Écrire et interroger des entrées de journal à l'aide d'un script Python
Ce guide de démarrage rapide présente quelques-unes des fonctionnalités de Cloud Logging et vous explique comment :
- Supprimer des entrées de journal à l'aide d'un script Python
- Affichez des entrées de journal à l'aide d'un script Python
- Supprimer des entrées de journal à l'aide d'un script Python
- Acheminer des journaux vers un bucket Cloud Storage
Logging peut acheminer les entrées de journal vers les destinations suivantes :
- Buckets Cloud Storage
- Ensembles de données BigQuery
- Pub/Sub
- Buckets Logging
- Google Cloud projets
Avant de commencer
Pour pouvoir réaliser cet exercice de démarrage rapide, vous devez disposer d'un projet Google Cloud avec la facturation activée. Si vous n'avez pas de projet Google Cloud ou si la facturation n'est pas activée pour votre projet Google Cloud , procédez comme suit :- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Ce guide de démarrage rapide fait appel à Cloud Logging et à Cloud Storage. L'utilisation de ces ressources peut entraîner des coûts. Une fois que vous avez terminé ce guide de démarrage rapide, vous pouvez éviter de continuer à payer des frais en supprimant les ressources que vous avez créées. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Premiers pas
Vous pouvez utiliser l'environnement Cloud Shell ou un environnement Linux générique pour suivre ce guide de démarrage rapide. Python est préinstallé dans Cloud Shell.
Cloud Shell
Ouvrez Cloud Shell et vérifiez la configuration de votre projet : Google Cloud
Dans la console Google Cloud , cliquez sur terminal Activer Cloud Shell.
Cloud Shell s'ouvre dans une fenêtre et affiche une bannière de bienvenue.
Le message de bienvenue reflète l'ID du projet Google Cloud configuré. S'il ne s'agit pas du projet Google Cloud que vous souhaitez utiliser, exécutez la commande suivante en remplaçant PROJECT_ID par l'ID de votre projet :
gcloud config set project PROJECT_ID
Linux
Assurez-vous que Python est bien installé et configuré. Pour en savoir plus sur la préparation de votre machine pour le développement Python, consultez la section Configurer un environnement de développement Python.
Installez la bibliothèque cliente Cloud Logging :
pip install --upgrade google-cloud-loggingConfigurez les autorisations Identity and Access Management pour votre projet Google Cloud . Dans les étapes suivantes, vous allez créer un compte de service pour votre projetGoogle Cloud , puis générer et télécharger un fichier sur votre poste de travail Linux.
-
Dans la console Google Cloud , accédez à la page Comptes de service :
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est IAM et administration.
Sélectionnez le projet de démarrage rapide Google Cloud , puis cliquez sur Créer un compte de service :
- Saisissez un nom pour le compte.
- Saisissez une description pour le compte.
- Cliquez sur Créer et continuer.
Cliquez sur le champ Sélectionner un rôle, puis sélectionnez Administrateur Logging.
Cliquez sur OK pour terminer la création du compte de service.
Créez un fichier de clé et téléchargez-le sur votre poste de travail :
- Pour votre compte de service, cliquez sur more_vert Plus d'options, puis sélectionnez Gérer les clés.
- Dans le volet Clés, cliquez sur Ajouter une clé.
- Cliquez sur Créer une clé.
Pour le type de clé, sélectionnez JSON, puis cliquez sur Créer. Après quelques instants, une fenêtre affiche un message semblable à celui-ci :

-
Sur votre poste de travail Linux, fournissez les identifiants d'authentification à votre application en définissant la variable d'environnement
GOOGLE_APPLICATION_CREDENTIALSsur le chemin d'accès au fichier de clé. Exemple :export GOOGLE_APPLICATION_CREDENTIALS="/home/user/Downloads/FILE_NAME.json"Cette variable ne s'applique qu'à la session d'interface système actuelle. Par conséquent, si vous ouvrez une nouvelle session, vous devez la définir à nouveau.
Cloner la source
Pour configurer Cloud Shell pour ce guide de démarrage rapide, procédez comme suit :
Clonez le projet GitHub
python-logging:git clone https://github.com/googleapis/python-loggingLe répertoire
samples/snippetscontient les deux scripts utilisés dans ce guide de démarrage rapide :snippets.pyvous permet de gérer les entrées dans un journal.export.pyvous permet de gérer les exportations de journaux.
Accédez au répertoire
snippets:cd python-logging/samples/snippets
Écrire des entrées de journal
Le script snippets.py utilise les bibliothèques clientes Python pour écrire des entrées de journal dans Logging. Lorsque l'option write est spécifiée sur la ligne de commande, le script écrit les entrées de journal suivantes :
- Une entrée avec des données non structurées et aucun niveau de gravité spécifié
- Une entrée avec des données non structurées et le niveau de gravité
ERROR - Une entrée avec des données structurées JSON et aucun niveau de gravité spécifié
Pour écrire de nouvelles entrées de journal dans le journal my-log, exécutez le script snippets.py avec l'option write :
python snippets.py my-log write
Afficher les entrées de journal
Pour afficher les entrées de journal dans Cloud Shell, exécutez le script snippets.py avec l'option list :
python snippets.py my-log list
La commande se termine avec le résultat suivant :
Listing entries for logger my-log:
* 2018-11-15T16:05:35.548471+00:00: Hello, world!
* 2018-11-15T16:05:35.647190+00:00: Goodbye, world!
* 2018-11-15T16:05:35.726315+00:00: {u'favorite_color': u'Blue', u'quest': u'Find the Holy Grail', u'name': u'King Arthur'}
Si le résultat n'affiche aucune entrée, relancez la commande. La réception et le traitement des entrées de journal par Logging peuvent prendre quelques instants.
Vous pouvez également afficher les entrées de journal à l'aide de l'explorateur de journaux. Pour en savoir plus, consultez Afficher les journaux à l'aide de l'explorateur de journaux.
Supprimer des entrées de journal
Pour supprimer toutes les entrées de journal dans le journal my-log, exécutez le script snippets.py avec l'option delete :
python snippets.py my-log delete
La commande se termine avec le résultat suivant :
Deleted all logging entries for my-log.
Acheminer les journaux
Dans cette section, vous allez exécuter les opérations suivantes :
- Créer un bucket Cloud Storage en tant que destination des données
- Créer un récepteur qui copie les nouvelles entrées de journal dans la destination
- Mettre à jour les autorisations du bucket Cloud Storage
- Écrire des entrées de journal dans Logging
- Si nécessaire, vérifier les contenus du bucket Cloud Storage
Créer une destination
Dans ce guide de démarrage rapide, la destination des exportations est un bucket Cloud Storage. Pour créer un bucket Cloud Storage, procédez comme suit :
-
Dans la console Google Cloud , accédez à la page Buckets :
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Cloud Storage.
- Cliquez sur Créer un bucket.
- Saisissez un nom pour ce bucket.
- Dans le champ Type d'emplacement, sélectionnez Région, ce qui sélectionne un emplacement de bucket avec la latence la plus faible.
- Dans Default storage class (Classe de stockage par défaut), sélectionnez Standard.
- Dans Contrôle des accès, sélectionnez Ultraprécis.
- Dans Outils de protection, sélectionnez Aucun, puis cliquez sur Créer.
Ce guide de démarrage rapide utilise un nom de bucket Cloud Storage de myloggingproject-1.
Créer un récepteur
Un récepteur est une règle qui détermine si une entrée de journal nouvellement arrivée doit être acheminée depuis Logging vers une destination. Il est doté de trois attributs :
- Nom
- Destination
- Filtre
Pour en savoir plus sur les récepteurs, consultez la page Récepteurs.
Si une entrée de journal nouvellement arrivée remplit les conditions de requête, elle est acheminée vers la destination.
Le script export.py utilise les bibliothèques clientes Python pour créer, répertorier, modifier et supprimer des récepteurs. Pour créer le récepteur mysink qui exporte toutes les entrées de journal dont la gravité est d'au moins INFO vers le bucket Cloud Storage myloggingproject-1, exécutez la commande suivante :
python export.py create mysink myloggingproject-1 "severity>=INFO"
Pour afficher vos récepteurs, exécutez le script export.py avec l'option list :
python export.py list
Le script renvoie les éléments suivants :
mysink: severity>=INFO -> storage.googleapis.com/myloggingproject-1
Mettre à jour les autorisations de la destination
Les autorisations de la destination, en l'occurrence votre bucket Cloud Storage, ne sont pas modifiées lorsque vous créez un récepteur à l'aide du script export.py.
Vous devez modifier les paramètres d'autorisation du bucket Cloud Storage pour accorder une autorisation en écriture au récepteur. Pour en savoir plus sur les comptes de service, les niveaux d'accès et les rôles IAM, consultez la page Comptes de service.
Pour mettre à jour les autorisations du bucket Cloud Storage :
Identifiez l'identité du rédacteur du récepteur :
-
Dans la console Google Cloud , accédez à la page Routeur de journaux :
Accéder à la page routeur de journaux
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Logging.
Un tableau récapitulatif des récepteurs s'affiche.
Recherchez le récepteur dans le tableau, sélectionnez more_vert Menu, puis Afficher les détails du récepteur.
Copiez l'identité du rédacteur dans votre presse-papiers.
-
-
Dans la console Google Cloud , accédez à la page Buckets :
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Cloud Storage.
Pour afficher la vue détaillée, cliquez sur le nom de votre bucket.
Sélectionnez Autorisations, puis cliquez sur Accorder l'accès.
Collez l'identité du rédacteur dans la zone Nouveaux comptes principaux. Supprimez le préfixe
serviceAccount:de l'adresse d'identité du rédacteur.Définissez le rôle sur
Storage Object Creator, puis cliquez sur Enregistrer.
Pour en savoir plus, consultez Définir les autorisations des destinations.
Valider le récepteur
Pour vérifier que le récepteur et la destination sont correctement configurés, procédez comme suit :
Écrivez de nouvelles entrées de journal dans le journal
my-log:python snippets.py my-log writeAffichez les contenus du bucket Cloud Storage :
-
Dans la console Google Cloud , accédez à la page Buckets :
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Cloud Storage.
Pour afficher la vue détaillée, cliquez sur le nom de votre bucket. Celle-ci répertorie les dossiers contenant des données. Si le bucket ne comporte aucune donnée, le message suivant s'affiche :
There are no live objects in this bucket.Comme indiqué dans la section Entrées de journaux reçues tardivement, deux à trois heures peuvent s'écouler avant que les premières entrées ne s'affichent dans la destination ou que vous ne soyez averti d'une erreur de configuration.
Une fois que le bucket a reçu les données, la vue détaillée affiche un résultat de ce type :
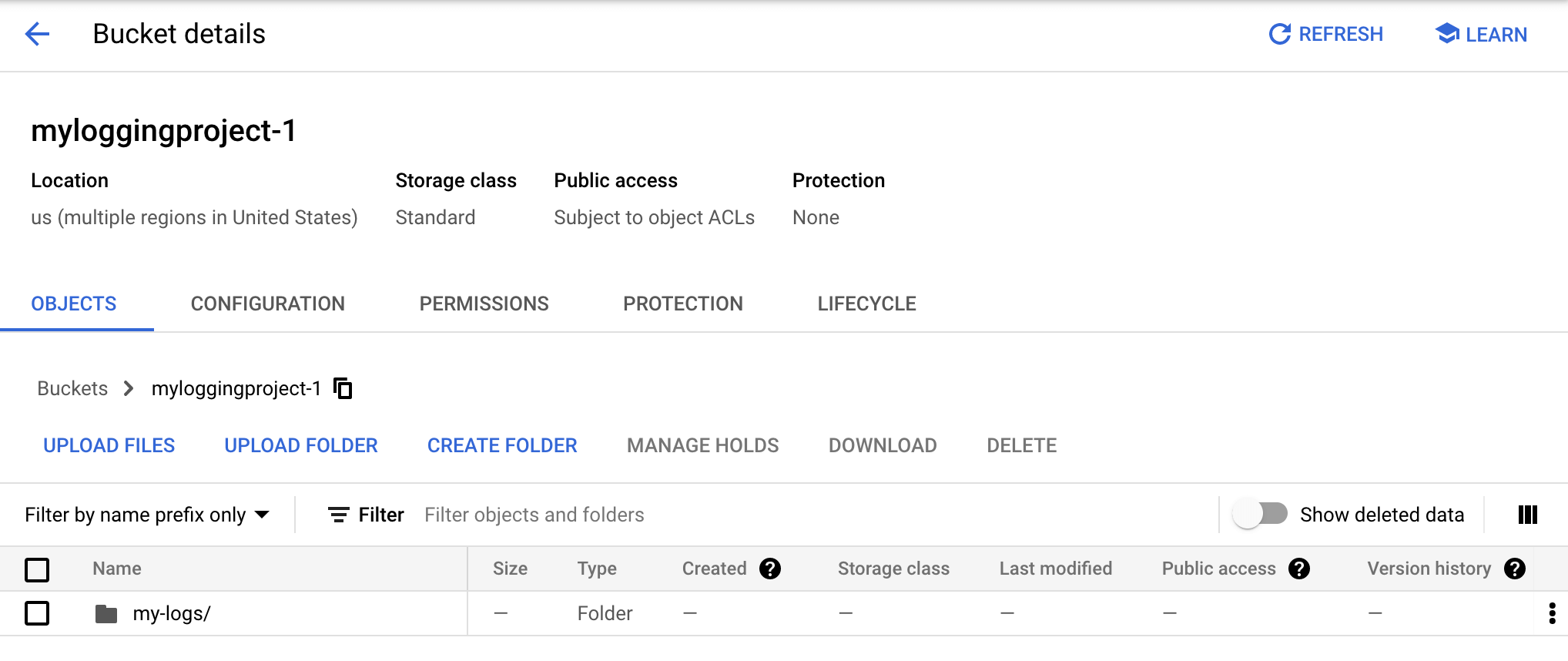
Les données de chaque dossier sont organisées en une série de dossiers, dotés d'une étiquette indiquant le dossier racine constitué d'un nom de journal, puis successivement, de l'année, du mois et du jour. Pour afficher les données exportées par le récepteur, cliquez sur le nom de dossier
my-log, puis continuez à cliquer sur les sous-dossiers de l'année, du mois et du jour jusqu'à atteindre un fichier finissant parjson: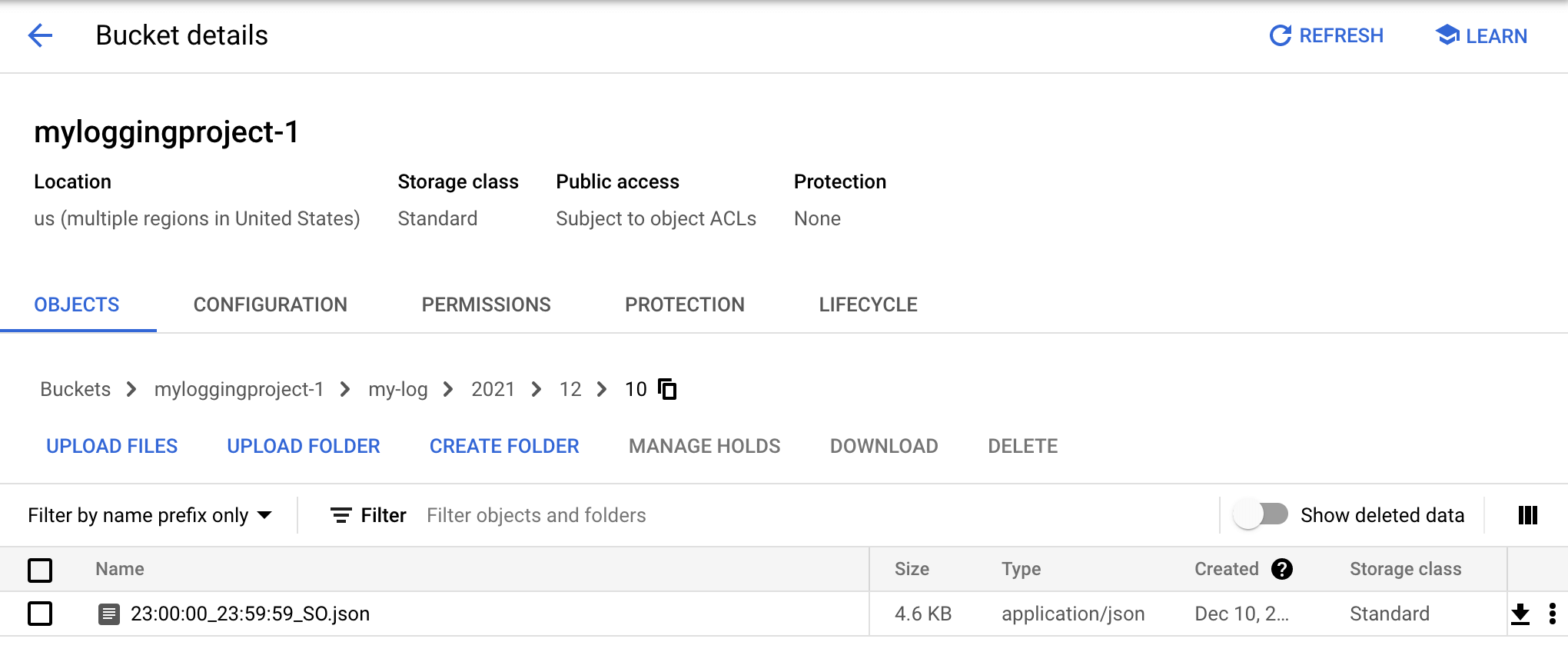
Le fichier JSON contient les entrées de journal exportées vers le bucket Cloud Storage. Cliquez sur le nom du fichier JSON pour afficher son contenu. Ce dernier devrait ressembler à ceci :
{"insertId":"yf1cshfoivz48", "logName":"projects/loggingproject-222616/logs/my-log", "receiveTimestamp":"2018-11-15T23:06:14.738729911Z", "resource":{"labels":{"project_id":"loggingproject-222616"},"type":"global"}, "severity":"ERROR", "textPayload":"Goodbye, world!", "timestamp":"2018-11-15T23:06:14.738729911Z"}Comme le niveau de gravité
ERRORest supérieur au niveau de gravitéINFO, l'entrée de journal contenant la chaîne "Goodbye, world!" est exportée vers la destination du récepteur. Les autres entrées de journal écrites ne sont pas exportées vers la destination, car leur niveau de gravité a été défini sur la valeur par défaut, qui est inférieure àINFO.
-
Dépannage
Un bucket Cloud Storage peut être vide pour plusieurs raisons :
Le bucket n'a pas reçu de données. Deux à trois heures peuvent s'écouler avant que les premières entrées ne s'affichent dans la destination ou que vous ne soyez averti d'une erreur de configuration. Pour en savoir plus, consultez Entrées de journal tardives.
Il y a une erreur de configuration. Dans ce cas, vous recevez un e-mail dont l'objet est semblable au texte suivant :
[ACTION REQUIRED] Logging export config error in myloggingproject.
Le problème de configuration est décrit dans le corps de l'e-mail. Par exemple, si vous ne mettez pas à jour vos autorisations de destination, l'e-mail répertorie le code d'erreur suivant :
bucket_permission_denied
Pour résoudre ce problème particulier, consultez la section Mettre à jour les autorisations de destination de la présente page.
Aucune entrée de journal n'a été écrite après la création du récepteur. Celui-ci ne s'applique qu'aux entrées de journal nouvellement arrivées. Pour remédier à cette situation, écrivez de nouvelles entrées de journal :
python snippets.py my-log write
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cette démonstration soient facturées sur votre compte Google Cloud , procédez comme suit :
(Facultatif) Supprimez les entrées de journal que vous avez créées. Si vous ne les supprimez pas, elles expireront et seront supprimées. Consultez la page Quotas et limites pour en savoir plus.
Pour supprimer toutes les entrées de journal dans
my-log, exécutez la commande suivante :python snippets.py my-log deleteSupprimez votre projet Google Cloud ou vos ressources de démarrage rapide.
Pour supprimer votre projet Google Cloud , dans le volet Informations sur le projet de la consoleGoogle Cloud , cliquez sur Accéder aux paramètres du projet, puis sur Arrêter.
Pour supprimer les ressources de démarrage rapide :
Supprimez le récepteur à l'aide de la commande suivante :
python export.py delete mysinkSupprimez le bucket Cloud Storage. Accédez à la console Google Cloud , puis cliquez sur Stockage > Buckets. Cochez la case à côté du nom du bucket, puis cliquez sur Supprimer.
Étape suivante
- Pour savoir comment lire, écrire et configurer des journaux à partir de vos applications, consultez la page API Cloud Logging.
- Pour en savoir plus sur l'explorateur de journaux, consultez Afficher les journaux à l'aide de l'explorateur de journaux.
- Pour savoir comment acheminer vos données de journaux vers des destinations compatibles, consultez la page Présentation du routage et du stockage.
- Pour savoir comment collecter des entrées de journal à partir de vos instances de VM, consultez la présentation de l'agent Ops.
- Pour en savoir plus sur l'audit et la conformité, consultez la présentation de Cloud Audit Logs.