대부분의 부하 분산기는 순차 순환 대기 또는 흐름 기반 해시 방식을 사용하여 트래픽을 분산시킵니다. 이 방식을 사용하는 부하 분산기는 트래픽 수요가 사용 가능한 제공 용량을 초과하는 경우 적용이 어려울 수 있습니다. 이 가이드에서는 Cloud Load Balancing으로 글로벌 애플리케이션 용량을 최적화하는 방법을 보여줍니다. 이렇게 하면 대부분의 부하 분산 구현에 비해 사용자 환경이 향상되고 비용이 절감됩니다.
이 문서는 Cloud Load Balancing 제품에 대한 권장사항 시리즈의 일부입니다. 이 튜토리얼은 전역 부하 분산 오버플로의 기본 메커니즘을 자세히 설명하는 개념 자료인 전역 부하 분산을 사용한 애플리케이션 용량 최적화와 함께 제공됩니다. 지연 시간에 대해 자세히 알아보려면 Cloud Load Balancing으로 애플리케이션 지연 시간 최적화를 참조하세요.
이 가이드에서는 여러분이 Compute Engine을 사용해 본 경험이 있다고 간주합니다. 외부 애플리케이션 부하 분산기 기본사항도 잘 알고 있어야 합니다.
목표
이 가이드에서는 망델브로 집합을 계산하는 CPU 집약적인 애플리케이션을 실행하는 간단한 웹 서버를 설정합니다. 먼저 부하 테스트 도구(siege 및 httperf)를 사용하여 네트워크 용량을 측정합니다. 그런 다음, 네트워크를 단일 지역의 여러 VM 인스턴스로 확장하고 부하 발생 시 응답 시간을 측정합니다. 마지막으로 글로벌 부하 분산을 사용하여 네트워크를 여러 지역으로 확장한 다음 부하 발생 시 서버의 응답 시간을 측정하고 단일 지역 부하 분산과 비교합니다. 이와 같은 일련의 테스트를 수행하면 Cloud Load Balancing의 지역 간 부하 관리를 사용할 경우 얻을 수 있는 긍정적인 효과를 확인할 수 있습니다.
일반적인 3 계층 서버 아키텍처의 네트워크 통신 속도는 대개 웹 서버의 CPU 부하가 아닌 애플리케이션 서버 속도나 데이터베이스 용량으로 제한됩니다. 이 튜토리얼을 실행한 후에는 같은 부하 테스트 도구와 용량 설정을 사용하여 실제 애플리케이션의 부하 분산 동작을 최적화할 수 있습니다.
실습할 내용은 다음과 같습니다.
- 부하 테스트 도구(
siege및httperf) 사용 방법을 알아봅니다. - 단일 VM 인스턴스의 서비스 용량을 결정합니다.
- 단일 지역 부하 분산으로 과부하의 영향을 측정합니다.
- 글로벌 부하 분산으로 다른 지역에 대한 오버플로의 영향을 측정합니다.
비용
이 튜토리얼에서는 비용이 청구될 수 있는 Google Cloud구성요소를 사용합니다.
- Compute Engine
- 부하 분산 및 전달 규칙
가격 계산기를 사용하면 예상 사용량을 기준으로 예상 비용을 산출할 수 있습니다.
시작하기 전에
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
환경 설정
이 섹션에서는 튜토리얼을 완료하는 데 필요한 프로젝트 설정, VPC 네트워크, 기본 방화벽 규칙을 구성합니다.
Cloud Shell 인스턴스 시작
Google Cloud 콘솔에서 Cloud Shell을 엽니다. 별도로 설명되어 있지 않으면 가이드의 나머지 내용을 Cloud Shell 내에서 실행합니다.
프로젝트 설정값 구성
gcloud 명령어를 보다 쉽게 실행하려면 각 명령어마다 속성에 대한 옵션을 제공할 필요가 없도록 속성을 설정하면 됩니다.
[PROJECT_ID]에 프로젝트 ID를 사용하여 기본 프로젝트를 설정합니다.gcloud config set project [PROJECT_ID]
[ZONE]에 선호 영역을 사용하여 기본 Compute Engine 영역을 설정한 다음 나중에 사용할 수 있도록 환경 변수로 설정합니다.gcloud config set compute/zone [ZONE] export ZONE=[ZONE]
VPC 네트워크 생성 및 구성
테스트할 VPC 네트워크를 만듭니다.
gcloud compute networks create lb-testing --subnet-mode auto
내부 트래픽을 허용하는 방화벽 규칙을 정의합니다.
gcloud compute firewall-rules create lb-testing-internal \ --network lb-testing --allow all --source-ranges 10.128.0.0/11SSH 트래픽이 VPC 네트워크와 통신할 수 있도록 방화벽 규칙을 정의합니다.
gcloud compute firewall-rules create lb-testing-ssh \ --network lb-testing --allow tcp:22 --source-ranges 0.0.0.0/0
단일 VM 인스턴스의 서비스 용량 결정
VM 인스턴스 유형의 성능 특성을 검사하려면 다음을 수행합니다.
워크로드 예시(웹 서버 인스턴스)로 제공할 VM 인스턴스를 설정합니다.
같은 영역에 두 번째 VM 인스턴스(부하 테스트 인스턴스)를 만듭니다.
두 번째 VM 인스턴스를 사용하면 간단한 부하 테스트 및 성능 측정 도구를 사용하여 성능을 측정할 수 있습니다. 이 가이드의 뒷부분에서 이 측정값을 사용하여 인스턴스 그룹의 올바른 부하 분산 용량 설정을 정의할 수 있습니다.
첫 번째 VM 인스턴스는 Python 스크립트를 사용하여 루트(/) 경로로 들어오는 각 요청에 대해 망델브로 집합을 계산하여 그림으로 표시하는 CPU 집약적인 작업을 만듭니다. 결과는 캐시되지 않습니다. 이 튜토리얼에서는 이 솔루션에 사용되는 GitHub 저장소에서 Python 스크립트를 가져옵니다.
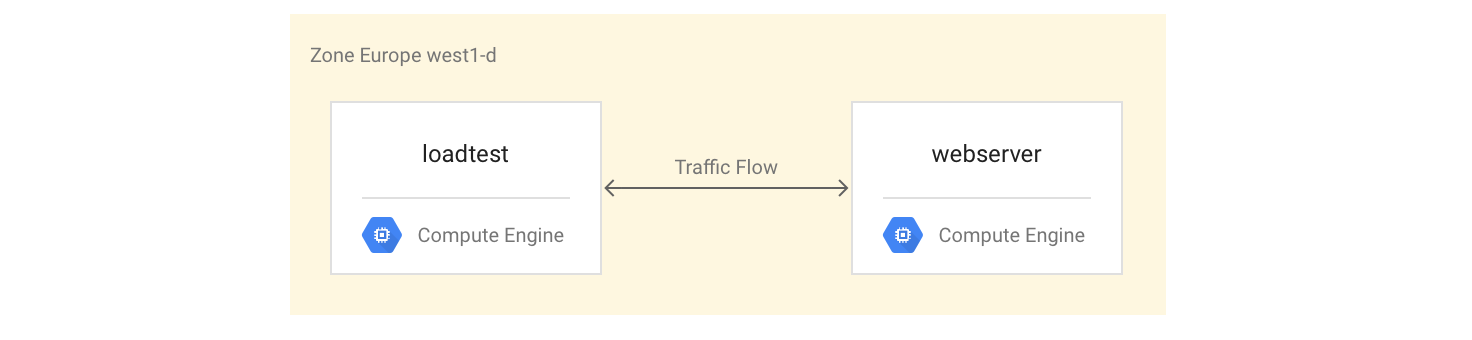
VM 인스턴스 설정
망델브로 서버를 설치하고 시작하여
webserverVM 인스턴스를 4코어 VM 인스턴스로 설정합니다.gcloud compute instances create webserver --machine-type n1-highcpu-4 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud --tags=http-server \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'자체 머신에서
webserver인스턴스에 대한 외부 액세스를 허용하는 방화벽 규칙을 만듭니다.gcloud compute firewall-rules create lb-testing-http \ --network lb-testing --allow tcp:80 --source-ranges 0.0.0.0/0 \ --target-tags http-serverwebserver인스턴스의 IP 주소를 가져옵니다.gcloud compute instances describe webserver \ --format "value(networkInterfaces[0].accessConfigs[0].natIP)"웹브라우저에서 위의 명령어로 반환된 IP 주소로 이동합니다. 계산된 망델브로 집합이 표시됩니다.
부하 테스트 인스턴스를 만듭니다.
gcloud compute instances create loadtest --machine-type n1-standard-1 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud
VM 인스턴스 테스트
다음 단계에서는 부하 테스트 VM 인스턴스의 성능 특성을 측정하는 요청을 실행합니다.
ssh명령어를 사용하여 부하 테스트 VM 인스턴스에 연결합니다.gcloud compute ssh loadtest
부하 테스트 인스턴스에 siege 및 httperf를 부하 테스트 도구로 설치합니다.
sudo apt-get install -y siege httperf
siege도구를 사용하면 지정된 수의 사용자 요청을 시뮬레이션하여 사용자가 응답을 수신한 후에만 후속 요청을 수행할 수 있습니다. 이렇게 하면 실제 환경에서 애플리케이션의 용량 및 예상 응답 시간을 파악할 수 있습니다.httperf도구를 사용하면 응답 또는 오류가 수신되었는지 여부와 상관없이 초당 특정 수의 요청을 보낼 수 있습니다. 그러면 애플리케이션이 특정 부하에 응답하는 방법을 파악할 수 있습니다.웹 서버에 대한 간단한 요청 시간을 측정합니다.
curl -w "%{time_total}\n" -o /dev/#objectives_2 -s webserver0.395260과 같은 응답을 받게 됩니다. 이는 서버가 요청에 응답하는 데 395밀리초(ms)가 걸렸음을 의미합니다.
다음 명령어를 사용하여 사용자 4명의 요청 20개를 동시에 실행합니다.
siege -c 4 -r 20 webserver
다음과 비슷한 출력이 표시됩니다.
** SIEGE 4.0.2 ** Preparing 4 concurrent users for battle. The server is now under siege... Transactions: 80 hits Availability: 100.00 % Elapsed time: 14.45 secs Data transferred: 1.81 MB Response time: 0.52 secs Transaction rate: 5.05 trans/sec Throughput: 0.12 MB/sec Concurrency: 3.92 Successful transactions: 80 Failed transactions: 0 **Longest transaction: 0.70 Shortest transaction: 0.37 **
출력은 siege 매뉴얼에 자세하게 설명되어 있지만 이 예에서 응답 시간이 0.37초에서 0.7초 사이로 다양하다는 것을 확인할 수 있습니다. 평균적으로 초당 5.05건의 요청이 응답되었습니다. 이 데이터를 사용하면 시스템의 제공 용량을 예측할 수 있습니다.
다음 명령어를 실행하여
httperf부하 테스트 도구를 사용하여 결과를 검증합니다.httperf --server webserver --num-conns 500 --rate 4
이 명령어는
siege가 완료한 초당 5.05개의 트랜잭션보다 적은 초당 요청 4개의 비율로 요청 500개를 실행합니다.다음과 비슷한 출력이 표시됩니다.
httperf --client=0/1 --server=webserver --port=80 --uri=/ --rate=4 --send-buffer=4096 --recv-buffer=16384 --num-conns=500 --num-calls=1 httperf: warning: open file limit > FD_SETSIZE; limiting max. # of open files to FD_SETSIZE Maximum connect burst length: 1 Total: connections 500 requests 500 replies 500 test-duration 125.333 s Connection rate: 4.0 conn/s (251.4 ms/conn, <=2 concurrent connections) **Connection time [ms]: min 369.6 avg 384.5 max 487.8 median 377.5 stddev 18.0 Connection time [ms]: connect 0.3** Connection length [replies/conn]: 1.000 Request rate: 4.0 req/s (251.4 ms/req) Request size [B]: 62.0 Reply rate [replies/s]: min 3.8 avg 4.0 max 4.0 stddev 0.1 (5 samples) Reply time [ms]: response 383.8 transfer 0.4 Reply size [B]: header 117.0 content 24051.0 footer 0.0 (total 24168.0) Reply status: 1xx=0 2xx=100 3xx=0 4xx=0 5xx=0 CPU time [s]: user 4.94 system 20.19 (user 19.6% system 80.3% total 99.9%) Net I/O: 94.1 KB/s (0.8*10^6 bps) Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
출력에 대한 설명은 httperf README 파일에 나와 있습니다.
Connection time [ms]로 시작되는 행을 확인합니다. 이 행은 연결에 총 369.6~487.8밀리초가 걸렸으며 생성된 오류가 없음을 보여줍니다.rate옵션을 초당 요청 5, 7, 10개로 설정하여 테스트를 3번 반복합니다.다음 블록은
httperf명령어와 출력(연결 시간 정보와 관련된 행만 표시)을 보여줍니다.초당 요청 5개에 대한 명령어:
httperf --server webserver --num-conns 500 --rate 5 2>&1| grep 'Errors\|ion time'
초당 요청 5개에 대한 결과:
Connection time [ms]: min 371.2 avg 381.1 max 447.7 median 378.5 stddev 7.2 Connection time [ms]: connect 0.2 Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
초당 요청 7개에 대한 명령어:
httperf --server webserver --num-conns 500 --rate 7 2>&1| grep 'Errors\|ion time'
초당 요청 7개에 대한 결과:
Connection time [ms]: min 373.4 avg 11075.5 max 60100.6 median 8481.5 stddev 10284.2 Connection time [ms]: connect 654.9 Errors: total 4 client-timo 0 socket-timo 0 connrefused 0 connreset 4 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
초당 요청 10개에 대한 명령어:
httperf --server webserver --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
초당 요청 10개에 대한 결과:
Connection time [ms]: min 374.3 avg 18335.6 max 65533.9 median 10052.5 stddev 16654.5 Connection time [ms]: connect 181.3 Errors: total 32 client-timo 0 socket-timo 0 connrefused 0 connreset 32 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
webserver인스턴스에서 로그아웃합니다.exit
이 측정값을 통해 시스템의 용량이 초당 요청 5개(RPS)라고 결론지을 수 있습니다. 초당 요청이 5개인 경우 VM 인스턴스는 연결 4개와 비슷한 지연 시간으로 반응합니다. 초당 연결이 7개 및 10개인 경우 여러 연결 오류로 인해 평균 응답 시간이 10초 이상으로 크게 증가합니다. 즉, 초당 요청 5개를 초과하면 심각한 속도 저하가 발생합니다.
더 복잡한 시스템에서는 서버 용량이 비슷한 방식으로 결정되지만 모든 구성요소의 용량에 따라 크게 달라집니다. siege 및 httperf 도구를 모든 구성요소(예: 프런트엔드 서버, 애플리케이션 서버, 데이터베이스 서버)의 CPU 및 I/O 부하 모니터링과 함께 사용하면 병목 현상을 식별할 수 있습니다. 이렇게 하면 각 구성요소에 대한 최적의 확장을 지원할 수 있게 됩니다.
단일 리전 부하 분산기로 과부하 영향 측정
이 섹션에서는 온프레미스에 사용되는 일반적인 부하 분산기 또는 Google Cloud외부 패스 스루 네트워크 부하 분산기와 같은 단일 리전 부하 분산기에 대한 과부하의 영향을 살펴봅니다. 부하 분산기를 글로벌이 아닌 리전 배포에 사용하는 경우에도 HTTP(S) 부하 분산기에서 이 영향을 확인할 수 있습니다.
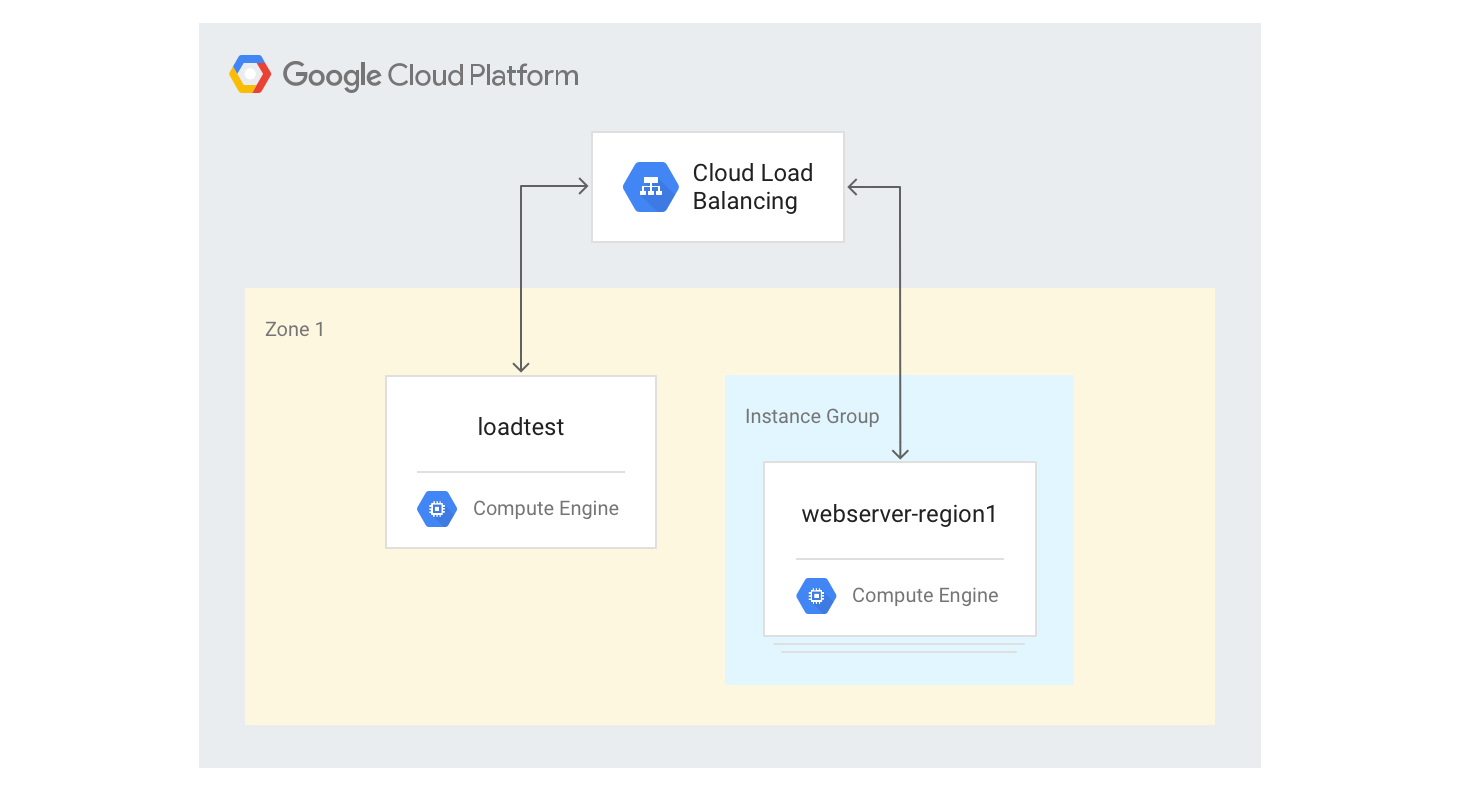
단일 리전 HTTP(S) 부하 분산기 만들기
다음 단계에서는 크기가 고정된 VM 인스턴스 3개가 있는 단일 지역 HTTP(S) 부하 분산기를 만드는 방법을 설명합니다.
이전에 사용한 Python Mandelbrot 생성 스크립트를 사용하여 웹 서버 VM 인스턴스의 인스턴스 템플릿을 만듭니다. Cloud Shell에서 다음 명령어를 실행합니다.
gcloud compute instance-templates create webservers \ --machine-type n1-highcpu-4 \ --image-family=debian-12 --image-project=debian-cloud \ --tags=http-server \ --network=lb-testing \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'이전 단계의 템플릿을 기반으로 인스턴스가 3개 있는 관리형 인스턴스 그룹을 만듭니다.
gcloud compute instance-groups managed create webserver-region1 \ --size=3 --template=webserversHTTP 부하 분산을 생성하는 데 필요한 상태 점검, 백엔드 서비스, URL 맵, 대상 프록시, 전역 전달 규칙을 만듭니다.
gcloud compute health-checks create http basic-check \ --request-path="/health-check" --check-interval=60s gcloud compute backend-services create web-service \ --health-checks basic-check --global gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE gcloud compute url-maps create web-map --default-service web-service gcloud compute target-http-proxies create web-proxy --url-map web-map gcloud compute forwarding-rules create web-rule --global \ --target-http-proxy web-proxy --ports 80전달 규칙의 IP 주소를 가져옵니다.
gcloud compute forwarding-rules describe --global web-rule --format "value(IPAddress)"
출력은 생성한 부하 분산기의 공개 IP 주소입니다.
브라우저에서 이전 명령어가 반환한 IP 주소로 이동합니다. 몇 분 후에 이전에 확인한 것과 같은 망델브로 그림이 표시됩니다. 하지만 이번에는 새로 생성된 그룹의 VM 인스턴스 중 하나에서 이미지가 제공됩니다.
loadtest머신에 로그인합니다.gcloud compute ssh loadtest
loadtest머신의 명령줄에서 여러 초당 요청 수(RPS)로 서버 응답을 테스트합니다. 적어도 5~20RPS 값을 사용해야 합니다.예를 들어 다음 명령어는 10RPS를 생성합니다.
[IP_address]를 이 절차의 앞 단계에서 가져온 부하 분산기의 IP 주소로 바꿉니다.httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
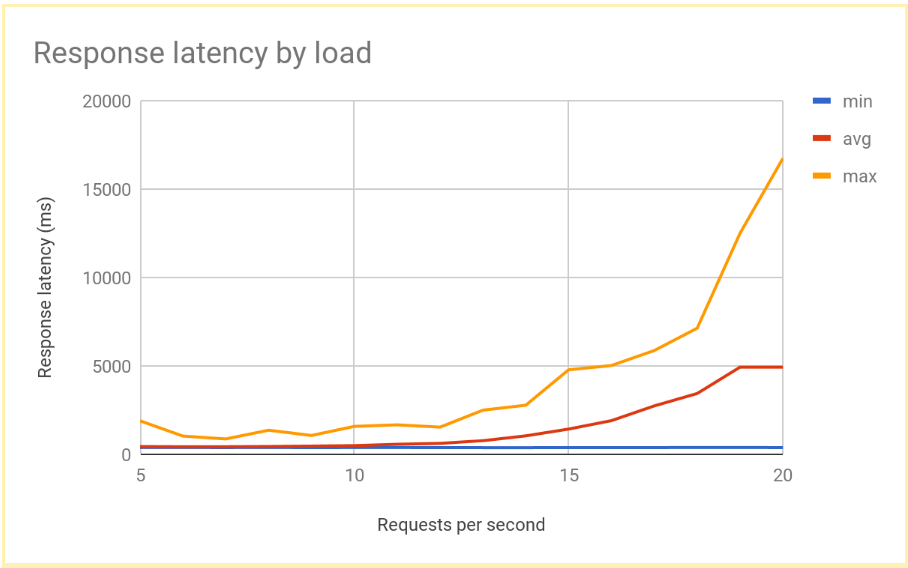
RPS가 12 또는 13을 초과하면 응답 지연 시간이 크게 증가합니다. 다음은 일반적인 결과를 시각화한 것입니다.
loadtestVM 인스턴스에서 로그아웃합니다.exit
이는 리전별로 부하가 분산된 시스템에서 일반적인 성능입니다. 부하가 제공 용량을 초과하여 증가하면 평균 및 최대 요청 지연 시간도 급격히 증가합니다. 10RPS의 경우 평균 요청 지연 시간은 500밀리초에 가깝지만 20RPS의 경우 지연 시간은 5,000밀리초입니다. 지연 시간이 10배 증가하고 사용자 환경이 급격히 악화되면 사용자 이탈 또는 애플리케이션 시간 초과가 발생하거나 두 가지가 모두 발생합니다.
다음 섹션에서는 부하 분산 토폴로지에 두 번째 리전을 추가하고 리전 간 장애 조치가 최종 사용자 지연 시간에 어떤 영향을 미치는지 비교해 보겠습니다.
다른 리전에 대한 오버플로 영향 측정
외부 애플리케이션 부하 분산기와 함께 전역 애플리케이션을 사용하고 여러 지역에 백엔드를 배포한 경우 단일 지역에서 용량 과부하가 발생하면 트래픽이 자동으로 다른 지역으로 이동합니다. 이전 섹션에서 만든 구성에 다른 리전의 두 번째 VM 인스턴스 그룹을 추가하여 이를 검증할 수 있습니다.
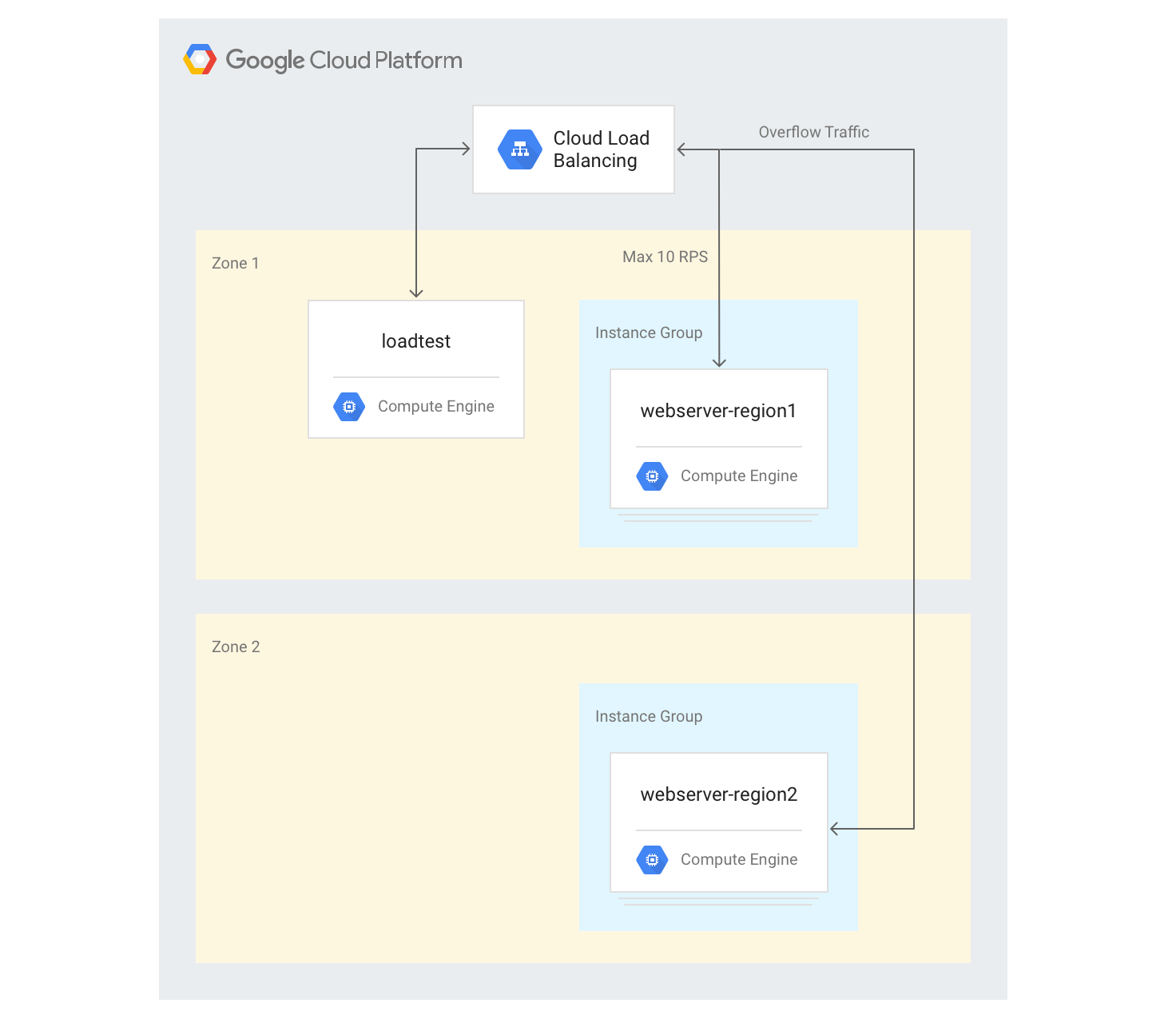
여러 리전에서 서버 만들기
다음 단계에서는 다른 지역에 또 다른 백엔드 그룹을 추가하고 지역마다 10RPS의 용량을 할당합니다. 그런 다음 이 한도를 초과하면 부하 분산이 어떻게 반응하는지 확인할 수 있습니다.
Cloud Shell에서 기본 영역과 다른 지역의 영역을 선택하여 환경 변수로 설정합니다.
export ZONE2=[zone]
VM 인스턴스 3개를 사용하여 두 번째 지역에 새 인스턴스 그룹을 만듭니다.
gcloud compute instance-groups managed create webserver-region2 \ --size=3 --template=webservers --zone $ZONE2기존 백엔드 서비스에 최대 용량이 10RPS인 인스턴스 그룹을 추가합니다.
gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region2 \ --instance-group-zone $ZONE2 --max-rate 10기존 백엔드 서비스에 대한
max-rate를 10RPS로 조정합니다.gcloud compute backend-services update-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE --max-rate 10모든 인스턴스가 부팅된 후
loadtestVM 인스턴스에 로그인합니다.gcloud compute ssh loadtest
10RPS로 500개의 요청을 실행합니다.
[IP_address]를 부하 분산기의 IP 주소로 바꿉니다.httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'ion time'
결과는 다음과 같이 표시됩니다.
Connection time [ms]: min 405.9 avg 584.7 max 1390.4 median 531.5 stddev 181.3 Connection time [ms]: connect 1.1
결과는 지역 부하 분산기에서 생성된 것과 유사합니다.
테스트 도구가 전체 부하를 즉시 실행하고 실제 구현과 같이 부하가 서서히 증가하지 않으므로 오버플로 메커니즘을 적용하려면 테스트를 두 번 반복해야 합니다. 20RPS로 500개의 요청을 다섯 번 실행합니다.
[IP_address]를 부하 분산기의 IP 주소로 바꿉니다.for a in \`seq 1 5\`; do httperf --server [IP_address] \ --num-conns 500 --rate 20 2>&1| grep 'ion time' ; done결과는 다음과 같이 표시됩니다.
Connection time [ms]: min 426.7 avg 6396.8 max 13615.1 median 7351.5 stddev 3226.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 417.2 avg 3782.9 max 7979.5 median 3623.5 stddev 2479.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 411.6 avg 860.0 max 3971.2 median 705.5 stddev 492.9 Connection time [ms]: connect 0.7 Connection time [ms]: min 407.3 avg 700.8 max 1927.8 median 667.5 stddev 232.1 Connection time [ms]: connect 0.7 Connection time [ms]: min 410.8 avg 701.8 max 1612.3 median 669.5 stddev 209.0 Connection time [ms]: connect 0.8
시스템이 안정화된 후 평균 응답 시간은 10RPS에서 400밀리초이고 20RPS인 경우에만 700밀리초로 증가합니다. 이는 지역 부하 분산기가 제공하는 5,000밀리초 지연보다 크게 개선된 결과이며 훨씬 향상된 사용자 환경을 제공합니다.
다음 그래프는 글로벌 부하 분산을 사용하여 측정한 응답 시간(RPS)을 보여줍니다.
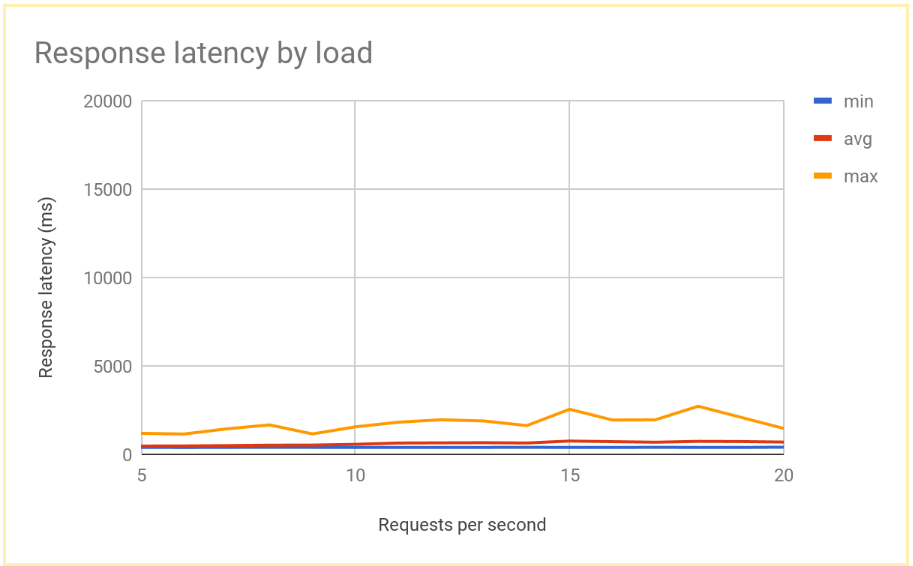
리전 및 전역 부하 분산 결과 비교
단일 노드의 용량을 설정한 후에는 지역 기반 배포에서 최종 사용자가 관찰한 지연 시간과 글로벌 부하 분산 아키텍처의 지연 시간을 비교할 수 있습니다. 단일 지역에 대한 요청 수가 해당 지역의 총 제공 용량보다 낮지만 사용자가 항상 가장 가까운 지역으로 리디렉션되므로 두 시스템의 최종 사용자 지연 시간은 비슷합니다.
한 지역에 대한 부하가 해당 지역의 제공 용량을 초과하면 솔루션 간 최종 사용자 지연 시간이 크게 달라집니다.
트래픽이 과부하된 백엔드 VM 인스턴스로만 이동할 수 있기 때문에 트래픽이 용량을 초과하여 증가하면 지역 부하 분산 솔루션에 과부하가 발생합니다. 여기에는 기존 온프레미스 부하 분산기, Google Cloud의 외부 패스 스루 네트워크 부하 분산기, 단일 리전 구성에서 외부 애플리케이션 부하 분산기(예: 표준 등급 네트워킹 사용)가 포함됩니다. 평균 및 최대 요청 지연 시간은 10배 이상의 단위로 증가하므로 사용자 환경이 악화되어 심각한 사용자 이탈로 이어질 수 있습니다.
여러 지역의 백엔드를 사용하는 전역 외부 애플리케이션 부하 분산기를 사용하면 사용 가능한 용량이 있는 가장 가까운 지역으로 트래픽을 오버플로할 수 있습니다. 그러면 최종 사용자 지연 시간이 체감은 되지만 비교적 낮은 수준으로 증가하므로 사용자 환경이 훨씬 개선됩니다. 애플리케이션을 지역에서 빠르게 확장할 수 없는 경우 권장되는 옵션은 전역 외부 애플리케이션 부하 분산기입니다. 사용자 애플리케이션 서버의 지역 전체에서 오류가 발생해도 트래픽이 다른 지역으로 빠르게 리디렉션되므로 전체 서비스 중단을 방지하는 데 도움이 됩니다.
삭제
프로젝트 삭제
비용이 청구되지 않도록 하는 가장 쉬운 방법은 튜토리얼에서 만든 프로젝트를 삭제하는 것입니다.
프로젝트를 삭제하는 방법은 다음과 같습니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
다음 페이지에서는 Google의 부하 분산 옵션에 대한 자세한 정보와 배경을 제공합니다.
- Cloud Load Balancing을 통한 애플리케이션 지연 시간 최적화
- 네트워킹 기초 Codelab
- 외부 패스 스루 네트워크 부하 분산기
- 외부 애플리케이션 부하 분산기
- 외부 프록시 네트워크 부하 분산기