BigQuery
Utilisez le connecteur BigQuery pour effectuer des opérations d'insertion, de suppression, de mise à jour et de lecture sur des données Google BigQuery. Vous pouvez également exécuter des requêtes SQL personnalisées sur des données BigQuery. Vous pouvez utiliser le connecteur BigQuery pour intégrer des données provenant de plusieurs services Google Cloud ou d'autres services tiers, tels que Cloud Storage ou Amazon S3.
Avant de commencer
Dans votre projet Google Cloud, effectuez les tâches suivantes :
- Assurez-vous que la connectivité réseau est configurée. Pour en savoir plus sur les schémas de réseau, consultez Connectivité réseau.
- Attribuez le rôle IAM roles/connectors.admin à l'utilisateur qui configure le connecteur.
- Attribuez le rôle IAM
roles/bigquery.dataEditorau compte de service que vous souhaitez utiliser pour le connecteur. - Activez les services suivants :
secretmanager.googleapis.com(API Secret Manager)connectors.googleapis.com(API Connectors)
Pour comprendre comment activer des services, consultez Activer des services. Si ces services ou autorisations n'ont pas encore été activés pour votre projet, vous êtes invité à les activer au moment de configurer le connecteur.
Créer une connexion BigQuery
Une connexion est propre à une source de données. Cela signifie que si vous disposez de nombreuses sources de données, vous devez créer une connexion distincte pour chacune d'elles. Pour créer une connexion, procédez comme suit :
- Dans la console Cloud, accédez à la page Connecteurs d'intégration > Connexions, puis sélectionnez ou créez un projet Google Cloud.
- Cliquez sur + CRÉER pour ouvrir la page Créer une connexion.
- Dans la section Emplacement, sélectionnez un emplacement dans la liste Région, puis cliquez sur SUIVANT.
Pour obtenir la liste de toutes les régions disponibles, consultez Emplacements.
- Dans la section Détails de connexion, procédez comme suit :
- Sélectionnez BigQuery dans la liste Connecteur.
- Sélectionnez une version de connecteur dans la liste Version du connecteur.
- Dans le champ Nom de connexion, indiquez le nom de l'instance de connexion. Le nom de la connexion peut contenir des lettres minuscules, des chiffres ou des traits d'union. Il doit commencer par une lettre et se terminer par une lettre ou un chiffre. Il ne doit pas dépasser 49 caractères.
- (Facultatif) Activez Cloud Logging, puis sélectionnez un niveau de journalisation. Par défaut, le niveau de journalisation est défini sur
Error. - Compte de service : sélectionnez un compte de service disposant des rôles requis.
- (Facultatif) Configurez les paramètres de nœuds de connexion.
- Nombre minimal de nœuds : saisissez le nombre minimal de nœuds de connexion.
- Nombre maximal de nœuds : saisissez le nombre maximal de nœuds de connexion.
- ID du projet : ID du projet Google Cloud dans lequel se trouvent les données.
- ID de l'ensemble de données : ID de l'ensemble de données BigQuery.
- Pour prendre en charge le type de données Array de BigQuery, sélectionnez Accepter les types de données natifs. Les types de tableaux suivants sont acceptés : Varchar, Int64, Float64, Long, Double, Bool et Timestamp. Les tableaux imbriqués ne sont pas pris en charge.
- (Facultatif) Pour configurer un serveur proxy pour la connexion, sélectionnez Utiliser un proxy, puis saisissez les détails du proxy.
-
Schéma d'authentification du proxy : sélectionnez le type d'authentification pour l'authentification auprès du serveur proxy. Les types d'authentification suivants sont compatibles :
- De base : authentification HTTP de base.
- Digest : authentification HTTP Digest.
- Utilisateur du proxy : nom d'utilisateur permettant de s'authentifier auprès du serveur proxy.
- Mot de passe du proxy : secret Secret Manager du mot de passe de l'utilisateur.
-
Type SSL du proxy : type SSL à utiliser lors de la connexion au serveur proxy. Les types d'authentification suivants sont compatibles :
- Auto : paramètre par défaut. Dans le cas d'une URL HTTPS, l'option "Tunnel" est utilisée. Dans le cas d'une URL HTTP, l'option "Jamais" est utilisée.
- Toujours : le protocole SSL est toujours activé pour la connexion.
- Jamais : le protocole SSL n'est pas activé pour la connexion.
- Tunnel : la connexion s'effectue avec un proxy de tunnelisation. Le serveur proxy ouvre une connexion à l'hôte distant et le trafic transite par le proxy.
- Dans la section Serveur proxy, saisissez les détails du serveur proxy.
- Cliquez sur + Ajouter une destination.
- Sélectionnez un type de destination.
- Adresse de l'hôte : spécifiez le nom d'hôte ou l'adresse IP de la destination.
Si vous souhaitez établir une connexion privée à votre système backend, procédez comme suit :
- Créez un rattachement de service PSC.
- Créez un rattachement de point de terminaison, puis saisissez les détails du rattachement de point de terminaison dans le champ Adresse de l'hôte.
- Adresse de l'hôte : spécifiez le nom d'hôte ou l'adresse IP de la destination.
- Cliquez sur SUIVANT.
Un nœud est une unité (ou instance répliquée) de connexion qui traite des transactions. Pour traiter davantage de transactions pour une connexion, vous devez disposer de plus de nœuds. À l'inverse, moins de nœuds sont nécessaires si une connexion traite moins de transactions. Pour comprendre comment les nœuds affectent la tarification de votre connecteur, consultez Tarifs des nœuds de connexion. Si vous ne saisissez aucune valeur, le nombre minimal de nœuds est défini par défaut sur 2 (pour améliorer la disponibilité) et le nombre maximal de nœuds sur 50.
-
Dans la section Authentification, saisissez les informations d'authentification.
- Indiquez si vous souhaitez configurer l'authentification avec le code d'autorisation OAuth 2.0 ou si vous voulez poursuivre sans authentification.
Pour savoir comment configurer l'authentification, consultez Configurer l'authentification.
- Cliquez sur SUIVANT.
- Indiquez si vous souhaitez configurer l'authentification avec le code d'autorisation OAuth 2.0 ou si vous voulez poursuivre sans authentification.
- Vérifiez les informations de connexion et d'authentification, puis cliquez sur Créer.
Configurer l'authentification
Saisissez les informations en fonction de l'authentification que vous souhaitez utiliser.
- Aucune authentification : sélectionnez cette option si vous ne souhaitez pas exiger d'authentification.
- Code d'autorisation OAuth 2.0 : sélectionnez cette option pour configurer l'authentification à l'aide d'un flux de connexion utilisateur Web. Spécifiez les informations suivantes :
- ID client : ID client requis pour se connecter à votre service de backend Google.
- Niveaux d'accès : liste des niveaux d'accès souhaités, séparés par une virgule. Pour afficher tous les champs d'application OAuth 2.0 acceptés par le service Google requis, consultez la section correspondante sur la page Champs d'application OAuth 2.0 pour les API Google.
- Code secret du client : sélectionnez le secret Secret Manager. Vous devez avoir créé le secret Secret Manager avant de configurer cette autorisation.
- Version du secret : version du secret Secret Manager pour le code secret du client.
Pour le type d'authentification Authorization code, vous devez autoriser la connexion après l'avoir créée.
Autoriser la connexion
Si vous utilisez le code d'autorisation OAuth 2.0 pour authentifier la connexion, effectuez les tâches suivantes après avoir créé la connexion.
- Sur la page Connexions, recherchez la connexion que vous venez de créer.
Notez que l'état du nouveau connecteur sera Autorisation requise.
- Cliquez sur Autorisation requise.
Le volet Modifier l'autorisation s'affiche.
- Copiez la valeur de l'URI de redirection dans votre application externe.
- Vérifiez les détails de l'autorisation.
- Cliquez sur Autoriser.
Si l'autorisation aboutit, l'état de la connexion est défini sur Active sur la page Connexions.
Accorder une nouvelle autorisation pour le code d'autorisation
Si vous utilisez le type d'authentification Authorization code et que vous avez modifié la configuration dans BigQuery, vous devez autoriser à nouveau votre connexion BigQuery. Pour autoriser à nouveau une connexion, procédez comme suit :
- Sur la page Connexions, cliquez sur la connexion requise.
La page de détails de la connexion s'ouvre.
- Cliquez sur Modifier pour modifier les détails de la connexion.
- Dans la section Authentification, vérifiez les détails du code d'autorisation OAuth 2.0.
Apportez des modifications, si besoin.
- Cliquez sur Enregistrer. La page de détails de la connexion s'affiche.
- Dans la section Authentification, cliquez sur Modifier l'autorisation. Le volet Autoriser s'affiche.
- Cliquez sur Autoriser.
Si l'autorisation aboutit, l'état de la connexion est défini sur Active sur la page Connexions.
Utiliser la connexion BigQuery dans une intégration
Une fois la connexion créée, elle devient disponible dans Apigee Integration et Application Integration. Vous pouvez utiliser la connexion dans une intégration au moyen de la tâche "Connecteurs".
- Pour savoir comment créer et utiliser la tâche "Connecteurs" dans Apigee Integration, consultez Tâche "Connecteurs".
- Pour savoir comment créer et utiliser la tâche "Connecteurs" dans Application Integration, consultez Tâche "Connecteurs".
Actions
Cette section décrit les actions disponibles dans le connecteur BigQuery.
Les résultats de toutes les actions et opérations d'entité seront disponibles sous forme de réponse JSON dans le paramètre de réponse connectorOutputPayload de la tâche Connectors une fois l'intégration exécutée.
Action CancelJob
Cette action permet d'annuler un job BigQuery en cours d'exécution.
Le tableau suivant décrit les paramètres d'entrée de l'action CancelJob.
| Nom du paramètre | Type de données | Description |
|---|---|---|
| JobId | STRING | ID du job que vous souhaitez annuler. Champ obligatoire. |
| Region | STRING | Région où le job est actuellement exécuté. Ce paramètre n'est pas obligatoire si le job est exécuté dans une région des États-Unis ou de l'UE. |
Action GetJob
Cette action permet de récupérer les informations de configuration et l'état d'exécution d'un job existant.
Le tableau suivant décrit les paramètres d'entrée de l'action GetJob.
| Nom du paramètre | Type de données | Description |
|---|---|---|
| JobId | STRING | ID du job dont vous souhaitez récupérer la configuration. Champ obligatoire. |
| Region | STRING | Région où le job est actuellement exécuté. Ce paramètre n'est pas obligatoire si le job est exécuté dans une région des États-Unis ou de l'UE. |
Action InsertJob
Cette action permet d'insérer un job BigQuery, qui peut ensuite être sélectionné pour récupérer les résultats de la requête.
Le tableau suivant décrit les paramètres d'entrée de l'action InsertJob.
| Nom du paramètre | Type de données | Description |
|---|---|---|
| Query | STRING | Requête à envoyer à BigQuery. Champ obligatoire. |
| IsDML | STRING | Doit être défini sur true si la requête est une instruction LMD ou sur false dans le cas contraire. La valeur par défaut est false. |
| DestinationTable | STRING | Table de destination de la requête, au format DestProjectId:DestDatasetId.DestTable. |
| WriteDisposition | STRING | Spécifie comment écrire des données dans la table de destination (par exemple, tronquer les résultats existants, ajouter les résultats existants ou écrire des données uniquement lorsque la table est vide). Valeurs acceptées :
|
| DryRun | STRING | Indique si l'exécution du job est un dry run (test à blanc). |
| MaximumBytesBilled | STRING | Spécifie le nombre maximal d'octets que le job peut traiter. BigQuery annule le job s'il tente de traiter plus d'octets que la valeur spécifiée. |
| Region | STRING | Spécifie la région dans laquelle le job doit être exécuté. |
Action InsertLoadJob
Cette action permet d'insérer un job de chargement BigQuery, qui ajoute des données de Google Cloud Storage à une table existante.
Le tableau suivant décrit les paramètres d'entrée de l'action InsertLoadJob.
| Nom du paramètre | Type de données | Description |
|---|---|---|
| SourceURIs | STRING | Liste d'URI Google Cloud Storage séparés par un espace. |
| SourceFormat | STRING | Format source des fichiers. Valeurs acceptées :
|
| DestinationTable | STRING | Table de destination de la requête, au format DestProjectId.DestDatasetId.DestTable. |
| DestinationTableProperties | STRING | Objet JSON spécifiant le nom convivial, la description et la liste d'étiquettes de la table. |
| DestinationTableSchema | STRING | Liste JSON spécifiant les champs utilisés pour créer la table. |
| DestinationEncryptionConfiguration | STRING | Objet JSON spécifiant les paramètres de chiffrement KMS pour la table. |
| SchemaUpdateOptions | STRING | Liste JSON spécifiant les options à appliquer lors de la mise à jour du schéma de la table de destination. |
| TimePartitioning | STRING | Objet JSON spécifiant le type et le champ de partitionnement temporel. |
| RangePartitioning | STRING | Objet JSON spécifiant les buckets et le champ de partitionnement de plage. |
| Clustering | STRING | Objet JSON spécifiant les champs à utiliser pour le clustering. |
| Autodetect | STRING | Indique si les options et le schéma doivent être déterminés automatiquement pour les fichiers JSON et CSV. |
| CreateDisposition | STRING | Indique si la table de destination doit être créée si elle n'existe pas déjà. Valeurs acceptées :
|
| WriteDisposition | STRING | Spécifie comment écrire des données dans la table de destination (par exemple, tronquer les résultats existants, ajouter les résultats existants ou écrire des données uniquement lorsque la table est vide). Valeurs acceptées :
|
| Region | STRING | Spécifie la région dans laquelle le job doit être exécuté. Les ressources Google Cloud Storage et l'ensemble de données BigQuery doivent se trouver dans la même région. |
| DryRun | STRING | Indique si l'exécution du job est un dry run (test à blanc). La valeur par défaut est false. |
| MaximumBadRecords | STRING | Spécifie le nombre d'enregistrements pouvant être non valides avant que l'intégralité du job soit annulée. Par défaut, tous les enregistrements doivent être valides. La valeur par défaut est 0. |
| IgnoreUnknownValues | STRING | Indique si les champs inconnus doivent être ignorés dans le fichier d'entrée ou traités comme des erreurs. Par défaut, ils sont traités comme des erreurs. La valeur par défaut est false. |
| AvroUseLogicalTypes | STRING | Indique si les types logiques AVRO doivent être utilisés pour convertir les données AVRO en types BigQuery. La valeur par défaut est true. |
| CSVSkipLeadingRows | STRING | Spécifie le nombre de lignes à ignorer au début des fichiers CSV. Cette option est généralement utilisée pour ignorer les lignes d'en-tête. |
| CSVEncoding | STRING | Type d'encodage des fichiers CSV. Valeurs acceptées :
|
| CSVNullMarker | STRING | Si cette chaîne est fournie, elle est utilisée pour les valeurs NULL dans les fichiers CSV. Par défaut, les fichiers CSV ne peuvent pas utiliser de valeurs NULL. |
| CSVFieldDelimiter | STRING | Caractère utilisé pour séparer les colonnes dans les fichiers CSV. La valeur par défaut est une virgule (,). |
| CSVQuote | STRING | Caractère utilisé pour les champs entre guillemets dans les fichiers CSV. Peut être vide pour désactiver les guillemets. Les guillemets doubles (") sont définis par défaut. |
| CSVAllowQuotedNewlines | STRING | Indique si les champs entre guillemets dans les fichiers CSV peuvent contenir des sauts de ligne. La valeur par défaut est false. |
| CSVAllowJaggedRows | STRING | Indique si les fichiers CSV peuvent contenir des champs manquants. La valeur par défaut est false. |
| DSBackupProjectionFields | STRING | Liste JSON des champs à charger à partir d'une sauvegarde Cloud Datastore. |
| ParquetOptions | STRING | Objet JSON spécifiant les options d'importation propres à Parquet. |
| DecimalTargetTypes | STRING | Liste JSON indiquant l'ordre de préférence appliqué aux types numériques. |
| HivePartitioningOptions | STRING | Objet JSON spécifiant les options de partitionnement côté source. |
Exécuter une requête SQL personnalisée
Pour créer une requête personnalisée, procédez comme suit :
- Suivez les instructions détaillées pour ajouter une tâche "Connecteurs".
- Lorsque vous configurez la tâche "Connecteurs", sélectionnez Actions dans le type d'action à effectuer.
- Dans la liste Action, sélectionnez Exécuter une requête personnalisée, puis cliquez sur OK.
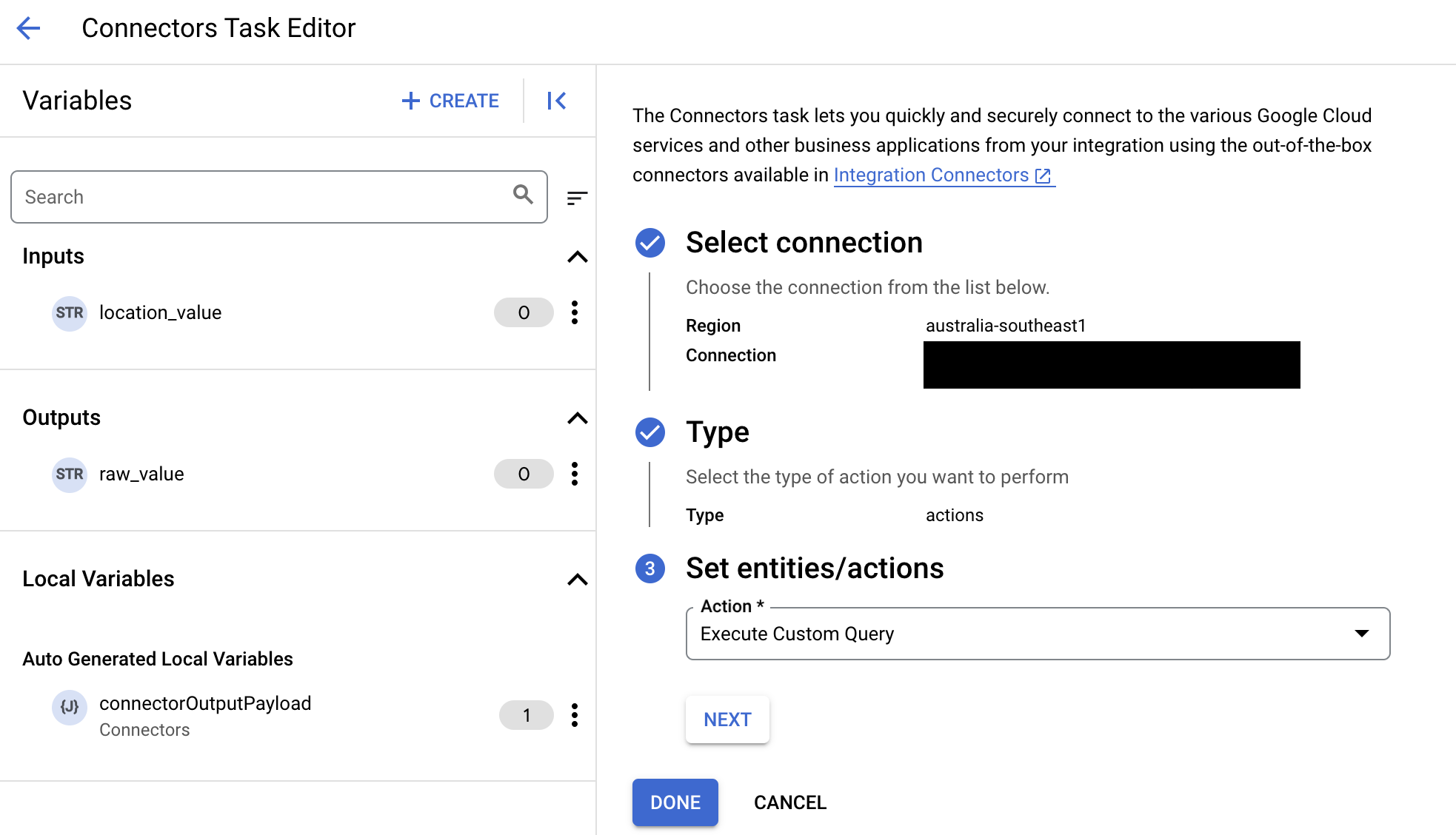
- Développez la section Entrée de la tâche, puis procédez comme suit :
- Dans le champ Délai d'inactivité après, saisissez le nombre de secondes d'attente jusqu'à l'exécution de la requête.
Valeur par défaut :
180secondes - Dans le champ Nombre maximal de lignes, saisissez le nombre maximal de lignes à renvoyer à partir de la base de données.
Valeur par défaut :
25 - Pour mettre à jour la requête personnalisée, cliquez sur Modifier le script personnalisé. La boîte de dialogue Éditeur de script s'ouvre.
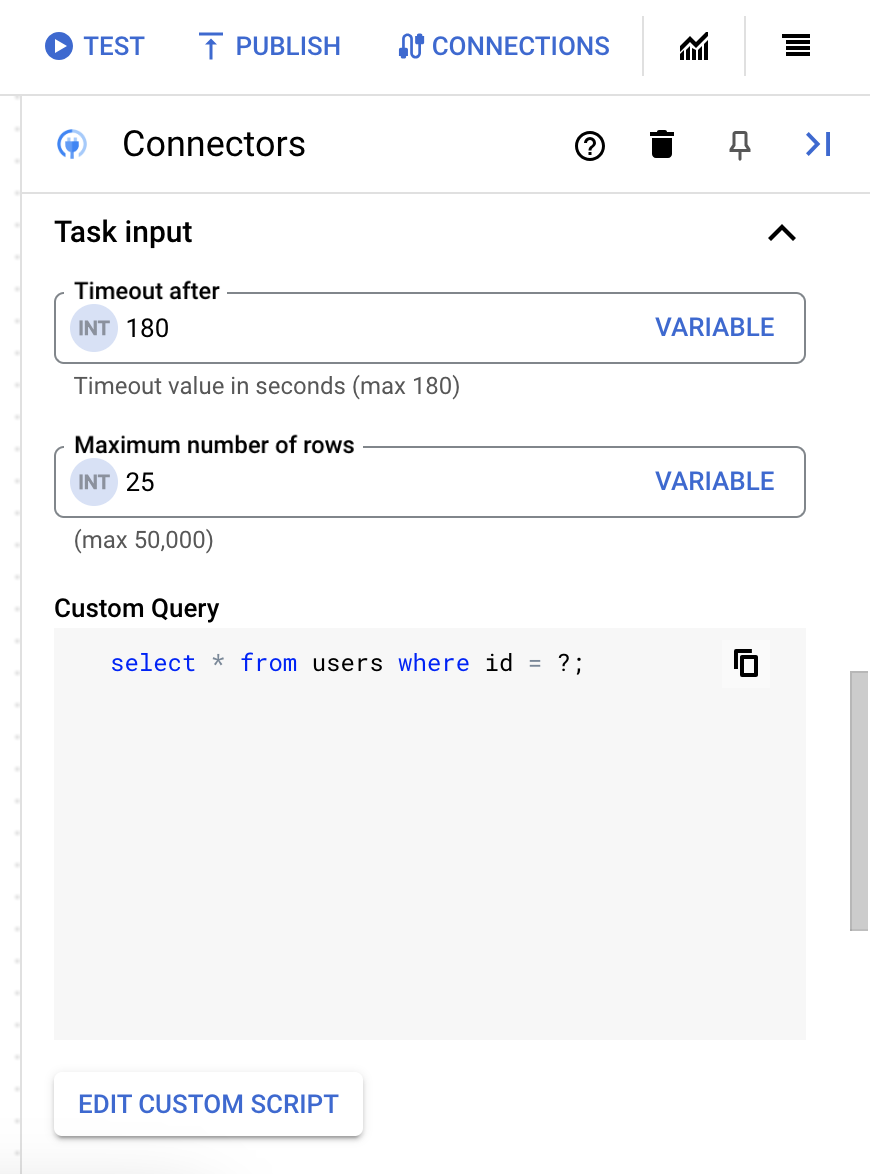
- Dans la boîte de dialogue Éditeur de script, saisissez la requête SQL, puis cliquez sur Enregistrer.
Vous pouvez utiliser un point d'interrogation (?) dans une instruction SQL pour représenter un seul paramètre devant être spécifié dans la liste des paramètres de requête. Par exemple, la requête SQL suivante sélectionne toutes les lignes de la table
Employeescorrespondant aux valeurs spécifiées pour la colonneLastName:SELECT * FROM Employees where LastName=?
- Si vous avez utilisé des points d'interrogation dans votre requête SQL, vous devez ajouter le paramètre en cliquant sur + Ajouter un nom de paramètre pour chaque point d'interrogation. Lors de l'exécution de l'intégration, ces paramètres remplacent les points d'interrogation (?) de la requête SQL de manière séquentielle. Par exemple, si vous avez ajouté trois points d'interrogation (?), vous devez ajouter trois paramètres dans l'ordre de séquence.
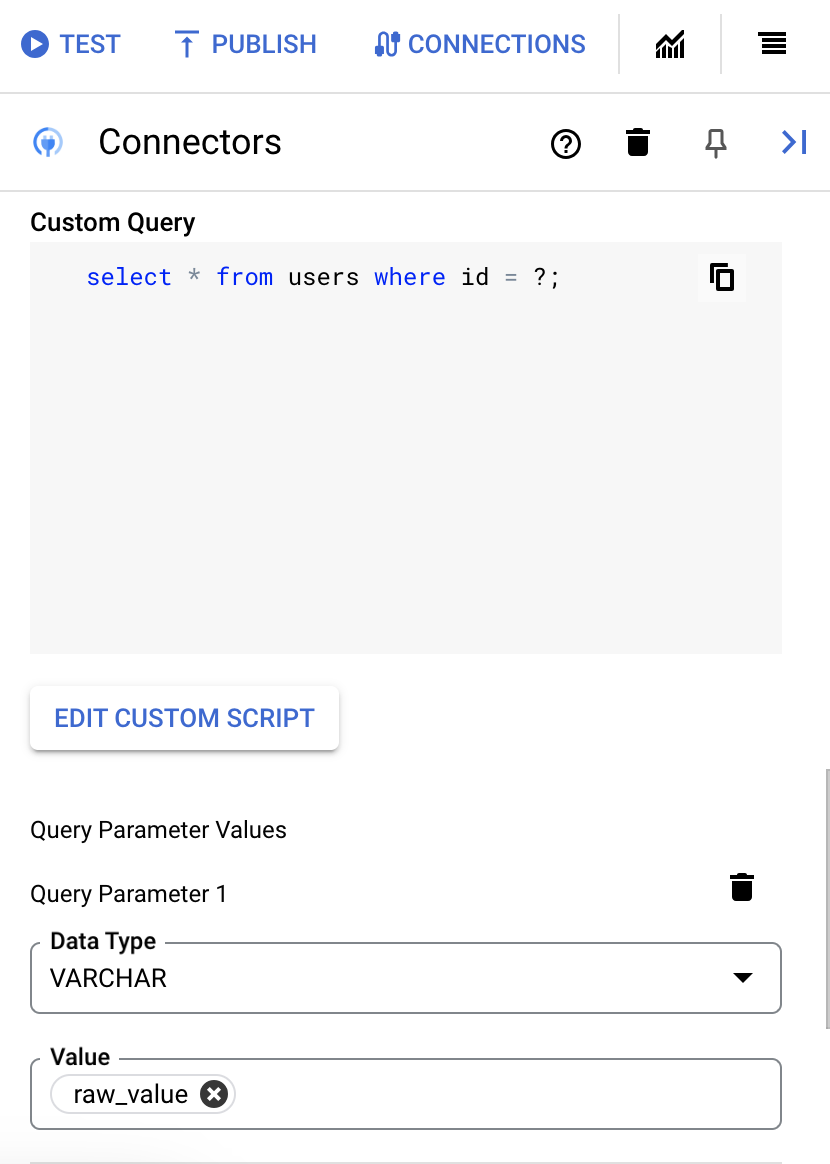
Pour ajouter des paramètres de requête, procédez comme suit :
- Dans la liste Type, sélectionnez le type de données du paramètre.
- Dans le champ Valeur, saisissez la valeur du paramètre.
- Pour ajouter plusieurs paramètres, cliquez sur + Ajouter un paramètre de requête.
- Dans le champ Délai d'inactivité après, saisissez le nombre de secondes d'attente jusqu'à l'exécution de la requête.
Utiliser Terraform pour créer des connexions
Vous pouvez utiliser la ressource Terraform pour créer une connexion.
Pour savoir comment appliquer ou supprimer une configuration Terraform, consultez Commandes Terraform de base.
Pour afficher un exemple de modèle Terraform permettant de créer une connexion, consultez Exemple de modèle.
Lorsque vous créez cette connexion à l'aide de Terraform, vous devez définir les variables suivantes dans votre fichier de configuration Terraform :
| Nom du paramètre | Type de données | Obligatoire | Description |
|---|---|---|---|
| project_id | STRING | True | ID du projet contenant l'ensemble de données BigQuery (par exemple, "myproject"). |
| dataset_id | STRING | False | ID de l'ensemble de données BigQuery sans le nom du projet (par exemple, "mydataset"). |
| proxy_enabled | BOOLEAN | False | Cochez cette case afin de configurer un serveur proxy pour la connexion. |
| proxy_auth_scheme | ENUM | False | Type d'authentification à utiliser pour s'authentifier auprès du proxy ProxyServer. Valeurs acceptées : BASIC, DIGEST et NONE. |
| proxy_user | STRING | False | Nom d'utilisateur permettant de s'authentifier auprès du proxy ProxyServer. |
| proxy_password | SECRET | False | Mot de passe à utiliser pour s'authentifier auprès du proxy ProxyServer. |
| proxy_ssltype | ENUM | False | Type SSL à utiliser pour se connecter au proxy ProxyServer. Valeurs acceptées : AUTO, ALWAYS, NEVER et TUNNEL. |
Limites du système
Le connecteur BigQuery peut traiter au maximum huit transactions par seconde et par nœud, et limite les transactions au-delà de ce seuil. Par défaut, Integration Connectors alloue deux nœuds (pour améliorer la disponibilité) à une connexion.
Pour en savoir plus sur les limites applicables à Integration Connectors, consultez Limites.
Types de données acceptés
Voici les types de données acceptés pour ce connecteur :
- ARRAY
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- TIME
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
Problèmes connus
Le connecteur BigQuery n'accepte pas la clé primaire dans une table BigQuery. Cela signifie que vous ne pouvez pas effectuer les opérations d'entité Get, Update et Delete à l'aide d'un entityId.
Sinon, vous pouvez utiliser la clause de filtre pour filtrer les enregistrements en fonction d'un ID.
Demander de l'aide à la communauté Google Cloud
Vous pouvez publier vos questions et discuter de ce connecteur sur les forums Cloud de la communauté Google Cloud.
Étapes suivantes
- Découvrez comment suspendre et reprendre une connexion.
- Découvrez comment surveiller l'utilisation des connecteurs.
- Découvrez comment afficher les journaux des connecteurs.