This document explains how Cloud Logging routes log entries that are received by Google Cloud. There are several different types of routing destinations. For example, you can route log entries to a destination like a log bucket, which stores log entries. If you want to export your log data to a third-party destination, then you can route log entries to Pub/Sub. Also, a log entry can be routed to multiple destinations.
At a high level, this is how Cloud Logging routes and stores log entries:
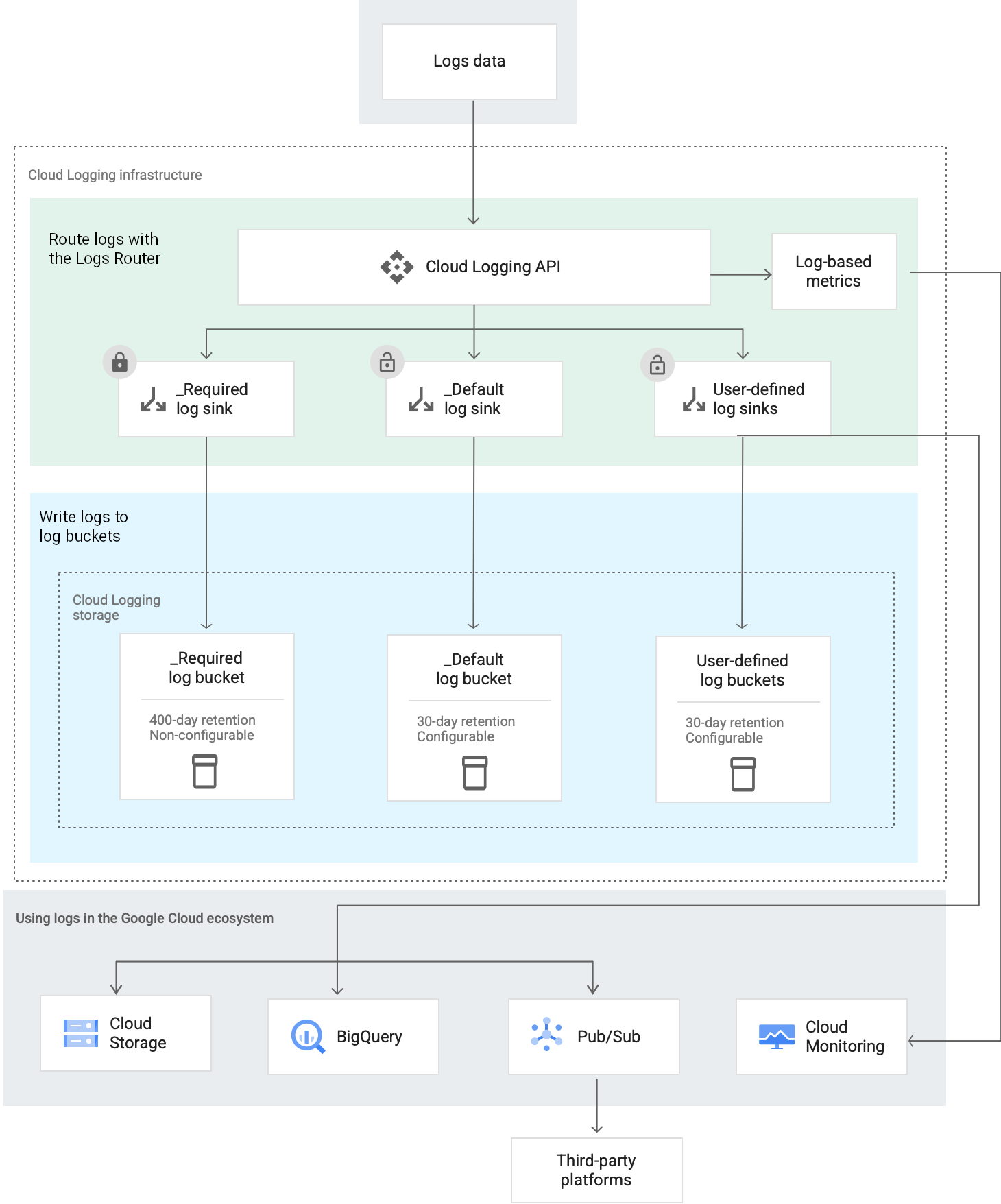
About Log Routers
Each Google Cloud project, billing account, folder, and organization has a Log Router, which manages the flow of log entries through resource-level sinks. A Log Router also manages the flow of a log entry through sinks that are in the entry's resource hierarchy. Sinks control how log entries are routed to destinations.
A Log Router stores a log entry temporarily. This behavior buffers against temporary disruptions and outages that might occur when a log entry flows through sinks. Temporary storage doesn't protect against configuration errors.
A Log Router's temporary storage is distinct from the longer term storage provided by Logging buckets.
Incoming log entries with timestamps that are more than the logs retention period in the past or that are more than 24 hours in the future are discarded.
About log sinks
When a log sink receives a log entry, it determines whether it should ignore or route the log entry. This decision is made by comparing the log entry to the filters in the log sink. When the log entry is routed, the log sink sends the log entry to the destination specified by the log sink. That destination might be a project, a storage location, or a service.
Log sinks belong to a given Google Cloud resource: Google Cloud projects, billing accounts, folders, and organizations. These resources also contain multiple log sinks. When a resource receives a log entry, every log sink in that resource independently evaluates the log entry. As a result, multiple log sinks can route the same log entry.
By default, log data is stored in the project where the data originates. However, there are several reasons why you might want to change this configuration:
- To centralize the storage of your log data.
- To join your log data with other business data.
- To organize your log data in a way that is useful to you.
- To stream your logs to other applications, other repositories, or third parties. For example, you might want to export your logs from Google Cloud so that you can view them on a third-party platform. To export your log entries, create a log sink that routes your log entries to Pub/Sub.
A misconfigured log sink doesn't route log entries. When a sink is misconfigured, log entries that report the detail of the error are written. Also, an email is sent to the Essential Contacts for the resource. For more information, see Troubleshoot: View errors.
Log sinks can't retroactively route log entries. That is, a log sink can't route a log entry that was received before the sink was created. Similarly, if a sink is misconfigured, then the sink only routes log entries that arrive after the configuration error is resolved. However, you can retroactively copy log data from a log bucket to Cloud Storage. For more information, see Copy logs.
Support for organizations and folders
To help you manage the log data in an organization or folder, you can do the following:
You can create aggregated sinks, which route log entries for an organization or folder and their children, to the destination specified by the sink. There are two types of aggregated sinks:
- Non-intercepting aggregated sinks
- Intercepting aggregated sinks
The difference between these two sink types is that intercepting sinks at one level in the resource hierarchy can affect routing for resources lower in the hierarchy. Non-intercepting sinks don't affect routing for other resources. When an intercepting sink in a resource matches a log entry, the log entry isn't sent to the sinks in child resources, with the exception that the log entry is always sent to the
_Requiredlog sink in the resource where the log entry originates.You can configure Default resource settings to specify the configuration of the system-created
_Defaultsink for new resources in an organization or folder. For example, you can use these settings to disable the_Defaultsink or specify the filters in that sink.
Routing examples
This section illustrates how a log entry that originates in a project might flow through the sinks in its resource hierarchy.
Example: No aggregated sinks exist
When no aggregated sinks exist in the resource hierarchy of the log entry, the log entry is sent to the log sinks in the project where the log entry originates. A project-level sink routes the log entry to the sink's destination when the log entry matches the sink's inclusion filter but doesn't match any of the sink's exclusion filters.
Example: A non-intercepting aggregated sink exists
Assume that a non-intercepting aggregated sink exists in the resource hierarchy for a log entry. After the Log Router sends the log entry to the non-intercepting aggregated sink, the following occurs:
The non-intercepting aggregated sink routes the log entry to the sink's destination when the log entry matches the inclusion filter but doesn't match any exclusion filter.
The Log Router sends the log entry to the log sinks in the project where the log entry originated.
A project-level sink routes the log entry to the sink's destination when the log entry matches the sink's inclusion filter but doesn't match any of the sink's exclusion filters.
Example: An intercepting aggregated sink exists
Assume that an intercepting aggregated sink exists in the resource hierarchy for a log entry. After the Log Router sends the log entry to the intercepting aggregated sink, one of the following occurs:
The log entry matches the inclusion filter but doesn't match any exclusion filter:
- The log entry is routed to the destination of the intercepting aggregated sink.
- The log entry is sent to the
_Requiredsink in the project where the log entry originated.
The log entry doesn't match the inclusion filter or it matches at least one exclusion filter:
- The log entry isn't routed by the intercepting aggregated sink.
The Log Router sends the log entry to the log sinks in the project where the log entry originated.
A project-level sink routes the log entry to the sink's destination when the log entry matches the sink's inclusion filter but doesn't match any of the sink's exclusion filters.
Log sink filters
Each log sink contains one inclusion filter and can contain multiple exclusion filters. These filters determine whether the log sink routes a log entry to the destination of the sink. If you don't specify any filters, then every log entry is routed to the sink's destination.
A log entry is routed by a log sink based on these rules:
If the log entry doesn't match the inclusion filter, then it isn't routed. When a sink doesn't specify an inclusion filter, then every log entry matches that filter.
If the log entry matches the inclusion filter and at least one exclusion filter, then it isn't routed.
If the log entry matches the inclusion filter and doesn't match any exclusion filter, then it is routed to the sink's destination.
The filters in a log sink are specified by using the Logging query language.
You can't use exclusion filters to reduce the consumption of your
entries.write API quota or the
the number of entries.write API calls. Exclusion filters
are applied after log entries are received by the Logging API.
System-created log sinks
For each Google Cloud project, billing account, folder, and organization,
Cloud Logging creates two log sinks, one named _Required and the other
named _Default. The inclusion and exclusion filters for these sinks verify
that every log entry that reaches the resource is routed by one of these sinks.
Both sinks route log data to a log bucket that is in the same resource as the
log sink.
The remainder of this section provides information about the filters and destinations of the system-created log sinks.
_Required log sink
The _Required log sink in a resource, routes a subset of audit logs to the
resource' _Required log bucket.
This sink doesn't specify any exclusion filters, and the inclusion filter
is as shown:
LOG_ID("cloudaudit.googleapis.com/activity") OR
LOG_ID("externalaudit.googleapis.com/activity") OR
LOG_ID("cloudaudit.googleapis.com/system_event") OR
LOG_ID("externalaudit.googleapis.com/system_event") OR
LOG_ID("cloudaudit.googleapis.com/access_transparency") OR
LOG_ID("externalaudit.googleapis.com/access_transparency")
The _Required log sink only matches log entries that originate in the
resource where the _Required log sink is defined. For example, suppose
a log sink routes an activity log entry from project A to project B.
Because the log entry didn't originate in project B, the
_Required log sink in project B doesn't route this log entry to the
_Required log bucket.
You can't modify or delete the _Required log sink.
_Default log sink
The _Default log sink in a resource, routes all log entries
except those that match the filter of the _Required log sink,
to the resource' _Default log bucket.
Because the inclusion filter for this sink is empty, it matches all
log entries. However, the exclusion filter is configured as follows:
NOT LOG_ID("cloudaudit.googleapis.com/activity") AND
NOT LOG_ID("externalaudit.googleapis.com/activity") AND
NOT LOG_ID("cloudaudit.googleapis.com/system_event") AND
NOT LOG_ID("externalaudit.googleapis.com/system_event") AND
NOT LOG_ID("cloudaudit.googleapis.com/access_transparency") AND
NOT LOG_ID("externalaudit.googleapis.com/access_transparency")
You can modify and disable the _Default log sink. For example, you can
edit the _Default log sink and change the destination. You can also
modify any existing filter and add exclusion filters.
Sink destinations
The destination of a sink can be in a different resource than the sink. For example, you can use a log sink to route log entries from one project to a log bucket stored in a different project.
The following destinations are supported:
- Google Cloud project
Select this destination when you want the log sinks in the destination project to reroute your log entries, or when you have created an intercepting aggregated sink. The log sinks in the project that is the sink destination can reroute the log entries to any supported destination except a project.
- Log bucket
Select this destination when you want to store your log data in resources managed by Cloud Logging. Log data stored in log buckets can be viewed and analyzed using services like the Logs Explorer and Log Analytics.
If you want to join your log data with other business data, then you can store your log data in a log bucket and create a linked BigQuery dataset. A linked dataset is a read-only dataset that can be queried like any other BigQuery dataset.
- BigQuery dataset
- Select this destination when you want to join your log data with other business data. The dataset you specify must be write-enabled. Don't set the destination of a sink to be a linked BigQuery dataset. Linked datasets are read-only.
- Cloud Storage bucket
- Select this destination when you want long-term storage of your log data. The Cloud Storage bucket can be in the same project in which log entries originate, or in a different project. Log entries are stored as JSON files.
- Pub/Sub topic
- Select this destination when you want to export your log data from Google Cloud and then use third-party integrations like Splunk or Datadog. Log entries are formatted into JSON and then routed to a Pub/Sub topic.
Destination limitations
This section describes destination-specific limitations:
- If you route log entries to a log bucket in a different Google Cloud project, then Error Reporting doesn't analyze those log entries. For more information, see Error Reporting overview.
- If you route log entries to a BigQuery dataset, the BigQuery dataset must be write-enabled. You can't route log entries to linked datasets, which are read-only.
- New sinks that route log data to Cloud Storage buckets might take several hours to start routing log entries. These sinks are processed hourly.
The following limitations apply when the destination of a log sink is a Google Cloud project:
- There is a one-hop limit.
- Log entries that match the filter of the
_Requiredlog sink are only routed to the_Requiredlog bucket of the destination project when they originate in the destination project. - Only aggregated sinks that are in the resource hierarchy of a log entry process the log entry.
For example, assume the destination of a log sink in project
Ais projectB. Then the following are true:- Due to the one-hop limit, the log sinks in project
Bcan't reroute log entries to a Google Cloud project. - The
_Requiredlog bucket of projectBonly stores log entries that originate in projectB. This log bucket doesn't store any log entries that originate in any other resource, including those that originate in projectA. - If the resource hierarchy of project
Aand projectBdiffer, then a log entry that a log sink in projectAroutes to projectBisn't sent to the aggregated sinks in the resource hierarchy of projectB. - If project
Aand projectBhave the same resource hierarchy, then log entries are sent to the aggregated sinks in that hierarchy. If a log entry isn't intercepted by an aggregated sink, then the Log Router sends the log entry to the sinks in projectA.
How routing log entries affects log-based metrics
Log-based metrics are Cloud Monitoring metrics that are derived from the content of log entries. For example, you can use a log-based metric to count the number of log entries that contain a particular message or to extract latency information recorded in log entries. You can display log-based metrics in Cloud Monitoring charts, and alerting policies can monitor these metrics.
System-defined log-based metrics apply at the project level. User-defined log-based metrics can apply at the project level or log bucket level. Bucket-scoped log-based metrics are useful when you use aggregated sinks to route log entries to a log bucket, and when you route log entries from one project to a log bucket in another project.
- System-defined log-based metrics
-
The Log Router counts a log entry when all of the following are true:
- The log entry passes through the log sinks of the project where the log-based metric is defined.
The log entry is stored in a log bucket. The log bucket can be in any project.
For example, suppose project
Ahas a log sink whose destination is projectB. Also assume that the log sinks in the projectBroute the log entries to a log bucket. In this scenario, the log entries routed from projectAto projectBcontribute to projectA's system-defined log-based metrics. These log entries also contribute to projectB's system-defined log-based metrics.
- User-defined log-based metrics
-
The Log Router counts a log entry when all of the following are true:
- Billing is enabled on the project where the log-based metric is defined.
- For bucket-scoped metrics, the log entry is stored in the log bucket where the log-based metric is defined.
- For project-scoped metrics, the log entry passes through the log sinks of the project where the log-based metric is defined.
For more information, see Log-based metrics overview.
Best practices
For best practices about using routing for data governance or for common use cases, see the following documents:
Examples: Centralize your log storage
This section outlines how you might configure centralized storage. Centralized storage provides a single place to query for log data, which simplifies your queries when you are searching for trends or investigating issues. From a security perspective, you also have one storage location, which can simplify the tasks of your security analysts.
If you centralize your log storage, then consider whether to place a lien on the project that stores your log data. A lien can prevent the accidental deletion of a project. To learn more, see Protecting projects with liens.
Centralize log storage for projects in a folder
Suppose that you manage a folder and want to centralize the storage of your log entries. For this use case, you might do the following:
- In your folder, you create a project named
CentralStorage. - Create an intercepting aggregated sink for your folder and you configure
it to route all log entries. You set the destination of the sink to be the
project named
CentralStorage.
When a log entry that originates in the folder or in one of its child
resources arrives, that log entry is sent to the
intercepting aggregated sink that you created. That sink routes log entries
to the project named CentralStorage. The log sinks in this project
process the log entries:
The
_Defaultlog sink routes to the_Defaultlog bucket all log entries that match the sink's filter. This log bucket is your centralized storage location.The
_Requiredlog sink routes to the_Requiredlog bucket the log entries that match the sink's filters and that originate in theCentralStorageproject. This log bucket isn't a centralized storage location. However, you can centrally store all your log data. For an example, see Store audit logs in a central location.
After the aggregated sink processing completes, the log entry is sent to
the _Required log sink in the
resource in which the log entry originated. When the log entry matches
the filter in the _Required log sink, the log entry is routed to the
resource's _Required log bucket. Consequently, each Google Cloud project in your
folder stores log entries in their _Required log bucket.
Centralize log storage for a set of projects
You can also store log entries in a single location when you don't have an organization or a folder. For example, you might do the following:
- Create a project named
CentralStorage. - For each project except
CentralStorage, you edit the_Defaultlog sink and set the destination to be the project namedCentralStorage.
You might wonder why the previous example sets the destination of the
_Default log sinks to be a project, instead of the _Default log bucket
in that project. The primary reasons are simplicity and consistency.
When you route log entries to a project, the log sinks in the destination
project control which log entries are stored and where they are stored.
That is, you centralize the filter and destination functionality. If you want
to change which log entries are stored or where they are stored, then you
only need to modify the log sinks in one project.
Centralize log storage for audit logs
You can centrally store log entries that match the
_Required log sink. If you want store these log entries
centrally, then do one of the following:
Create log sinks that route log entries that match the
_Requiredlog sink to a centralized log bucket.Configure log sinks as in the previous two examples, and then add a log sink in the destination project that routes log entries that match the
_Requiredlog sink to a log bucket. You could also edit the filters in the_Defaultlog sink.
Before you implement such a strategy, review the pricing guidelines.
Pricing
To learn about pricing for Cloud Logging, see the Google Cloud Observability pricing page.
What's next
To help you route and store Cloud Logging data, see the following documents:
To create sinks to route log entries to supported destinations, see Route logs to supported destinations.
To learn how to create aggregated sinks that can route log entries from the resources in folders or organizations, see Aggregated sinks overview.
To learn about the format of routed log entries and how the logs are organized in destinations, see the following documents: