如需训练您的自定义模型,请提供您要分析的文档类型的代表性样本,并以您希望 AutoML Natural Language 为类似文档添加标签的方式添加标签。训练数据的质量极大影响着所创建的模型的效果,进而影响该模型返回的预测结果的质量。
收集训练文档并为其添加标签
第一步是收集反映您希望自定义模型处理的文档范围的各种训练文档。根据您训练模型的目的是为了进行分类、实体提取还是情感分析,训练文档的准备步骤会有所不同。
实体提取
如需训练实体提取模型,您需要提供要分析的内容类型的代表性样本,并使用标签进行注释,这些标签用于标识您希望 AutoML Natural Language 识别的实体类型。
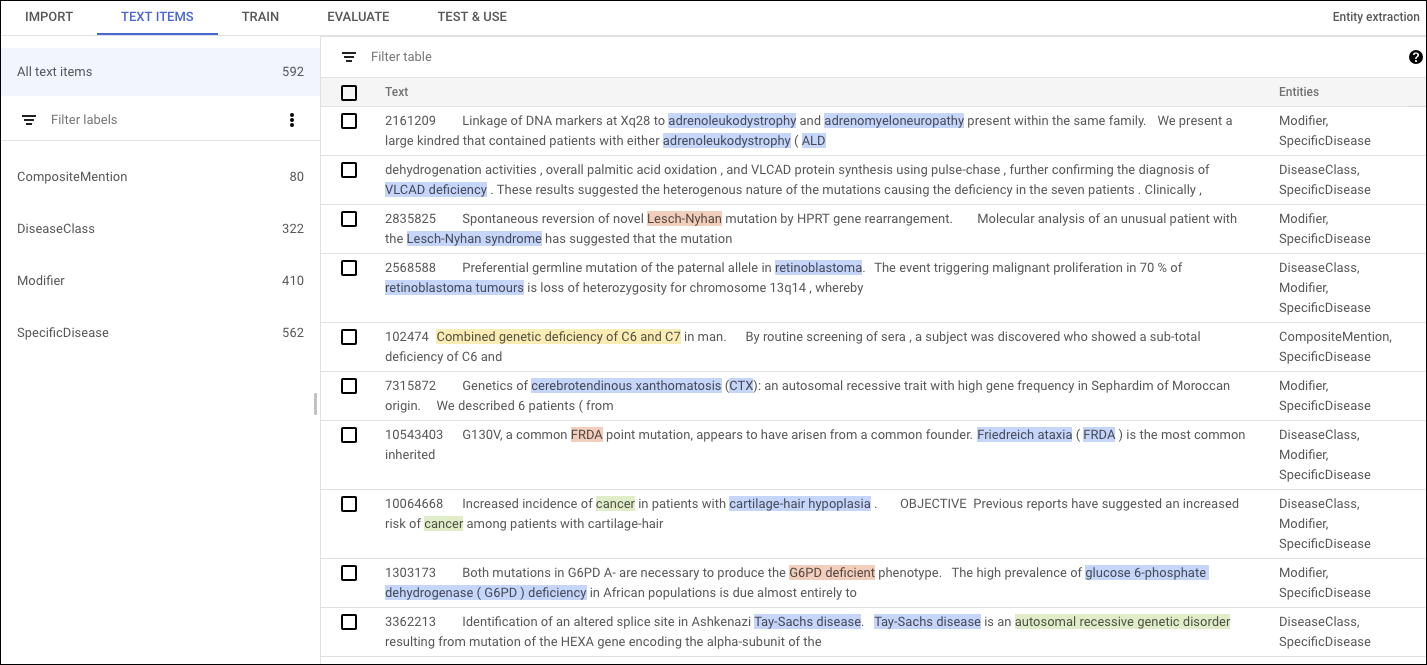
您可以提供 50 个到 10 万个文档来用于训练自定义模型。 您可以使用 1 个到 100 个唯一性标签来为您希望模型学习提取的实体添加注释。每条注解都是一段文本和一个关联的标签。 标签名称可以包含 2 个到 30 个字符,并且可用于为 1 个到 10 个字词添加注释。我们建议您在训练数据集中至少使用每个标签 200 次。
如果您要为结构化或半结构化文档类型(例如账单或合同)添加注解,则 AutoML Natural Language 可以将页面上的注解位置视为影响其正确标签的一个因素。例如,房地产合同同时约定了交房日期和过户日期,AutoML Natural Language 可以学习根据注解的空间位置来区分这些实体。
格式化训练文档
您可以采用包含示例文档的 JSONL 文件形式将训练数据上传到 AutoML Natural Language。该文件中的每一行都是一个训练文档,以两种形式之一指定:
- 文档的完整内容,长度为 10 个到 10000 个字节(采用 UTF-8 编码)
- 来自与您的项目相关联的 Cloud Storage 存储桶中的 PDF 或 TIFF 文件的 URI
AutoML Natural Language 仅对 PDF 格式的训练文档考虑空间位置。
您可以通过以下三种方式为文本文档添加注释:
- 在上传之前直接为 JSONL 文件添加注释
- 上传未注释的文档后,在 AutoML Natural Language 界面中添加注释
- 使用 AI Platform 数据标签服务请求人工标签添加者添加标签
您可以结合使用前两种方式,只需上传已加标签的 JSONL 文件并在界面中对其进行修改即可。
您只能使用 AutoML Natural Language 界面为 PDF 文件添加注释。
JSONL 文档
为了帮助您创建 JSONL 训练文件,AutoML Natural Language 提供了一个 Python 脚本,用于将纯文本文件转换为格式正确的 JSONL 文件。如需了解详情,请参阅该脚本中的注释。
JSONL 文件中的每个文档都具有以下某种格式:
每个文档在 JSONL 文件中都必须单独占据一行。为了方便阅读,以下示例使用了换行符;在 JSONL 文件中,您必须移除这些换行符。如需了解详情,请参阅 http://jsonlines.org/。
对于未注释的文档:
{
"text_snippet":
{"content": string}
}
对于带注释的文档:
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
...
],
"text_snippet":
{"content": string}
}
每个 text_extraction 元素标识 text_snippet.content 中的一条注解。它通过指定从 text_snippet.content 的开始位置到带注释文本的开头 (start_offset) 和结尾 (end_offset) 的字符数来指示该文本的位置;display_name 是实体的标签。
start_offset 和 end_offset 都是字符偏移量,而不是字节偏移量。end_offset 处的字符不包含在文本段中。如需了解详情,请参阅 TextSegment。text_extraction 元素是可选的;如果您打算使用 AutoML Natural Language 界面为文档添加注释,则可以省略这些元素。每条注解最多可以涵盖十个词法单元(单词)。它们不能重叠;某条注解的 start_offset 不能位于同一文档中其他注解的 start_offset 和 end_offset 之间。
例如,以下示例训练文档标识了 NCBI 语料库的摘要中提到的特定疾病。
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": 67,
"start_offset": 62
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 158,
"start_offset": 141
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 330,
"start_offset": 290
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 337,
"start_offset": 332
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 627,
"start_offset": 610
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 754,
"start_offset": 749
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 875,
"start_offset": 865
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 968,
"start_offset": 951
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1553,
"start_offset": 1548
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1652,
"start_offset": 1606
}
},
"display_name": "CompositeMention"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1833,
"start_offset": 1826
}
},
"display_name": "DiseaseClass"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1860,
"start_offset": 1843
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1930,
"start_offset": 1913
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2129,
"start_offset": 2111
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2188,
"start_offset": 2160
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2260,
"start_offset": 2243
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2356,
"start_offset": 2339
}
},
"display_name": "Modifier"
}
],
"text_snippet": {
"content": "10051005\tA common MSH2 mutation in English and North American HNPCC families:
origin, phenotypic expression, and sex specific differences in colorectal cancer .\tThe
frequency , origin , and phenotypic expression of a germline MSH2 gene mutation previously
identified in seven kindreds with hereditary non-polyposis cancer syndrome (HNPCC) was
investigated . The mutation ( A-- > T at nt943 + 3 ) disrupts the 3 splice site of exon 5
leading to the deletion of this exon from MSH2 mRNA and represents the only frequent MSH2
mutation so far reported . Although this mutation was initially detected in four of 33
colorectal cancer families analysed from eastern England , more extensive analysis has
reduced the frequency to four of 52 ( 8 % ) English HNPCC kindreds analysed . In contrast ,
the MSH2 mutation was identified in 10 of 20 ( 50 % ) separately identified colorectal
families from Newfoundland . To investigate the origin of this mutation in colorectal cancer
families from England ( n = 4 ) , Newfoundland ( n = 10 ) , and the United States ( n = 3 ) ,
haplotype analysis using microsatellite markers linked to MSH2 was performed . Within the
English and US families there was little evidence for a recent common origin of the MSH2
splice site mutation in most families . In contrast , a common haplotype was identified
at the two flanking markers ( CA5 and D2S288 ) in eight of the Newfoundland families .
These findings suggested a founder effect within Newfoundland similar to that reported by
others for two MLH1 mutations in Finnish HNPCC families . We calculated age related risks
of all , colorectal , endometrial , and ovarian cancers in nt943 + 3 A-- > T MSH2 mutation
carriers ( n = 76 ) for all patients and for men and women separately . For both sexes combined ,
the penetrances at age 60 years for all cancers and for colorectal cancer were 0 . 86 and 0 . 57 ,
respectively . The risk of colorectal cancer was significantly higher ( p < 0.01 ) in males
than females ( 0 . 63 v 0 . 30 and 0 . 84 v 0 . 44 at ages 50 and 60 years , respectively ) .
For females there was a high risk of endometrial cancer ( 0 . 5 at age 60 years ) and premenopausal
ovarian cancer ( 0 . 2 at 50 years ) . These intersex differences in colorectal cancer risks
have implications for screening programmes and for attempts to identify colorectal cancer
susceptibility modifiers .\n "
}
}
JSONL 文件可以包含多个具有此结构的训练文档(该文件每行一个文档)。
PDF 或 TIFF 文档
如需将 PDF 或 TIFF 文件作为文档上传,请将文件路径包装在 JSONL document元素内:
每个文档在 JSONL 文件中都必须单独占据一行。为了方便阅读,以下示例使用了换行符;在 JSONL 文件中,您必须移除这些换行符。如需了解详情,请参阅 http://jsonlines.org/。
{
"document": {
"input_config": {
"gcs_source": {
"input_uris": [ "gs://cloud-ml-data/NL-entity/sample.pdf" ]
}
}
}
}
input_uris 元素的值是与项目相关联的 Cloud Storage 存储桶中 PDF 或 TIFF 文件的路径。PDF 或 TIFF 文件的大小上限为 2MB。
导入训练文档
您可以使用 CSV 文件将训练数据导入到 AutoML Natural Language 中,该 CSV 文件列出了文档,并且可能包含文档的类别标签或情感值。AutoML Natural Language 会根据列出的文档创建数据集。
训练与评估数据
AutoML Natural Language 会将您的训练文档分为训练模型的三个集合:训练集、验证集、测试集。
AutoML Natural Language 使用训练集构建模型。该模型在搜寻训练数据中的模式时会尝试多种算法和参数。在模型识别出模式后,它会使用验证集来测试算法和模式。AutoML Natural Language 会从训练阶段识别出的算法和模式中选出表现最佳的。
在识别出表现最佳的算法和模式之后,AutoML Natural Language 会将其应用到测试集以测试错误率、质量和准确度。
默认情况下,AutoML Natural Language 会将您的训练数据随机分为三个集合:
- 80% 的文档用于训练
- 10% 的文档用于验证(超参数调整和/或决定何时停止训练)
- 10% 的文档预留用于测试(在训练期间不使用)
如果您想指定训练数据中的每个文档应属于哪个集合,可以在 CSV 文件中明确地将文档分配到相应集合,具体如下一部分中所述。
创建导入 CSV 文件
收集完所有训练文档后,请创建一个完整列出这些文档的 CSV 文件。该 CSV 文件可以采用任何文件名,但必须使用 UTF-8 编码,并且文件名必须以 .csv 扩展名结尾。它必须存储在与您的项目关联的 Cloud Storage 存储桶中。
在该 CSV 文件中,每个训练文档单独占据一行,每行包含以下几列:
将此行中的内容分配到哪个集合。此列是可选列,可使用以下值之一:
TRAIN- 使用 document 训练模型。VALIDATION- 使用 document 验证训练期间模型返回的结果。TEST- 使用 document 验证模型训练完成后模型的结果。
如果您在此列中添加值以指定集合,我们建议您为每个类别至少标识 5% 的数据。如果用于训练、验证或测试的数据不足 5%,将会产生意外结果和无效模型。
如果您没有在此列中添加值,请在每一行开头输入一个英文逗号,以表示第一列为空。AutoML Natural Language 会自动将您的文档分为三个集合,它在训练、验证、测试中使用的数据比例分别约为 80%、10%、10%(用于验证和测试的上限为 10000 对)。
要分类的内容。此列包含文档的 Cloud Storage URI。Cloud Storage URI 区分大小写。
对于分类和情感分析,文档可以是文本文件,PDF 文件,TIFF 文件或 ZIP 文件。对于实体提取,文档是 JSONL 文件。
对于分类和情感分析,此列中的值可以是引用的内嵌文本,而不是 Cloud Storage URI。
对于分类数据集,您可以选择性地添加以英文逗号分隔的标签列表,用于标识文档的分类方式。标签必须以字母开头,且只能包含字母、数字和下划线。每个文档最多可包含 20 个标签。
对于情感分析数据集,您可以选择性地添加一个指示内容的情感值的整数。情感值的范围从 0(非常消极)到最大值 10(非常积极)。
例如,用于多标签分类数据集的 CSV 文件可能包含以下内容:
TRAIN, gs://my-project-lcm/training-data/file1.txt,Sports,Basketball VALIDATION, gs://my-project-lcm/training-data/ubuntu.zip,Computers,Software,Operating_Systems,Linux,Ubuntu TRAIN, gs://news/documents/file2.txt,Sports,Baseball TEST, "Miles Davis was an American jazz trumpeter, bandleader, and composer.",Arts_Entertainment,Music,Jazz TRAIN,gs://my-project-lcm/training-data/astros.txt,Sports,Baseball VALIDATION,gs://my-project-lcm/training-data/mariners.txt,Sports,Baseball TEST,gs://my-project-lcm/training-data/cubs.txt,Sports,Baseball
常见的 .csv 错误
- 在标签中使用 Unicode 字符。例如,不支持日语字符。
- 在标签中使用空格和非字母数字字符。
- 空行。
- 空列(行中带有两个连续英文逗号)。
- 包含逗号的嵌入文本两边缺少引号。
- Cloud Storage 路径的大小写错误。
- 文档的访问权限控制配置错误。您的服务账号应具有读取或更高权限,或者文件必须可供公开读取。
- 引用非文本文件(如 JPEG 文件)。同样,如果文件并非文本文件,但重命名为具有文本扩展名,则将导致错误。
- 文档的 URI 指向不属于当前项目的存储桶。 只能访问项目存储桶中的文件。
- 文件并非 CSV 格式。
创建导入 ZIP 文件
对于分类数据集,您可以使用 ZIP 文件导入训练文档。 在 ZIP 文件中,请为每个标签或情感值创建一个文件夹,然后将每个文档保存在与要应用到该文档的标签或情感值相对应的文件夹中。例如,用于对商业信件进行分类的模型的 ZIP 文件可能具有以下结构:
correspondence.zip
transactional
letter1.pdf
letter2.pdf
letter5.pdf
persuasive
letter3.pdf
letter7.pdf
letter8.pdf
informational
letter6.pdf
instructional
letter4.pdf
letter9.pdf
AutoML Natural Language 会将文件夹名称作为标签应用到文件夹中的文档。 对于情感分析数据集,文件夹名称为情感值:
sentiment.zip
0
document4.txt
1
document3.txt
document1.txt
document5.txt
2
document2.txt
document6.txt
document8.txt
document9.txt
3
document7.txt
后续步骤
- 导入数据以创建数据集。