Cloud TPU 简介
张量处理单元 (TPU) 是 Google 定制开发的专用集成电路 (ASIC),用于加速机器学习工作负载。如需详细了解 TPU 硬件,请参阅系统架构。Cloud TPU 是一种 Web 服务,使 TPU 可用作 Google Cloud 上的可扩缩计算资源。
TPU 使用专为执行机器学习算法中常见的大型矩阵运算而设计的硬件,更高效地训练模型。TPU 芯片上高带宽存储器 (HBM),让您可以使用更大的模型 尺寸。TPU 可以连接在名为 Pod 的组中,这让您可以在几乎不需要更改代码的情况下对工作负载进行纵向扩容。
工作原理
为了理解 TPU 的工作原理,我们不妨了解一下其他加速器如何应对训练机器学习模型的计算挑战。
CPU 的工作方式
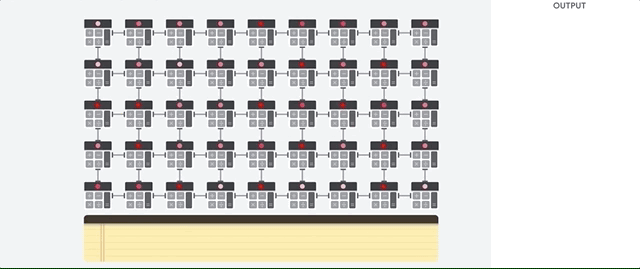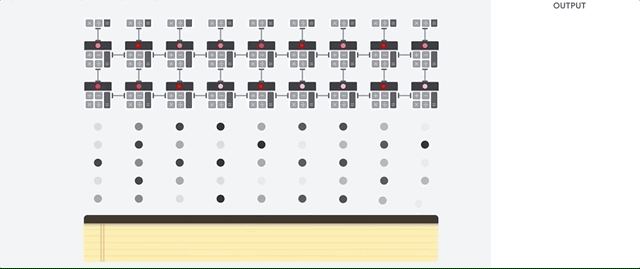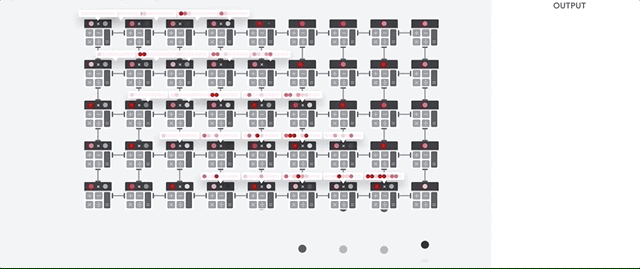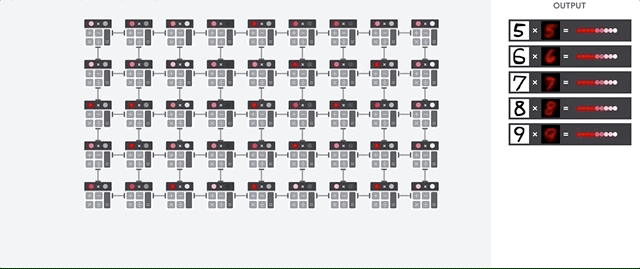
CPU 是一种基于冯·诺依曼结构的通用处理器。这意味着 CPU 与软件和内存协同工作,如下所示:
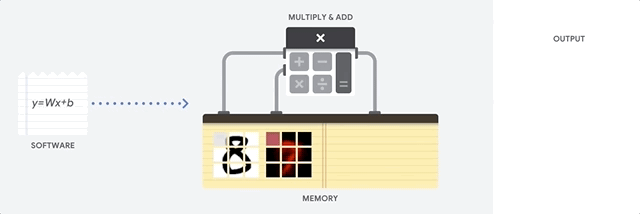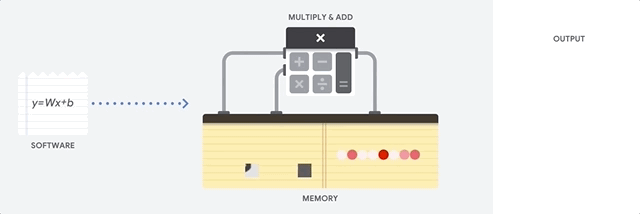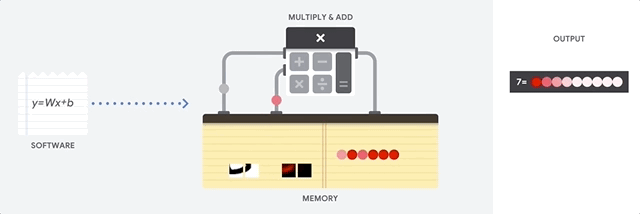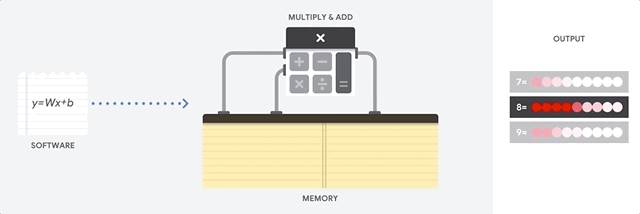
CPU 最大的优点是它们的灵活性。您可以在 CPU 上为许多不同类型的应用加载任何类型的软件。例如,您可以使用 CPU 在 PC 上进行文字处理、控制火箭发动机、处理银行交易或通过神经网络对图片进行分类。
对于每次计算,CPU 从内存加载值,对值执行计算,然后将结果存储回内存中。与计算速度相比,内存访问速度较慢,并可能会限制 CPU 的总吞吐量。这通常称为冯·诺依曼瓶颈。
GPU 的工作方式
为了提高吞吐量,GPU 在单个处理器中包含数千个算术逻辑单元 (ALU)。现代 GPU 通常包含 2500 - 5000 个 ALU。如此大量的处理器意味着您可以同时执行数千次乘法和加法运算。

这种 GPU 架构非常适合并行处理大量运算(例如神经网络中的矩阵运算)的应用。实际上,在用于深度学习的典型训练工作负载上,GPU 的吞吐量可比 CPU 高出一个数量级。
不过,GPU 仍然是一种通用处理器,必须支持许多不同应用和软件。因此,GPU 也存在 CPU。对于数千个 ALU 中的每一次计算,GPU 都必须访问寄存器或共享内存,以读取运算对象以及存储中间计算结果。
TPU 的工作方式
Google 设计了 Cloud TPU,它们是专门用于神经网络工作负载的矩阵处理器。TPU 不能运行文字处理程序、控制火箭引擎或执行银行交易,但它们可以很快地处理神经网络中使用的大量矩阵运算。
TPU 的主要任务是矩阵处理,这是乘法和累加运算的组合。TPU 包含数千个乘法累加器,这些累加器彼此直接连接以形成大型物理矩阵。这称为脉动阵列架构。Cloud TPU v3 在单个处理器上包含两个 128 x 128 ALU 的脉动阵列。
TPU 主机将数据流式传输到馈入队列中。TPU 从馈入队列加载数据,并将其存储在 HBM 内存中。计算完成后,TPU 会将结果加载到馈出队列中。然后,TPU 主机从馈出队列读取结果并将其存储在主机的内存中。
为了执行矩阵运算,TPU 将 HBM 内存中的参数加载到矩阵乘法单元 (MXU) 中。

然后,TPU 从内存加载数据。每次执行乘法运算时, 结果会传递到下一个乘积累加器。输出是数据和参数之间所有乘法结果的总和。在矩阵乘法过程中,不需要访问内存。
因此,TPU 可以在神经网络计算中实现高计算吞吐量。
XLA 编译器
在 TPU 上运行的代码必须由加速器线性代数 (XLA) 编译 。XLA 是一种实时编译器,可获取机器学习框架应用发出的图表,并将图表的线性代数、损失和梯度组件编译为 TPU 机器码。程序的其余部分在 TPU 宿主机上运行。XLA 编译器是运行在 TPU 主机上的 TPU 虚拟机映像的一部分。
何时使用 TPU
Cloud TPU 针对特定工作负载进行了优化。在某些情况下,您可能希望在 Compute Engine 实例上使用 GPU 或 CPU 来运行机器学习工作负载。通常,您可以根据以下准则确定哪种硬件最适合您的工作负载:
CPU
- 需要最高灵活性的快速原型设计
- 训练时间不长的简单模型
- 有效批量大小较小的小型模型
- 包含许多以 C++ 编写的自定义 TensorFlow 操作的模型
- 受主机系统可用 I/O 或网络带宽限制的模型
GPU
- 具有大量自定义且必须至少部分在 CPU 上运行的 TensorFlow/PyTorch/JAX 操作的模型
- 具有 Cloud TPU 上不可用的 TensorFlow 操作的模型 (请参阅可用的 TensorFlow 操作列表)
- 有效批量大小较大的中到大型模型
TPU
- 由矩阵计算主导的模型
- 主函数内没有自定义 TensorFlow/PyTorch/JAX 操作的模型 训练循环
- 需要训练数周或数月的模型
- 有效批量大小较大的大型模型
Cloud TPU 不适合以下工作负载:
- 需要频繁分支或包含许多元素级代数运算的线性代数程序
- 以稀疏方式访问内存的工作负载
- 需要高精度算法的工作负载
- 主训练循环中包含自定义操作的神经网络工作负载
模型开发最佳做法
由非矩阵运算(如 add、reshape 或 concatenate)主导计算的程序可能无法实现较高的 MXU 利用率。以下是一些可帮助您选择和构建 适合 Cloud TPU 的模型。
布局
XLA 编译器执行代码转换,包括将矩阵乘法平铺成较小的块,以便高效地在矩阵单元 (MXU) 上执行计算。XLA 编译器使用 MXU 硬件结构(128x128 脉动阵列)和 TPU 内存子系统设计(该设计更擅长处理 8 的倍数的维度)来提高平铺效率。因此,某些布局更有利于平铺,而另一些布局则需要在平铺之前调整形状。调整形状的操作在 Cloud TPU 上通常受限于内存。
形状
XLA 编译器即时为第一批量编译机器学习图。如果任何后续批量具有不同形状,则该模型不起作用。(在每次形状变化时重新编译图太慢。)因此,任何 具有动态形状的张量不太适合 TPU。
填充
高性能 Cloud TPU 程序是指密集计算 可以平铺成 128x128 块如果矩阵计算不能占满整个 MXU,编译器会用零来填充张量。填充有两个不足:
- 用零填充的张量不能充分利用 TPU 核心。
- 填充增加了张量所需的片上内存存储,并且在极端情况下可能导致内存不足错误。
虽然填充是由 XLA 编译器在必要时自动执行的,但您可以通过 op_profile 工具确定填充量。您可以通过选择非常适合 TPU 的张量维度来避免填充。
维度
选择合适的张量维度对于使 TPU 硬件(尤其是 MXU)发挥最高性能很有帮助。XLA 编译器尝试使用批量大小或特征维度来最大限度地使用 MXU。因此,这两个因素之一必须是 128 的倍数。否则,编译器会将其中某个填充到 128。理想情况下,批量大小和特征维度应为 8 的倍数,这样可以使内存子系统发挥最高性能。
VPC Service Controls 集成
借助 Cloud TPU VPC Service Controls, 您的 Cloud TPU 资源,并控制跨边界的数据移动 边界。如需详细了解 VPC Service Controls,请参阅 VPC Service Controls 概览。 如需详细了解将 Cloud TPU 与 VPC Service Controls 结合使用的限制,请参阅支持的产品和限制。
Edge TPU
在云端训练的机器学习模型越来越需要“在边缘”(即在物联网 (IoT) 边缘运行的设备上)进行推断。这些设备包括传感器和其他智能设备,它们收集实时数据,作出智能的决策,然后采取行动或将信息传递给其他设备或云端。
由于此类设备必须在有限的电量(包括电池供电)下运行,因此 Google 设计了 Edge TPU 协处理器来加速低功耗设备上的机器学习推断。一个 Edge TPU 每秒可执行 4 万亿次操作(4 TOPS),能耗仅 2 瓦特,换句话说,每瓦特可获得 2 TOPS。例如,Edge TPU 能够以低能耗的方式以接近每秒 400 帧的速率执行先进的移动视觉模型,例如 MobileNet V2。
这款低功耗的机器学习加速器增强了 Cloud TPU 和 Cloud IoT 的功能,提供一个端到端(云端到边缘、硬件 + 软件)的基础架构,帮助您实现基于 AI 的解决方案。
Edge TPU 适用于多种设备类型的的原型设计和生产设备,包括单板计算机、模块化系统、PCIe/M.2 卡和表面安装模块。如需详细了解 Edge TPU 和所有可用产品,请访问 coral.ai。
Cloud TPU 使用入门
- 设置 Google Cloud 账号
- 激活 Cloud TPU API
- 向 Cloud TPU 授予对您的 Cloud Storage 存储桶的访问权限
- 在 TPU 上运行基本计算
- 在 TPU 上训练参考模型
- 分析模型
请求帮助
请与 Cloud TPU 支持团队联系。 如果您有有效的 Google Cloud 项目,请准备好提供以下信息:
- 您的 Google Cloud 项目 ID
- 您的 TPU 名称(如果有)
- 您要提供的其他信息
后续步骤
想要详细了解 Cloud TPU?以下资源可能对您有所帮助: