負荷分散のオプション
アプリケーションに送信されるトラフィックの種類に応じて、利用できる外部ロード バランシングのオプションが決まります。次の表に、オプションをまとめます。
| オプション | 説明 | トラフィック フロー | スコープ |
|---|---|---|---|
| 外部アプリケーション ロードバランサ | HTTP(S) トラフィックと、URL マッピングや SSL オフロードなどの高度な機能をサポートします。 HTTP 以外の特定のポートのトラフィックには、外部プロキシ ネットワーク ロードバランサを使用します。 |
TCP または SSL(TLS)セッションは、Google ネットワーク エッジの Google Front End(GFE)で終了し、トラフィックはバックエンドにプロキシされます。 | グローバル |
| 外部パススルー ネットワーク ロードバランサ | 任意のポートを使用して TCP / UDP トラフィックがロードバランサを通過するようにします。 | Google の Maglev テクノロジーを使用して提供され、バックエンドにトラフィックを配信します。 | リージョン |
内部ロードバランサと Cloud Service Mesh はユーザー向けのトラフィックをサポートしていないため、この記事では対象としません。
グローバル ロード バランシングではこのサービスティアが必要になるため、この記事の測定では Network Service Tiers のプレミアム ティアを使用します。
レイテンシの測定
あるドイツのユーザーが us-central1 でホストされているウェブサイトにアクセスしている場合、レイテンシをテストするには次の方法を使用します。
- ping: ICMP ping はサーバーの到達可能性を測定する一般的な方法ですが、エンドユーザーのレイテンシを測定するものではありません。詳細については、外部アプリケーション ロードバランサのその他のレイテンシ効果をご覧ください。
- Curl: 最初のバイトまでの時間(TTFB)を測定します。サーバーに
curlコマンドを繰り返し発行します。
結果を比較する際には、ファイバー リンク上のレイテンシは、距離とファイバー内の光の速度(約 200,000 km/秒、124,724 マイル/秒)によって制約されることに注意してください。
ドイツのフランクフルトと、アイオワ州カウンシル ブラフス(us-central1 リージョン)との距離は約 7,500 km です。これらのロケーション間にまっすぐなファイバーがある場合、ラウンドトリップ レイテンシは次のとおりです。
7,500 km * 2 / 200,000 km/s * 1000 ms/s = 75 milliseconds (ms)
光ファイバー ケーブルは、ユーザーとデータセンターの間で直接的につながっているわけではありません。ファイバー ケーブル上の光は、その経路に沿ってアクティブおよびパッシブ機器を通過します。観察されたレイテンシは理想値の約 1.5 倍、すなわち 112.5 ミリ秒であり、ほぼ理想的な構成を示します。
レイテンシの比較
このセクションでは、次の構成でのロード バランシングを比較します。
- ロード バランシングなし
- 外部パススルー ネットワーク ロードバランサ
- 外部アプリケーション ロードバランサまたは外部プロキシ ネットワーク ロードバランサ
このシナリオでは、アプリケーションは、HTTP ウェブサーバーのリージョンのマネージド インスタンス グループで構成されます。アプリケーションは中央データベースへのレイテンシの少ない呼び出しに依存しているため、ウェブサーバーは 1 か所でホストされなければなりません。アプリケーションは us-central1 リージョンにデプロイされ、ユーザーは世界中に分散しています。このシナリオでドイツのユーザーが観測するレイテンシは、世界中のユーザーが経験する可能性がある内容を示しています。

ロード バランシングなし
ユーザーが HTTP リクエストを行うと、ロード バランシングが構成されていない限り、トラフィックはユーザーのネットワークから Compute Engine でホストされている仮想マシン(VM)に直接流れます。プレミアム ティアの場合、トラフィックはユーザーの場所に近いエッジのポイント オブ プレゼンス(PoP)で Google のネットワークに入ります。スタンダード ティアの場合、ユーザー トラフィックは宛先リージョンに近い PoP で Google のネットワークに入ります。詳細については、Network Service Tiers のドキュメントをご覧ください。
{kind=link}

次の表は、ドイツのユーザーがロード バランシングのないシステムのレイテンシをテストした結果を示しています。
| メソッド | 結果 | 最小レイテンシ |
|---|---|---|
| VM の IP アドレスを ping します(レスポンスはウェブサーバーから直接取得されます)。 |
ping -c 5 compute-engine-vm PING compute-engine-vm (xxx.xxx.xxx.xxx) 56(84) bytes of data. 64 bytes from compute-engine-vm (xxx.xxx.xxx.xxx): icmp_seq=1 ttl=56 time=111 ms 64 bytes from compute-engine-vm (xxx.xxx.xxx.xxx): icmp_seq=2 ttl=56 time=110 ms [...] --- compute-engine-vm ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4004ms rtt min/avg/max/mdev = 110.818/110.944/111.265/0.451 ms |
110 ms |
| TTFB |
for ((i=0; i < 500; i++)); do curl -w /
"%{time_starttransfer}\n" -o /dev/null -s compute-engine-vm; done
0.230 0.230 0.231 0.231 0.230 [...] 0.232 0.231 0.231 |
230 ms |
最初の 500 リクエストの次のグラフが示すように、TTFB レイテンシは安定しています。
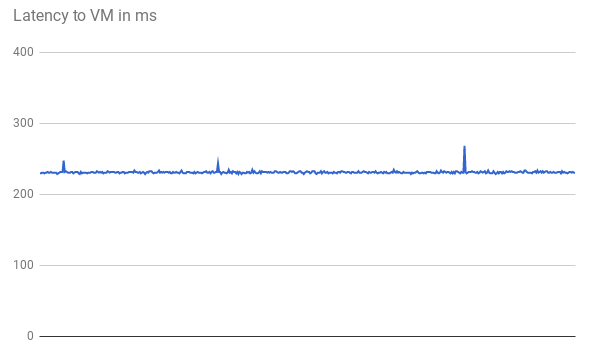
VM IP アドレスに ping を実行すると、レスポンスはウェブサーバーから直接返されます。ウェブサーバーからのレスポンス時間は、ネットワーク レイテンシ(TTFB)と比較した場合ごくわずかです。これは、HTTP リクエストごとに新しい TCP 接続が開かれるためです。次の図に示すように、HTTP レスポンスを送信するには、最初に 3 方向の handshake が必要です。そのため、観測するレイテンシは ping のレイテンシの約 2 倍になります。

外部パススルー ネットワーク ロードバランサ
外部パススルー ネットワーク ロードバランサの場合、ユーザー リクエストは最も近いエッジ PoP(プレミアム ティア)で Google ネットワークに入ります。プロジェクトの VM が配置されているリージョンでは、最初にトラフィックが外部パススルー ネットワーク ロードバランサを通過します。変更が加わることなくターゲット バックエンド VM に転送されます。外部パススルー ネットワーク ロードバランサは、安定したハッシュ アルゴリズムに基づいてトラフィックを分散します。このアルゴリズムでは、送信元ポート、宛先ポート、IP アドレス、プロトコルを組み合わせて使用します。VM はロードバランサ IP をリッスンし、変更されていないトラフィックを受け入れます。

次の表は、ドイツのユーザーがネットワーク ロード バランシング オプションのレイテンシをテストしたときの結果を示しています。
| メソッド | 結果 | 最小レイテンシ |
|---|---|---|
| 外部パススルー ネットワーク ロードバランサに ping する |
ping -c 5 net-lb PING net-lb (xxx.xxx.xxx.xxx) 56(84) bytes of data. 64 bytes from net-lb (xxx.xxx.xxx.xxx): icmp_seq=1 ttl=44 time=110 ms 64 bytes from net-lb (xxx.xxx.xxx.xxx): icmp_seq=2 ttl=44 time=110 ms [...] 64 bytes from net-lb (xxx.xxx.xxx.xxx): icmp_seq=5 ttl=44 time=110 ms --- net-lb ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4007ms rtt min/avg/max/mdev = 110.658/110.705/110.756/0.299 ms |
110 ms |
| TTFB |
for ((i=0; i < 500; i++)); do curl -w /
"%{time_starttransfer}\n" -o /dev/null -s net-lb
0.231 0.232 0.230 0.230 0.232 [...] 0.232 0.231 |
230 ms |
負荷分散はリージョン内で行われ、トラフィックが転送されるだけであるため、ロードバランサがない場合と比べてレイテンシに大きな影響はありません。
外部ロード バランシング
外部アプリケーション ロードバランサでは、GFE がトラフィックをプロキシします。これらの GFE は、Google のグローバル ネットワークのエッジにあります。GFE は TCP セッションを終了し、トラフィックを処理できる最も近いリージョンのバックエンドに接続します。

次の表は、ドイツのユーザーが HTTP ロード バランシング オプションのレイテンシをテストしたときの結果を示しています。
| メソッド | 結果 | 最小レイテンシ |
|---|---|---|
| 外部アプリケーション ロードバランサに ping する |
ping -c 5 http-lb PING http-lb (xxx.xxx.xxx.xxx) 56(84) bytes of data. 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=1 ttl=56 time=1.22 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=2 ttl=56 time=1.20 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=3 ttl=56 time=1.16 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=4 ttl=56 time=1.17 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=5 ttl=56 time=1.20 ms --- http-lb ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4005ms rtt min/avg/max/mdev = 1.163/1.195/1.229/0.039 ms |
1 ミリ秒 |
| TTFB |
for ((i=0; i < 500; i++)); do curl -w /
"%{time_starttransfer}\n" -o /dev/null -s http-lb; done
0.309 0.230 0.229 0.233 0.230 [...] 0.123 0.124 0.126 |
123 ミリ秒 |
外部アプリケーション ロードバランサの結果は大きく異なります。外部アプリケーション ロードバランサに ping すると、ラウンドトリップ レイテンシは 1 ミリ秒をわずかに超えます。この結果は、ユーザーと同じ都市にある最も近い GFE までのレイテンシを表します。この結果では、us-central1 リージョンでホストされているアプリケーションにアクセスしようとしたときに実際にユーザーが体験するレイテンシが反映されません。ご使用のアプリケーション通信プロトコル(HTTP)と異なるプロトコル(ICMP)を使用した実験によって、誤解を招く可能性があります。
TTFB を測定する場合、最初のリクエストは同様のレスポンス レイテンシを示します。次のグラフに示すように、一部のリクエストは低い最小レイテンシ(123 ミリ秒)を達成しています。
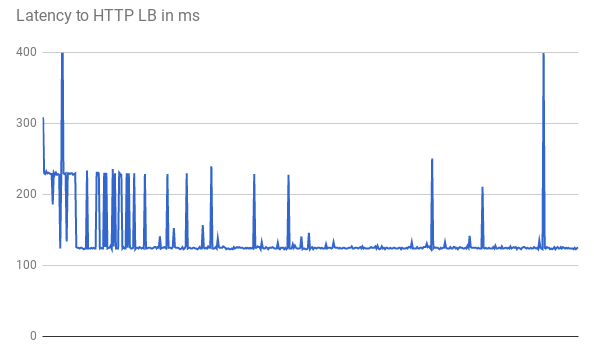
クライアントと VM 間の 2 回のラウンド トリップには、直線的なファイバーであっても 123 ミリ秒を超える時間を要しています。GFE がトラフィックをプロキシするため、レイテンシは短くなります。GFE はバックエンド VM への永続的な接続を維持します。したがって、特定の GFE から特定のバックエンドへの最初のリクエストだけが、3-way handshake を必要とします。
各ロケーションには複数の GFE があります。レイテンシ グラフを見ると、トラフィックが各 GFE とバックエンドのペアに初めて到達するときに、複数の変動するスパイクを確認できます。次に、GFE はそのバックエンドへの新しい接続を確立する必要があります。これらのスパイクは、さまざまなリクエスト ハッシュを反映しています。後続のリクエストでは、レイテンシは短くなります。

これらのシナリオは、本番環境でユーザーが経験する可能性のあるレイテンシの短縮を示しています。次の表に結果をまとめます。
| オプション | Ping | TTFB |
|---|---|---|
| ロード バランシングなし | ウェブサーバーに 110 ms | 230 ms |
| 外部パススルー ネットワーク ロードバランサ | インリージョン外部パススルー ネットワーク ロードバランサまで 110 ms | 230 ms |
| 外部アプリケーション ロードバランサ | 最も近い GFE まで 1 ms | 123 ms |
正常なアプリケーションが特定のリージョンのユーザーにサービスを提供する場合、そのリージョン内の GFE は、すべての処理バックエンドに対して永続的な接続を維持します。このため、ユーザーがアプリケーションのバックエンドから離れている場合、その地域のユーザーは最初の HTTP リクエストのレイテンシが短くなります。ユーザーがアプリケーション バックエンドの近くにいる場合、そのユーザーはレイテンシが改善したことを把握できません。
最新のブラウザはサービスへの永続的な接続を維持しているため、ページリンクのクリックなど、後続のリクエストではレイテンシの改善はありません。これは、コマンドラインから発行される curl コマンドとは異なります。
外部アプリケーション ロードバランサのその他のレイテンシ効果
外部アプリケーション ロードバランサで観測可能なその他の影響はトラフィック パターンによって異なります。
外部アプリケーション ロードバランサは、レスポンスが完了する前に必要なラウンド トリップが少ないため、複雑なアセットに対するレイテンシが外部パススルー ネットワーク ロードバランサよりも少なくなります。たとえば、ドイツのユーザーが 10 MB のファイルを繰り返しダウンロードして同じ接続のレイテンシを測定した場合、外部パススルー ネットワーク ロードバランサの平均のレイテンシは 1,911 ミリ秒です。外部アプリケーション ロードバランサの平均レイテンシは 1,341 ミリ秒です。そのため、リクエストごとに約 5 回のラウンド トリップが削減されます。GFE とサービス バックエンド間の永続的な接続により、TCP スロースタートの影響が軽減されます。
外部アプリケーション ロードバランサは、TLS handshake によって追加されるレイテンシ(通常、1~2 回の追加ラウンドトリップ)を大幅に削減します。これは、外部アプリケーション ロードバランサが SSL オフロードを使用し、エッジ PoP のレイテンシのみが関係するためです。ドイツのユーザーの場合、外部アプリケーション ロードバランサを使用したときに観察される最小レイテンシは 201 ミリ秒ですが、外部パススルー ネットワーク ロードバランサを介した HTTP(S) では 525 ミリ秒になります。
外部アプリケーション ロードバランサを使用すると、ユーザー向けのセッションを HTTP/2 に自動アップグレードできます。HTTP/2 では、バイナリ プロトコル、ヘッダー圧縮、接続多重化の改善により、必要なパケット数を減らすことができます。これらの改善により、観測されるレイテンシを外部アプリケーション ロードバランサに切り替えた場合よりもさらに短縮できます。HTTP/2 は、SSL / TLS を使用する現在のブラウザでサポートされています。ドイツのユーザーの場合、HTTPS の代わりに HTTP/2 を使用すると、最小レイテンシが 201 ミリ秒から 145 ミリ秒に短縮されました。
外部アプリケーション ロードバランサの最適化
外部アプリケーション ロードバランサを使用すると、次のようにアプリケーションのレイテンシを最適化できます。
提供するトラフィックの一部がキャッシュに保存できる場合は、Cloud CDN と統合できます。Cloud CDN は、Google のネットワーク エッジで直接アセットを提供することで、レイテンシを短縮します。Cloud CDN では、外部アプリケーション ロードバランサのその他のレイテンシ効果で説明されている HTTP/2 の TCP 最適化と HTTP 最適化も使用されます。
任意の CDN パートナーを Google Cloudと併用できます。Google の CDN Interconnect パートナーのいずれかを使用することで、データ転送料金の割引を受けることができます。
コンテンツが静的な場合は、外部アプリケーション ロードバランサを介して Cloud Storage から直接コンテンツを提供することで、ウェブサーバーの負荷を軽減できます。このオプションは、Cloud CDN と組み合わせて使用します。
ユーザーに近い複数のリージョンにウェブサーバーを配置すると、ロードバランサが自動的に最も近いリージョンにユーザーを誘導するため、レイテンシーを減らすことができます。ただし、アプリケーションの一部が集中管理されている場合は、リージョン間の往復を抑えるようにアプリケーションを設計します。
アプリケーション内のレイテンシを短縮するには、VM 間で通信するすべてのリモート プロシージャ コール(RPC)を調べます。このレイテンシは通常、アプリケーションが階層間またはサービス間で通信する場合に発生します。Cloud Trace などのツールを使用すると、アプリケーションの処理リクエストに起因するレイテンシを短縮できます。
外部プロキシ ネットワーク ロードバランサは GFE に基づいているため、レイテンシに及ぼす影響は外部アプリケーション ロードバランサで観察されるものと同じになります。外部アプリケーション ロードバランサには外部プロキシ ネットワーク ロードバランサよりも多くの機能があるため、HTTP(S) トラフィックには外部アプリケーション ロードバランサを使用することをおすすめします。
次のステップ
ほとんどのユーザーの近くにアプリケーションをデプロイすることをおすすめします。Google Cloudでのさまざまなロード バランシング オプションの詳細については、次のドキュメントをご覧ください。