Error Reporting을 사용하면 애플리케이션 비정상 종료를 자동으로 캡처하고 이러한 비정상 종료의 스택 트레이스를 오류 그룹으로 그룹화하여 애플리케이션 오류를 식별, 이해, 관리할 수 있습니다. 그러나 일부 Google Cloud서비스 오류는 오류 메시지로 로깅되며 스택 트레이스 형식으로 발생하지 않습니다. Error Reporting의 서비스 오류 기능은 이러한 유형의 Google Cloud 서비스 오류를 자동으로 캡처하고 그룹화하여 시스템의 문제를 신속하게 파악하고 새 오류가 발생할 때 알림을 제공합니다.
예를 들어 Cloud Run을 사용하는 경우 요청을 실행할 때 최대 컨테이너 인스턴스 한도에 도달하는 상황이 발생할 수 있습니다. 이 이벤트가 Cloud Logging에 로깅되면 Error Reporting의 서비스 오류는 이 오류를 자동으로 캡처하고 유사한 오류와 함께 그룹화하며 이 이벤트가 발생했음을 알립니다. 또한 일부 Google Cloud 서비스는 이러한 오류를 해결하기 위해 Error Reporting 페이지에서 액세스할 수 있는 문제 해결 문서를 제공합니다.
서비스 오류 보기
Google Cloud 콘솔에서 Error Reporting 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾을 수도 있습니다.
Error Reporting은 새로운 서비스 오류가 포함된 로그를 감지하고 그룹화할 때 유형 열의 Error Reporting 개요 페이지에서 이러한 서비스 오류를 확인할 수 있습니다.
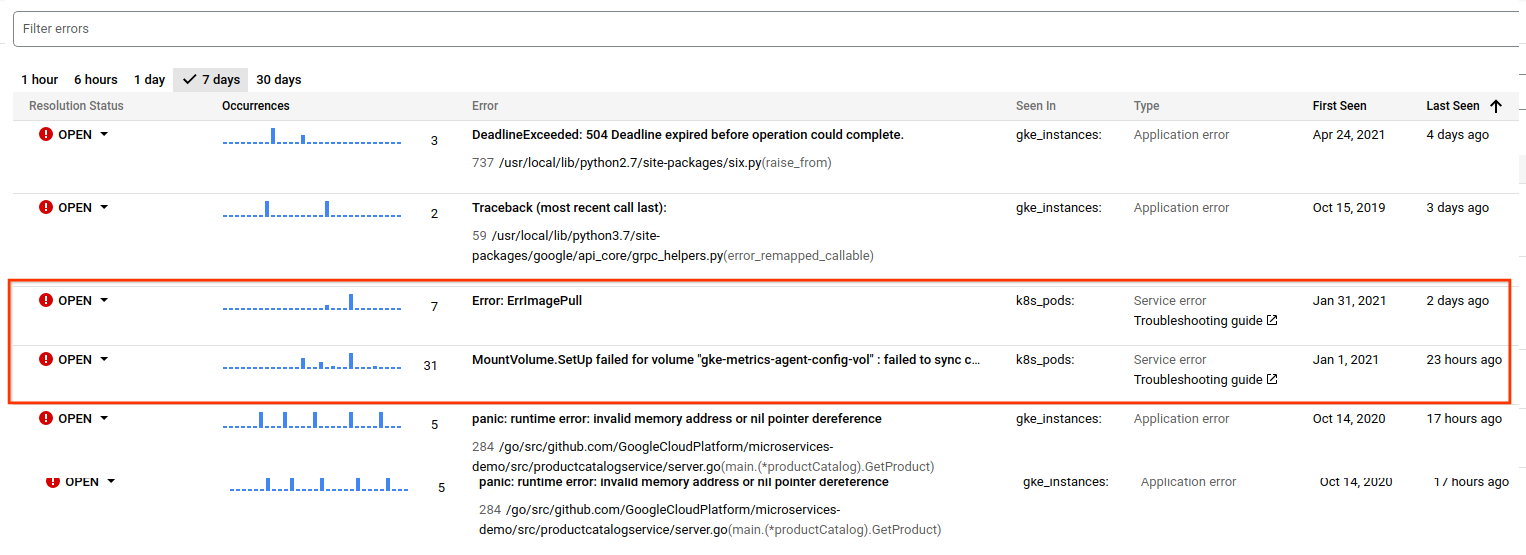
문서화된 솔루션이 있는 서비스 오류의 경우 Error Reporting은 서비스에서 제공하는 문제 해결 가이드 링크를 제공합니다. Google Cloud
서비스 오류 샘플
다음 표에는 Error Reporting의 서비스 오류가 캡처하는 오류의 일부만 나와 있습니다.
| Google Cloud 서비스 이름 | 오류 유형 |
|---|---|
| Dataflow | 작업자 로그 제한 메모리 부족(시스템) 커스텀 서브넷 누락 단계의 긴 작업 JRE 비정상 종료 잘못 구성된 작업자 JAR 파일 |
| Cloud Run | 메모리 한도 초과 사용 가능한 인스턴스 없음 |
| Google Kubernetes Engine | 비정상 pod, 실패한 프로브 Pod 예약 실패 백오프로 실패한 컨테이너 다시 시작 마운트 해제된 볼륨 컨테이너 이미지를 가져오지 못함 엔드포인트를 업데이트할 수 없음 Secrets/configmaps를 찾을 수 없음 |