Overview
Looker uses aggregate awareness logic to find the smallest, most efficient table available in your database to run a query while still maintaining accuracy.
For very large tables in your database, Looker developers can create smaller aggregate tables of data, grouped by various combinations of attributes. The aggregate tables act as roll-ups or summary tables that Looker can use for queries whenever possible, instead of the original large table. When implemented strategically, aggregate awareness can speed up the average query by orders of magnitude.
For example, you might have a petabyte-scale data table with one row for every order that has occurred on your website. From this database, you can create an aggregate table with your daily sales totals. If your website receives 1,000 orders every day, your daily aggregate table would represent each day with 999 fewer rows than your original table. You can create another aggregate table with monthly sales totals that will be even more efficient. So now, if a user runs a query for daily or weekly sales, Looker will use the daily sales total table. If a user runs a query about yearly sales and you don't have a yearly aggregate table, Looker will use the next best thing, which is the monthly sales aggregate table in this example.
Looker answers your users' questions with the smallest aggregate tables whenever possible. For example:
- For a query about total monthly sales, Looker uses the aggregate table based on monthly sales (
sales_monthly_aggregate_table). - For a query about the total of each sale in a day, there is no aggregate table with that granularity, so Looker gets query results from the original database table (
orders_database). (However, if your users run this type of query often, you could create an aggregate table for it.) - For a query about weekly sales, there is no weekly aggregate table, so Looker uses the next best thing, which is the aggregate table based on daily sales (
sales_daily_aggregate_table).
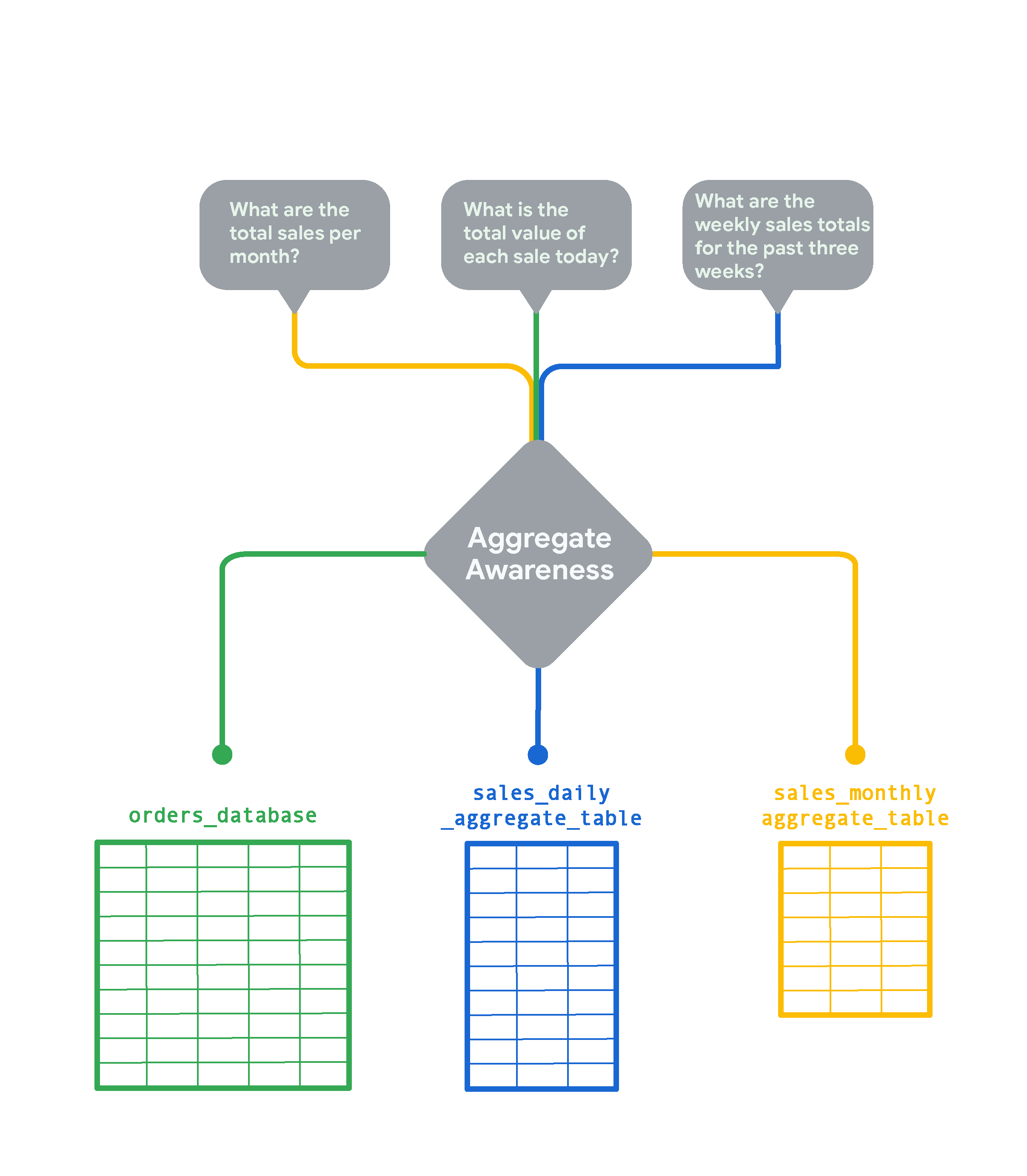
Using aggregate awareness logic, Looker will query the smallest aggregate table possible to answer your users' questions. The original table would be used only for queries requiring finer granularity than the aggregate tables can provide.
Aggregate tables don't need to be joined in or added to a separate Explore. Instead, Looker dynamically adjusts the FROM clause of the Explore query to access the best aggregate table for the query. This means that your drills are maintained and Explores can be consolidated. With aggregate awareness, one Explore can automatically leverage aggregate tables but still dive deep into granular data if needed.
You can also leverage aggregate tables to drastically improve the performance of dashboards, especially for tiles that query huge datasets. For details, see the Getting aggregate table LookML from a dashboard section on the aggregate_table parameter documentation page.
Adding aggregate tables to your project
Looker developers can create strategic aggregate tables that will minimize the number of queries required on the large tables in a database. Aggregate tables must be persisted to your database so that they can be accessible for aggregate awareness. Aggregate tables are therefore a type of persistent derived table (PDT).
An aggregate table is defined using the aggregate_table parameter under an explore parameter in your LookML project.
Here is an example of an explore with an aggregate table in LookML:
explore: orders {
label: "Sales Totals"
join: order_items {
sql_on: ${orders.id} = ${order_items.id} ;;
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [created_month]
measures: [order_items.total_sales]
}
}
# other explore parameters
}
To create an aggregate table, you can write the LookML from scratch, or you can get aggregate table LookML from an Explore or from a dashboard. See the aggregate_table parameter documentation page for the specifics of the aggregate_table parameter and its subparameters.
Designing aggregate tables
For an Explore query to use an aggregate table, the aggregate table must be able to provide accurate data for the Explore query. Looker can use an aggregate table for an Explore query if all the following are true:
- The Explore query's fields are a subset of the aggregate table's fields (see the Field factors section on this page). Or, for timeframes, the Explore query's timeframes can be derived from the timeframes in the aggregate table (see the Timeframe factors section on this page).
- The Explore query contains measure types supported by aggregate awareness (see the Measure type factors section on this page), or the Explore query has an aggregate table that is an exact match (see the Creating aggregate tables that exactly match Explore queries section on this page).
- The Explore query's time zone matches the time zone used by the aggregate table (see the Time zone factors section on this page).
- The Explore query's filters reference fields that are available as dimensions in the aggregate table, or each of the Explore query's filters matches a filter in the aggregate table (see the Filter factors section on this page).
One way to ensure that an aggregate table can provide accurate data for an Explore query is to create an aggregate table that exactly matches an Explore query. See the Creating aggregate tables that exactly match Explore queries section on this page for details.
Field factors
To be used for an Explore query, an aggregate table must have all the dimensions and measures needed for that Explore query, including the fields used for filters in the Explore query. If an Explore query contains a dimension or measure that is not in an aggregate table, Looker can't use the aggregate table and will use the base table instead.
For example, if a query groups by dimensions A and B, aggregates by measure C, and filters on dimension D, then the aggregate table must minimally have A, B, and D as dimensions and C as a measure.
The aggregate table can have other fields as well, but it must have at least the Explore query fields in order to be viable for optimization. The one exception is timeframe dimensions, since coarser granularity timeframes can be derived from finer granularity ones.
Because of these field considerations, an aggregate table is specific to the Explore under which it's defined. An aggregate table defined under one Explore won't be used for queries on a different Explore.
Timeframe factors
Looker's aggregate awareness logic is able to derive one timeframe from another. An aggregate table can be used for a query as long as the aggregate table's timeframe has a finer (or equal) granularity as the Explore query. For example, an aggregate table based on daily data can be used for an Explore query that calls for other timeframes, such as queries for daily, monthly, and yearly data, or even day-of-month, day-of-year, and week-of-year data. But a yearly aggregate table can't be used for an Explore query that calls for hourly data, since the aggregate table's data doesn't have fine enough granularity for the Explore query.
The same applies to time range subsets. For example, if you have an aggregate table that is filtered for the last three months and a user queries the data with a filter for the last two months, Looker will be able to use the aggregate table for that query.
In addition, the same logic applies for queries with timeframe filters: an aggregate table can be used for a query with a timeframe filter as long as the aggregate table's timeframe has a finer (or equal) granularity as the timeframe filter used in the Explore query. For example, an aggregate table that has a daily timeframe dimension can be used for an Explore query that filters on day, week, or month.
Measure type factors
For an Explore query to use an aggregate table, the measures in the aggregate table must be able to provide accurate data for the Explore query.
For this reason, only certain types of measures are supported, as described in the following sections:
- Measures with supported measure types
- Measures defined by SQL expressions
- Measures that are not defined with
${TABLE} - Measures that approximate distinct counts
If an Explore query uses any other type of measure, Looker will use the original table, not the aggregate table, to return results. The only exception is if the Explore query is an exact match of an aggregate table query, as described in the section Creating aggregate tables that exactly match Explore queries.
Otherwise, Looker will use the original table, not the aggregate table, to return results.
Measures with supported measure types
Aggregate awareness can be used for Explore queries that use measures with these measure types:
To use an aggregate table for an Explore query, Looker must be able to operate on the aggregate table's measures to provide accurate data in the Explore query. For example, a measure with type: sum can be used for aggregate awareness because you can sum several sums: An aggregate table of weekly sums can be added together to get an accurate monthly sum. Similarly, a measure with type: max can be used because an aggregate table of daily maximums can be used to find the accurate weekly maximum.
In the case of measures with type: average, aggregate awareness is supported because Looker uses sum and count data to accurately derive average values from aggregate tables.
Measures defined with SQL expressions
Aggregate awareness can also be used with measures that are defined with expressions in the sql parameter. When defined with SQL expressions, the following measure types are also supported:
Aggregate awareness is supported for measures that are defined as combinations of other measures, such as this example:
measure: total_revenue_in_dollars {
type: number
sql: ${total_revenue_in_dollars} - ${inventory_item.total_cost_in_dollars} ;;
}
Aggregate awareness is also supported for measures where calculations are defined in the sql parameter, such as this measure:
measure: wholesale_value {
type: number
sql: (${order_items.total_sale_price} * 0.60) ;;
}
And aggregate awareness is supported for measures where MIN, MAX, and COUNT operations are defined in the sql parameter, such as this measure:
measure: most_recent_order_date {
type: date
sql: MAX(${users.created_at_raw})
}
Measures that refer to LookML fields
When sql expressions are used in measures, aggregate awareness supports the following types of field references:
- References using the
${view_name.field_name}format, which indicates fields in other views - References using the
${field_name}format, which indicates fields in the same view
Aggregate awareness is not supported for measures that are defined using the ${TABLE}.column_name format, which indicates a column in a table. (See the Incorporating SQL and referring to LookML objects documentation page for an overview of using references in LookML.)
For example, a measure defined with this sql parameter wouldn't be supported in an aggregate table, since it uses the ${TABLE}.column_name format:
measure: wholesale_value {
type: number
sql: (${TABLE}.total_sale_price * 0.60) ;;
}
If you want to include this measure in an aggregate table, you can instead create a dimension defined with the ${TABLE}.column_name format, then create a measure that references the dimension, like this:
dimension: total_sale_price {
sql: (${TABLE}.total_sale_price) ;;
}
measure: wholesale_value {
type: number
sql: (${total_sale_price} * 0.60) ;;
}
Now you can use the wholesale_value measure in your aggregate table.
Measures that approximate distinct counts
In general, distinct counts aren't supported with aggregate awareness because you can't get accurate data if you try to aggregate distinct counts. For example, if you are counting the distinct users on a website, there may be a user who came to the website twice, three weeks apart. If you tried to apply a weekly aggregate table to get a monthly count of distinct users on your website, that user would be counted twice in your monthly distinct count query, and the data would be incorrect.
One workaround for this is to create an aggregate table that exactly matches an Explore query, as described in the Creating aggregate tables that exactly match Explore queries section on this page. When the Explore query and an aggregate table query are the same, distinct count measures do provide accurate data, so they can be used for aggregate awareness.
Another option is to use approximations for distinct counts. For dialects that support HyperLogLog sketches, Looker can leverage the HyperLogLog algorithm to approximate distinct counts for aggregate tables.
The HyperLogLog algorithm is known to have about a 2% error. The allow_approximate_optimization: yes parameter requires your Looker developers to acknowledge that it's okay to use approximate data for the measure so that the measure may be calculated approximately from aggregate tables.
See the allow_approximate_optimization parameter documentation page for more information and for the list of dialects that support count distinct using HyperLogLog.
Time zone factors
In many cases, database admins use UTC as the time zone for databases. However, many users might not be in the UTC time zone. Looker has multiple options for converting time zones so that your users will get query results in their own time zone:
- Query time zone, a setting that applies to all queries on the database connection. If all your users are in the same time zone, you can set a single query time zone so that all queries are converted from the database time zone into the query time zone.
- User-specific time zones, where users can be assigned and select time zones individually. In this case, queries are converted from the database time zone into the individual user's time zone.
See the Using time zone settings documentation page for more information on these options.
These concepts are important for understanding aggregate awareness because, in order for an aggregate table to be used for a query with date dimensions or date filters, the time zone on the aggregate table must match the time zone setting used for the original query.
Aggregate tables use the database time zone if no timezone value is specified. Your database connection will also use the database time zone if any of the following are true:
- Your database does not support time zones.
- Your database connection's query time zone is set to the same time zone as the database time zone.
- Your database connection has neither a specified query time zone nor user-specific time zones. If this is the case, your database connection will use the database time zone.
If any of these are true, you can omit the timezone parameter for your aggregate tables.
Otherwise, the aggregate table's time zone should be defined to match possible queries so that the aggregate table is more likely to be used:
- If your database connection uses a single query time zone, you should match your aggregate table's
timezonevalue to the query time zone value. - If your database connection uses user-specific time zones, you should create identical aggregate tables, each with a different
timezonevalue to match the possible time zones of your users.
Filter factors
Be careful when including filters in your aggregate table. Filters on an aggregate table can narrow the results to the point where the aggregate table is unusable. For example, say that you create an aggregate table for daily order counts, and the aggregate table filters for just sunglass orders coming from Australia. If a user runs an Explore query for daily order counts of sunglasses worldwide, Looker cannot use the aggregate table for that Explore query, since the aggregate table only has the data for Australia. The aggregate table filters the data too narrowly to be used by the Explore query.
Also, be conscious of the filters that your Looker developers might have built into your Explore, such as:
access_filters: Applies user-specific data restrictions.always_filter: Require users to include a certain set of filters for an Explore query. Users may change the default filter value for their query, but they cannot remove the filter entirely.conditionally_filter: Defines a set of default filters that users can override if they apply at least one filter from a second list that's also defined in the Explore.
These filter types are based on specific fields. If your Explore has these filters, you must include their fields in the dimensions parameter of the aggregate_table.
For example, here is an Explore with an access filter that is based on the orders.region field:
explore: orders {
access_filter: {
field: orders.region
user_attribute: region
}
}
To create an aggregate table that would be used for this Explore, the aggregate table must include the field on which the access filter is based. In the next example, the access filter is based on the field orders.region, and this same field is included as a dimension in the aggregate table:
explore: orders {
access_filter: {
field: orders.region # <-- orders.region field
user_attribute: region
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_day, orders.region] # <-- orders.region field
measures: [orders.total_sales]
timezone: America/Los_Angeles
}
}
}
Because the aggregate table query includes the orders.region dimension, Looker can dynamically filter the data in the aggregate table to match the filter from the Explore query. Therefore, Looker can still use the aggregate table for the Explore's queries, even though the Explore has an access filter.
This also applies to Explore queries that use a native derived table configured with bind_filters. The bind_filters parameter passes specified filters from an Explore query into the native derived table subquery. In the case of aggregate awareness, if your Explore query requires a native derived table that uses bind_filters, the Explore query can use an aggregate table only if all the fields used in the native derived table's bind_filters parameter have the exact same filter values in the Explore query as in the aggregate table.
Creating aggregate tables that exactly match Explore queries
One way to be sure that an aggregate table can be used for an Explore query is to create an aggregate table that exactly matches the Explore query. If the Explore query and the aggregate table both use the same measures, dimensions, filters, timezones, and other parameters, then by definition the aggregate table's results will apply to the Explore query. If an aggregate table is an exact match of an Explore query, Looker is able to use aggregate tables that include any type of measure.
You can create an aggregate table from an Explore using the Get LookML option from the gear menu of an Explore. You can also create exact matches for all the tiles in a dashboard using the Get LookML option from the gear menu of a dashboard.
Determining which aggregate table is used for a query
Users with see_sql permissions can use the comments in the SQL tab of an Explore to see which aggregate table will be used for a query. The SQL tab comments are also shown in Development Mode, so developers can test new aggregate tables to see how Looker uses them before you push new tables to production.
For example, based on the example monthly aggregate table shown previously, you can go to the Explore and run a query for yearly sales totals. Then you can click the SQL tab to see the details of the query that Looker created. If you are in Development Mode, Looker shows comments to indicate the aggregate table it used for the query.
From the following comments on the SQL tab, we can see that Looker is using the sales_monthly aggregate table for this query, and information about why other aggregate tables weren't used for the query:
-- use existing orders::sales_monthly in sandbox_scratch.LR$LB4151619827209021_orders$sales_monthly
-- Did not use orders::sales_weekly; it does not include the following fields in the query: orders.created_month
-- Did not use orders::sales_daily; orders::sales_monthly was a better fit for optimization.
-- Did not use orders::sales_last_3_days; contained filters not in the query: orders.created_date
See the Troubleshooting section on this page for possible comments you may see in the SQL tab and suggestions for how to resolve them.
Computation savings estimates for aggregate awareness
If your database connection supports cost estimates and if an aggregate table can be used for a query, the Explore window will show the computing savings of using the aggregate table instead of querying the database directly. The aggregate awareness savings is shown next to the Run button in an Explore before the query is run.
Before running the query, if you want to see which aggregate table will be used for the query, you can click the SQL tab, as described in the Determining which aggregate table is used for a query section of this documentation page.
After the query is run, the Explore window will show which aggregate table was used to answer the query next to the Run button.
Aggregate awareness savings is shown for database connections that are enabled for cost estimates. See the Exploring data in Looker documentation page for more information.
Looker unions new data to your aggregate tables
For aggregate tables with time filters, Looker can union fresh data into your aggregate table. You might have an aggregate table that includes data for the past three days, but that aggregate table might have been built yesterday. The aggregate table would be missing today's information, so you wouldn't expect to use it for an Explore query on the most recently daily information.
However, Looker still can use the data in that aggregate table for the query because Looker will run a query on the most recent data, then union those results into the results in the aggregate table.
Looker can union fresh data with your aggregate table's data given the following circumstances:
- The aggregate table has a time filter.
- The aggregate table includes a dimension based on the same time field as the time filter.
For example, the following aggregate table has a dimension based on the orders.created_date field, and has a time filter ("3 days") based on the same field:
aggregate_table: sales_last_3_days {
query: {
dimensions: [orders.created_date]
measures: [order_items.total_sales]
filters: [orders.created_date: "3 days"] # <-- time filter
timezone: America/Los_Angeles
}
...
}
If this aggregate table was built yesterday, Looker will retrieve the most recent data that is not yet included in the aggregate table, then union the fresh results with the results from the aggregate table. This means your users will get the latest data while still optimizing performance using aggregate awareness.
If you're in Development Mode, you can click the SQL tab of an Explore to see the aggregate table that Looker used for the query, and the UNION statement that Looker used to bring in newer data that wasn't included in the aggregate table.
Aggregate tables must be persisted
To be accessible for aggregate awareness, your aggregate table must be persisted in your database. The persistence strategy is specified in the aggregate table's materialization parameter. Because aggregate tables are a type of persistent derived table (PDT), aggregate tables have the same requirements as PDTs. See the Derived tables in Looker documentation page for details.
You can create incremental PDTs in your project if your dialect supports them. Looker builds incremental PDTs by appending fresh data to the table, instead of rebuilding the table in its entirety. Since aggregate tables are themselves a type of PDT, you can create incremental aggregate tables as well. See the Incremental PDTs documentation page for more information on incremental PDTs. See the increment_key parameter documentation page for an example of an incremental aggregate table.
A user with develop permission can override the persistence settings and rebuild all the aggregate tables for a query to get the most up-to-date data. To rebuild the tables for a query, select the Rebuild Derived Tables & Run option from the Explore actions gear menu.
You must wait for the Explore query to load before this option is available.
The Rebuild Derived Tables & Run option rebuilds all derived tables that are referenced in the query as well as any derived tables that are depended on by the tables in the query. This includes aggregate tables, which are themselves a type of persistent derived table.
For the user who initiates the Rebuild Derived Tables & Run option, the query will wait for the tables to rebuild before loading results. Other users' queries will still use the existing tables. Once the persistent tables are rebuilt, then all users will use the rebuilt tables.
See the Derived tables in Looker documentation page for further details about the Rebuild Derived Tables & Run option.
Troubleshooting
As described in the Determining which aggregate table is used for a query section, if you're in Development Mode, you can run queries on the Explore and click the SQL tab to see comments about the aggregate table used for the query, if any.
The SQL tab also includes comments about why aggregate tables were not used for a query, if that is the case. For aggregate tables that aren't used, the comment will begin with:
Did not use [explore name]::[aggregate table name];
For example, here is a comment about why the sales_daily aggregate table defined in the order_items Explore wasn't used for a query:
-- Did not use order_items::sales_daily; query contained the following filters
that were neither included as fields nor exactly matched by filters in the aggregate table:
order_items.created_year.
In this case, the filters in the query prevented the aggregate table from being used.
The following table shows some other possible reasons that an aggregate table can't be used, along with steps you can take to increase the usability of the aggregate table.
| Reason for not using the aggregate table | Explanation and possible steps |
|---|---|
| No such field in the Explore. | There is a LookML validation type error. This is mostly likely because the aggregate table was not properly defined, or there was a typo in the LookML for your aggregate table. A likely culprit is an incorrect field name, or the like.To resolve this, verify that the dimensions and measures in the aggregate table match the field names in the Explore. See the aggregate_table parameter documentation page for more information on how to define an aggregate table. |
| The aggregate table does not include the following fields in the query. | To be used for an Explore query, an aggregate table must have all the dimensions and measures needed for that Explore query, including the fields used for filters in the Explore query. If an Explore query contains a dimension or measure that is not in an aggregate table, Looker can't use the aggregate table and will use the base table instead. See the Field factors section on this page for details. The one exception is timeframe dimensions, since coarser granularity timeframes can be derived from finer granularity ones. To resolve this, verify that the Explore query's fields are included in the aggregate table definition. |
| The query contained the following filters that were neither included as fields nor exactly matched by filters in the aggregate table. | The filters in the Explore query prevent Looker from using the aggregate table. To resolve this, you can do one of the following:
|
| The query contains the following measures that cannot roll up. | The query contains one or more measure types that aren't supported for aggregate awareness, such as distinct count, median, or percentile.To resolve this, check the type of each measure in the query and make sure it is one of the supported measure types. Also, if your Explore has joins, verify that your measures aren't converted to distinct measures (symmetric aggregates) through fanned out joins. See the Symmetric aggregates for Explores with joins section on this page for an explanation. |
| A different aggregate table was a better fit for optimization. | There were multiple viable aggregate tables for the query and Looker found a more optimal aggregate table to use instead. Nothing needs to be done in this case. |
Looker did not do any grouping (because of a primary_key or cancel_grouping_fields parameter) and therefore the query can't be rolled up. |
The query references a dimension that prevents it from having a GROUP BY clause, and therefore Looker cannot use any aggregate table for the query.
To resolve this, verify that the view's primary_key parameter and the Explore's cancel_grouping_fields parameter are set up correctly. |
| The aggregate table contained filters not in the query. | The aggregate table has a non-time filter that is not in the query.To resolve this, you can remove the filter from the aggregate table. See the Filter factors section on this page for details. |
A field is defined as a filter-only field in the Explore query but is listed in the dimensions parameter of the aggregate table. |
The aggregate table's dimensions parameter lists a field that is defined only as a filter field in the Explore query.To resolve this, remove the field from the aggregate table's dimensions list. If this field is needed for the aggregate table, add it to the filters list in the aggregate table's query. |
| The optimizer cannot determine why the aggregate table wasn't used. | This comment is reserved for corner cases. If you see this for an Explore query that is used often, you can create an aggregate table that exactly matches the Explore query. You can easily get aggregate table LookML from an Explore, as described on the aggregate_table parameter page. |
Things to consider
Symmetric aggregates for Explores with joins
One important thing to note is that in an Explore that joins multiple database tables, Looker can render measures of type SUM, COUNT, and AVERAGE as SUM DISTINCT, COUNT DISTINCT, and AVERAGE DISTINCT, respectively. Looker does this in order to avoid fanout miscalculations. For example, a count measure is rendered as a count_distinct measure type. This is to avoid fanout miscalculations for joins, and it is part of Looker's symmetric aggregates functionality. See the Best Practices page on symmetric aggregates for an explanation of this feature of Looker.
The symmetric aggregates functionality prevents miscalculations, but it can also prevent your aggregate tables from being used in certain cases, so it is important to understand.
For the measure types supported by aggregate awareness, this applies to sum, count, and average. Looker will render these types of measures as DISTINCT if:
- The measure is from the "one" view of a many-to-one or one-to-many join.
- The measure is from either view of a many-to-many join.
See the relationship parameter documentation page for an explanation of these types of joins.
If you find that your aggregate table isn't being used for this reason, you can create an aggregate table to exactly match an Explore query in order to use these measure types for an Explore with joins. See the Creating aggregate tables that exactly match Explore queries section on this page for more information.
Also, if you have a SQL dialect that supports HyperLogLog sketches, you can add the allow_approximate_optimization: yes parameter to the measure. When a count measure is defined with allow_approximate_optimization: yes, Looker can use the measure for aggregate awareness, even if it renders as a distinct count.
See the allow_approximate_optimization parameter documentation page for details, and for a list of which SQL dialects support HyperLogLog sketches.
Dialect support for aggregate awareness
The ability to use aggregate awareness depends on the database dialect your Looker connection is using. In the latest release of Looker, the following dialects support aggregate awareness:
| Dialect | Supported? |
|---|---|
| Actian Avalanche | Yes |
| Amazon Athena | Yes |
| Amazon Aurora MySQL | Yes |
| Amazon Redshift | Yes |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | Yes |
| Apache Hive 3.1.2+ | Yes |
| Apache Spark 3+ | Yes |
| ClickHouse | No |
| Cloudera Impala 3.1+ | Yes |
| Cloudera Impala 3.1+ with Native Driver | Yes |
| Cloudera Impala with Native Driver | Yes |
| DataVirtuality | No |
| Databricks | Yes |
| Denodo 7 | No |
| Denodo 8 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | Yes |
| Firebolt | No |
| Google BigQuery Legacy SQL | Yes |
| Google BigQuery Standard SQL | Yes |
| Google Cloud PostgreSQL | Yes |
| Google Cloud SQL | No |
| Google Spanner | No |
| Greenplum | Yes |
| HyperSQL | No |
| IBM Netezza | Yes |
| MariaDB | Yes |
| Microsoft Azure PostgreSQL | Yes |
| Microsoft Azure SQL Database | Yes |
| Microsoft Azure Synapse Analytics | Yes |
| Microsoft SQL Server 2008+ | Yes |
| Microsoft SQL Server 2012+ | Yes |
| Microsoft SQL Server 2016 | Yes |
| Microsoft SQL Server 2017+ | Yes |
| MongoBI | No |
| MySQL | Yes |
| MySQL 8.0.12+ | Yes |
| Oracle | Yes |
| Oracle ADWC | Yes |
| PostgreSQL 9.5+ | Yes |
| PostgreSQL pre-9.5 | Yes |
| PrestoDB | Yes |
| PrestoSQL | Yes |
| SAP HANA 2+ | Yes |
| SingleStore | Yes |
| SingleStore 7+ | Yes |
| Snowflake | Yes |
| Teradata | Yes |
| Trino | Yes |
| Vector | Yes |
| Vertica | Yes |
Dialect support for incrementally building aggregate tables
For Looker to support incremental aggregate tables in your Looker project, your database dialect must also support them. The following table shows which dialects support incrementally building PDTs in the latest release of Looker:
| Dialect | Supported? |
|---|---|
| Actian Avalanche | No |
| Amazon Athena | No |
| Amazon Aurora MySQL | No |
| Amazon Redshift | Yes |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | No |
| Apache Hive 3.1.2+ | No |
| Apache Spark 3+ | No |
| ClickHouse | No |
| Cloudera Impala 3.1+ | No |
| Cloudera Impala 3.1+ with Native Driver | No |
| Cloudera Impala with Native Driver | No |
| DataVirtuality | No |
| Databricks | Yes |
| Denodo 7 | No |
| Denodo 8 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | No |
| Firebolt | No |
| Google BigQuery Legacy SQL | No |
| Google BigQuery Standard SQL | Yes |
| Google Cloud PostgreSQL | Yes |
| Google Cloud SQL | No |
| Google Spanner | No |
| Greenplum | Yes |
| HyperSQL | No |
| IBM Netezza | No |
| MariaDB | No |
| Microsoft Azure PostgreSQL | Yes |
| Microsoft Azure SQL Database | No |
| Microsoft Azure Synapse Analytics | Yes |
| Microsoft SQL Server 2008+ | No |
| Microsoft SQL Server 2012+ | No |
| Microsoft SQL Server 2016 | No |
| Microsoft SQL Server 2017+ | No |
| MongoBI | No |
| MySQL | Yes |
| MySQL 8.0.12+ | Yes |
| Oracle | No |
| Oracle ADWC | No |
| PostgreSQL 9.5+ | Yes |
| PostgreSQL pre-9.5 | Yes |
| PrestoDB | No |
| PrestoSQL | No |
| SAP HANA 2+ | No |
| SingleStore | No |
| SingleStore 7+ | No |
| Snowflake | Yes |
| Teradata | No |
| Trino | No |
| Vector | No |
| Vertica | Yes |