부하 분산 옵션
애플리케이션에 전송되는 트래픽 유형에 따라 여러 가지 부하 분산 옵션이 있습니다. 다음은 옵션을 요약한 표입니다.
| 옵션 | 설명 | 트래픽 흐름 | 범위 |
|---|---|---|---|
| 외부 애플리케이션 부하 분산기 | HTTP(S) 트래픽과 URL 매핑 및 SSL 오프로드 등의 고급 기능 지원 특정 포트의 HTTP 외 트래픽에 외부 프록시 네트워크 부하 분산기 사용 |
TCP 또는 SSL(TLS) 세션은 Google 네트워크 에지의 Google 프런트엔드(GFE)에서 종료되고 트래픽이 백엔드로 프록시 처리됩니다. | 전역 |
| 외부 패스 스루 네트워크 부하 분산기 | 포트를 사용하는 TCP/UDP 트래픽이 부하 분산기를 통과하도록 허용합니다. | Google의 Maglev 기술을 사용해 트래픽을 백엔드에 배포합니다. | 리전 |
내부 부하 분산기와 Cloud Service Mesh는 사용자 대상 트래픽을 지원하지 않으므로 이 문서에서는 다루지 않습니다.
전역 부하 분산에 이 서비스 등급이 필요하므로 이 문서의 측정에서는 네트워크 서비스 등급의 프리미엄 등급을 사용합니다.
지연 시간 측정
독일의 한 사용자가 us-central1에서 호스팅되는 웹사이트에 액세스할 때 다음과 같은 방법으로 지연 시간을 테스트합니다.
- 핑: ICMP 핑은 일반적인 서버 연결 가능성을 측정하는 일반적인 방법이지만 ICMP 핑은 최종 사용자 지연 시간을 측정하지 않습니다. 자세한 내용은 외부 애플리케이션 부하 분산기의 추가 지연 시간 효과를 참조하세요.
- Curl: Curl은 첫 바이트 소요 시간(TTFB)을 측정합니다.
curl명령어를 서버에 반복해서 실행하세요.
결과를 비교해 보면 광섬유 링크의 지연 시간은 주로 광섬유의 거리와 광신호 속도의 제한을 받으며 약 200,000km/초(또는 124,724마일/초)라는 사실을 알 수 있습니다.
독일의 프랑크푸르트와 아이오와의 카운슬 블러프스(us-central1 리전) 사이의 거리는 약 7,500km입니다. 두 위치 간에 직선 광섬유를 사용할 경우 왕복 지연 시간은 다음과 같습니다.
7,500 km * 2 / 200,000 km/s * 1000 ms/s = 75 milliseconds (ms)
광섬유 케이블은 사용자와 데이터 센터 간의 직선 경로를 따르지 않습니다. 이 경로를 따라 광섬유의 광신호가 능동 및 수동 장비를 통과합니다. 이상적인 지연 시간의 약 1.5배 또는 112.5ms에 해당하는 지연 시간이 관찰되었으며 이는 이상적인 구성에 가깝습니다.
지연 시간 비교
이 섹션에서는 다음 구성의 부하 분산을 비교합니다.
- 부하 분산 없음
- 외부 패스 스루 네트워크 부하 분산기
- 외부 애플리케이션 부하 분산기 또는 외부 프록시 네트워크 부하 분산기
이 시나리오의 애플리케이션은 HTTP 웹 서버의 리전 관리형 인스턴스 그룹으로 구성되어 있습니다. 이 애플리케이션에서는 지연 시간이 짧은 중앙 데이터베이스 호출을 사용하기 때문에 웹 서버를 한 위치에서 호스팅해야 합니다. 애플리케이션은 us-central1 리전에 배포되며 사용자는 전 세계에 분산됩니다. 이 시나리오에서는 독일 사용자에게 발생한 지연 시간을 전 세계 사용자가 경험할 수 있음을 보여줍니다.

부하 분산 없음
사용자가 HTTP 요청을 하면 부하 분산이 구성되지 않는 한 트래픽이 사용자의 네트워크에서 Compute Engine에 호스팅된 가상 머신(VM)으로 직접 이동합니다. 프리미엄 등급의 경우 트래픽은 사용자의 위치와 가까운 에지 지점(PoP)의 Google 네트워크로 들어갑니다. 표준 등급의 경우 사용자 트래픽이 대상 리전과 가까운 PoP의 Google 네트워크로 들어갑니다. 자세한 내용은 네트워크 서비스 등급 문서를 참조하세요.
{kind=link}

다음 표에서는 독일 사용자가 부하 분산 없이 시스템의 지연 시간을 테스트한 결과를 보여줍니다.
| 메서드 | 결과 | 최소 지연 시간 |
|---|---|---|
| VM IP 주소 핑(웹 서버에서 직접 응답) |
ping -c 5 compute-engine-vm PING compute-engine-vm (xxx.xxx.xxx.xxx) 56(84) bytes of data. 64 bytes from compute-engine-vm (xxx.xxx.xxx.xxx): icmp_seq=1 ttl=56 time=111 ms 64 bytes from compute-engine-vm (xxx.xxx.xxx.xxx): icmp_seq=2 ttl=56 time=110 ms [...] --- compute-engine-vm ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4004ms rtt min/avg/max/mdev = 110.818/110.944/111.265/0.451 ms |
110ms |
| TTFB |
for ((i=0; i < 500; i++)); do curl -w /
"%{time_starttransfer}\n" -o /dev/null -s compute-engine-vm; done
0.230 0.230 0.231 0.231 0.230 [...] 0.232 0.231 0.231 |
230ms |
처음 500개의 요청을 보여주는 다음 그래프에서 알 수 있듯이 TTFB 지연 시간은 안정적입니다.
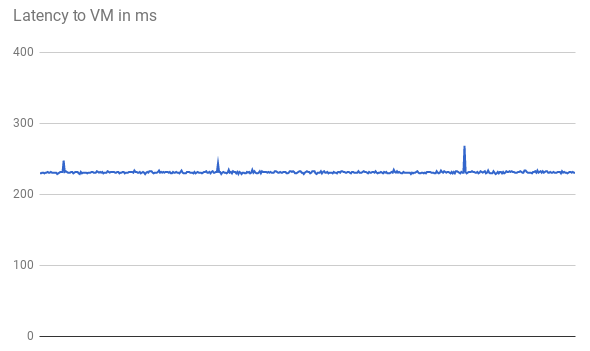
VM IP 주소를 핑하면 웹 서버에서 직접 응답합니다. 웹 서버로부터의 응답 시간은 네트워크 지연 시간(TTFB)에 비해 매우 짧습니다. 모든 HTTP 요청에 새 TCP 연결이 열려 있기 때문입니다. 다음 다이어그램과 같이 HTTP 응답이 전송되기 전에 초기 3방향 핸드셰이크가 필요합니다. 따라서 관찰된 지연 시간은 핑 지연 시간의 약 두 배입니다.

외부 패스 스루 네트워크 부하 분산기
외부 패스 스루 네트워크 부하 분산기를 사용하면 사용자 요청이 여전히 가장 가까운 에지 PoP의 Google 네트워크로 들어갑니다(프리미엄 등급). 프로젝트의 VM이 있는 리전에서 트래픽은 먼저 외부 패스 스루 네트워크 부하 분산기를 통과합니다. 그리고 나서 대상 백엔드 VM에 그대로 전달됩니다. 외부 패스 스루 네트워크 부하 분산기는 안정적인 해싱 알고리즘을 기반으로 트래픽을 분산합니다. 이 알고리즘은 소스 및 대상 포트, IP 주소, 프로토콜의 조합을 사용합니다. VM에서 부하 분산기 IP를 수신 대기하고 변경되지 않은 트래픽을 허용합니다.

다음 표에서는 독일 사용자가 네트워크 부하 분산 옵션의 지연 시간을 테스트한 결과를 보여줍니다.
| 메서드 | 결과 | 최소 지연 시간 |
|---|---|---|
| 외부 패스 스루 네트워크 부하 분산기 핑 |
ping -c 5 net-lb PING net-lb (xxx.xxx.xxx.xxx) 56(84) bytes of data. 64 bytes from net-lb (xxx.xxx.xxx.xxx): icmp_seq=1 ttl=44 time=110 ms 64 bytes from net-lb (xxx.xxx.xxx.xxx): icmp_seq=2 ttl=44 time=110 ms [...] 64 bytes from net-lb (xxx.xxx.xxx.xxx): icmp_seq=5 ttl=44 time=110 ms --- net-lb ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4007ms rtt min/avg/max/mdev = 110.658/110.705/110.756/0.299 ms |
110ms |
| TTFB |
for ((i=0; i < 500; i++)); do curl -w /
"%{time_starttransfer}\n" -o /dev/null -s net-lb
0.231 0.232 0.230 0.230 0.232 [...] 0.232 0.231 |
230ms |
부하 분산은 리전 내에서 발생하며 트래픽은 단순히 전달되므로 부하 분산기가 없는 것에 비해 지연 시간 영향이 미미합니다.
외부 부하 분산
외부 애플리케이션 부하 분산기를 사용하면 GFE가 트래픽을 프록시 처리합니다. 이러한 GFE는 Google의 전역 네트워크 에지에 있습니다. GFE는 TCP 세션을 종료하고 트래픽을 처리할 수 있는 가장 가까운 리전의 백엔드에 연결합니다.

다음 표에서는 독일 사용자가 HTTP 부하 분산 옵션의 지연 시간을 테스트한 결과를 보여줍니다.
| 메서드 | 결과 | 최소 지연 시간 |
|---|---|---|
| 외부 애플리케이션 부하 분산기 핑 |
ping -c 5 http-lb PING http-lb (xxx.xxx.xxx.xxx) 56(84) bytes of data. 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=1 ttl=56 time=1.22 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=2 ttl=56 time=1.20 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=3 ttl=56 time=1.16 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=4 ttl=56 time=1.17 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=5 ttl=56 time=1.20 ms --- http-lb ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4005ms rtt min/avg/max/mdev = 1.163/1.195/1.229/0.039 ms |
1ms |
| TTFB |
for ((i=0; i < 500; i++)); do curl -w /
"%{time_starttransfer}\n" -o /dev/null -s http-lb; done
0.309 0.230 0.229 0.233 0.230 [...] 0.123 0.124 0.126 |
123ms |
외부 애플리케이션 부하 분산기의 결과는 상당히 다릅니다. 외부 애플리케이션 부하 분산기를 핑할 경우 왕복 지연 시간은 1ms를 약간 초과합니다. 이 결과는 사용자와 동일한 도시에 있는 가장 가까운 GFE의 지연 시간을 나타냅니다. 이 결과에는 us-central1 리전에서 호스팅되는 애플리케이션에 액세스하려고 할 때 사용자가 경험하는 실제 지연 시간이 반영되지 않습니다. 애플리케이션 통신 프로토콜(HTTP)과 다른 프로토콜(ICMP)을 사용하는 실험은 오해의 소지가 있을 수 있습니다.
TTFB를 측정할 경우 초기 요청에서는 거의 비슷한 응답 지연 시간이 발생합니다. 일부 요청은 다음 그래프와 같이 123ms의 낮은 최소 지연 시간을 보입니다.
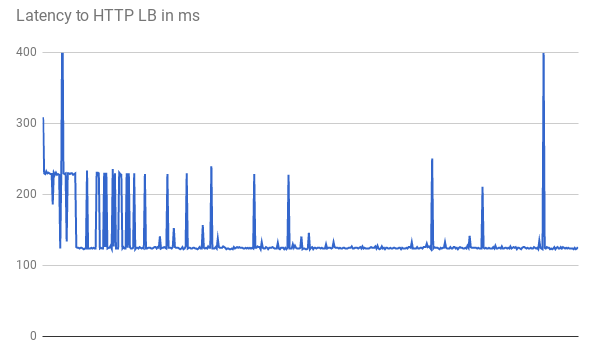
직선 광섬유를 사용해도 클라이언트와 VM 간의 2회 왕복에 123ms 넘게 걸립니다. GFE가 트래픽을 프록시 처리하므로 지연 시간이 줄어듭니다. GFE는 백엔드 VM에 대한 지속적인 연결을 유지합니다. 따라서 특정 백엔드에 대한 특정 GFE의 첫 번째 요청에 한해 3방향 핸드셰이크가 필요합니다.
각 위치에는 GFE가 여러 개 있습니다. 지연 시간 그래프에서는 트래픽이 각 GFE-백엔드 쌍에 처음 도달할 때 급격하게 증가하는 여러 형태를 보여줍니다. 그런 다음 GFE는 백엔드에 대한 새 연결을 설정해야 합니다. 이러한 급증은 요청 해시 차이를 반영합니다. 이후 요청에서는 지연 시간이 짧습니다.

이 시나리오는 사용자가 프로덕션 환경에서 경험할 수 있는 감소된 지연 시간을 보여줍니다. 다음은 그 결과를 요약한 표입니다.
| 옵션 | 핑 | TTFB |
|---|---|---|
| 부하 분산 없음 | 웹 서버까지 110ms | 230ms |
| 외부 패스 스루 네트워크 부하 분산기 | 리전 내 외부 패스 스루 네트워크 부하 분산기까지 110ms | 230ms |
| 외부 애플리케이션 부하 분산기 | 가장 가까운 GFE까지 1ms | 123ms |
정상적인 애플리케이션에서 특정 리전의 사용자에게 서비스를 제공하는 경우 해당 리전의 GFE는 모든 제공 중인 백엔드에 지속적인 연결을 유지합니다. 따라서 해당 리전의 사용자가 애플리케이션 백엔드와 멀리 떨어져 있는 경우 첫 번째 HTTP 요청의 지연 시간이 줄어듭니다. 사용자가 애플리케이션 백엔드 근처에 있는 경우 사용자는 지연 시간 개선을 알아채지 못합니다.
페이지 링크 클릭과 같은 후속 요청의 경우 최신 브라우저에서 서비스에 대한 영구 연결을 유지하므로 지연 시간이 개선되지 않습니다. 이는 명령줄에서 실행된 curl 명령어와 다릅니다.
외부 애플리케이션 부하 분산기의 추가 지연 시간 효과
외부 애플리케이션 부하 분산기에서 관찰 가능한 추가 효과는 트래픽 패턴에 따라 다릅니다.
외부 애플리케이션 부하 분산기는 외부 패스 스루 네트워크 부하 분산기에 비해 응답이 완료되기 전에 필요한 왕복 횟수가 적기 때문에 복잡한 애셋에 대한 지연 시간이 짧습니다. 예를 들어 독일에 있는 사용자가 10MB 파일을 반복적으로 다운로드하여 동일한 연결에서 지연 시간을 측정하는 경우 외부 패스 스루 네트워크 부하 분산기의 평균 지연 시간은 1,911ms입니다. 외부 애플리케이션 부하 분산기를 사용할 경우 평균 지연 시간은 1,341ms이므로 이렇게 하면 요청당 약 5회의 왕복이 절약됩니다. GFE와 제공 백엔드 간의 영구 연결은 TCP 느린 시작의 효과를 감소시킵니다.
외부 애플리케이션 부하 분산기는 TLS 핸드셰이크(일반적으로 1~2회 추가 왕복)의 추가 지연 시간을 크게 줄여줍니다. 이는 외부 애플리케이션 부하 분산기가 SSL 오프로드를 사용하고 에지 PoP의 지연 시간만 관련성이 있기 때문입니다. 독일 사용자의 경우 외부 패스 스루 네트워크 부하 분산기를 통해 HTTP(S)를 사용할 경우 525ms가 기록된 것에 반해 외부 애플리케이션 부하 분산기로 최소 지연 시간 201ms를 얻었습니다.
외부 애플리케이션 부하 분산기를 사용하면 사용자 대상 세션을 HTTP/2로 자동 업그레이드할 수 있습니다. HTTP/2에서는 개선된 바이너리 프로토콜, 헤더 압축, 연결 다중화 기능 사용하여 필요한 패킷 수를 줄일 수 있습니다. 이러한 개선사항으로 인해 외부 애플리케이션 부하 분산기로 전환할 때보다 관찰되는 지연 시간이 훨씬 줄어듭니다. HTTP/2는 SSL/TLS를 사용하는 현재 브라우저에서 지원됩니다. 독일 사용자의 경우 HTTPS 대신 HTTP/2를 사용할 경우 최소 지연 시간이 201ms에서 145ms로 더욱 단축되었습니다.
외부 애플리케이션 부하 분산기 최적화
다음과 같이 외부 애플리케이션 부하 분산기를 사용하면 애플리케이션 지연 시간을 최적화할 수 있습니다.
제공하는 트래픽 중 일부를 캐시할 수 있으면 Cloud CDN과 통합할 수 있습니다. Cloud CDN은 Google의 네트워크 에지에서 애셋을 직접 제공하여 지연 시간을 줄여줍니다. Cloud CDN은 외부 애플리케이션 부하 분산기의 추가 지연 시간 효과 섹션에 언급된 HTTP/2의 TCP 및 HTTP 최적화도 사용합니다.
Google Cloud와 함께 모든 CDN 파트너를 사용할 수 있습니다. Google의 CDN Interconnect 파트너 중 하나를 이용하면 데이터 전송 비용을 할인 받을 수 있습니다.
콘텐츠가 정적인 경우 외부 애플리케이션 부하 분산기를 통해 Cloud Storage에서 직접 콘텐츠를 제공하여 웹 서버의 로드를 줄일 수 있습니다. 이 옵션은 Cloud CDN과 결합됩니다.
부하 분산기는 자동으로 사용자를 가장 가까운 리전에 연결하므로 사용자 근처의 여러 리전에 웹 서버를 배치하면 지연 시간을 줄일 수 있습니다. 하지만 애플리케이션이 부분적으로 중앙 집중화된 경우 리전 간 왕복 횟수가 줄어들도록 설계해야 합니다.
애플리케이션 내부의 지연 시간을 줄이려면 VM 간에 통신하는 RPC(리모트 프로시져 콜)를 검사하세요. 일반적으로 애플리케이션에서 계층 또는 서비스 간에 통신할 때 이러한 지연 시간이 발생합니다. Cloud Trace와 같은 도구를 사용하면 애플리케이션 제공 요청으로 인한 지연 시간을 줄일 수 있습니다.
외부 프록시 네트워크 부하 분산기는 GFE를 기반으로 하므로 지연 시간 효과는 외부 애플리케이션 부하 분산기에서 관찰된 효과와 같습니다. 외부 애플리케이션 부하 분산기에는 외부 프록시 네트워크 부하 분산기보다 많은 기능이 있으므로 HTTP(S) 트래픽에 외부 애플리케이션 부하 분산기를 사용하는 것이 좋습니다.
다음 단계
대부분의 사용자 가까이에 애플리케이션을 배포하는 것이 좋습니다.Google Cloud의 다양한 부하 분산 옵션에 대한 자세한 내용은 다음 문서를 참조하세요.