Questa pagina descrive l'alta disponibilità (HA) per le istanze Memorystore for Redis nel livello Standard.
Panoramica
Il livello standard protegge un'istanza Redis da errori comuni replicando i dati in una o più repliche e fornendo un failover automatico rapido a una replica.
Il livello Standard viene sottoposto a provisioning con un'istanza principale e una o più repliche. Un'istanza di livello standard con readReplicaMode disabilitato ha una singola replica non di lettura. Un'istanza di livello standard con readReplicaMode abilitato ha da una a cinque repliche di lettura. Per determinare se
readReplicaMode è abilitato, consulta Visualizzare le informazioni sulla replica di lettura per l'istanza.
Memorystore for Redis offre alta disponibilità replicando un'istanza Redis primaria in una o più repliche. Le modifiche apportate ai dati sul server primario vengono copiate nelle repliche utilizzando il protocollo di replica asincrona di Redis. A causa della natura asincrona della replica, le repliche possono essere in ritardo rispetto al primario a seconda della velocità di scrittura sul primario.
In caso di errore dell'istanza principale, viene eseguito automaticamente il failover su una replica. Per le istanze configurate con più di una replica, l'istanza esegue automaticamente il failover a una replica integra con il minor ritardo di replica.
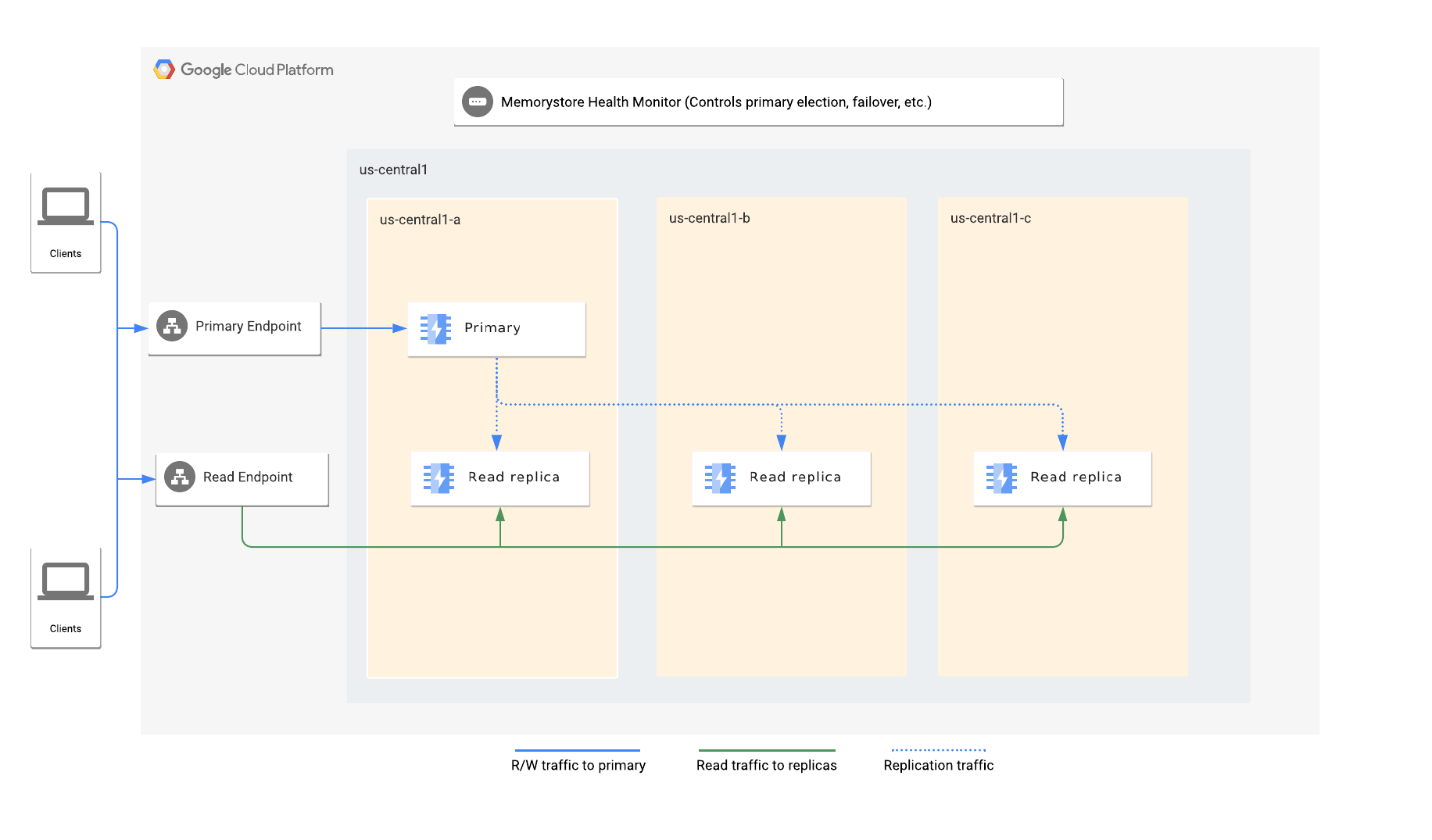
Se un'istanza è configurata con una sola replica di lettura, tutte le connessioni dell'applicazione vengono indirizzate all'endpoint primario. Se un'istanza è configurata utilizzando le repliche di lettura, le applicazioni possono anche sfruttare l'endpoint di lettura per distribuire le query di lettura su tutte le repliche.
Quando viene attivato un failover
Un failover si verifica quando l'istanza Redis primaria non funziona. Durante un failover, l'endpoint primario e di lettura viene reindirizzato automaticamente alla nuova istanza principale e alle repliche. Tutte le connessioni all'endpoint primario vengono interrotte e anche le connessioni dell'endpoint di lettura alla replica di lettura promossa vengono interrotte.
In che modo un failover influisce sulla tua applicazione
Quando viene eseguito il failover dell'istanza principale sulla replica, le connessioni esistenti all'endpoint principale dell'istanza vengono interrotte. L'istanza non sarà disponibile per una media di 30 secondi durante le riparazioni automatiche e di 15 secondi per gli eventi di manutenzione. Al momento della riconnessione, l'applicazione viene reindirizzata automaticamente al nuovo server primario utilizzando la stessa stringa di connessione o lo stesso indirizzo IP. Non è necessario aggiornare l'applicazione dopo un failover.
Durante il failover, se sono presenti connessioni all'endpoint di lettura, le connessioni alla replica che viene promossa a primaria vengono interrotte. Le connessioni alle altre repliche continuano a essere gestite durante il failover. Una volta completato il failover e quando la nuova replica è disponibile, le connessioni vengono reindirizzate alla nuova replica.
Riprova la connessione all'istanza dopo il failover
Quando si verifica un failover, tutte le connessioni dall'endpoint principale vengono interrotte e, a seconda del numero di repliche, alcune connessioni di lettura vengono terminate.
A causa di questa perdita di connessione, l'applicazione deve riprovare a ristabilire la connessione. La logica di ripetizione deve utilizzare il backoff esponenziale per assicurarsi di non sovraccaricare l'istanza con troppe richieste di ripetizione. Oltre a includere la logica di ripetizione, devi testare l'effetto di un failover sulla tua applicazione eseguendo un test con un failover manuale.
La maggior parte dei client Redis dispone di funzionalità di ripetizione integrate che devi sfruttare in caso di interruzione della connessione dovuta al failover.
Un failover si verifica nei seguenti scenari:
- Scalabilità dell'istanza
- Upgrade della versione di Redis di un'istanza
- Avvio di un failover manuale
- Aggiornamenti di manutenzione
Se implementi la logica di ripetizione nell'applicazione per gestire le interruzioni della connessione dovute ai failover, la tua istanza non dovrebbe subire un impatto significativo sulle prestazioni. In genere, i problemi si verificano solo se non è presente una logica di ripetizione.
Come visualizzare lo stato dell'alta disponibilità
Puoi visualizzare le metriche di alta disponibilità per l'istanza Redis utilizzando Cloud Monitoring. Per informazioni sulle metriche che Cloud Monitoring fornisce per Memorystore for Redis, consulta Monitoraggio delle istanze Redis e Metriche di monitoraggio.
Per saperne di più, consulta la documentazione di Cloud Monitoring.
Per visualizzare lo stato della replica nativa fornito da Redis, puoi inviare il comando Redis INFO all'istanza Memorystore for Redis.