借助 Document AI,您可以使用自己的训练数据训练新的处理器版本,并根据自己的测试数据评估处理器版本的质量。
如果您想使用自定义处理器,此方法会非常有用。Document AI 提供了适合您的文档类型的处理器,但您可以对该处理器的自定义版本进行增量训练,以满足您的需求。
训练和评估通常会同步进行,以便迭代生成高质量、可用的处理器版本。
Document AI
借助 Document AI,您可以构建自己的自定义提取器,该提取器可从特定类型的文档中提取实体,例如菜单中的项目或简历中的姓名和联系信息。
与其他处理器不同,自定义处理器不附带任何预训练的处理器版本,因此在您从头开始训练版本之前,无法处理任何文档。
如需开始使用 Document AI,请参阅构建自己的自定义处理器。
增量训练处理器
您可以追加训练新的处理器版本,以提高数据准确性、从文档中提取其他自定义字段,并添加对新语言的支持。
升级训练通过对 Google 预训练的处理器版本应用迁移学习来实现,通常比从头开始训练所需的数据更少。
如需开始使用,请参阅对预训练的处理器进行增量训练。
支持的处理器
并非所有专用处理器都支持向上训练。以下是支持升级训练的处理器。
数据注意事项和建议
数据的质量和数量决定了训练、再训练和评估的质量。
获取一组具有代表性的真实文档并提供足够的高质量标签通常是流程中最耗时且最耗费资源的部分。
文档数量
如果您的所有文档都具有相似的格式(例如,固定格式,变化很小),那么只需较少的文档即可实现高准确度。变异程度越高,所需的文件就越多。
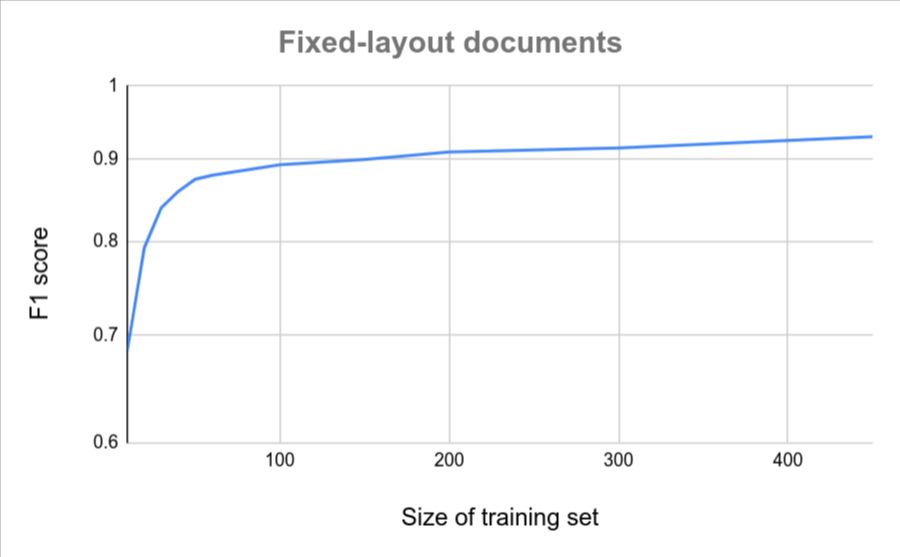
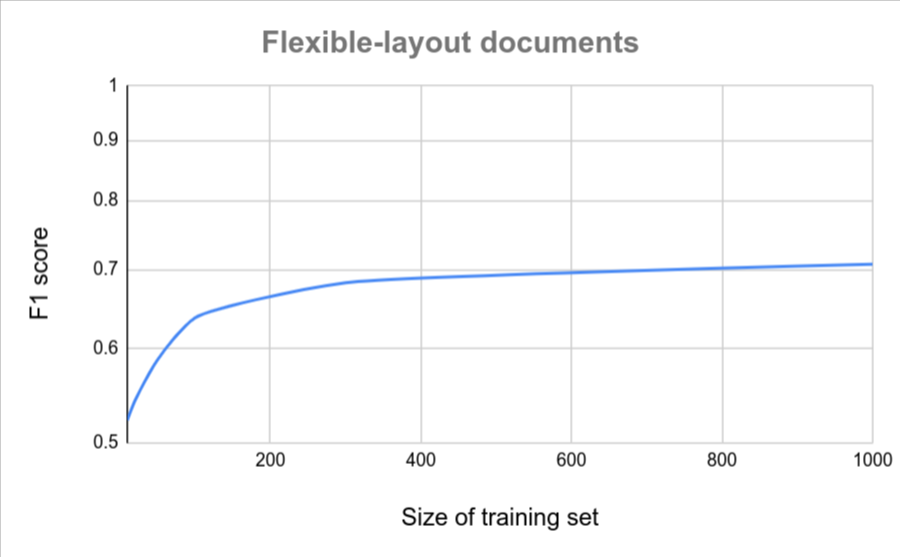
以下图表粗略估计了自定义文档提取器达到特定质量分数所需的文档数量。
| 变化较小 | 变化较大 |
|---|---|
 |
 |
为数据加标签
考虑标记文档的选项,并确保您有足够的资源来注释数据集中的文档。
训练模型
自定义提取器处理器可以使用不同的模型类型,具体取决于特定用例和可用的训练数据。
- 自定义模型:使用已加标签的训练数据的模型。
- 基于模板:具有固定布局的文档。
- 基于模型:布局略有变化的文档。
- 生成式 AI 模型:基于预训练的基础模型,只需进行极少的额外训练。
下表说明了每种模型类型对应的使用场景。
| 自定义模型 | 生成式 AI | ||
|---|---|---|---|
| 基于模板 | 基于模型 | ||
| 布局变体 | 无 | 低到中 | 高 |
| 自由格式文本的数量(例如合同中的段落) | 低 | 低 | 高 |
| 所需的训练数据量 | 低 | 高 | 低 |
| 在训练数据有限的情况下实现高准确率 | 较高 | 较低 | 较高 |
了解如何使用属性说明微调处理器。
何时使用其他处理器
在以下情况下,您可能需要考虑 Document AI Document AI Workbench 以外的选项,或者调整工作流程。
- Document AI Workbench 不支持某些基于文本的输入格式(.txt、.html、.docx、.md 等)。不妨考虑 Google Cloud中的其他预构建或自定义语言处理产品,例如 Cloud Natural Language API。
- 自定义文档提取器架构最多支持 150 个实体标签。如果您的业务逻辑需要在架构定义中使用 150 个以上的实体,请考虑训练多个处理器,每个处理器以一部分实体为目标。
如何训练处理器
假设您已创建支持训练或追加训练的处理器并为数据集添加标签,那么您可以从头开始训练新的处理器版本。或者,您也可以基于现有处理器版本追加训练新的处理器版本。
训练处理器版本
网页界面
在 Google Cloud 控制台中,前往处理器的训练标签页。
点击修改架构以打开管理标签页面。验证处理器的标签。
训练时启用的标签决定了新处理器版本提取的实体。如果架构中的某个标签处于非活跃状态,即使文档已添加标签,处理器版本也不会提取该标签。
在训练标签页上,点击查看标签统计数据,然后验证测试集和训练集。自动加标签、未加标签或未分配的文档不会用于训练和评估。
点击训练新版本。
版本名称定义了
processorVersion的name字段。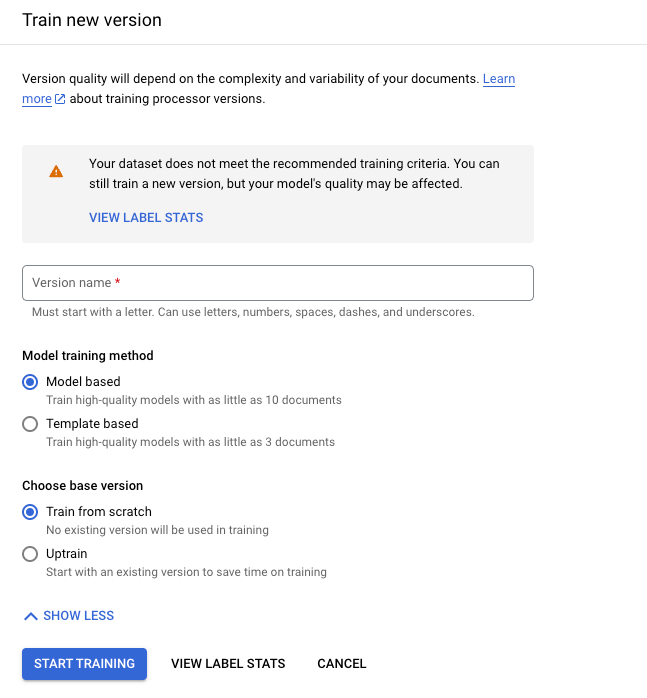
点击开始训练,然后等待系统训练并评估新的处理器版本。
您可以在管理版本标签页中监控训练进度:
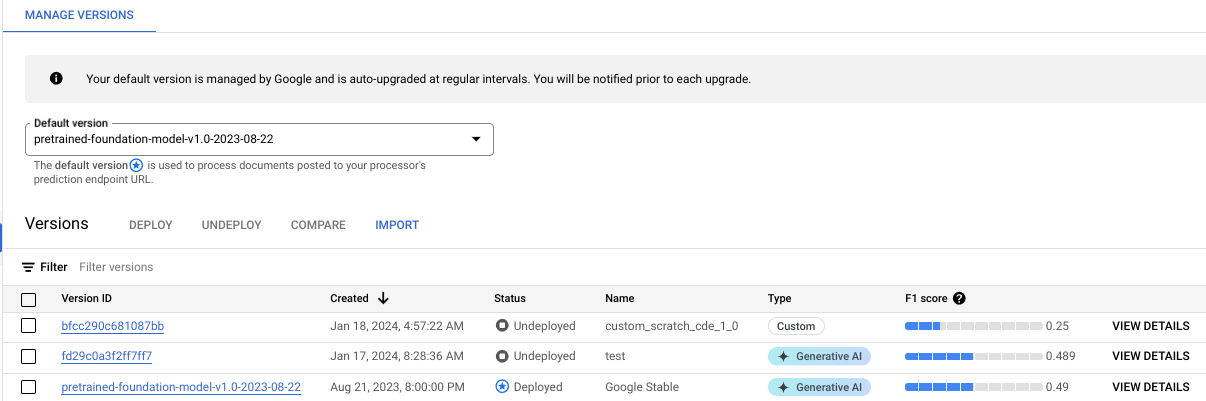
点击评估和测试标签页,查看新处理器版本在测试集上的表现。如需了解详情,请参阅评估处理器版本。
Python
如需了解详情,请参阅 Document AI Python API 参考文档。
如需向 Document AI 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
部署和使用处理器版本
您可以像部署和管理任何其他处理器版本一样部署和管理处理器版本。如需了解详情,请参阅管理处理器版本。
部署后,您可以向自定义处理器发送处理请求。
停用或删除处理器
如果您不想再使用某个处理器,可以将其停用或删除。如果您停用了处理器,可以重新启用它。处理器一经删除,便无法恢复。
在左侧的 Document AI 面板中,点击我的处理器。
点击处理器名称右侧的竖向三点状图标。点击停用处理器或删除处理器。
如需了解详情,请参阅管理处理器版本。
训练数据加密
Document AI 训练数据保存在 Cloud Storage 中,并且可以根据需要使用客户管理的加密密钥进行加密。
删除训练数据
Document AI 训练作业完成后,保存在 Cloud Storage 中的所有训练数据会在 2 天的保留期限过后失效。后续的数据删除活动将遵循 Google Cloud上的数据删除中所述的流程。
价格
训练或重新训练无需付费。您需要支付托管和预测费用。 如需了解详情,请参阅 Document AI 价格。