En esta página, se describe la alta disponibilidad (HA) para instancias de Memorystore para Redis en el nivel Estándar.
Descripción general
El nivel Estándar protege a las instancias de Redis de fallas comunes replicando los datos en una o más réplicas y proporcionando una conmutación por error automática rápida a una réplica.
El nivel estándar se aprovisiona con una instancia principal y una o más réplicas. Una instancia de nivel Estándar que tiene inhabilitado readReplicaMode tiene una sola réplica que no es de lectura. Una instancia de nivel Estándar que tiene habilitado readReplicaMode tiene entre una y cinco réplicas de lectura. Para determinar si readReplicaMode está habilitado, consulta Cómo ver la información de la réplica de lectura.
Memorystore para Redis proporciona alta disponibilidad mediante la replicación de un Redis principal en una o más réplicas. Los cambios realizados a los datos en el principal se copian en las réplicas mediante el protocolo de replicación asíncrona de Redis. Debido a la naturaleza asíncrona de la replicación, las réplicas pueden retrasarse con respecto a la instancia principal según la tasa de escritura en la instancia principal.
Si falla la instancia principal, la instancia se conmuta por error automáticamente a una réplica. En el caso de las instancias configuradas con más de una réplica, la instancia falla automáticamente a una réplica con el menor retraso de replicación que esté en buen estado.
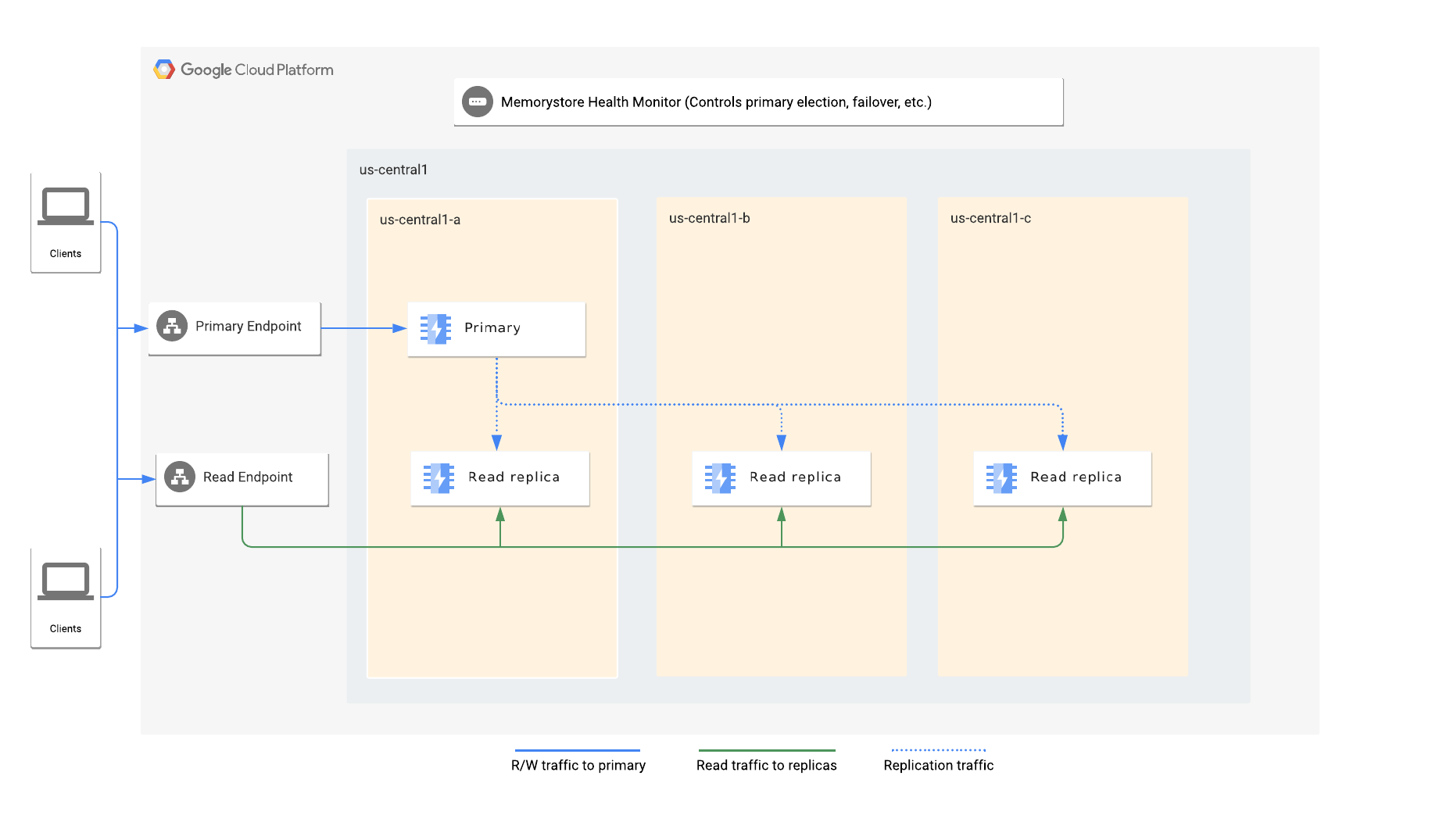
Si una instancia se configura con una sola réplica que no es de lectura, todas las conexiones de la aplicación se dirigen al extremo principal. Si una instancia se configura con réplicas de lectura, las aplicaciones también pueden aprovechar el extremo de lectura para distribuir las consultas de lectura entre todas las réplicas.
Cuándo se activa una conmutación por error
Una conmutación por error ocurre cuando falla el Redis principal. Durante una conmutación por error, el extremo principal y de lectura redireccionan automáticamente a la nueva instancia principal y a las réplicas. Se descartan todas las conexiones al extremo principal y también las conexiones del extremo de lectura a la réplica de lectura que se promociona.
Cómo afecta una conmutación por error a tu aplicación
Cuando la instancia principal se conmuta por error a la réplica, se descartan las conexiones existentes al extremo principal de la instancia. La instancia no estará disponible durante un promedio de 30 segundos durante las reparaciones automáticas y de 15 segundos para los eventos de mantenimiento. Cuando se vuelve a conectar, tu aplicación se redirecciona automáticamente al nuevo elemento principal con la misma cadena de conexión o dirección IP. No necesitas actualizar tu aplicación después de una conmutación por error.
Durante la conmutación por error, si hay conexiones al extremo de lectura, se descartan las conexiones a la réplica que se promueve a principal. Las conexiones a las otras réplicas se siguen entregando durante la conmutación por error. Una vez que se complete la conmutación por error y la réplica nueva esté disponible, las conexiones se redireccionarán a la réplica nueva.
Reintenta la conexión de la instancia después de la conmutación por error
Cuando se produce una conmutación por error, se pierden todas las conexiones del extremo principal y, según la cantidad de réplicas, se finalizan algunas conexiones de lectura.
Debido a esta desconexión, tu aplicación debe ejecutar un reintento para restablecer la conexión. La lógica de reintento debe usar la retirada exponencial para asegurarse de no sobrecargar la instancia con demasiadas solicitudes de reintento. Además de incluir la lógica de reintento, debes probar cómo una conmutación por error afecta a tu aplicación mediante la prueba con una conmutación por error manual.
La mayoría de los clientes de Redis tienen funciones de reintento integradas que debes aprovechar en caso de caídas de conexión debido a la conmutación por error.
En una de estas situaciones, se produce una conmutación por error:
- Escalamiento de la instancia
- Actualiza la versión de Redis de una instancia
- Inicia una conmutación por error manual
- Actualizaciones de mantenimiento
Si implementas la lógica de reintento en tu aplicación para controlar las desconexiones debidas a las conmutaciones por error, la instancia no debería ver un impacto significativo en el rendimiento. Por lo general, solo ocurren problemas porque no se implementó una lógica de reintento.
Cómo visualizar el estado de alta disponibilidad
Puedes ver las métricas de alta disponibilidad para tu instancia de Redis mediante Cloud Monitoring. Para obtener más información sobre las métricas que proporciona Cloud Monitoring para Memorystore para Redis, consulta Supervisa instancias de Redis y Métricas de supervisión.
Para obtener más información, consulta la documentación de Cloud Monitoring.
Para ver el estado de replicación nativo que brinda Redis, puedes ejecutar el comando INFO de Redis a la instancia de Memorystore para Redis.