En esta página se describe la alta disponibilidad de las instancias de Memorystore para Redis del nivel estándar.
Información general
El nivel estándar protege las instancias de Redis frente a los fallos habituales replicando los datos en una o varias réplicas y proporcionando una conmutación por error automática rápida a una réplica.
El nivel Estándar se aprovisiona con una réplica principal y una o varias réplicas. Una instancia de nivel estándar que tiene la opción readReplicaMode inhabilitada tiene una sola réplica que no es de lectura. Una instancia de nivel estándar que tenga la opción readReplicaMode habilitada tiene entre una y cinco réplicas de lectura. Para determinar si la readReplicaMode está habilitada, consulta Ver información de réplica de lectura.
Memorystore para Redis ofrece alta disponibilidad replicando una instancia principal de Redis en una o varias réplicas. Los cambios que se hagan en los datos de la instancia principal se copiarán en las réplicas mediante el protocolo de replicación asíncrona de Redis. Debido a la naturaleza asíncrona de la replicación, las réplicas pueden ir con retraso con respecto a la principal en función de la velocidad de escritura de la principal.
Si falla la instancia principal, se conmutará por error automáticamente a una réplica. En las instancias configuradas con más de una réplica, se produce un failover automático a una réplica con el menor retraso de replicación que esté en buen estado.
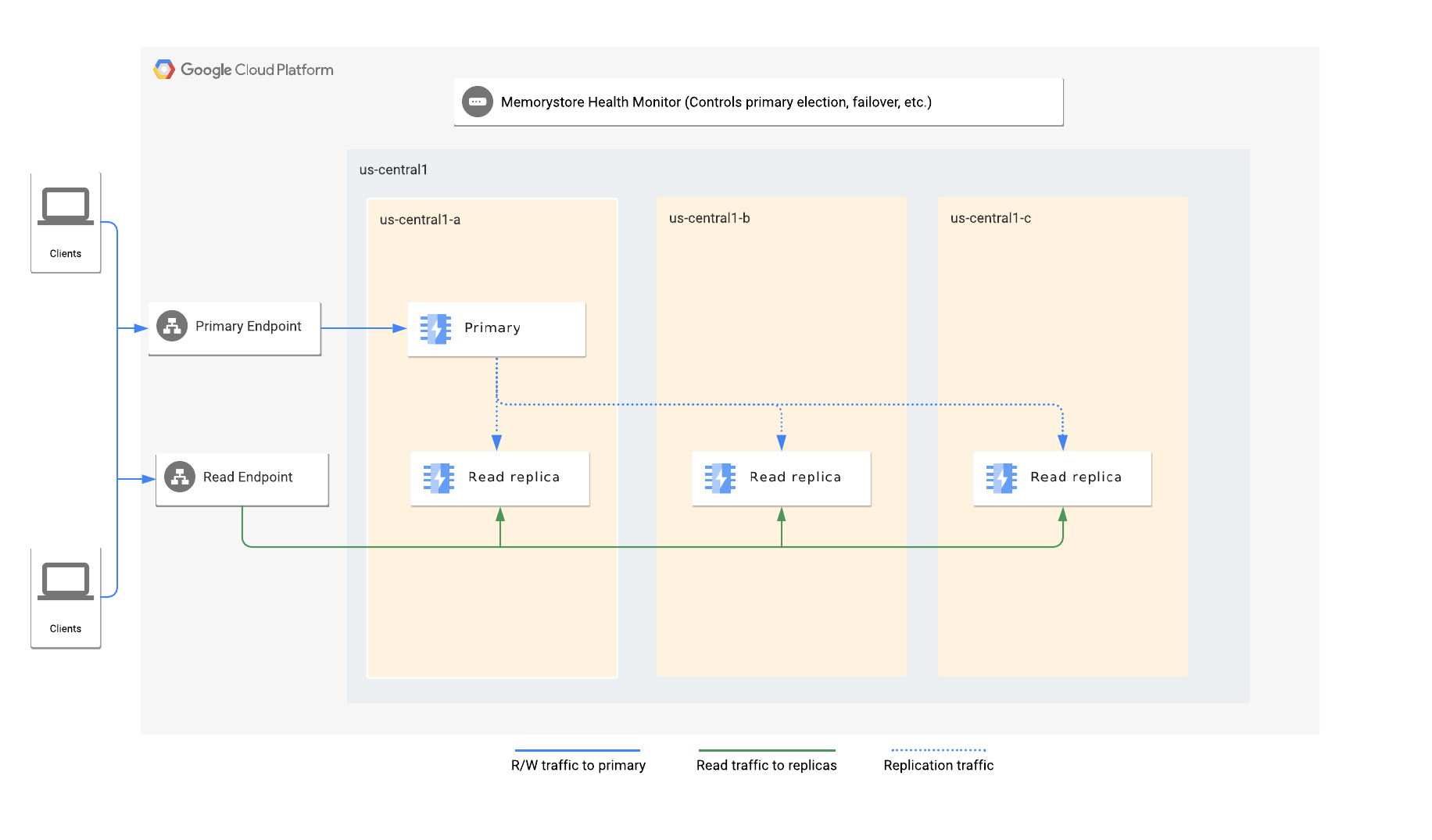
Si una instancia se configura con solo una réplica de no lectura, todas las conexiones de la aplicación se dirigen al endpoint principal. Si una instancia se configura con réplicas de lectura, las aplicaciones también pueden aprovechar el endpoint de lectura para distribuir las consultas de lectura entre todas las réplicas.
Cuando se activa una conmutación por error
Se produce una conmutación por error cuando falla el servidor principal de Redis. Durante una conmutación por error, los endpoints principal y de lectura se redirigen automáticamente al nuevo principal y a las réplicas. Se interrumpen todas las conexiones al endpoint principal y también las conexiones al endpoint de lectura de la réplica de lectura que se ha ascendido.
Cómo afecta una conmutación por error a tu aplicación
Cuando la réplica toma el control de la instancia principal, se pierden las conexiones existentes con el endpoint principal de la instancia. La instancia no estará disponible durante una media de 30 segundos durante las reparaciones automatizadas y 15 segundos durante los eventos de mantenimiento. Cuando se vuelve a conectar, tu aplicación se redirige automáticamente al nuevo principal con la misma cadena de conexión o dirección IP. No es necesario que actualices tu aplicación después de una conmutación por error.
Durante la conmutación por error, si hay conexiones al endpoint de lectura, se eliminarán las conexiones a la réplica que se esté convirtiendo en principal. Las conexiones a las otras réplicas se siguen atendiendo durante la conmutación por error. Una vez que se haya completado la conmutación por error y la nueva réplica esté disponible, las conexiones se redirigirán a la nueva réplica.
Reintentar la conexión de la instancia después de la conmutación por error
Cuando se produce una conmutación por error, se eliminan todas las conexiones del endpoint principal y, en función del número de réplicas, se terminan algunas conexiones de lectura.
Debido a esta pérdida de conexión, tu aplicación debe volver a intentarlo para restablecer la conexión. La lógica de reintentos debe usar un tiempo de espera exponencial para asegurarse de que no se sobrecarga la instancia con demasiadas solicitudes de reintento. Además de incluir la lógica de reintento, debes probar cómo afecta una conmutación por error a tu aplicación haciendo una prueba de conmutación por error manual.
La mayoría de los clientes de Redis tienen funciones de reintento integradas que deberías aprovechar en caso de que se interrumpa la conexión debido a una conmutación por error.
Se produce una conmutación por error en los siguientes casos:
- Escalar una instancia
- Actualizar la versión de Redis de una instancia
- Iniciar una conmutación por error manual
- Actualizaciones de mantenimiento
Si implementas una lógica de reintento en tu aplicación para gestionar las interrupciones de conexión debidas a conmutaciones por error, tu instancia no debería experimentar un impacto significativo en el rendimiento. Normalmente, los problemas solo surgen cuando no se ha implementado la lógica de reintento.
Cómo ver el estado de la alta disponibilidad
Puedes ver las métricas de alta disponibilidad de tu instancia de Redis con Cloud Monitoring. Para obtener información sobre las métricas que proporciona Cloud Monitoring para Memorystore para Redis, consulta los artículos Monitorizar instancias de Redis y Métricas de monitorización.
Para obtener más información, consulta la documentación de Cloud Monitoring.
Para ver el estado de la réplica nativa que proporciona Redis, puedes ejecutar el comando INFO de Redis en la instancia de Memorystore para Redis.