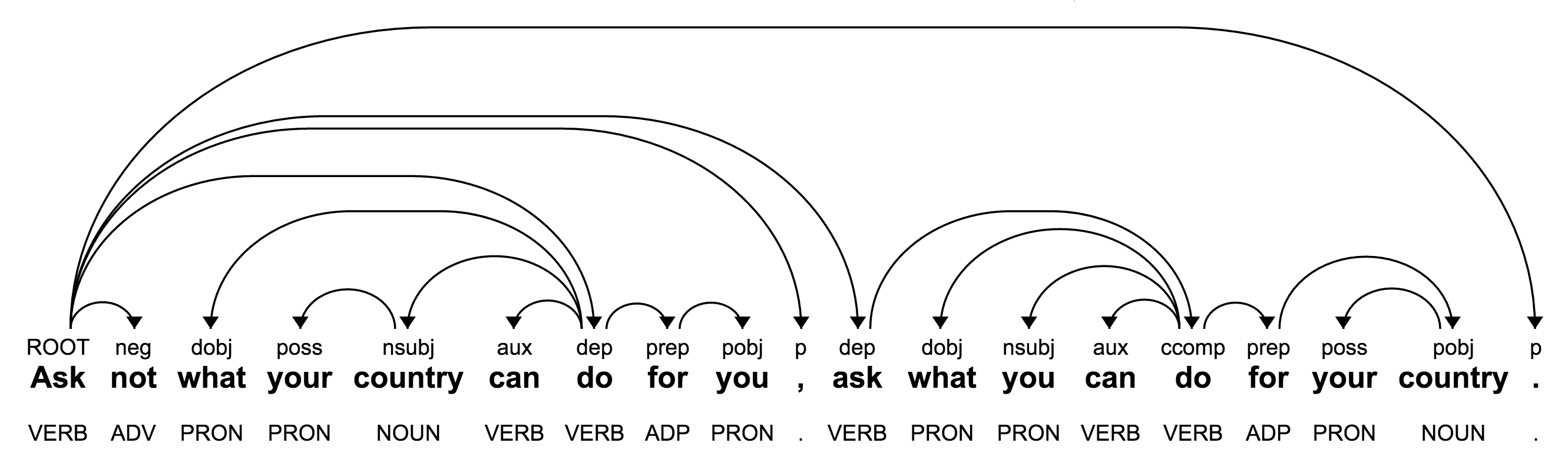
各トークンについて、dependencyEdge 要素は、他のどのトークンを修飾するかを(headTokenIndex フィールドで)識別し、このトークンとそのヘッドトークン間の構文関係を(label フィールドで)識別します。たとえば、初出の「your country」という句のトークン「your」に対する dependencyEdge 要素は次のようになります。
"dependencyEdge": {
"headTokenIndex": 4,
"label": "POSS"
},
この要素は、「your」が 5 つ目のトークンを修飾すること(headTokenIndex では 0 から始まるオフセットが使用されます)、およびこれが所有格の修飾子であることを示します。
この依存関係ツリーには ROOT 要素("label": ROOT)が含まれています。これは、この文の本動詞に相当します。上記の例では、文の最初の単語が ROOT 要素になります("headTokenIndex": 0)。ROOT 語である「Ask」の headTokenIndex は自身のインデックスになります。
解析ツリーは文の境界を越えませんが、Natural Language API により、0 から始まるオフセット値を使用して、テキスト全体で文やトークンにインデックスが付けられます。
Natural Language API により、サポートされている言語全体に適用される共通の依存関係セットを使用して、構文関係にラベルが付けられます。 ラベルについては以下で説明します。テキスト例では、「Head」とラベルは適用されるトークンの下に表示されています。
| ラベル | 説明 |
|---|---|
UNKNOWN |
不明な関係 |
ABBREV |
ヘッドトークンの略語。
British Broadcasting Company (BBC)
Head ABBREV
|
ACOMP |
補語として機能する形容詞句(動詞の目的語など)。この関係には特に、形容詞述語を伴う「be」連結詞構文が含まれます。
The book looks heavy.
Head ACOMP
The book is heavy.
Head ACOMP
She arrived sad.
Head ACOMP
I consider John intelligent.
Head ACOMP
|
ADVCL |
時間、結果、条件、目的を示す節など、動詞を修飾する副詞節。
The accident happened as the night was falling.
Head ADVCL
If you know who did it, you should tell the teacher.
ADVCL Head
He talked to him in order to secure the account.
Head ADVCL
|
ADVPHMOD |
副詞句の修飾子(日本語) |
ADVMOD |
(節でない)副詞や単語の意味を修飾する働きをする副詞句。Genetically modified food. ADVMOD Head less often ADVMOD Head About 200 people came to the party. ADVMOD Head |
AMOD |
名詞句の意味を修飾する働きをする形容詞句。
Sam eats red meat.
AMOD Head
Sam took out a 3 million dollar loan.
AMOD Head
|
APPOS |
別の名詞句のすぐ右側にある名詞句。2 番目の句が最初の句を定義または修飾する働きをします。Sam, my brother, arrived. Head APPOS Bill (John’s cousin) Head APPOS |
ATTR |
連結動詞で始まる名詞句。形容詞ではなく名詞句に属する点で、「ATTR」は「ACOMP」とは異なることに注意してください。
He is a doctor.
Head ATTR
She resembles her mother.
Head ATTR
What is your name?
ATTR Head NSUBJ
What breed is the dog?
ATTR Head NSUBJ
I consider John an intelligent person. Head ATTR |
AUX |
法助動詞や迂言形における「be」、「do」、「have」の形式などの非本動詞。受動態構文における助動詞としての「be」の使用は除きます。
Reagan has died.
AUX Head
He should leave.
AUX Head
|
AUXPASS |
受動態の節の非本動詞。
Kennedy has been killed.
AUX AUXPASS Head
Kennedy was/got killed.
AUXPASS Head
|
CC |
接続詞の要素と等位接続詞の間の関係。接続詞のいずれかの等位項(通常は最初の項)は、接続詞の Head として扱われます。
Bill is big and honest.
Head CC
They either ski or snowboard.
Head CC
Bill went to Florida but Jane traveled to Alaska.
Head CC
|
CCOMP |
動詞や形容詞の目的語のような働きをする内部的な主語を含む従属節。
He says that you like to swim.
Head CCOMP
I am certain that he did it.
Head CCOMP
I admire the fact that you are honest.
Head CCOMP
|
CONJ |
「and」や「or」などの等位接続詞によって接続された 2 つの要素間の関係。この関係の Head は最初の等位項であり、その他の接続詞の場合は「CONJ」関係によって決まります。
Bill is big and honest.
Head CONJ
They either ski or snowboard.
Head CONJ
We have apples, pears, oranges, and bananas.
DOBJ CONJ CONJ CONJ
|
CSUBJ |
節の構文上の主語。つまり、主語自体が節です(下の例では「what she said」)。
What she said makes sense.
CSUBJ Head
|
CSUBJPASS |
受動態の節の構文上の主語。
That she lied was suspected by everyone.
CSUBJ Head
|
DEP |
2 つの単語間について、この体系では正確に依存関係を判別できない場合に使用します。
Then, as if to show that he could, . . .
DEP Head
travel agency florence kentucky
Head DEP
|
DET |
名詞句の Head とその限定詞の間の関係。The man is here. DET Head Which book do you prefer? DET Head |
DISCOURSE |
感情を表す方法以外では文の構造に明確に関連付けられない、間投詞やその他の談話要素。たとえば、「oh」、「uh-huh」、「Welcome」などの間投詞、「um」、「ah」などのフィラー、「well」、「like」、「actually」などの談話標識(「you know」は除く)があります。
Iguazu is in Argentina :)
Head DISCOURSE
|
DOBJ |
動詞の目的語である名詞句([accusative](https://en.wikipedia.org/wiki/Accusative_case))。
She gave me a raise.
Head DOBJ
They win the lottery.
Head DOBJ
|
EXPL |
冗語的な名詞句。英語では、場合に応じて「it」と「there」が使用されます。「there」は存在を表す場合に使用され、「it」は外置変形構文で使用されます。虚辞名詞句または冗語的な名詞句では、名詞句が述語のセマンティックな役割を果たしません。虚辞を含む言語では、主語や直接目的語の位置に置かれる場合があります。There is a ghost in the room. EXPL Head NSUBJ It is clear that we should decline. EXPL Head |
GOESWITH |
テキストで分割されている 1 つの単語の 2 つの部分を関連付けます。 |
IOBJ |
動詞の関節目的語である名詞句([dative](https://en.wikipedia.org/wiki/Dative_case))。
She gave me a present.
Head IOBJ DOBJ
|
MARK |
「that」や「whether」など、制限用法または非制限用法の従属節を導入する単語。Head は従属節の Head になります。
Forces engaged in fighting after insurgents attacked.
MARK Head
He says that you like to swim.
MARK Head
|
MWE |
(「NN」と並んで)複合を表す 2 つの関係の 1 つ。単一の機能語のような働きをする、複数の機能語で構成された文法上の特定の定型表現に使用されます。複単語表現は、Head を先頭にした横並びの構造でラベル付けされ、表現内のすべての単語は「MWE」ラベルを使用して最初の単語を修飾します。
I like dogs as well as cats.
Head MWE MWE
He cried because of you.
Head MWE
|
MWV |
動詞性の複単語表現。 |
NEG |
否定語とその単語が修飾する単語の間の関係。
Bill is not a scientist.
Head NEG
Bill is no scientist.
NEG Head
|
NN |
Head 名詞を修飾する働きをするすべての名詞。phone book NN Head oil price futures NN NN Head |
NPADVMOD |
副詞の修飾子として使用される名詞句。
The director is 65 years old.
NPADVMOD Head
Six feet long
NPADVMOD Head
Shares eased a fraction.
HEAD NPADVMOD
The silence is itself significant.
NPADVMOD Head
90% of Australians like him, the most of any country.
Head NPADVMOD
|
NSUBJ |
節の構文上の主語である名詞句。
Clinton defeated Dole.
NSUBJ Head
The baby is cute
NSUBJ Head
|
NSUBJPASS |
受動態の節の構文上の主語である名詞句。Dole was defeated by Clinton. NSUBJPASS Head |
NUM |
数量で名詞句の意味を修飾する働きをするすべての数詞句。
Sam ate three sheep.
NUM Head
|
NUMBER |
数詞句の部分。
I have four thousand sheep.
NUMBER Head
|
P |
節内のすべての句読点。 |
PARATAXIS |
並列関係(「並べて置く」を意味するギリシャ語が語源)とは、単語(通常は文の主文述語)と、Head 語との明確な等位関係や従属関係を持たず関係についての根拠なく配置されたその他の要素の間の関係のことです。並列は談話のようなもので、等位と同等です。
Let's face it we're annoyed.
Head PARATAXIS
The guy, John said, left early in the morning.
PARATAXIS Head
|
PARTMOD |
分詞の修飾子 |
PCOMP |
前置詞の補語が節や前置詞句(場合によっては副詞句)であるときに使用されます。
We have no information on whether users are at risk.
Head PCOMP
They heard about you missing classes.
Head PCOMP
|
POBJ |
前置詞や副詞「here」と「there」の後に続く名詞句の Head。
I sat on the chair.
Head POBJ
What does CPR stand for?
POBJ Head
|
POSS |
所有限定詞または([genitive](https://en.wikipedia.org/wiki/Genitive_case))修飾子。their offices POSS Head Bill’s clothes. POSS Head |
POSTNEG |
動詞の後の否定助詞 |
PRECOMP |
叙述的な補語 |
PRECONJ |
「either」、「both」、「neither」など、接続詞をひとくくりにして先頭に配置される単語。Both the boys and the girls are here. PRECONJ Head |
PREDET |
名詞句の限定詞に先行してその意味を修飾する単語。All the boys are here. PREDET Head |
PREF |
接頭辞 |
PREP |
動詞、形容詞、名詞、さらには別の前置詞の意味を修飾する働きをするすべての前置詞句。
I saw a cat in a hat.
Head PREP
I saw a cat with a telescope.
Head PREP
He is responsible for meals.
Head PREP
|
PRONL |
動詞と動詞形態素の間の関係(フランス語) |
PRT |
動詞の不変化詞。
They shut down the station.
Head PRT
He would not put up with it.
Head PRT
|
PS |
関連マーカーまたは所有マーカー |
QUANTMOD |
数量詞句の修飾子 |
RCMOD |
名詞から関係節を率いる動詞への関連付け。
I saw the man you love.
Head RCMOD
the book that you bought
Head RCMOD
Bell, a company which is based in LA, makes and distributes computer products.
Head RCMOD
|
RCMODREL |
関係節内の補文標識(中国語) |
RDROP |
先行する述語のない省略(日本語) |
REF |
指示物(ヒンディー語) |
REMNANT |
省略に使用されます。
John won bronze, Mary silver, and Sandy gold.
Head REMNANT REMNANT
|
REPARANDUM |
音声修復で無効化される非流暢性を示します。Go to the righ- to the left. REPARANDUM Head |
ROOT |
文の語根。多くの場合、これは動詞です。 |
SNUM |
数字の単位を指定する接尾辞(日本語) |
SUFF |
サフィックス |
TMOD |
時間を指定することで構成要素の意味を修飾する働きをする、最小限の名詞句構成要素。「TMOD」により時点と期間が取得されます。繰り返しは取得されません(「NPADVMOD」に該当する「two times」など)。
Last night, I swam in the pool.
TMOD Head
|
TOPIC |
トピック マーカー(中国語) |
VMOD |
動詞の不定形で始まる節。
Berries gathered on this side of the mountain are sweeter.
Head VMOD
He sat in the armchair reading the morning newspaper.
Head VMOD
I have nothing to say to them.
Head VMOD
|
VOCATIVE |
テキスト(通常はメールやニュースグループの投稿)で呼ばれた対話参加者をマーク付けします。Anna, can you bring a tent? VOCATIVE Head |
XCOMP |
独自の主語を持たない節の補語。その参照は外部の主語によって決まります。
He says that you like to swim.
Head XCOMP
I am ready to leave.
Head XCOMP
|
SUFFIX |
名前の接尾辞 |
TITLE |
名前に付く称号 |
AUXCAUS |
使役の助動詞(日本語) |
AUXVV |
補助的な助動詞(日本語) |
DTMOD |
連帯詞(名詞の前に置く修飾子) |
FOREIGN |
外来語 |
KW |
キーワード |
LIST |
比較可能なアイテムの一連のリスト |
NOMC |
名詞化した節 |
NOMCSUBJ |
名詞化した節の主語 |
NOMCSUBJPASS |
名詞化した節の受動態 |
NUMC |
数字の修飾子の複合語(日本語) |
COP |
連結詞(スペイン語) |
DISLOCATED |
位置が変化した関係(先頭に置かれた / 主題化された要素に関する) |
ASP |
相マーカー |
GMOD |
属格修飾子 |
GOBJ |
属格目的語 |
INFMOD |
不定詞の修飾子 |
MES |
測定 |
NCOMP |
名詞補部 |
依存関係ツリーの詳細については、Universal Dependency Treebank プロジェクトをご覧ください。 また、Universal Dependency Annotation for Multilingual Processing(英語)には、このような依存関係ツリーを解釈するための方法に関する背景情報が含まれています。
構文解析のレスポンスの解析
次の疑似コードは、構文解析のレスポンスに対して反復オペレーションを行う際に使用する一般的なパターンを示しています。
index = 0
for sentence in self.sentences:
content = sentence['text']['content']
sentence_begin = sentence['text']['beginOffset']
sentence_end = sentence_begin + len(content) - 1
while index < len(self.tokens) and self.tokens[index]['text']['beginOffset'] <= sentence_end:
# This token is in this sentence
index += 1