이 페이지에서는 Cloud Logging에서 로그 기반 측정항목을 사용할 때 일반적으로 발생하는 상황에 대한 문제 해결 정보를 제공합니다.
측정항목을 보거나 만들 수 없음
로그 기반 측정항목은 단일 Google Cloud 프로젝트 또는 Google Cloud 프로젝트 내의 Logging 버킷에만 적용됩니다. 결제 계정이나 조직과 같은 기타 Google Cloud리소스에 대한 로그 기반 측정항목을 만들 수 없습니다. 로그 기반 측정항목은 로그를 수신한 Google Cloud 프로젝트 또는 버킷의 로그에 대해서만 계산됩니다.
측정항목을 만들려면 올바른 Identity and Access Management 권한이 필요합니다. 자세한 내용은 IAM으로 액세스 제어: 로그 기반 측정항목을 참조하세요.
측정항목에 로그 데이터가 없음
로그 기반 측정항목에 데이터가 누락되는 이유로는 다음 몇 가지가 있습니다.
새 로그 항목이 측정항목의 필터와 일치하지 않을 수 있습니다. 로그 기반 측정항목은 측정항목이 생성된 후에 수신되는 일치 로그 항목에서 데이터를 가져옵니다. Logging은 이전 로그 항목에서 측정항목을 백필하지 않습니다.
새 로그 항목에 올바른 필드가 포함되어 있지 않거나 데이터가 분산 측정항목의 추출에 맞는 올바른 형식으로 되어 있지 않을 수 있습니다. 필드 이름과 정규 표현식이 올바른지 확인하세요.
측정항목 카운트가 지연될 수 있습니다. 카운트 가능한 로그 항목이 로그 탐색기에 표시되더라도 Cloud Monitoring에서 로그 기반 측정항목을 업데이트하는 데 최대 10분이 걸릴 수 있습니다.
표시된 로그 항목의 타임스탬프가 너무 먼 과거나 미래 시점으로 되어 있어서 늦게 계수되거나 아예 계수되지 않을 수 있습니다. 로그 항목이 Cloud Logging에 의해 24시간 이전 또는 10분 후에 수신되는 경우 로그 항목은 로그 기반 측정항목에 계산되지 않습니다.
늦게 도착하는 항목 수는 로그 기반 측정항목인
logging.googleapis.com/logs_based_metrics_error_count에 기록됩니다.예: 로그 기반 측정항목과 일치하는 로그 항목이 늦게 도착합니다.
timestamp는 2020년 2월 20일 2:30 PM이고receivedTimestamp는 2020년 2월 21일 2:45 PM입니다. 이 항목은 로그 기반 측정항목에 포함되지 않습니다.로그 기반 측정항목은 측정항목에 계산될 수 있는 로그 항목이 도착한 이후에 생성되었습니다. 로그 기반 측정항목은 로그 버킷에 저장될 때 로그 항목을 평가합니다. 이러한 측정항목은 Logging에 저장된 로그 항목을 평가하지 않습니다.
로그 기반 측정항목에 데이터 격차가 있습니다. 로그 기반 측정항목 데이터를 처리하는 시스템은 모든 측정항목 데이터 포인트의 지속성을 보장하지 않기 때문에 일부 데이터 격차가 예상됩니다. 발생하는 격차는 일반적으로 드물고 짧습니다. 하지만 로그 기반 측정항목을 모니터링하는 알림 정책이 있으면 데이터 격차로 인해 거짓 알림이 발생할 수 있습니다. 알림 정책에 사용하는 설정으로 이러한 가능성을 줄일 수 있습니다.
예시: "하트비트" 로그 항목이 5분마다 기록되고 로그 기반 측정항목이 "하트비트" 로그 항목 수를 계산합니다. 알림 정책은 5분 간격으로 개수를 합산하고 합계가 1 미만이면 알림을 표시합니다. 시계열에 데이터 포인트가 누락되면 알림 정책이 최신 샘플의 복제본이고 대부분 0일 수 있는 합성 값을 주입한 후 조건을 평가합니다. 따라서 데이터 포인트 하나만 누락되어도 합산 값이 0이 되고, 이 알림 정책이 알림을 보낼 수 있습니다.
거짓 알림 위험을 줄이려면 "하트비트" 로그 항목을 하나만 계산하지 않고 여러 개 계산하도록 정책을 구성하세요.
Cloud Monitoring에서 리소스 유형이 '정의되지 않음'
일부 Cloud Logging 모니터링 리소스 유형은 Cloud Monitoring 모니터링 리소스 유형에 직접 매핑되지 않습니다. 예를 들어 로그 기반 측정항목에서 알림 정책이나 차트 중 하나를 처음 만들 때 리소스 유형이 '정의되지 않음'으로 표시될 수 있습니다.
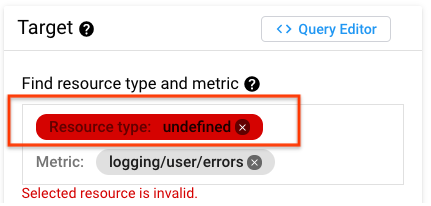
모니터링 리소스 유형은 global 또는 Cloud Monitoring의 다른 모니터링 리소스 유형 중 하나에 매핑됩니다. 어떤 모니터링 리소스 유형을 선택해야 할지 결정하려면 Logging 전용 리소스 매핑을 참조하세요.
알림의 라벨이 해결되지 않음
로그 기반 측정항목을 만든 다음 해당 로그 기반 측정항목을 모니터링하는 알림 정책을 만듭니다.
알림 정책의 문서 필드에서 ${log.extracted_label.KEY} 형식 변수를 사용하여 추출한 라벨을 참조합니다. 여기서 KEY는 추출된 라벨의 이름입니다. 알림에서 라벨이 해결되지 않습니다.
이 문제를 해결하려면 다음 중 한 가지를 따르세요.
추출된 라벨 콘텐츠를 문서에서 삭제합니다. 로그 기반 측정항목을 모니터링하는 알림 정책은 로그 항목에서 데이터를 추출할 수 없습니다.
로그 기반 알림을 만듭니다. 이러한 알림 정책은 알림 정책을 트리거하는 로그 항목에서 데이터를 추출할 수 있습니다.
이슈가 생성되지 않거나 거짓양성임
알림 정책의 정렬 기간이 너무 짧아서 Monitoring이 로그 기반 측정항목으로부터 이슈를 만들지 않는 거짓양성 이슈 또는 상황이 발생할 수 있습니다. 다음 시나리오에서 거짓양성이 발생할 수 있습니다.
- 알림 정책에 보다 작음 논리가 사용되는 경우
- 알림 정책이 배포 측정항목의 백분율 조건을 기반으로 하는 경우
- 측정항목 데이터에 격차가 있는 경우.
로그 항목이 Logging으로 늦게 전송될 수 있으므로 거짓양성 이슈가 발생할 수 있습니다. 예를 들어 로그 필드 timestamp 및 receiveTimestamp는 어떤 경우에 분 단위의 델타 값을 가질 수 있습니다. 또한 Logging이 로그를 로그 버킷에 저장할 때 로그 항목이 생성되는 시점과 Logging에서 수신하는 시점 사이에 내재된 지연이 있습니다. 즉, 로그 항목이 생성된 이후의 특정 시점까지 특정 로그 항목의 총 개수가 Logging에 없을 수 있습니다. 따라서 less than 논리를 사용하거나 분포 측정항목의 백분율 조건을 기반으로 하는 알림 정책은 거짓양성 알림을 생성할 수 있습니다. 아직 모든 로그 항목이 고려되지 않았기 때문입니다.
하지만 로그 기반 측정항목은 로그 기반 측정항목과 일치하는 로그 항목이 로그의 receiveTimestamp보다 훨씬 오래되거나 최신의 timestamp와 함께 Logging으로 전송되기 때문에 결국에는 eventual consistency를 가집니다.
즉, Logging이 동일한 타임 스탬프를 가진 기존 로그 항목을 수신한 후에 로그 기반 측정항목은 이전 타임 스탬프를 가진 로그 항목을 수신할 수 있습니다. 따라서 측정항목 값을 업데이트해야 합니다.
정시 데이터에 대해서도 알림 정확도를 유지하려면 조건의 정렬 기간을 최소 10분 이상으로 설정하는 것이 좋습니다. 특히 필터와 일치하는 여러 로그 항목이 계산되도록 이 값이 충분히 커야 합니다. 예를 들어 로그 기반 측정항목이 N분마다 예상되는 "하트비트" 로그 항목을 계산할 경우 정렬 기간을 2N분 또는 10분 중 더 큰 값으로 설정합니다.
Google Cloud 콘솔을 사용하는 경우 순환 기간 메뉴를 사용하여 정렬 기간을 설정합니다.
API를 사용하는 경우 조건의
aggregations.alignmentPeriod필드를 사용해서 정렬 기간을 설정합니다.
측정항목에 시계열이 너무 많음
측정항목 내 시계열의 개수는 여러 가지 라벨 값으로 구성된 조합의 개수에 따라 결정됩니다. 시계열 수는 측정항목의 카디널리티라고 하며 30,000을 초과해서는 안 됩니다.
모든 라벨 값 조합에 대해 시계열을 생성할 수 있으므로 값이 많은 라벨이 하나 이상이면 30,000개의 시계열을 어렵지 않게 초과할 수 있습니다. 카디널리티가 높은 측정항목은 피하는 것이 좋습니다.
측정항목의 카디널리티가 증가하면 측정항목이 제한되고 일부 데이터 포인트가 측정항목에 기록되지 않을 수 있습니다. 차트가 처리해야 하는 시계열 수가 많아서 측정항목을 표시하는 차트의 로드 속도가 느려질 수 있습니다. 또한 시계열 데이터를 쿼리하는 API 호출 비용이 발생할 수 있습니다. Google Cloud Observability 가격 책정 페이지의 Cloud Monitoring 섹션을 검토하세요.
카디널리티 측정항목이 많아지는 것을 피하려면 다음 안내를 따르세요.
라벨 필드와 추출기 정규 표현식이 제한된 카디널리티가 있는 값과 일치하는지 확인하세요.
예를 들어 라벨에 크기, 개수 또는 기간을 저장하지 마세요. 또한 URL, IP 주소 또는 고유 ID와 같은 필드를 저장하지 마세요. 이러한 필드로 인해 다수의 시계열이 생성될 수 있습니다.
경계가 없이 바뀔 수 있는 텍스트 메시지를 라벨 값으로 추출하지 마세요.
무한한 카디널리티가 있는 숫자 값을 추출하는 일을 삼가세요.
알려진 카디널리티 라벨(예: 일련의 알려진 값이 있는 상태 코드)에서만 값을 추출하세요.
이러한 시스템 로그 기반 측정항목을 사용하면 라벨 추가 또는 삭제가 측정항목의 카디널리티에 미치는 영향을 측정할 수 있습니다.
logging.googleapis.com/metric_throttledlogging.googleapis.com/time_series_countlogging.googleapis.com/metric_label_throttledlogging.googleapis.com/metric_label_cardinality
이러한 측정항목을 검사 할 때 측정항목 이름별로 결과를 더 필터링 할 수 있습니다. 자세한 내용은 측정항목 선택: 필터링을 참조하세요.
측정항목 이름이 잘못됨
카운터 또는 분포 측정항목을 만들 때 Google Cloud 프로젝트의 로그 기반 측정항목 중에서 고유한 측정항목 이름을 선택하세요.
측정항목 이름 문자열은 100자를 초과할 수 없으며 다음 문자만 포함할 수 있습니다.
A~Za~z0~9특수 문자
_-.,+!*',()%\/.슬래시 문자
/는 측정항목 이름 내 계층구조를 나타내며 이름의 첫 문자로 사용될 수 없습니다.
측정항목 값이 올바르지 않음
로그 기반 측정항목에 보고된 값이 로그 탐색기에서 보고한 로그 항목 수와 다른 경우가 있습니다.
불일치를 최소화하려면 다음을 수행합니다.
애플리케이션에서 중복 로그 항목을 전송하지 않는지 확인합니다. 로그 항목의
timestamp및insertId가 같으면 중복으로 간주됩니다. 로그 탐색기는 중복 로그 항목을 자동으로 숨깁니다. 하지만 로그 기반 측정항목은 측정항목의 필터와 일치하는 각 로그 항목을 계산합니다.타임스탬프가 이전 24시간 미만이거나 향후 10분 미만일 때 로그 항목이 Cloud Logging으로 전송되는지 확인합니다. 타임스탬프가 이 범위에 속하지 않는 로그 항목은 로그 기반 측정항목에서 계산되지 않습니다.
로그 중복 가능성을 배제할 수는 없습니다. 로그 항목 처리 중에 내부 오류가 발생하면 Cloud Logging에서 재시도 프로세스를 호출합니다. 재시도 프로세스로 인해 중복 로그 항목이 발생할 수 있습니다. 중복 로그 항목이 있으면 로그 기반 측정항목 값이 너무 클 수 있습니다. 이러한 측정항목은 측정항목의 필터와 일치하는 각 로그 항목을 계산하기 때문입니다.
라벨 값이 잘림
사용자 정의 라벨 값은 1,024바이트를 초과하면 안 됩니다.
커스텀 로그 측정항목을 삭제할 수 없음
Google Cloud 콘솔을 사용하여 커스텀 로그 기반 측정항목을 삭제하려고 합니다.
삭제 요청이 실패하고 삭제 대화상자에 오류 메시지 There is an unknown error while executing this operation이 표시됩니다.
이 문제를 해결하려면 다음을 시도해 보세요.
Google Cloud 콘솔에서 로그 기반 측정항목 페이지를 새로고칩니다. 내부 타이밍 문제로 인해 오류 메시지가 표시될 수 있습니다.
로그 기반 측정항목을 모니터링하는 모든 알림 정책을 식별하고 삭제합니다. 알림 정책에서 로그 기반 측정항목을 모니터링하지 않는지 확인한 후 로그 기반 측정항목을 삭제합니다. 알림 정책으로 모니터링되는 로그 기반 측정항목은 삭제할 수 없습니다.