本頁面說明標準級 Memorystore for Redis 執行個體的高可用性 (HA)。
總覽
標準級會將資料複製到一或多個副本,並提供快速自動容錯移轉至副本的功能,保護 Redis 執行個體免於常見故障。
標準級會佈建一個主要執行個體和一或多個副本。如果標準級執行個體已停用 readReplicaMode,則只有一個非唯讀備用資源。啟用 readReplicaMode 的標準級執行個體會有一到五個唯讀備用資源。如要判斷是否已啟用 readReplicaMode,請參閱查看執行個體的唯讀備用資源資訊。
Memorystore for Redis 會將 Redis 主要執行個體複製到一或多個副本,藉此提供高可用性。主要執行個體上的資料變更會使用 Redis 非同步複製通訊協定複製到副本。由於複製作業具有非同步特性,備用資源可能會落後主要資源,具體情況取決於主要資源的寫入率。
如果主要執行個體發生故障,執行個體會自動容錯移轉至副本。如果執行個體設定了多個副本,執行個體會自動容錯移轉至健康狀態良好且複製延遲時間最短的副本。
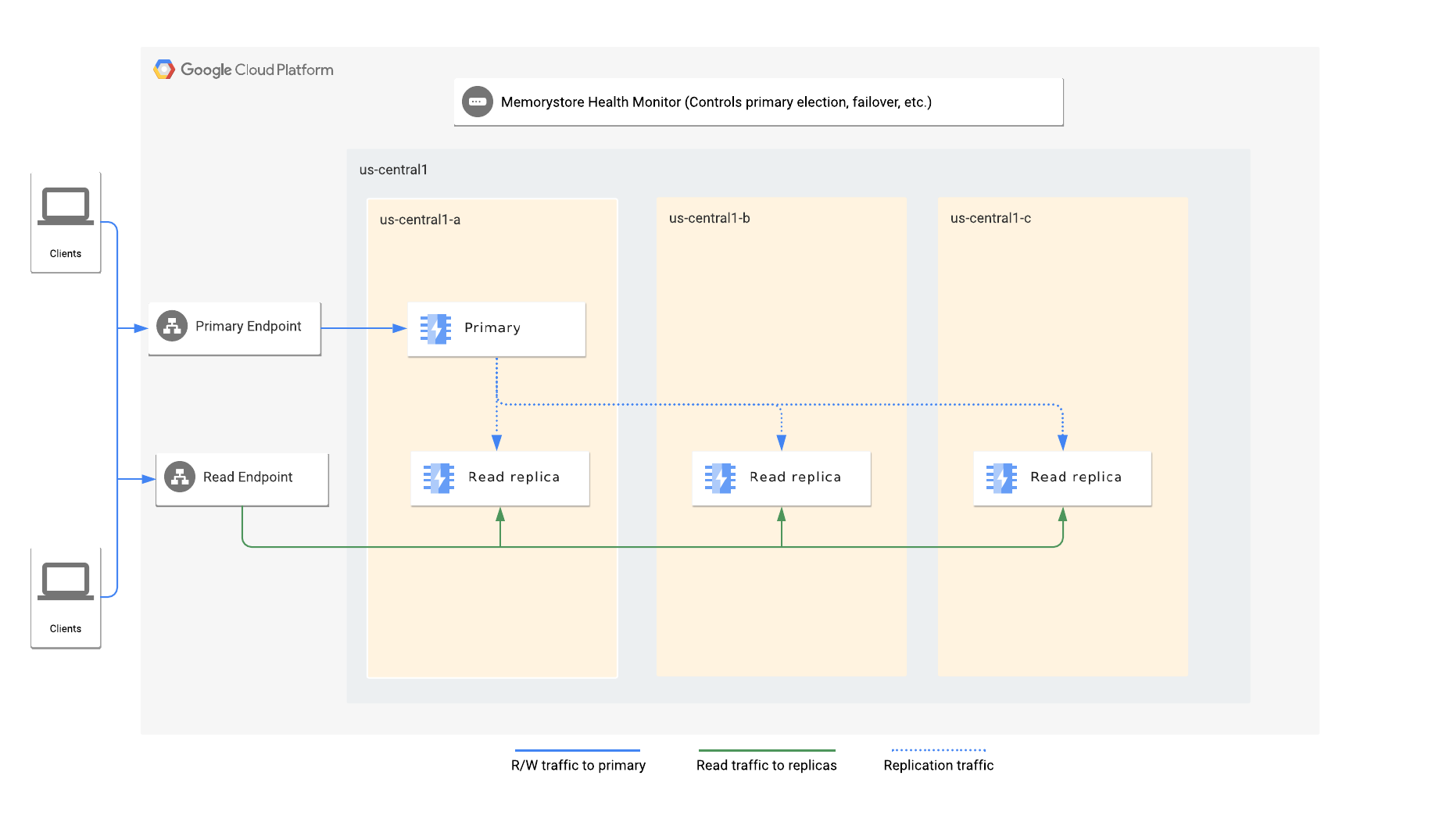
如果執行個體只設定一個非讀取副本,所有應用程式連線都會導向主要端點。如果執行個體是使用唯讀備用資源設定,應用程式也可以利用讀取端點,將讀取查詢分散到所有備用資源。
觸發容錯移轉時
當 Redis 主要執行個體發生故障時,就會發生容錯移轉。容錯移轉期間,主要和讀取端點會自動重新導向至新的主要和備用資源。系統會捨棄與主要端點的所有連線,以及與升級唯讀副本的唯讀端點連線。
容錯移轉對應用程式的影響
當主要節點容錯移轉到備用資源時,所有連到執行個體主要端點的現有連線都會遭到捨棄。自動修復期間,執行個體平均會停機 30 秒,維護事件則為 15 秒。重新連線時,系統會使用相同的連線字串或 IP 位址,將您的應用程式自動重新導向到新的主要節點。容錯移轉後,您不需要更新應用程式。
在容錯移轉期間,如果連線到讀取端點,系統會捨棄連線到升級為主要執行個體的備用資源。容錯移轉期間,系統會繼續提供其他副本的連線。容錯移轉完成且新副本可用後,連線會重新導向至新副本。
容錯移轉後重試執行個體連線
發生容錯移轉時,來自主要端點的所有連線都會遭到捨棄,且視備用資源數量而定,部分讀取連線會終止。
由於連線中斷,應用程式需要重試才能重新建立連線。重試邏輯應使用指數輪詢,確保不會因重試要求過多而導致執行個體過載。除了加入重試邏輯,您也應透過手動容錯移轉進行測試,瞭解容錯移轉對應用程式的影響。
大多數 Redis 用戶端都內建重試功能,如果因容錯移轉而導致連線中斷,您應善用這項功能。
發生容錯移轉的情況如下:
如果您在應用程式中實作重試邏輯,處理因容錯移轉而中斷連線的問題,執行個體就不會受到顯著的效能影響。通常,只有在沒有重試邏輯的情況下才會發生問題。
如何查看高可用性的狀態
您可以使用 Cloud Monitoring 查看 Redis 執行個體的高可用性指標。如要瞭解 Cloud Monitoring 為 Memorystore for Redis 提供的指標,請參閱「監控 Redis 執行個體」和「監控指標」。
詳情請參閱 Cloud Monitoring 說明文件。
如要查看 Redis 提供的原生複製狀態,您可以向 Memorystore for Redis 執行個體發出 Redis INFO 指令。