Error Reporting を使用すると、アプリケーションのクラッシュを自動的にキャプチャし、これらのクラッシュからのスタック トレースをエラーグループにグループ化することで、アプリケーション エラーを特定して把握し、管理できます。ただし、一部の Google Cloudサービスエラーは、エラー メッセージとしてログに記録され、スタック トレースの形式で取得されません。Error Reporting の [サービスエラー] 機能は、このような Google Cloud サービスエラーを自動的にキャプチャしてグループ化するため、システムの問題をすばやく特定して、新しいエラーが発生したときに通知を受け取ることができます。
たとえば、Cloud Run を使用しているときに、リクエストの送信時にコンテナ インスタンス数が上限に達する場合があります。このイベントが Cloud Logging に記録されると、Error Reporting のサービスエラーがこのエラーを自動的にキャプチャし、同様のエラーでグループ化して、このイベントの発生を通知します。さらに、これらのエラーを解決するために、一部の Google Cloud サービスは、Error Reporting ページからアクセスできるトラブルシューティング ドキュメントを提供しています。
サービスエラーを表示する
Google Cloud コンソールで、[Error Reporting] ページに移動します。
このページは、検索バーを使用して見つけることもできます。
Error Reporting が新しいサービスエラーを含むログを検出し、グループ化すると、[タイプ] 列の Error Reporting の概要ページにそれらのサービスエラーが表示されます。
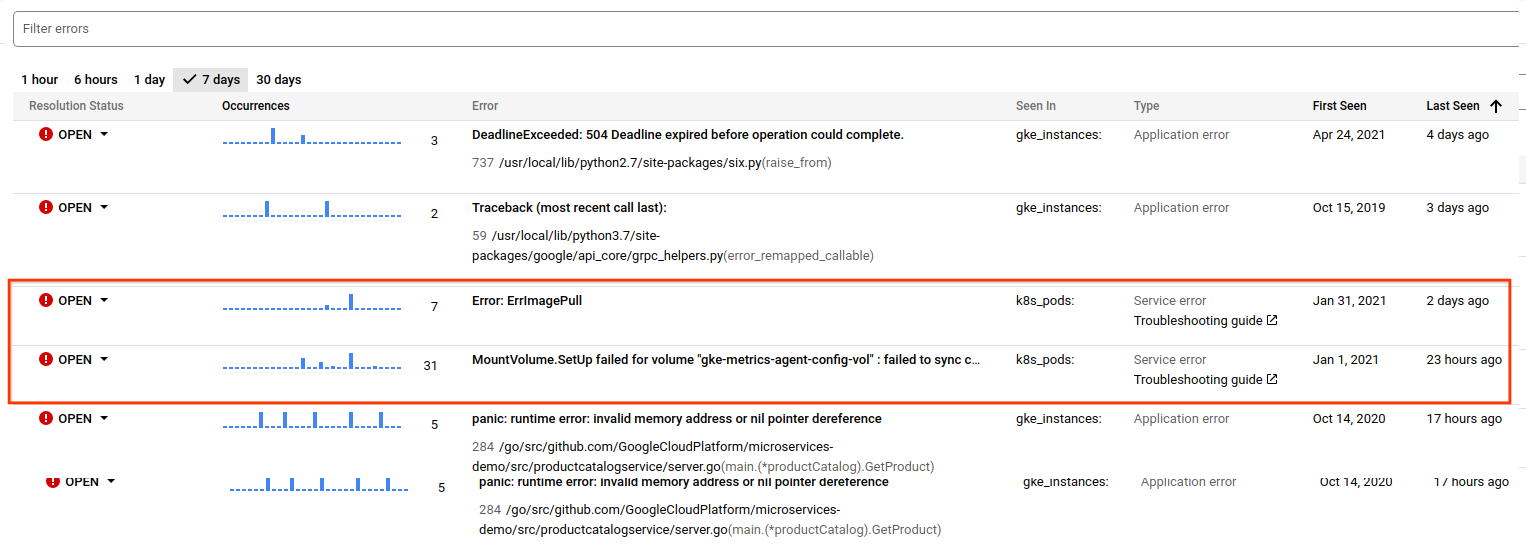
文書化されたソリューションに関するサービスエラーの場合、Error Reporting は、サービスに用意されたトラブルシューティング ガイドへのリンクを表示します。 Google Cloud
サービスエラーの例
次の表に、Error Reporting のサービスエラーでキャプチャできるエラーの一部を示します(すべてを網羅した表ではありません)。
| Google Cloud サービス名 | エラーの種類 |
|---|---|
| Dataflow | ワーカーログのスロットリング メモリ不足(システム) カスタム サブネットの欠落 ステップの実行時間が長い操作 JRE クラッシュ ワーカー JAR ファイルの構成の誤り |
| Cloud Run | メモリ上限の超過 使用可能なインスタンスがない |
| Google Kubernetes Engine | 異常な状態の Pod、プローブの失敗 Pod のスケジュール設定に失敗しました 失敗したコンテナをバックオフで再起動する マウントされていないボリューム コンテナ イメージの pull に失敗しました エンドポイントを更新できませんでした Secret / configmap が見つかりませんでした |